【论文精读】Revisiting a Methodology for Efficient CNN Architectures in Profiling Attacks
摘要
这项工作对Zaid等人在TCHES(The Journal of Cryptographic Hardware and Embedded Systems)上发表的题为“分析攻击中高效CNN架构的方法论”的论文进行了批评性评论。该论文研究了CNN网络的设计,以对嵌入式设备上AES的多种实现进行侧信道分析。
在这项工作中,作者使用了Zaid等人提供的代码和公共数据集,进行了交叉验证,并对其结果进行了全面的分析。通过仔细研究Zaid等人提出的模型架构的各个元素,研究人员纠正了多种误解。
首先,通过更好地理解这些模型的内部工作原理,研究人员成功地将模型的参数数量平均减少了52%,同时保持了类似的性能水平。
其次,研究人员证明了卷积滤波器的大小与侧信道攻击中的未对齐量之间并没有严格的相关性。
第三,研究人员表明,增加滤波器的大小和卷积次数实际上可以提高网络的性能。
这项研究再次强调了科学研究中再现性和审查性的重要性。为了使读者能够重现研究结果,研究人员提供了一个在线的Python笔记本,并在GitHub上提供了额外的示例代码。
总结起来,我们的工作对Zaid等人的论文进行了批评性评论,并提出了以下贡献:
-
预处理技术:我们展示了如何用经典的预处理技术替代Zaid等人提出的第一个卷积层,从而平均降低了模型的复杂度达到52%。我们进行了大量实验并展示了各种预处理技术对模型性能的影响。
-
模型设计参数:通过实验研究了滤波器大小和卷积块数量等网络参数对性能的影响。我们证明了Zaid等人在论文中概述的设计指南并不适用于所有情况。通过纠正误解,我们提供了更加直观的推理,有助于设计通用方法。
-
再现性:通过提供Python笔记本,确保读者能够轻松复制我们概述的实验。此外,我们的实现可用于构建和改进我们的工作。
实验一 预处理
x1卷积滤波器
使用1x1卷积滤波器意味着滤波器只覆盖每个位置上的单个元素。这种操作可以降低输入数据的维度,同时仍然允许网络学习非线性变换。
1x1卷积滤波器的作用主要有以下几个方面:
- 降维:1x1卷积滤波器可以减少数据中通道或特征图的数量,而不改变它们的空间维度。这样做有助于降低计算复杂度和模型大小,同时保留重要信息。
