
机器学习模型偏差与拒绝推断的Python实现
幸存者偏差
风险分析的本质是使用部分样本分布估计总体分布。在风险建模的过程中,普遍存在着幸存者偏差(Survivorship Bias)。其含义为,使用局部样本代替总体样本时,局部样本无法充分表征总体样本的分布信息,从而得到错误的总体估计
在风控架构体系中,多次涉及样本被拒绝或客户流失等问题。由于风险分析得到的结果认为部分样本的预估表现较差,因此该部分样本无法获取有效的贷后信息,即无法参与未来的模型训练。缺少该部分低分人群的信息,对全局样本表示模型的影响非常大。因为当模型经过多次迭代后,其重要特征可能被逐渐弱化,甚至呈现出与原模型完全相反的负样本分布趋势。因此需要使用相应手段进行处理。
拒绝推断(Reject Inference)
是一种对拒绝用户进行推理归纳,从而得到该部分样本标签分布的方法。常见的拒绝推断方法分为三种:数据验证、标签分裂、数据推断。本章分别对这三种方法进行介绍。
一、数据验证
数据验证,又称为下探,即从拒绝样本中选取部分样本进行放款。以获得该部分样本的真实标签,从而带入评分卡模型进行监督学习。数据验证是最有效且实施起来非常简单的一种拒绝推断方法。通常为获取较为丰富的拒绝样本标签,将当前模型打分低于通过阈值的客群,按照预测分值排序后,等频划分为10箱。然后从中分别抽取部分拒绝样本进行放款实验。
数据验证的缺点也非常明显。首先,数据验证本身是一个需要一定周期才能得到结果的方法。为将验证样本用于后续模型建模中,数据验证方案需要提前整个贷款周期,再加上逾期观察周期,预先进行实施。其次,拒绝样本中的负样本占比明显高于通过样本,因此该验证方法会对平台造成一定程度上的收益损失。获取该部分样本的信息,对未来模型的表现有极大帮助。因此需要在短期收益与长期风险控制中选择一个平衡点。
二、标签 (y) 分裂
通常评分卡模型的标签定义方式较为统一,如历史最大逾期天数等。标签分裂(Label Split)方法期望将标签定义方法,拆分为多个和原始标签定义方法强相关的子方法。常见的标签分类方法包括如下两类。
同生表现(Cohort Performance):利用当前产品的拒绝原因、平台其他产品线的贷后表现,或其余机构的标注信息定义拒绝样本的伪标签。如将征信数据标记为黑的样本定义为负样本,或将信审人员审批结果作为真实负标签使用,又或者利用其历史表现判断该用户是否为负样本。其缺点有二:第一,不同平台对于标签的定义有差异,因此外部数据在很多情况下无法直接用于拒绝样本的伪标签定义;第二,平台其余产品的贷后表现较容易获得,而外部数据获取的成本较高,并且需要考虑数据的泄露问题及数据交互的合规性。
多规则交叉(Multiple Rule Cross):由于规则制定通常使用IV较高的变量,其对负样本的挑选精准度较高。然而利用单规则阈值对样本进行的标记与模型低分直接标记无本质区别,因此通常使用多条关键规则进行交叉组合。将同时命中多条规则的用户标记为负样本。通常规则拒绝样本对模型训练的帮助较小,原因是该类样本在前置规则中被拒绝,均无法参与后续模型评分。对于申请评分卡模型来说,规则拒绝样本可以从整体样本空间中剔除。然而规则也非一成不变,如果不使用拒绝推断方法进行标注,在后续的规则迭代中同样存在偏差问题。
标签分裂的用途较广,本质上是一种基于业务思想的方法。在实际使用中,限制条件也较多。相较之下,基于数据的推断方法普适性更强,下面就来介绍几种基于数据的拒绝推断方法。
三、数据推断
事实上,从业者常说的拒绝推断(Inference methods),通常是指通过数据分析方法修正模型的参数估计偏差。拒绝推断的主要意义在于,希望修正建模样本和实际全量样本之间的差异,本质上是为了降低模型参数估计的偏差。
拒绝推断场景下有如下3个概念。
已知好坏标签(Know Good Bad,KGB)样本:准入模型允许通过的样本集,已知标签。由KGB样本训练的模型又叫KGB模型。
未知标签(Inferred Good Bad,IGB)拒绝样本:准入模型拒绝的样本集,未知标签。由于IGB样本没有标签,通常不会用于训练模型。在部分方法中可能会生成伪标签,从而参与建模过程。
全量(All Good Bad,AGB)样本:包含KGB和IGB两部分的全量样本集。由该部分数据训练得到的模型又称AGB模型。请牢记这三个概念,接下来的内容中会反复提到它们。下面来看一下常用的数据推断方法。
a.硬截断法
一种常见的思路是,直接使用KGB模型在拒绝样本上做预测,并将低分样本(如分数最低的20%样本)认为是负样本,带入模型进行估计,其余拒绝样本全部视为灰色样本,不予考虑。这种推断方法就叫作硬截断法(Hard Cutoff)。硬截断法假设“逾期”与“放款”之间相互独立。其示意图如图所示。
