【SCA】评估指标
在实际的分析攻击中,单条功耗曲线正确分类的评估指标并不能完全表征机器学习模型攻击性能的优劣,往往需要多条功耗曲线才能恢复出正确密钥。
例如,在功耗曲线的分类结果中,若正确密钥在猜测密钥中排名第二,那么分类准确率为 0。但当使用猜测熵指标时,对多条功耗曲线的所有猜测密钥的概率对数化后进行累加,可能仅仅需要数条功耗曲线即可恢复出正确密钥。因此,成功率和猜测熵等指标在实际攻击中能够更好地表征基于机器学习的功耗分析的攻击性能。
1.分类准确率(Accuracy):
不同明文 pi 和相同密钥 k∗p的 Q 条功耗曲线可以表示为:
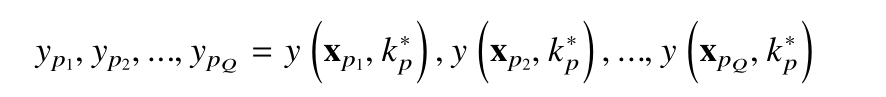
式中,y ∈ { c1 ,c2 ,...,c|C|} ,|C| 是需要分类的数目。
第 i 条功耗曲线输出的概率向量为:
![]()

输出的概率向量 probi 中最大值对应的类别即第 i 条功耗曲线的预测类别:
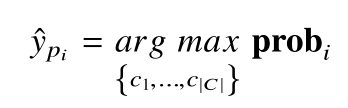
分类准确率定义为:
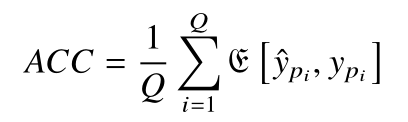
式中 E [·,·] 表示相等则计算加 1,否则不变。ACC 独立地考虑功耗曲线预测概率最大的类别,没有考虑多条功耗曲线预测概率间的关联。
2.成功率 (Success Rate, SR)
假设猜测密钥 k 的所有可能值为 1,2,...., |K|,中间值ci = y (pi,k)。为了计算 Q 条功耗曲线对每个猜测密钥 k 的可能性,对输出概率取对数后累加,即对于 Q 条功耗曲线计算密钥 k 的对数似然概率:
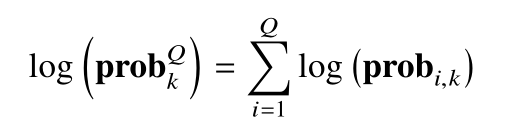
那么,Q 条功耗曲线的正确密钥为:
![]()
执行 N 次攻击实验后的成功率 (Success Rate, SR) 经验值定义为 :
