
CatBoost 使用
一些有用的变量,比如省份或者是货物的编号等,涵盖这比较多信息,我们就可以使用CatBoost ,下面主要讲述一下CatBoost 的用法
一、使用CatBoost 内置数据。
首先导入数据
import pandas as pd
import catboost
print(catboost.__version__) #0.26.1
from catboost import CatBoostClassifier
from catboost import datasets
train_df, test_df = datasets.amazon() # nice datasets with categorical features only :D
train_df.shape, test_df.shape #((32769, 10), (58921, 10))
tmp = pd.DataFrame()
tmp['英文名称'] = ['ACTION', 'RESOURCE', 'MGR_ID', 'ROLE_ROLLUP_1', 'ROLE_ROLLUP_2',
'ROLE_DEPTNAME', 'ROLE_TITLE', 'ROLE_FAMILY_DESC', 'ROLE_FAMILY',
'ROLE_CODE']
tmp['中文名称'] = ['操作','资源','经理标识','角色汇总1 ','角色汇总2 ', '角色_部门名称','角色_职位','角色_家庭_DESC ','角色_家庭', '角色代码']
字段如下:

查看数据
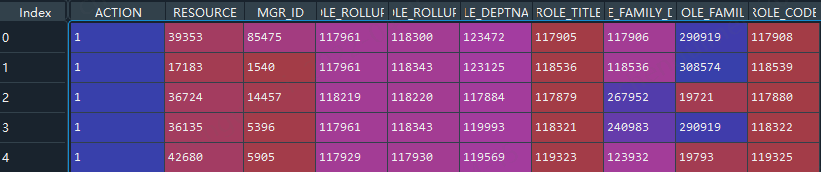
总体来说,ACTION 是target, 其余的变量即是看着都是一些数据,但是这些都是编号,也就是类别型数据,下面看看这些类别型数据有多少种类别

这些变量的类别还是很多的,如果做独热编码,将会引起维度奔溃。
二、开始构造模型。
首先划分训练集测试集
y = train_df['ACTION'] X = train_df.drop(columns='ACTION') # or X = train_df.drop('ACTION', axis=1) X_test = test_df.drop(columns='id') SEED = 1 from sklearn.model_selection import train_test_split X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.25, random_state=SEED)
指定类别型变量
cat_features = list(range(X.shape[1])) print(cat_features) #[0, 1, 2, 3, 4, 5, 6, 7, 8]
开始训练
%%time params = {'loss_function':'Logloss', 'eval_metric':'AUC', 'cat_features': cat_features, 'early_stopping_rounds': 200, 'verbose': 200, 'random_seed': SEED } cbc_2 = CatBoostClassifier(**params) cbc_2.fit(X_train, y_train, eval_set=(X_valid, y_valid), use_best_model=True, plot=True );
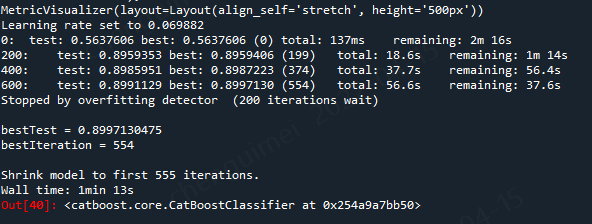
尝试一下cat_features 不适用位置索引,而是使用列名
cat_features = list(X.columns) %%time params = {'loss_function':'Logloss', 'eval_metric':'AUC', 'cat_features': cat_features, 'early_stopping_rounds': 200, 'verbose': 200, 'random_seed': SEED } cbc_2 = CatBoostClassifier(**params) cbc_2.fit(X_train, y_train, eval_set=(X_valid, y_valid), use_best_model=True, plot=True );
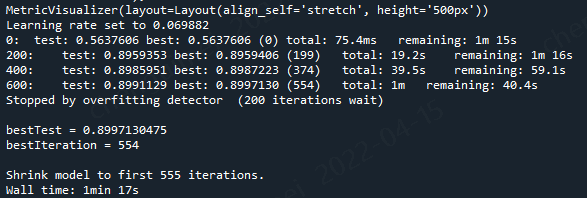
但是,但是,有些版本的cat_features 是不能使用列名训练,具体原因还未知。
https://www.kaggle.com/code/mitribunskiy/tutorial-catboost-overview

 浙公网安备 33010602011771号
浙公网安备 33010602011771号