【SCA】论文:基于机器学习的侧通道分析中的偏差方差分解
reference:Bias-variance Decomposition in Machine Learning-based Side-channel Analysis
摘要:机器学习技术是剖析侧通道分析的一个强大选项。尽管如此,在许多情况下,他们的表现远未达到预期。在这种情况下,了解问题的难度和机器学习算法的行为非常重要。为此,我们不仅需要研究机器学习的性能,还需要深入了解机器学习的可解释性。使我们能够做到这一点的一个工具是偏差-方差分解,我们能够将预测误差分解为偏差、方差和噪声。使用此技术,我们可以分析各种场景,并识别问题困难的来源,以及其他测量/特征或更复杂的机器学习模型如何缓解问题。虽然这样的结果是有希望的,但仍然存在缺点,因为通常不容易将侧信道攻击的性能与机器学习分类器的性能联系起来,如偏方差分解所给出的。在本文中,我们提出了一种用于分析基于机器学习的侧信道攻击性能的新工具——猜测熵偏差——方差分解。通过它,我们能够更好地理解各种机器学习技术的性能,并了解设置的变化如何影响攻击的性能。为了验证我们的说法,我们给出了大量不同设置的实验结果。
关键词:侧信道分析,机器学习,深度学习,偏差方差分解,损失函数
一个自然的问题是,是否有技术可以让我们更好地了解机器学习的性能。虽然这些见解远不能提供一个完整的图景,但它们可以提供一些有用的结果并改进过程,从而产生更强大的攻击。此外,我们可以增加对某一机器学习算法的问题理解及其难度。
了解机器学习性能的一种众所周知且(相对)成功的技术是偏差方差分解。在那里,我们能够将机器学习算法的预测误差分解为3个部分:偏差、方差和噪声。
图1给出了偏差和方差相互作用的常见图形描述。到目前为止,在SCA社区中,偏差方差分解只引起了适度的关注。据我们所知,它被认为是分析攻击的度量[LBM15]或泄漏分析的工具[LVMS18]。虽然这两个例子都给出了有希望的结果,但我们相信偏差方差分解可以在SCA中提供更多帮助。