- 非线性变换:尽管滤波器的尺寸是1x1,卷积操作仍然对输入元素应用非线性激活函数。这使得网络能够学习复杂的关系并捕捉更高级的特征。
- 信息融合:在深度卷积神经网络中,可以使用1x1卷积滤波器来组合来自不同层的特征图。这有助于将不同尺度或抽象级别的信息融合在一起,实现更好的表示学习。
总之,使用1x1卷积滤波器可以灵活地处理特征图的维度,整合信息并引入非线性变换。它们是卷积神经网络有效性和表达能力的重要工具。这种技术在最先进的分类网络中被广泛应用,有时被称为"bottlenecks",用于降低中间表示的维度。
实验
验证在预处理时是否可以省略大小为1的滤波器的第一层卷积:
- 研究者对Zaid等人提出的网络以及稍作修改的版本进行了实验。他们通过移除第一个滤波器大小为1的卷积层和相应的批标准化层来验证这个假设。同时,也移除了来自激活函数的非线性效果。
- 值得注意的是,卷积块由卷积层、批标准化层和池化层组成。然而,保留了第一个平均池化层进行降维操作。
- 实验中没有对修改后的网络进行任何超参数调优,并将实验结果原样呈现。
- 对于对齐的迹线,Zaid等人使用Sklearn的MinMaxScaler函数将输入特征缩放到0到1之间。然而,在训练神经网络时,推荐的做法是将数据标准化(均值为0,方差为1)或将其缩放到-1到1之间。将输入特征缩放到0到1之间(所有输入都为正数)会降低网络收敛速度[LBO12]。
综上所述,该实验主要针对Zaid等人的网络进行了修改,并移除了第一个卷积层,然后通过不同的预处理策略来验证这个假设。实验结果表明,在对齐的迹线情况下,将输入特征标准化或缩放到-1到1之间比缩放到0到1之间更有利于网络的收敛速度。
比较了特征缩放和标准化在不同范围内的应用效果。同时,对于不对齐的迹线,还探究了基于实例的特征缩放和标准化的效果。
虽然本文只限于这些具体的预处理策略,但也提到了值得研究的组合技术,如水平标准化后再进行特征标准化,以及使用非线性转换方法,如Box-Cox变换。实
验中将数据分为训练集和验证集,采用90-10的比例进行划分,每个数据集的模型和预处理策略的组合会进行十次训练和评估,每次使用不同的划分和随机权重初始化。
表1显示了Zaid等人提出的网络和修改后的网络在实验中的可训练参数数量。我们的模型在可训练参数数量上减少了高达70.0%,同时仍然产生类似的结果。接下来,将对图1和图2中所展示的结果进行讨论,针对每个数据集进行分析。