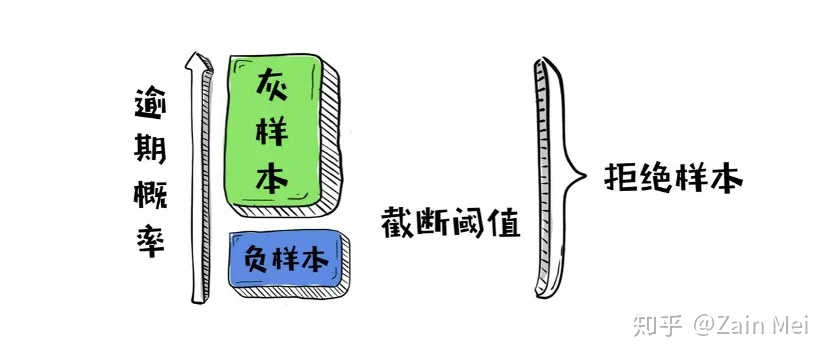
利用KGB模型进行打分,按照逾期概率降序排列,选择截断点( cut-off)进行截断后,仅将截断点以下的蓝色部分作为负样本带入模型进行学习,从而修正模型的偏差。
接下来通过一个申请评分卡的例子,看看如何在Python中实现基于数据技巧的拒绝推断。首先加载相关库和数据。
# 加载相关库 from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_curve import pandas as pd import numpy as np import random import math import warnings warnings.filterwarnings("ignore") # 读取数据 data = pd.read_csv('Acard_reject.txt') data.sample(5)
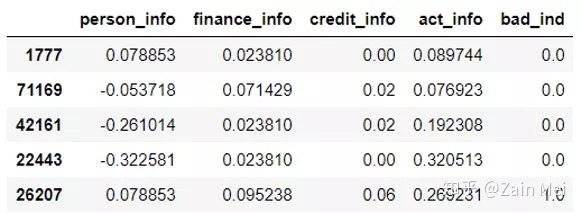
根据KGB数据训练KGB模型。
# 有真实标签 ,0和1是真实有标签的,-1是没有标签的,可以认为是使用有标签数据做模型,然后在使用无标签做验证, kgb = data[data['bad_ind']!=-1].copy() # 无标签拒绝样本 reject = data[data['bad_ind']==-1].copy() # 所有样本 agb = data.copy() # 指定变量名,使用LR模型进行拟合 feature_lst = ['person_info', 'finance_info', 'credit_info', 'act_info'] x = kgb[feature_lst] y = kgb['bad_ind'] lr_model = LogisticRegression(C=0.1) lr_model.fit(x, y)
b.模糊展开法
与硬截断法类似的还有模糊展开法(Fuzzy Augmentation),后者同样假设“逾期”与“放款”之间相互独立。模糊展开法将每条拒绝样本复制为不同类别、不同权重的两条。假设当前有一个拒绝样本,KGB模型预测其为负样本的概率为0.8,为正样本的概率为0.2,则分别生成两条新样本。第一个样本标签为负('bad_ind’=1),权重为0.8;第二个样本标签为正(’bad_ind’=0),权重为0.2。将两条样本分别带入AGB模型进行训练。其概念如图所示。

在Python中简单实现模糊展开法
# 复制样本 reject1 = reject.copy() reject2 = reject.copy() # 按照正负样本概率加权 reject1['weight'] = lr_model.predict_proba(reject1[feature_lst])[:,1] reject2['weight'] = lr_model.predict_proba(reject2[feature_lst])[:,0] # 合并 一个用户有两条数据 labeled = pd.concat([reject1, reject2], ignore_index=True) # 为KGB样本设置权重 kgb['weight'] = 1 # 合后并重新建模 final = pd.concat([labeled, kgb], ignore_index=True) x = final[feature_lst] y = final['bad_ind'] lr_fuzz = LogisticRegression(C=0.1) lr_fuzz.fit(x, y, sample_weight=final['weight'])
c.重新加权法
模糊展开法通过权重调整,修正模型的偏差,其效果与AGB模型的识别能力相关性较高。使用权重进行调整的拒绝推断方法还有重新加权法(Reweighting)。与前面的两种方法不同,重新加权法不使用拒绝样本进行学习,而仅利用其样本分布特点,调整原KGB数据集分布权重。在重新加权法中,首先使用KGB模型获得AGB样本的逾期概率,并将逾期概率升序排列;接着等频分箱为10等份,分别计算每一个分箱中的负样本占比;然后将负样本占比乘以当前箱中的权重修正项,获取AGB样本中负样本占比的边际期望;最后将权重带入建模过程,得到新的KGB模型作为最终模型。其权重修正公式为:
