MySQL 的 行锁、间隙锁
转载 https://mp.weixin.qq.com/s/7e1h5k9hIcc9KFHt84ePGw
今天跟大家聊一聊 MySQL 的事务隔离,并通过一些实验做了些总结。光说不练,假把式,没有经过实践就没有话语权
我们都知道数据库有四种隔离级别, 分别是:
读未提交 (READ UNCOMMITTED)
读已提交 (READ COMMITTED)
可重复读 (REPEATABLE READ)
串行化 (SERIALIZABLE)

实验前的准备工作
1、 基础环境
当前数据库版本, 原文为 8.0.27, 此处使用 5.7.22
select version();
5.7.22
当前的事务隔离级别:
show variables like 'transaction_isolation' transaction_isolation | REPEATABLE-READ
2、 创建个人收支表,并对 income 字段创建索引, expend 字段没有索引
CREATE TABLE `person` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键', `income` bigint(20) NOT NULL COMMENT '收入', `expend` bigint(20) NOT NULL COMMENT '支出', PRIMARY KEY (`id`), KEY `idx_income` (`income`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='个人收支表';
3、 初始化表数据, 插入 5条记录
insert into person values(100,1000,1000); insert into person values(200,2000,2000); insert into person values(300,3000,3000); insert into person values(400,4000,4000); insert into person values(500,5000,5000);
实验一、 事务A、 B 的条件字段没有索引
实验过程
为了便于描述,我们定义时间轴坐标, 用 T1, T2,T3 ... 表示当前时刻
T1: 事务A 开启事务, 并执行 select * from person where expend = 4000 for update;
由于 expend 字段没有索引,需要扫描全表。
此时加的锁事所有记录的行锁和他们之间的间隙锁, 也称为 next-key lock, 前开后闭区间。 分别是 (-∞,100]、(100,200]、(200,300]、(300,400]、(400,500]、(500, +supremum]。
T2: 事务B 开启事务, 执行插入语句 insert into person values (401, 4001, 4001);
此时一直被阻塞住, 因为没有获得锁。
面对这种情况,有两种选择, 一种是等到事务A结束(提交或回滚); 另一种等待事务锁超时。
接着这个话题,我们稍微扩展介绍下锁超时:
MySQL 数据库采用 InnoDB 模式, 默认参数 innodb_lock_wait_timeout 设置锁等待的时间是 50s, 一旦数据库超过这个时间就会报错。
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
当然我们也可以通过命令来查看、修改这个超时时间。