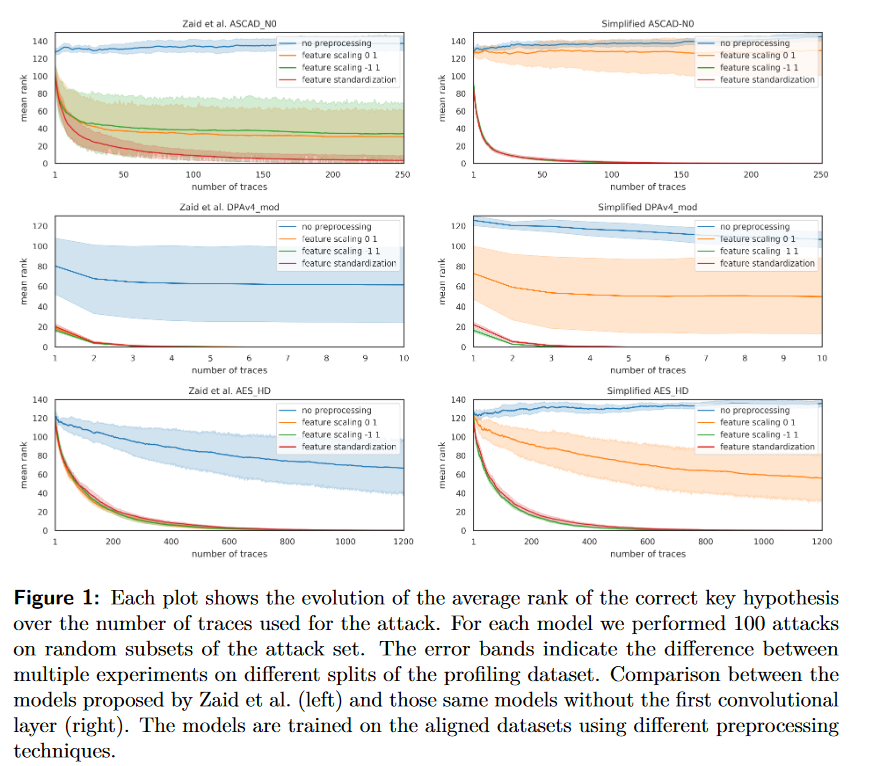
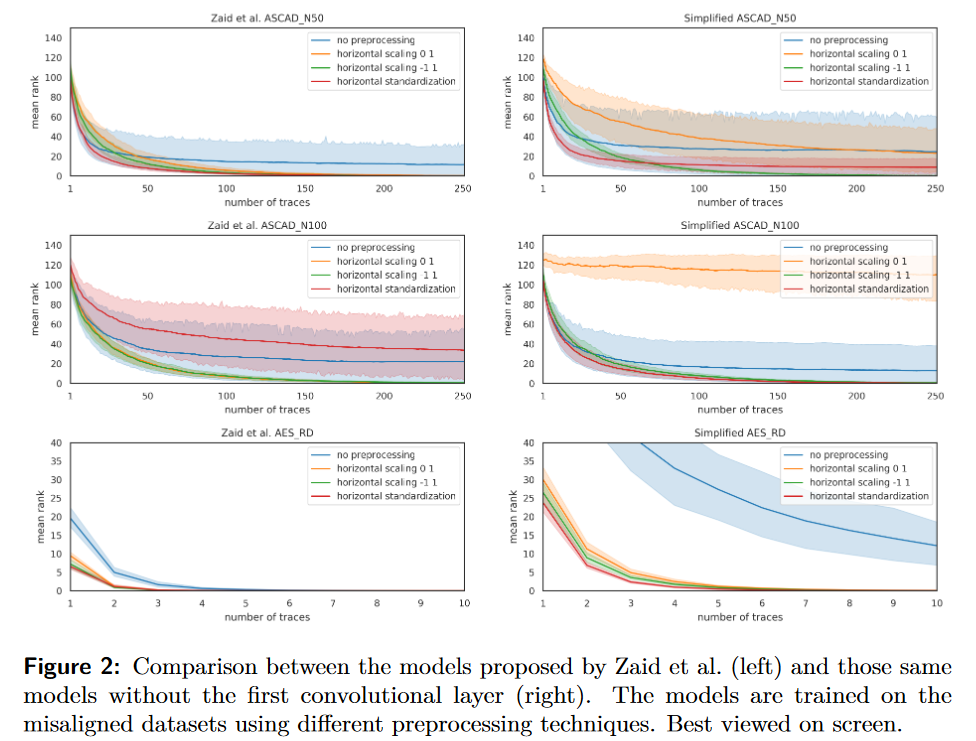
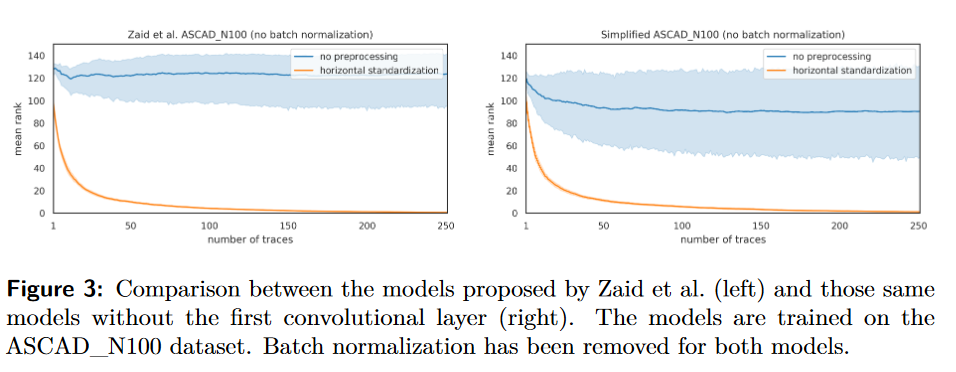
结论
本节中的实验表明,在训练模型之前对迹线进行预处理是非常重要的。我们证明了[ZBHV20]和其他许多论文中采用的预处理策略对这些数据集来说不是最佳选择。
此外,我们证明了具有大小为1的滤波器的第一个卷积块行为类似于网络内部的预处理单元,与传统的预处理技术相比,并没有明显的优势。
最后,我们的结果表明,通过使用批标准化,人们可能不必总是进行预处理就能获得良好的结果。
然而,本文中使用的数据集、训练策略和模型都受益于预处理。正如表1所示,去除第一个卷积层平均可以减少52%的网络参数。尽管按照当今的标准,原始网络已经很小,这种减少在使用更真实的包含更长迹线的数据集上将会更加显著和重要。
实验二 正确使用可视化技术
Zaid等人认为,诸如梯度可视化等技术“不适合用于解释网络的卷积部分”。
Zaid等人提出的权重可视化方法试图通过查看分类部分的第一个全连接层的权重来可视化网络如何学习相关信息。然而,这种方法无法精确定位实际输入轨迹中的兴趣点。
要获取这些样本,需要使用反向传播方法,这将引入2.3节介绍的技术。在我们的实验中,这些方法(在DeepExplain框架中实现)获得了类似或甚至更好的结果。
我们在图4中对此进行了比较。在DeepExplain提供的选项中,我们选择了第一种方法,即梯度×输入(Gradient*Input),但使用其他技术也可以获得类似的结果。
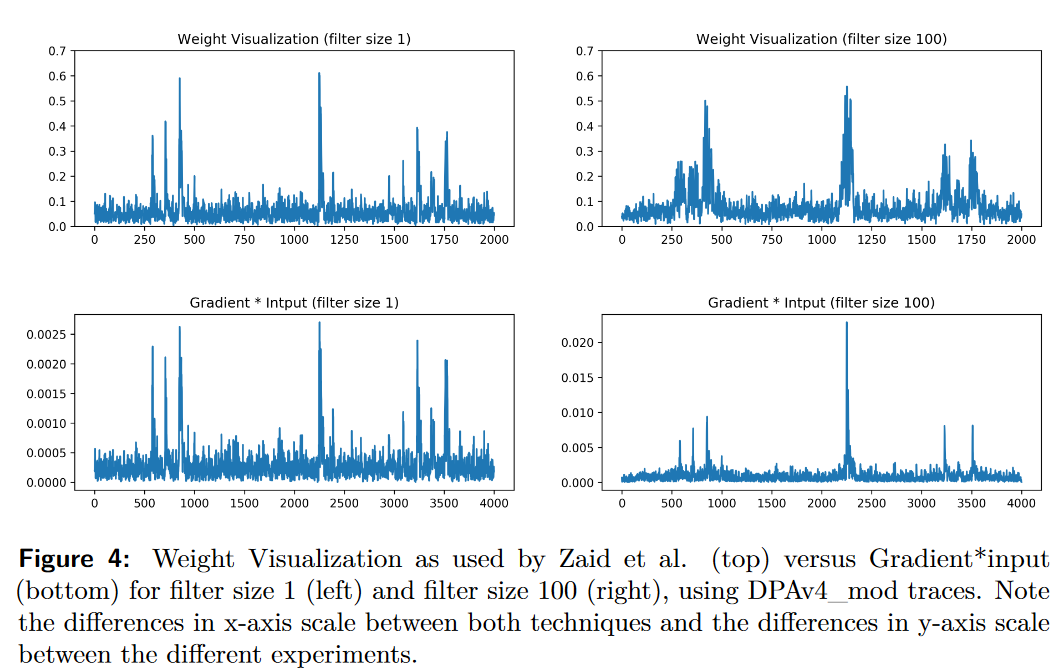
图4展示了与Zaid等人提出的DPAv4_mod数据集对应的模型的结果,该模型具有一个包含大小为1的滤波器的卷积块。左侧的图表使用完全相同的模型生成,而右侧的图表仅将滤波器大小改为100。顶部行显示了根据公式(2)定义的权重可视化结果(注意我们得到了与[ZBHV20]中相同的结果)。底部行说明了从输出开始(向后传播直到输入)应用梯度×输入(Gradient*Input)技术的结果。我们可以看到两种结果都显示出相似性,但也存在重要的区别。