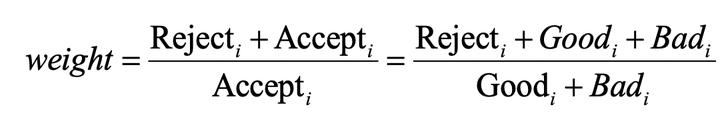
其中,Reject_j表示当前分组中拒绝样本的个数,Accept_i表示当前样本中接受样本的个数。Accept_i可以表示为当前分箱中,已知正样本个数(Good_i)和已知负样本个数(Bad_i)的和。在Python中简单实现重新加权法。
# 负样本概率,越大越可能是负样本 agb['y_pred'] = lr_model.predict_proba(agb[feature_lst])[:,1] # 等频分箱 agb['range'] = pd.qcut(agb['y_pred'], 10) # 分组计算权重 final_1 = pd.DataFrame() for i in list(set(agb['range'])): tt = agb[agb['range']==i].copy() good = sum(tt['bad_ind']==1) bad = sum(tt['bad_ind']==0) re = sum(tt['bad_ind']==-1) # 权重计算 tt['weight'] = (good+bad+re)/(good+bad) final_1 = final.append(tt) # 带入权重,重新拟合模型 x = final[feature_lst] y = final['bad_ind'] lr_weighted = LogisticRegression(C=0.1) lr_weighted.fit(x, y, sample_weight=final_1['weight'])
d.外推法
除了基于数据分析修正模型偏差外,还可以根据经验风险因子调控,引入人工修正。外推法(Extrapolation)根据KGB模型在拒绝样本上的预测结果,通过人工指定经验风险因子,获取不同分组上的负样本占比。然后按照正负样本的比例,为无标签拒绝样本随机赋值为0或1。红宝书中将经验风险因子公式定义为:

经验风险因子表示拒绝推断坏好比与放贷已知坏好比的倍数。数值越大,代表拒绝样本越“坏”,通常取值在2~4之间。这里使用动态的IK值进行权重调整。假设AGB样本使用AGB模型预测获得逾期概率,按照逾期概率升序排列后等频划分为10箱,则每一箱样本中的负样本占比应逐箱递增,因此定义其经验风险逐箱递增。从第1箱初始IK为2,逐步递增至第10箱IK为4。每一箱之间增加的数值相等,恒等于0.2。
在Python中简单实现外推法。
# 负样本概率,越大越可能是负样本 kgb['y_pred'] = lr_model.predict_proba(kgb[feature_lst])[:,1] # 等频分箱 kgb['range'] = pd.qcut(kgb['y_pred'], 10) # 在AGB有标记样本上计算等频分箱阈值和负样本占比 pmax = kgb['y_pred'].max() cutpoints = list(set(kgb['y_pred'].quantile( [0.1 * n for n in range(1, 10)]))) + [pmax + 1] cutpoints.sort(reverse=False) dct = {} for i in range(len(cutpoints) - 1): # 分箱 data = kgb.loc[np.logical_and(kgb['y_pred'] >= cutpoints[i], kgb['y_pred'] < cutpoints[i + 1]), ['bad_ind']] good = sum(data['bad_ind']==0) bad = sum(data['bad_ind']==1) # 通过递增的步长,使得经验风险因子从2增长至4 step = (i + 1) * 0.2 dct[i] = bad / (bad + good) * 2 * step # 拒绝样本按照阈值进行划分 reject['y_pred'] = lr_model.predict_proba(reject[feature_lst])[:,1] rejectNew = pd.DataFrame() for i in range(len(cutpoints) - 1): # 分箱 data = reject.loc[np.logical_and(reject['y_pred']>=cutpoints[i], reject['y_pred']<cutpoints[i+1])] data['badrate'] = dct[i] rejectNew.append(data) if