PostgreSQL TOAST技术,了解一下?
PostgreSQL TOAST技术,了解一下?
Whoami:5年+金融、政府、医疗领域工作经验的DBA
Certificate:OCP、PCP
Skill:Oracle、Mysql、PostgreSQL
Platform:CSDN、墨天伦、公众号(呆呆的私房菜)
业务范围:数据库安装部署、日常维护、主备切换、故障处理、性能优化、技术培训等。
需要的伙伴或者商业合作请移步 公众号【呆呆的私房菜】获取联系方式。
01 Toast概述
Toast(The OverSized Attribute Storage Technique)是超长字段在PostgreSQL的一种存储方式。它会把大字段值压缩或者分散成多个物理行来存储,而对于用户来说是完全透明的。
02 Toast存储方式
PostgreSQL的部分类型数据支持toast;
支持toast的数据类型应当是可变长度的;
表中任何一个字段有toast,这个表都会有一个相关联的toast表,oid存储在pg_class.reltoastrelid里边;
超出的数值将会被分割成chunks,并且最多toast_max_chunk_size个bytes(缺省是2KB)
当存储的行数据超出toast_tuple_threshold值(通常是2KB),就会触发toast存储。
toast将会压缩或者移动字段值直到超出部分比toast_tuple_target值小(通常是2KB)。
03 Toast策略
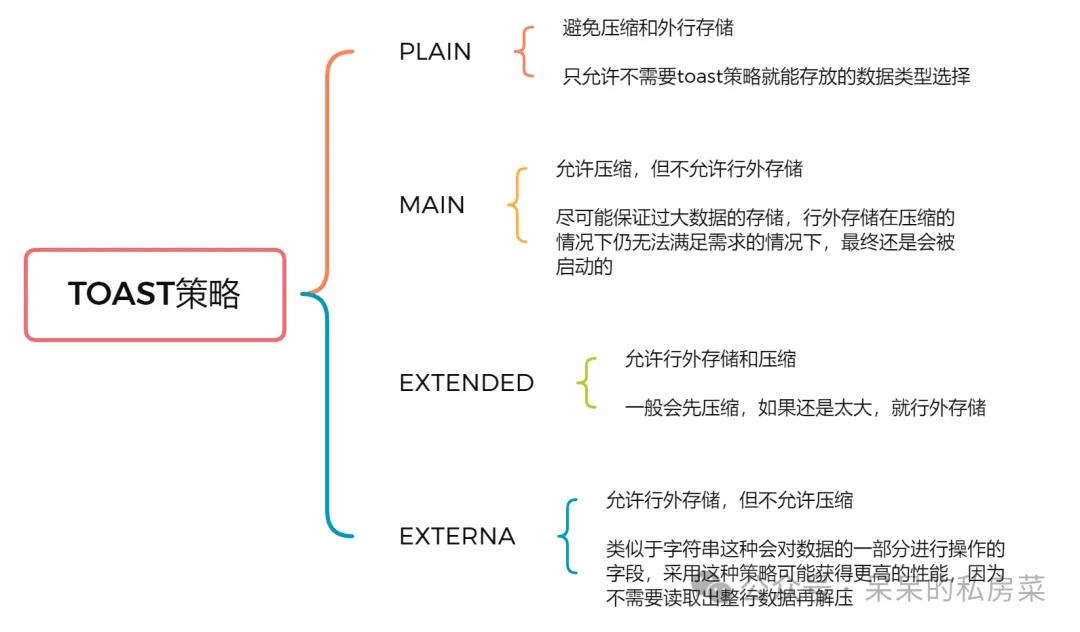
04 Toast表的计算
计算一个表的大小时要注意统计Toast的大小,因为对超长字段存储时,在基础表上可能只存了20%,另外的数据都存储到Toast里边去了,计算大小的时候要结合看。
索引也是一样的道理,对于表中有extended或者externa类型的都会创建Toast表,两者的关联是通过pg_class里的oid去关联的。
05 Toast表的优劣
**优点:
**1. 可以存储超长超大字段,避免之前不能直接存储的限制;
2. 物理上与普通表是分离的,检索查询时不检索该字段会极大加快速度;
3. 更新普通表时,该表的Toast数据没有被更新时,不用去更新Toast表。
**缺点:
**
- 索引问题,不建议在大字段上创建索引,如果必要的情况下可以创建全文索引;
- 更新慢,大字段的更新速度会很慢,当然这也是DB的通病。
06 Toast表案例
假设有一个documents表,其中包含一个大字段content用于存储文档的全文内容。这个字段可能会包含非常大的数据,如果直接存储在表中,可能会导致行变得非常大,影响数据库的性能。此时Toast技术的优势就展示出来了。
## 创建表
testdb=# CREATE TABLE document (
id SERIAL PRIMARY KEY,
title VARCHAR(255),
content TEXT
);
CREATE TABLE
testdb=# \d document;
Table "public.document"
Column | Type | Collation | Nullable | Default
---------+------------------------+-----------+----------+--------------------------------------
id | integer | | not null | nextval('document_id_seq'::regclass)
title | character varying(255) | | |
content | text | | |
Indexes:
"document_pkey" PRIMARY KEY, btree (id)
## 数据块是8k数据库,toast默认触发阈值是2048个字节。
## 这意味着字段要超过2048字节,它就会被存储到toast表中。
testdb=# show block_size;
block_size
------------
8192
(1 row)
## 查看toast信息,可以看到自动创建了一个toast表
testdb=# select oid, relname,relfilenode,reltoastrelid from pg_class where relname like '%documents';
oid | relname | relfilenode | reltoastrelid
-------+-----------+-------------+---------------
41252 | documents | 41252 | 41256
(1 row)
testdb=# select relname from pg_class where oid = 41256;
relname
----------------
pg_toast_41252
(1 row)
## toast表数据是空的
testdb=# select * from pg_toast.pg_toast_41252;
chunk_id | chunk_seq | chunk_data
----------+-----------+------------
(0 rows)
## 插入一条数据
testdb=# INSERT INTO document (title, content) VALUES ('Small Text', 'This is small content');
INSERT 0 1
## 还没触发toast
testdb=# select * from pg_toast.pg_toast_41252;
chunk_id | chunk_seq | chunk_data
----------+-----------+------------
(0 rows)
## 再插入一条数据,发现toast插入了两条数据
testdb=# INSERT INTO documents (title, content) VALUES ('Large Content Document', repeat('This is a very large text that should trigger TOAST storage because it is much larger than the default threshold. ', 2000));
INSERT 0 1
## chunk_id:标识toast表的oid字段
## chunk_seq:chunk的序列号,与chunk_id的组合唯一索引可以加速访问
## chunk_data:存储toast表的实际数据
testdb=# select chunk_id, chunk_seq from pg_toast.pg_toast_41252;
chunk_id | chunk_seq
----------+-----------
41264 | 0
41264 | 1
(2 rows)
## 再插入一条数据
testdb=# INSERT INTO document (title, content) VALUES ('Large Content Document', repeat('This is a very large text that should trigger TOAST storage because it is much larger than the default threshold. ', 2000));
INSERT 0 1
testdb=# select count(1) from pg_toast.pg_toast_41252;
testdb=# select chunk_id, chunk_seq from pg_toast.pg_toast_41252;
chunk_id | chunk_seq
----------+-----------
41264 | 0
41264 | 1
41265 | 0
41265 | 1
(4 rows)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号