Python3+selenium 爬取网站美女图片最简单版本
听说python是爬虫利器,用java几百行的代码,python十几行就搞定了,所以决定自己来感受一下python的方便,参考了很多文章,自己都忘记了,就不一一列举了
1.安装python,pycharm
python怎么安装就不说了,网上一大堆 这是我的python版本,如果你是第一次安装,推荐安装我这个版本

你当然可以选择用python自带的编辑器,不过我觉得pycharm真的是最好用的python编辑器了,推荐使用pycharm
2.安装selenium
可以参考这一篇 https://www.cnblogs.com/fnng/archive/2013/05/29/3106515.html
我安装完selenium之后,在pycharm中 写 from selenium import webdriver 报错,但是用python自带的编辑器应该是可以使用selenium模块了,那么如何解决pycharm上面报错的问题呢,我的做法是
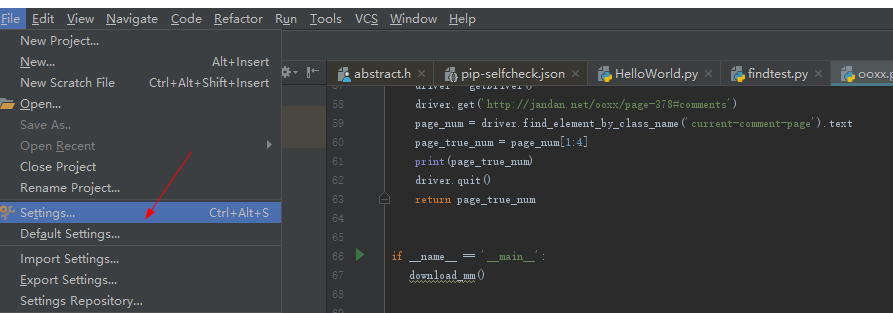
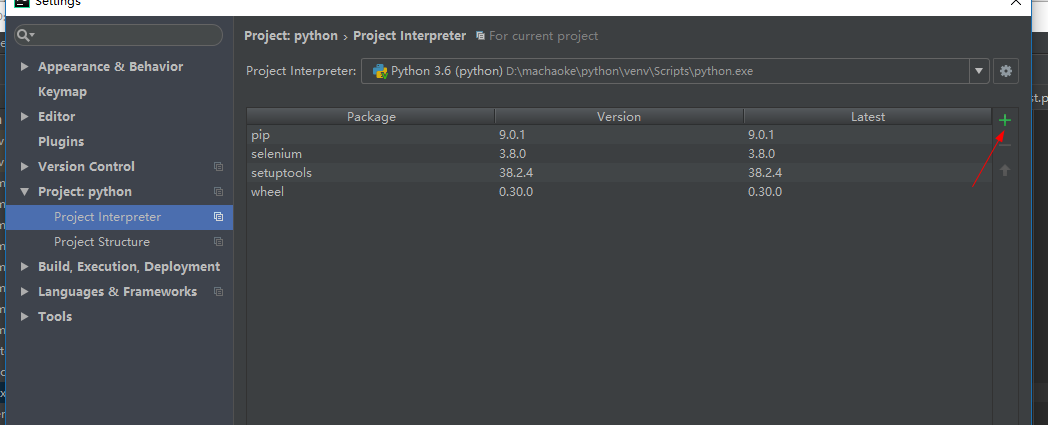
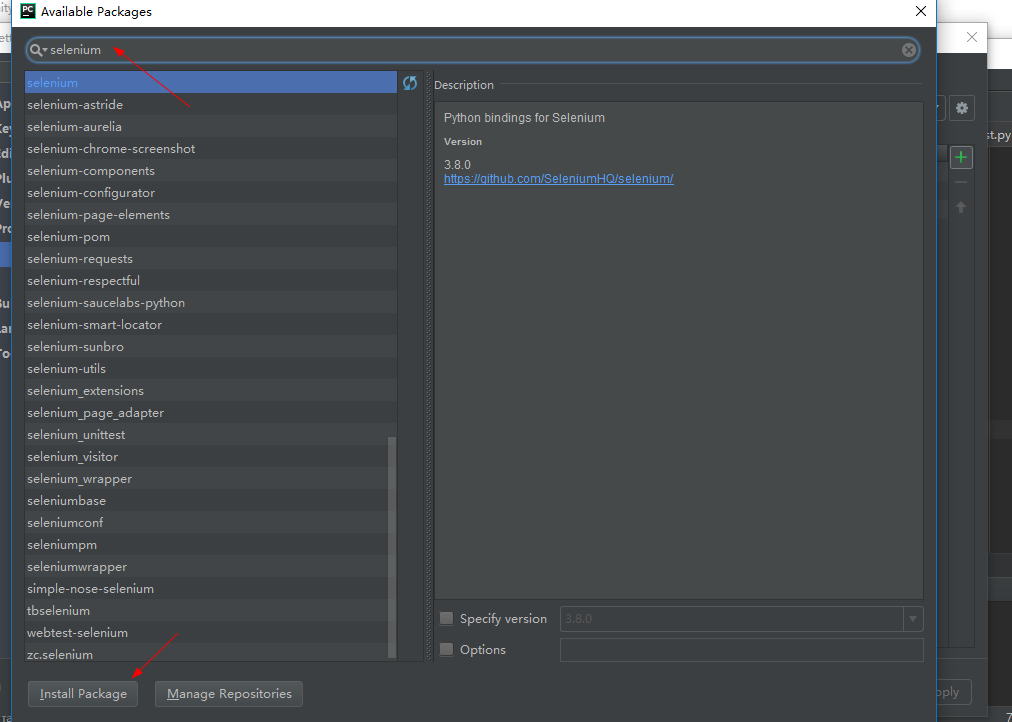
安装好之后,form selenium import webdriver 就不报错了! 由此猜测估计是pycharm没有找到之前 pip下载下来的selenium模块。。
3.安装chromedriver
网上搜索一下就可以了。有一点要说明一下,按照我的代码的写法是不需要配置chromedriver的环境变量的,因为我自己配置了环境变量,但是一直报错,没办法之下,只能退而求其次,网上找了一种把chromedriver写死的办法了
4.代码阶段
额,准备工作就花了大半天了,现在可以进入激动人心的阶段了,爬取我们的美女图片了!