rejectNew is None: rejectNew= data else: rejectNew = rejectNew.append(data) # 定义随机打分函数 def assign(x): tt = random.uniform(0, 1) if tt < x: return 1 else: return 0 # 按照加权负样本占比随机赋值 rejectNew['bad_ind'] = rejectNew['badrate'].map(lambda x:assign(x)) # 合后并重新建模 final = pd.concat([rejectNew,kgb], ignore_index=True) x = final[feature_lst] y = final['bad_ind'] lr_Extra = LogisticRegression(C=0.1) lr_Extra.fit(x,y)
外推法的思路简单,实现逻辑也不复杂。然而其缺点是随机赋值有较大的偶然性,因此可以在每一个分箱内引入硬截断法,即不按照正负样本比例进行随机赋值,而是按照AGB模型的预测概率排序后选择百分比阈值进行截断。感兴趣的读者可以自行尝试。
e.迭代再分类法
前几种方法普遍存在一个问题:无法有效保证修正偏差后的模型仍是有效的。迭代再分类法(Iterative Reclassification)是一种通过多次迭代,保证模型结果有效且收敛的拒绝推断方法。其基本思想是,先使用硬截断法为拒绝样本的标签赋值;随后将具有“伪标签”的样本加入原KGB模型进行学习,得到部分标签失真的AGB模型;接着使用AGB模型获取拒绝样本的逾期概率;之后再次使用硬截断法,不断重复上述过程,直至某个指标收敛。迭代再分类法的思路是启发式的,可以使用任何指标作为判断模型是否收敛的依据。
在Python中简单实现迭代再分类法。
maxKS = 0 n = 0 x = kgb[feature_lst] y = kgb['bad_ind'] lr_hard = LogisticRegression(C=0.1) lr_hard.fit(x,y) reject['y_pred'] = lr_hard.predict_proba(reject[feature_lst])[:,1] while True: # 负样本概率,越大越可能是负样本 reject['y_pred'] = lr_hard.predict_proba(reject[feature_lst])[:,1] # 0.8分位点 thd = reject['y_pred'].quantile(0.4) # 阈值以上硬截断为负样本 reject['bad_ind'] = reject['y_pred'].map( lambda x :1 if x >= thd else -1) # 只保留负样本 labeled = reject[reject['bad_ind']==1] labeled = labeled.drop('y_pred', axis=1) # 合后并重新建模 final = pd.concat([labeled,kgb], ignore_index=True) x = final[feature_lst] y = final['bad_ind'] lr_hard = LogisticRegression(C=0.1) lr_hard.fit(x,y) y_pred = lr_hard.predict_proba(kgb[feature_lst])[:,1] fpr_lr_train,tpr_lr_train,_ = roc_curve(kgb['bad_ind'],y_pred) ks = abs(fpr_lr_train - tpr_lr_train).max() if maxKS <= ks: maxKS = ks n+=1 print('迭代第%s轮,ks值为%s' % (n,ks)) else: break
其运行结果为:
迭代第1轮,ks值为0.3553602599594899
迭代第2轮,ks值为0.3638000806187246迭代
第3轮,ks值为0.36671654105103924
迭代第4轮,ks值为0.3670731426379163
文章转自:https://zhuanlan.zhihu.com/p/162724703
https://zhuanlan.zhihu.com/p/88624987

 浙公网安备 33010602011771号
浙公网安备 33010602011771号