在本文中,我们研究了用于侧信道分析的机器学习技术的偏差方差分解。在那里,我们的结果使我们能够洞察并回答以下问题:
1)特征数量对攻击性能的影响是什么?
2) 训练样本数量对攻击性能的影响是什么?
3) 机器学习模型复杂性的影响是什么?
4) 我们可以将偏差方差分解与常见的SCA度量(如猜测熵)联系起来吗?
虽然前两个问题在相关工作中得到了部分考虑,但据我们所知,第二个问题以前从未被考虑过。
1.1贡献本文的主要贡献如下:
1.我们提供了关于特征数量、训练样本数量和机器学习模型复杂性的偏差方差分解的实验结果。
2.我们展示了均方误差函数和猜测熵之间的联系。
3.我们引入了新的分析技术,我们称之为猜测熵双方差分解。通过它,我们能够了解SCA中机器学习性能的更多细节2,以及各种实验设置如何影响攻击性能。
我们进行了详细的分析,并考虑了4个公开可用的数据集、2个泄漏模型、3个机器学习技术和3个实验设置(模型复杂性、特征数量和训练示例数量)。最后,为了促进可再现的结果,我们的代码是开源的[fs19]。
2.3 Machine Learning Methods
随机森林随机森林(RF)算法是一种集成决策树学习器[BR01]。
这里,集成分类器意味着它由许多更简单的分类器技术(决策树)组成。决策树从每个内部节点的k个属性的随机子集中选择其拆分属性。在这些随机选择的属性中进行最佳分割,并且树是在无需谨慎的情况下构建的。RF是一种随机算法,因为它有两个随机性来源:自举抽样和节点分割时的属性选择。
多层感知机多层感知机(MLP)算法是一种前馈神经网络,它将输入集映射到适当的输出集上。MLP由有向图中的多个层(至少三个)节点组成,其中每一层完全连接到下一层,网络的训练使用反向传播算法完成。第一层始终是输入层(输入是特征),最后一层是输出层(输出是类)。输入层和输出层之间的任何层都称为隐藏层。
