直接代码,如有不懂请加群讨论
# *-* coding:utf-8 *-* #
import json
import requests
import pytesseract
import time
import datetime
from PIL import Image
from bs4 import BeautifulSoup
import urllib3
import random
import os
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
}
session = requests.session()
url = 'https://www.saikr.com/'
def get_index():
'''
直接访问活动页面
:return:
'''
response = session.get(url+'activity',headers=headers)
response.encoding = 'utf8'
return response.content
def get_page(res = ''):
'''
获取数据进行存储
:return:
'''
if res:
html = etree.HTML(res)
else:
html = etree.HTML(get_index())
#获取尾页数据
lastpage = html.xpath('//li[@class="last"]/a/@data-ci-pagination-page')[0]
#从第一页开始爬取
for p in range(1, int(lastpage)):
net_url = url + 'activity/' + str(p)
response = session.get(net_url, headers=headers)
response.encoding = 'utf8'
get_page(response.content)
#得到详情页数据
items = html.xpath('//div[@id="activeLoadContentBox"]/ul/li')
title = ''
for item in items:
at_url = item.xpath('./div/h3/a/@href')[0]
at_title = item.xpath('./div/h3/a/text()')[0]
title = at_title.strip() + '\n'
get_content(at_url,title)
def get_content(u,t):
res = session.get(u, headers=headers)
html = etree.HTML(res.content)
items = html.xpath('//div[@class="new-active-box"]/ul/li')
result = t
for item in items:
title = item.xpath('./span/text()')[0]
cont = item.xpath('./div/p[1]/text()')
#结束时间
cont2 = item.xpath('./div/p[2]/text()')
if cont2:
endtime = cont2[0]
else:
endtime = ''
if cont:
conts = cont
else:
conts = item.xpath('./p/text()')
if conts[0].strip() == '':
conts = item.xpath('./p/span/text()')
result += title.strip() +conts[0].strip() + endtime + '\n'
print(result)
file = os.getcwd() + '/active.txt'
output = open(file, 'a')
output.write(result)
output.close()
if __name__ == '__main__':
get_page()
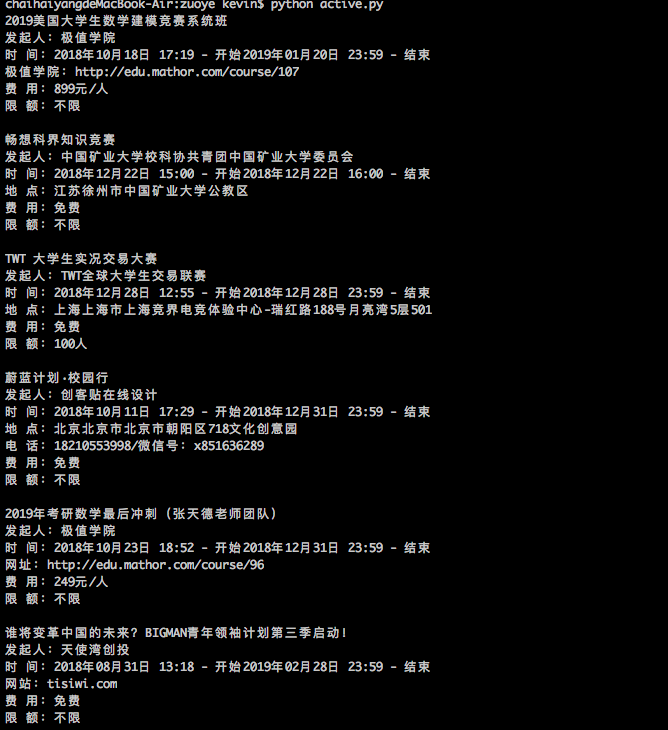
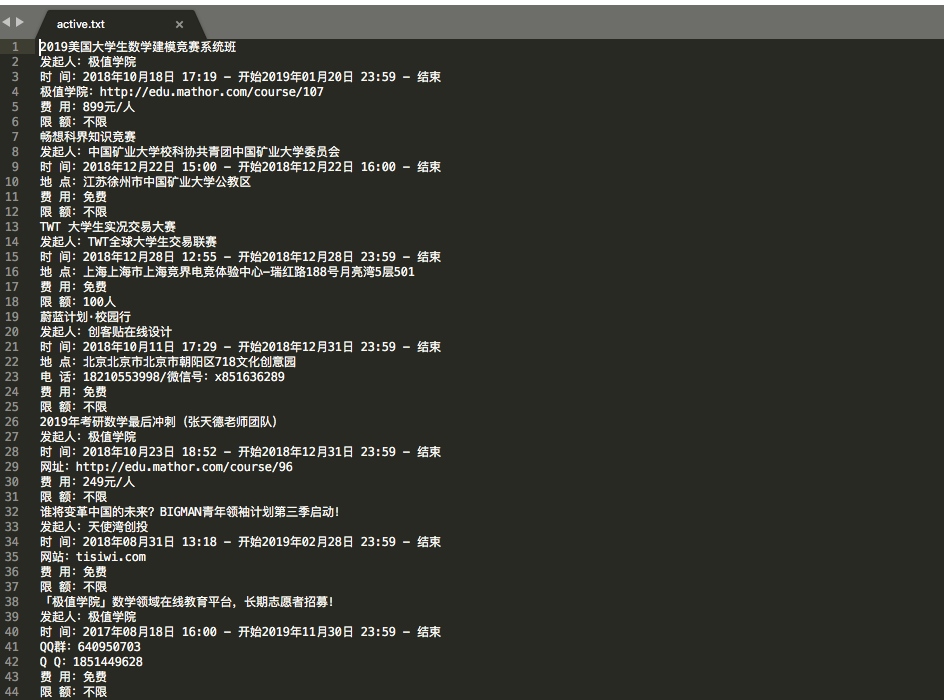
运行:




 浙公网安备 33010602011771号
浙公网安备 33010602011771号