现在附上我的代码截图 参考了很多文章,但是中间有很多报错啥的,经过了摸索修改,最终成功拿到了图片
成果截图:
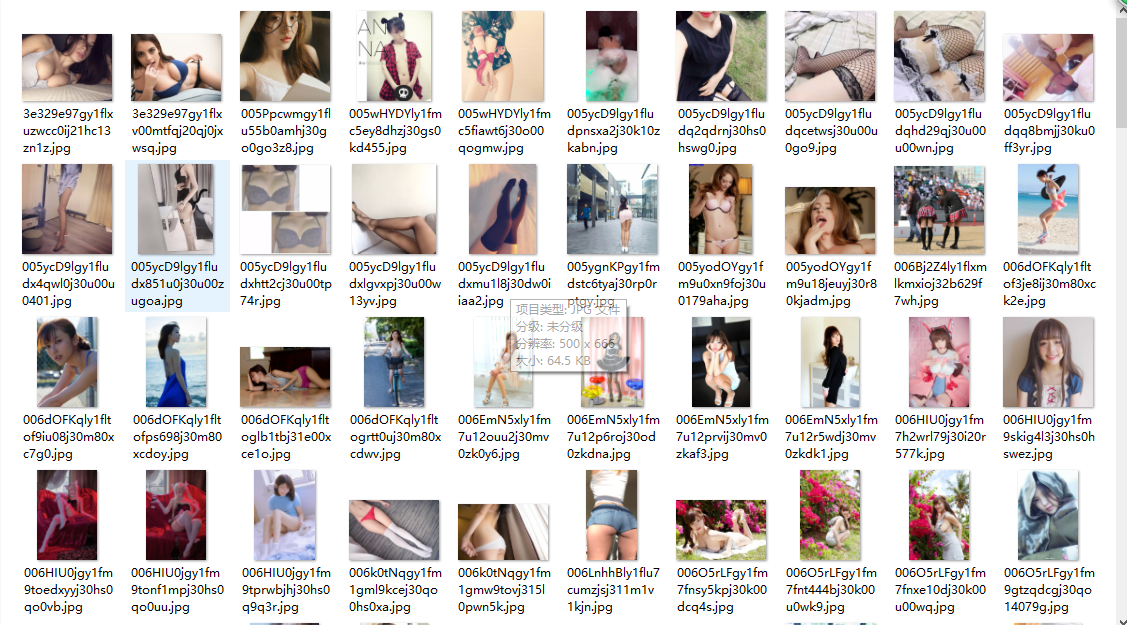
以下是代码:
import urllib.request
import os
import time
from selenium import webdriver
def getDriver():
chromedriver = 'D://chromedriver/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
return driver
def find_img(url):
driver = getDriver()
driver.get(url)
src = driver.find_elements_by_tag_name('img')
img_addrs = []
for pic in src:
filename = pic.get_attribute('src').split('.')[-1]
if filename == 'jpg':
img_addrs.append(pic.get_attribute('src'))
print(pic.get_attribute('src'))
driver.quit()
return img_addrs
#保存图片
def save_imgs(img_addrss):
for each in img_addrss:
print('download images:%s'%each)
filename = each.split('/')[-1]
urllib.request.urlretrieve(each,filename)
print('保存了图片'+filename)
#下载图片
#folder 文件夹前缀名
#pages 爬多少页的资源,默认只爬10页
def download_mm(folder='woman',pages=10):
folder+= str(time.time())
#创建文件夹
os.mkdir(folder)
#将脚本的工作环境移动到创建的文件夹下
os.chdir(folder)
page_num = int(get_page())
for i in range(pages):
page_num -= i
#建立新的爬虫页
page_url = 'http://jiandan.net/ooxx/'+'page-'+str(page_num-1)+'#comments'
print(page_url)
#爬完当前页面下的所有图片
img_addrs = find_img(page_url)
#将爬到的页面保存起来
save_imgs(img_addrs)
def get_page():
driver = getDriver()
driver.get('http://jandan.net/ooxx/page-378#comments')
page_num = driver.find_element_by_class_name('current-comment-page').text
page_true_num = page_num[1:4]
print(page_true_num)
driver.quit()
return page_true_num
if __name__ == '__main__':
download_mm()
!!!!!!!!!!!!郑重提示!由于图片太香艳,而且程序运行过程中,会自动打开浏览器,所以。。如果你是上班族的话,请小心操作!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号