卷积神经网络卷积神经网络(CNNs)是一种神经网络,最初设计用于二维卷积,因为它受到动物视觉皮层的生物学过程的启发[LB+95]。它们主要用于图像分类,但最近,它们被证明是音乐和语音等时间序列数据的强大分类器[ODZ+16]。从操作角度来看,神经网络类似于普通的神经网络(例如多层感知器):它们由多个层组成,每个层由神经元组成。CNN使用三种主要类型的层:卷积层、池化层和完全连接层。卷积神经网络是一个层次序列,网络的每一层都通过一个可微函数将一组激活函数转换为另一组。首先,输入保存原始特征。接下来,卷积层计算连接到输入中的局部区域的神经元的输出,每个神经元计算其权重与输入体积中连接到的小区域之间的点积。ReLU层将应用元素激活函数,例如最大(0,x)阈值为零。Max Pooling沿空间维度执行向下采样操作。最后,完全连接的层计算隐藏激活或类分数。批量标准化用于在使用运行平均值和标准偏差应用标准缩放后通过调整和缩放激活来标准化输入层。
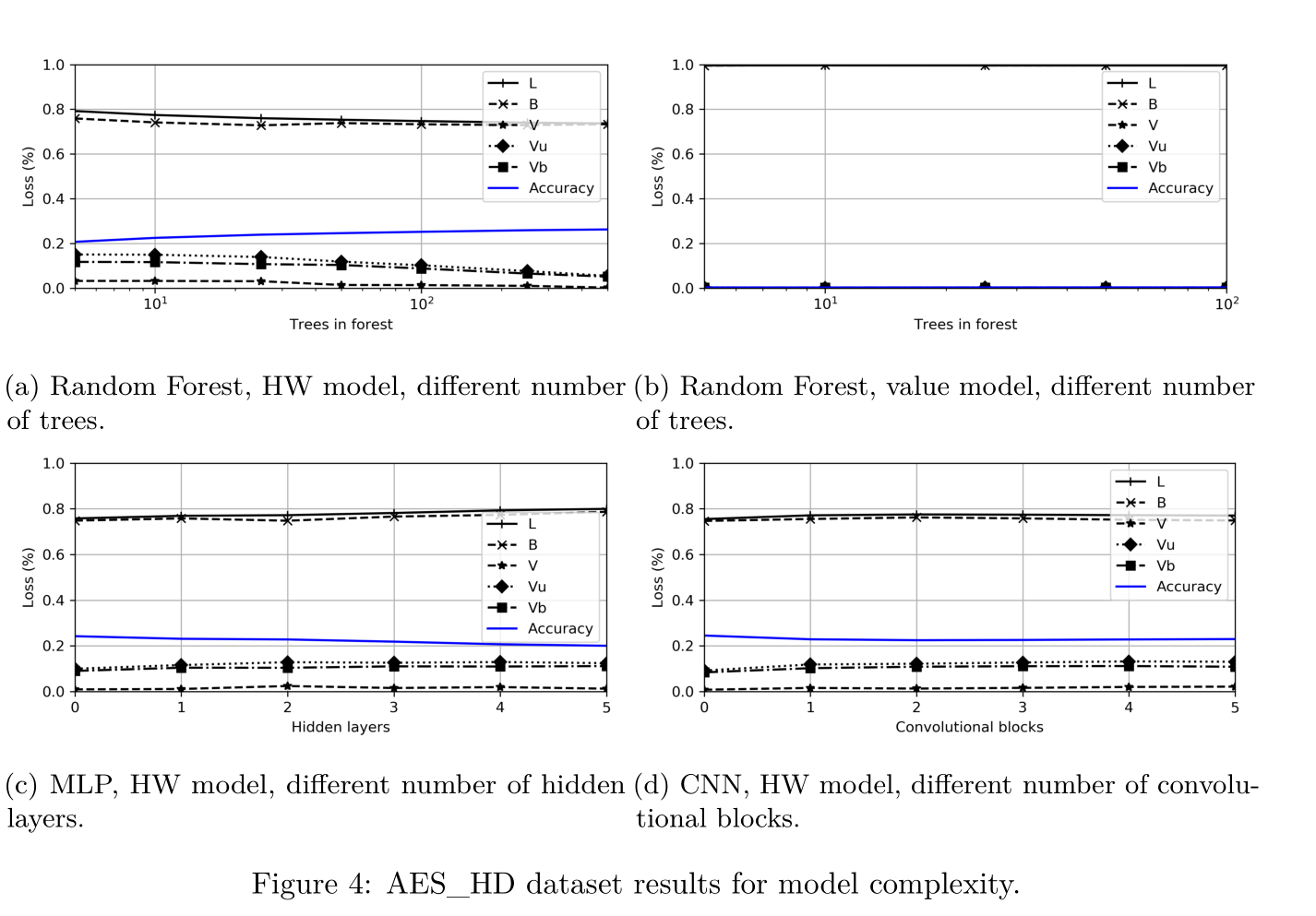
about the datasets( 4 datasets)
1 measurementswith low noise :DPAcontest v4
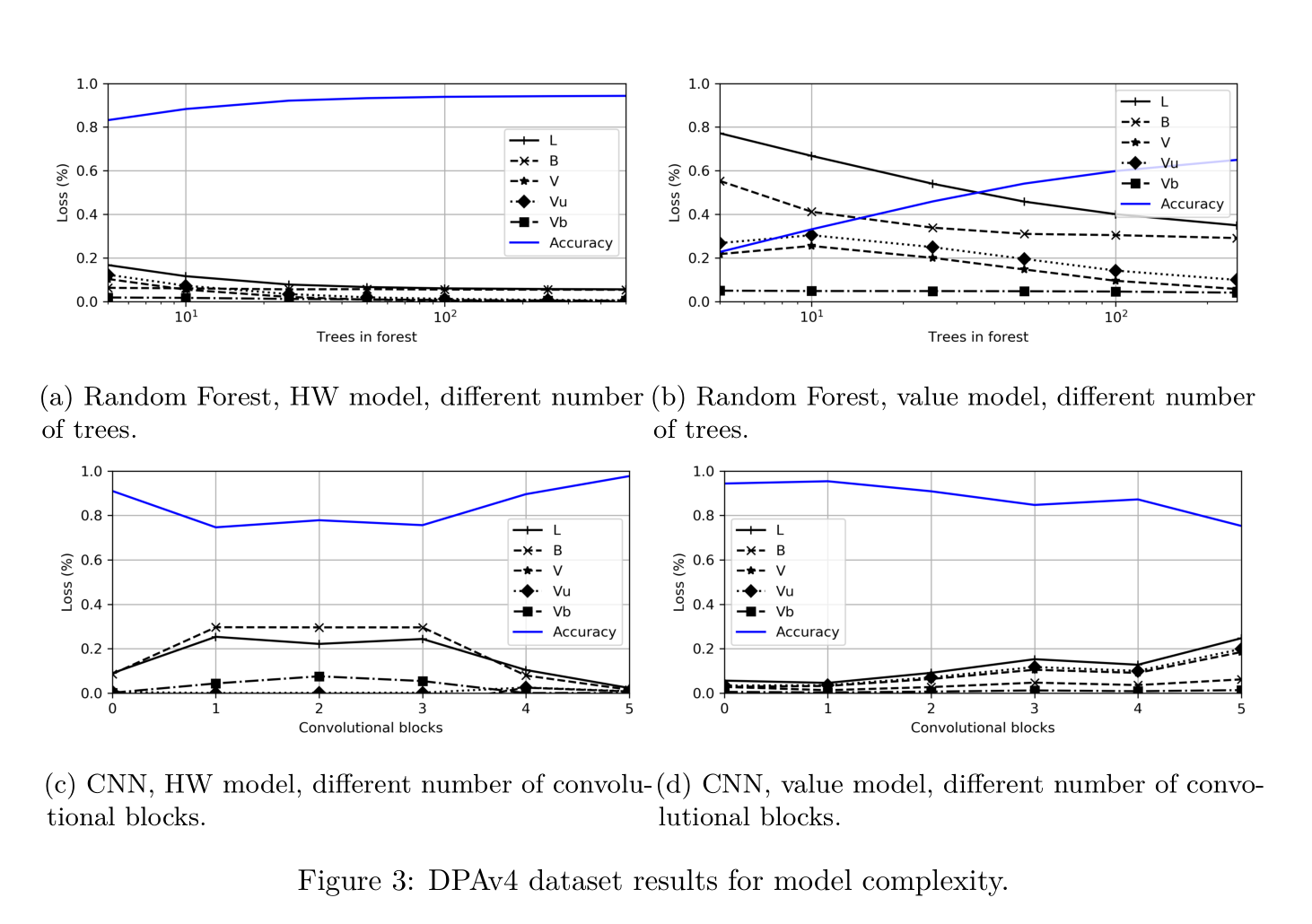
2 measurements with high noise:Unprotected AES-128 on FPGA (AES_HD)
3 measurements protected with a random delay countermeasure:Random Delay Countermeasure (AES_RD)
4 measurements protected with a masking countermeasure:ASCAD

 浙公网安备 33010602011771号
浙公网安备 33010602011771号