我们观察到的第一个区别是在应用较大的滤波器大小时可视化结果的差异。由于滤波器的大小,我们可以在权重可视化中看到相关数据分散在多个点上。另一方面,通过梯度×输入,我们可以更精确地确定兴趣点,因为表示完全回溯到输入。第二个并且最重要的区别是权重可视化的大小与输入大小不对应,这妨碍了兴趣点的精确定位。请注意,输入轨迹的长度为4000个样本。[ZBHV20]中的图15展示了同样的效果,如果中间表示被过度减小(因为池化),则权重可视化技术将无法准确地识别泄漏的输入样本。
根据[ZBHV20]中的图形可视化技术来解释结果,我们认为该论文的作者对权重可视化技术的解释是不准确的,从而导致了错误的结论。他们将这种技术作为量化网络性能的决定性因素,基于权重的大小。根据[ZBHV20]中图14的结果,Zaid等人在同一研究的第4.2节中得出结论:“如果我们想要精确定义泄漏发生的时间空间,建议尽量减小滤波器的长度以降低纠缠的风险”。在本文的图4右上方的结果中,可以观察到与[ZBHV20]中图14呈类似效果的影响,即PoI的相关性也扩散开来。
根据Zaid等人的结论,这种扩散会影响网络的性能,导致使用较大滤波器尺寸的网络表现比使用较小尺寸更差。然而,如果通过梯度×输入的结果进行分析,并遵循相同的推理,得出的结论将是相反的。
用一个直观的方式来证明这个结论可能不正确,就是评估两个模型的攻击性能,一个模型在第一个卷积块中使用大小为1的滤波器(与Zaid等人使用的相同),另一个模型使用大小为100的滤波器。
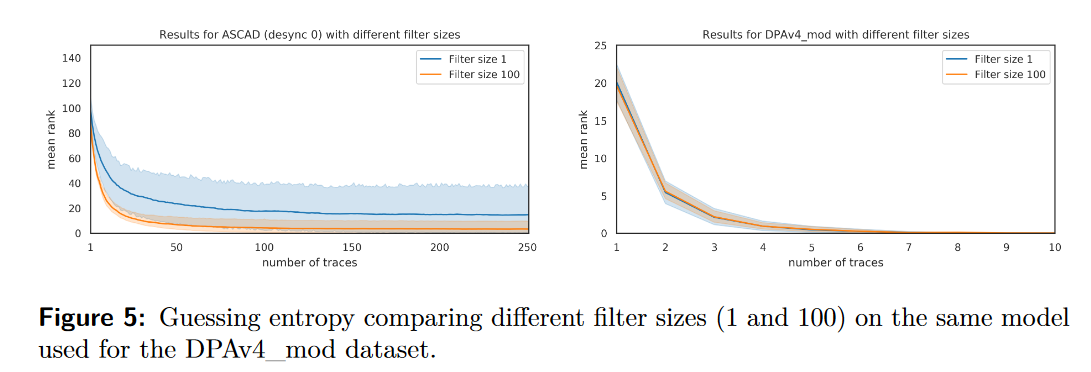
图5展示了这个实验的结果,包括DPAv4_mod数据集和ASCAD_N0数据集。根据Zaid等人的解释,滤波器大小为100的模型在攻击集上表现应该比滤波器大小为1的模型差
。然而,图5的结果表明相反的情况。确实,使用较大滤波器尺寸训练的模型并不比使用较小滤波器尺寸训练的模型性能更差。我们在第6节进一步研究了滤波器大小的影响
。根据相似的论证方式,Zaid等人在他们的论文的第4.3节中得出结论:“网络越深,对其特征检测越不自信”。
这一观点基于附录D中的图15和16,其中可以看到权重的大小随着卷积块的数量减小。我们在第6节进行了深入的研究,以证明Zaid等人的结论是错误的。
实验三 Entanglement and Filter size
