Docker搭建Prometheus+grafana监控系统
一、Prometheus简介
1、简介
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。
Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。 2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。 Prometheus目前在开源社区相当活跃。
Prometheus和Heapster(Heapster是K8S的一个子项目,用于获取集群的性能数据。)相比功能更完善、更全面。Prometheus性能也足够支撑上万台规模的集群。
2、基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。
这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter。目前互联网公司常用的组件大部分
都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
3、架构
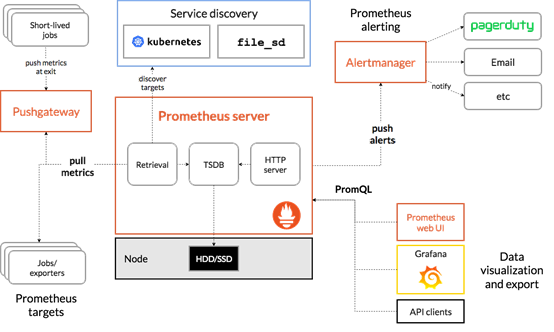
组件
Prometheus Sever:是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储及查询。
Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Sever需要对采集到的数据进行存储,Prometheus Server本身就是一个实时数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。Prometheus Server对外提供了自定义的PromQL,实现对数据的查询以及分析。另外Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据。
Exporter:将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可以获取到需要采集的监控数据。可以将Exporter分为2类:
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
间接采集:原有监控目标并不直接支持Prometheus,因此需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如:Mysql Exporter,JMX Exporter,Consul Exporter等。
Service Discovery:服务发现,Prometheus支持多种服务发现机制:文件,DNS,Consul,Kubernetes,OpenStack,EC2等等。基于服务发现的过程并不复杂,通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮询这些Target获取监控数据。
AlertManager:在Prometheus Server中支持基于Prom QL创建告警规则,如果满足Prom QL定义的规则,则会产生一条告警。在AlertManager从 Prometheus server 端接收到 alerts后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,webhook 等。
PushGateway:Prometheus数据采集基于Prometheus Server从Exporter pull数据,因此当网络环境不允许Prometheus Server和Exporter进行通信时,可以使用PushGateway来进行中转。通过PushGateway将内部网络的监控数据主动Push到Gateway中,Prometheus Server采用针对Exporter同样的方式,将监控数据从PushGateway pull到Prometheus Server。
工作流