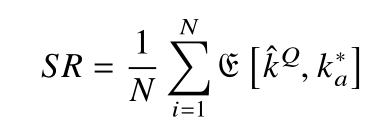
在 Q 条功耗曲线中,猜测密钥 k 为正确密钥的概率向量为 log(probkQ),将猜测密钥按照概率大小排序,得到猜测密钥向量 g =[ g1 ,g2 ,...,g|K|] 。其中,g1为正确密钥的概率最大,g|K| 则对应着正确密钥可能性最小的猜测密钥。成功率为在 N 次实验中猜测密钥 k 等于正确密钥 k∗ 的平均经验概率,表征了模型对功耗曲线预测正确密钥的概率。
3.猜测熵 (Guessing Entropy, GE)
猜测熵定义为在对 Q 条功耗曲线的攻击中,重复执行 N 次实验密钥猜测向量 g 中正确密钥k∗ 的平均秩 (Mean Ranks)。更准确地说,GE 指标表征了得到正确密钥 k∗ 所需要进行功耗分析攻击的平均次数。
4.rank
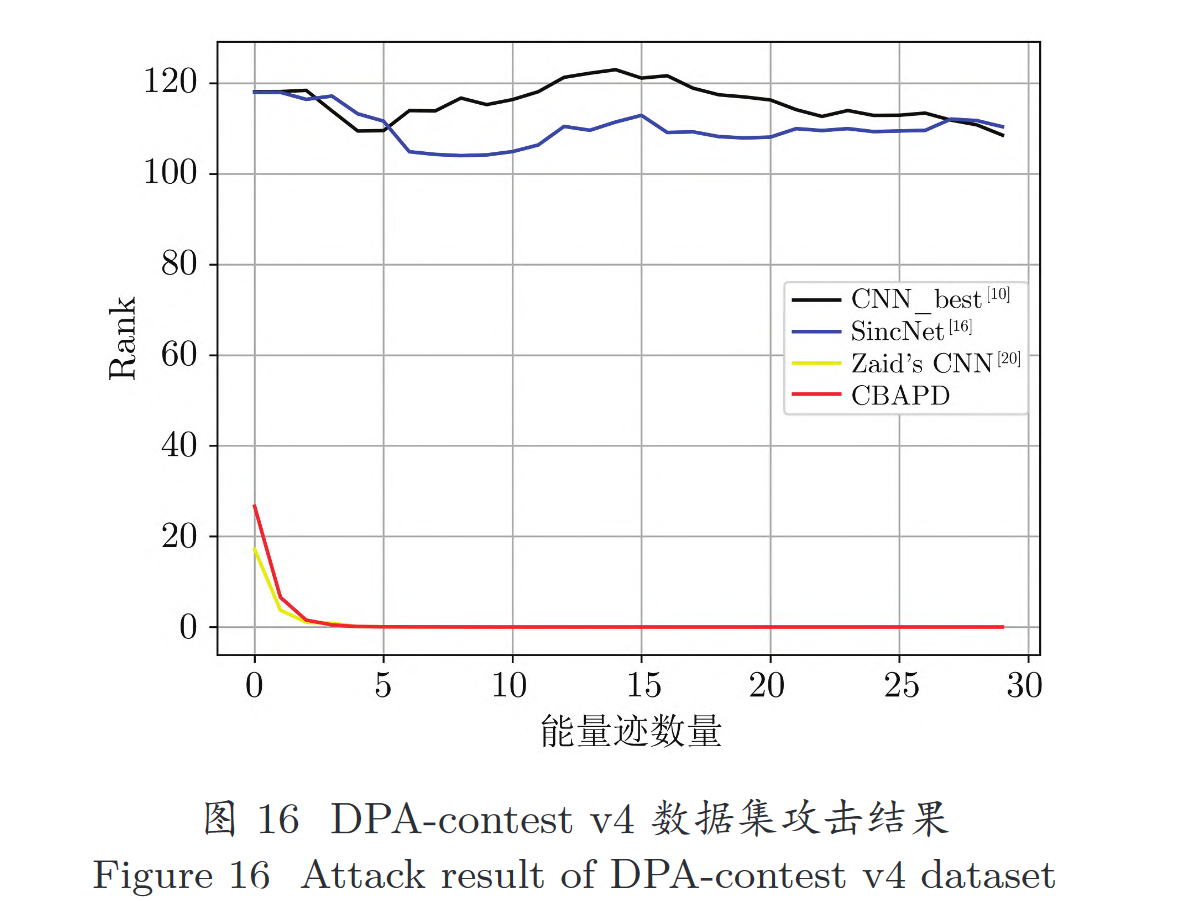
rank 是侧信道领域中最常用的评价指标, 它代表的是正确密钥在所有可能密钥中的排序, 通常会随着攻击时所使用的能量迹条数的增加而逐渐降低。 当 rank 值降低为 0 时, 表示深度学习模型将正确 密钥排到了所有可能密钥的第一位, 即此时模型已经成功找到了正确密钥. 本文的目标是构建一个模型, 使得 rank 值降到 0 并保持稳定时使用的能量迹尽可能少.
小知识点:
1.对数似然估计函数
参数估计中有一类方法叫做“最大似然估计”,因为涉及到的估计函数往往是是指数型,取对数后不影响它的单调性但会让计算过程变得简单,所以就采用了似然函数的对数,称“对数似然函数”。
最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
2.平均秩
平均秩次即为将数据从小到大排序并编号之后序号的平均数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号