在本节中,我们描述了[ZBHV20]中引入的纠缠概念,分析了其影响,并重新审视了Zaid等人从这个概念中得出的关于滤波器大小的结论。此外,我们展示了如何通过增加滤波器大小来提高网络的性能,这与[ZBHV20]的主张相反。
在[ZBHV20]中,Zaid等人引入了一个新概念,称为"纠缠"(entanglement)。他们引入这个概念是为了解释卷积滤波器的效果,该滤波器的目标是提取相关的输入样本,并说明这些提取的特征如何在网络的后续层中分布。
"纠缠"在这个上下文中的意思是,相关信息(来自输入)在多个卷积样本中共享和混合。这种效应导致PoI在多个卷积点之间水平扩散。根据[ZBHV20]的作者所说:"增加滤波器的长度会引起纠缠,减少与单个信息相关的权重,从而降低网络的置信度"。为了更精确地定位泄漏源,他们建议最小化滤波器的长度,以减小纠缠效应的影响。Zaid等人试图通过使用他们的权重可视化方法(参见[ZBHV20]的图14)来证明纠缠的相关性,以及根据他们的标准,更大的滤波器尺寸的性能更差。正如我们在前面的部分中所看到的,我们认为权重可视化方法并不能提供合适的结果来支持网络使用较长滤波器尺寸性能更差的观点。在图4的顶部图中,我们可以看到纠缠效应的影响,以及当滤波器尺寸增大时,泄漏样本在水平轴上更分散的情况。相反,从图4的底部图中的梯度×输入结果可以看出,无论使用什么滤波器尺寸,都能成功揭示实际输入跟踪中的相关关注点(Points of Interest)。此外,如图5所示,滤波器尺寸更大的模型的性能与滤波器尺寸为1的模型一样好(甚至更好)。这些例子说明并验证了一个观点,即关于纠缠减少神经网络性能的论点是有缺陷的。我们的直觉是,滤波器的目标是检测某种模式。这个目标可以通过组合多层小滤波器来实现(通常在图像分类网络中经常采用的方法),也可以通过训练更大的滤波器来实现,后者应该也能够检测到较小的模式,通过学习和微调正确的权重。这与图4的右下角图中显示的实验结果相符,无论滤波器尺寸如何,我们仍然能够准确追踪泄漏样本。我们的实验表明,在这个上下文中,纠缠问题是不存在的,并导致了错误的结论。因此,我们认为纠缠这个概念是不必要的。在接下来的章节中,我们将提供更多关于滤波器尺寸影响的实验来支持我们的观点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号