# 查看超时时间 show global variables like 'innodb_lock_wait_timeout' innodb_lock_wait_timeout | 50 #修改时间 set global innodb_lock_wait_timeout=120;
T3: 事务A , 执行 commit 操作, 提交事务
T4: 事务B, 插入一条记录,insert into person valus (401, 4001,4001);
操作成功, 此时 select * from person; 可以查看到新插入的记录。
实验二、 事务 A、 B 的条件字段有创建索引
T1: 事务A, 开启事务, 并执行 select * from person where incom = 3000 for update;
命中记录且 income 有索引, 此时的加锁区间是 income =3000 的行记录以及与下一个值 4000 质检的空隙 (行锁 + 间隙锁), 也就是 [3000, 4000]
T2: 事务B,开始事务,执行 insert into person values(301, 3001, 3001);
没有抢到锁,线程被阻塞住,知道事务A 提交事务并释放锁
实验三、 自动识别死锁
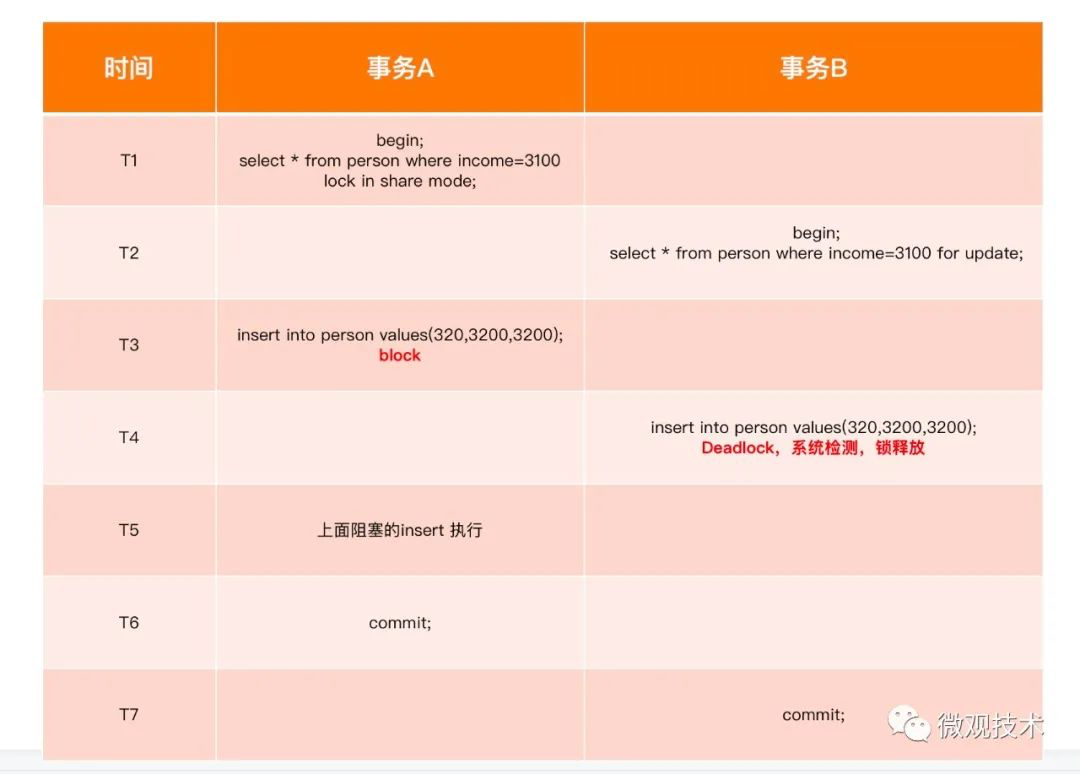
特别说明:
T3 : 事务 A 执行 insert 操作,被事务B 拦截住了
T4: 同理,事务B 执行 insert 操作,被事务A 拦截了。 这里被系统自动检测到, 抛出异常。 将事务B 持有的锁释放掉,并重启事务
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
T5: 事务A 在 T3 时刻的insert 可以继续操作
实验四、 更新记录锁保护
1、事务A在执行后 update person set income = 111 where income = 3000; 开启了锁保护
2、这时,事务B 在执行 insert into person values (307, 3000, 3000) 或者 update person set income = 3000 where id = 100 都会重新去抢夺锁, 从而保证安全。
知识小结:
1) 对于事务,binlog 日志是在 commit 提交时才生成的。
2)行锁 与间隙锁有很大区别。
行锁: 如果事务A 对 id=1 添加行锁,事务B 则无法对 id=1 添加行锁
间隙锁: 如果 select ... from 表名 where id=6 for update, 事务A 和 事务B 都可以对 (5, 12) 添加间隙锁, 间隙锁是开区间。
3)行锁和间隙锁 合称 next-key lock, 每个 next-key lock 都是 前开后闭区间
4)只有在可重复读的隔离级别下,才会有间隙锁。
5)读提交级别没有间隙锁, 只有行锁, 但是如何保证一个间隙操作产生的 binlog 对著丛数据同步产生影响呢? 我们需要把 binlog 的格式设置为 row.
其本质就是,将模糊操作改成了针对具体主键 id 行操作
# 初始语句 delete from order where c = 10 #转换后语句 delete from order where id = 10
6) 大部分公司的数据库隔离级别都是 读提交隔离级别加 binlog_format = row 的组合
7) 大多数数据库的默认级别就是读提交(read committed), 比如 SQL Server 、 Oracle 。
MySQL 的默认级别是 可重复读(Repeatable Read)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号