1 Prometheus server定期从配置好的jobs或者exporters中拉取metrics,或者接收来自 Pushgateway发送过来的metrics,或者从其它的Prometheus server中拉metrics。 2 Prometheus server在本地存储收集到的metrics,并运行定义好的alerts.rules,记录新的时间序列或者向Alert manager推送警报。 3 Alertmanager根据配置文件,对接收到的警报进行处理,发出告警。 4 在图形界面中,可视化采集数据。
常用的exporter整理
node-exporter: 用来监控运算节点上的宿主机的资源信息,需要部署到所有运算节点 kube-state-metric:prometheus采集k8s资源数据的exporter,能够采集绝大多数k8s内置资源的相关数据,例如pod、deploy、service等等。同时它也提供自己的数据,主要是资源采集个数和采集发生的异常次数统计 cAdvisor (Container Advisor) :用于监控正在运行的容器资源使用和性能信息。 https://github.com/google/cadvisor Blackbox_exporter:监控业务容器存活性。可以提供 http、dns、tcp、icmp 的监控数据采集
二、前提准备
1、docker环境2台 server:192.168.1.20 client:192.168.1.30 2、nginx服务:192.168.1.10 3、监控服务器 需要安装4个服务 Prometheus Server(普罗米修斯监控主服务器 ) Node Exporter (收集Host硬件和操作系统信息) cAdvisor (负责收集Host上运行的容器信息) Grafana (展示普罗米修斯监控界面) 4、被监控的只需安装2个 Node Exporter (收集Host硬件和操作系统信息) cAdvisor (负责收集Host上运行的容器信息)
三、部署node_exporter(server、client都安装)
docker pull prom/node-exporter
docker run --name=node-exporter -p 9100:9100 -itd prom/node-exporter
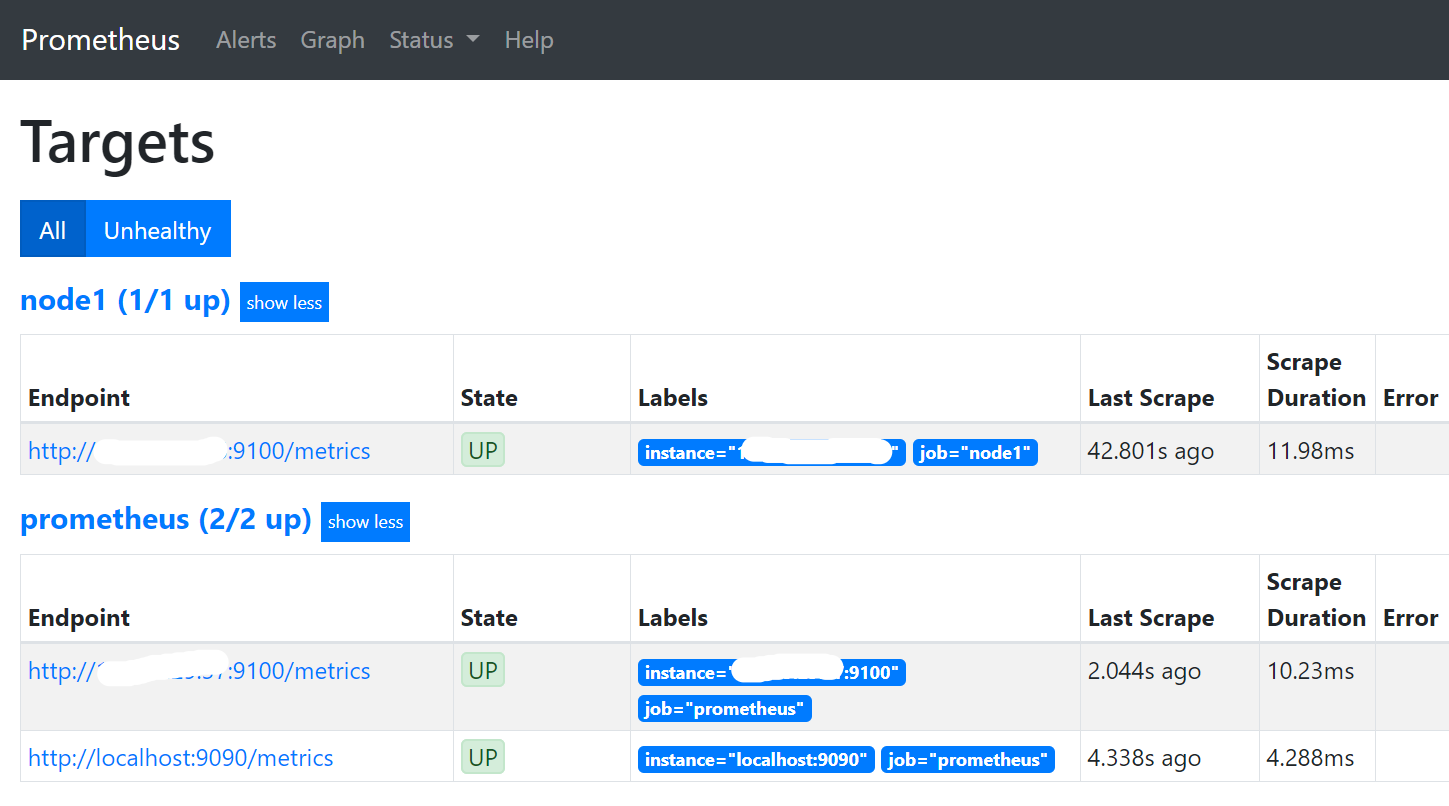
访问:http://192.168.1.20:9100 #查看节点信息
http://192.168.1.30:9100
四、安装prometheus server(server安装)
mkdir -p /server/docker/prometheus/{server,client} touch /server/docker/prometheus/server/rules.yml 编辑prometheus.yml文件,添加客户端信息
vim /server/docker/prometheus/server/prometheus.yml
global:
scrape_interval:
external_labels:
monitor: 'codelab-monitor'
# 这里表示抓取对象的配置
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s #重写了全局抓取间隔时间,由15秒重写成5秒
static_configs:
- targets: ['localhost:9090','192.168.1.20:9100']
- job_name: 'client-node1'
static_configs:
- targets: ['192.168.1.30:9100']
docker启动prometheus:
docker pull prom/prometheus
docker run --name prometheus -p 9090:9090 \ -v /server/docker/prometheus/server/prometheus.yml:/etc/prometheus/prometheus.yml \ -v /server/docker/prometheus/server/rules.yml:/etc/prometheus/rules.yml \ -itd prom/prometheus \ --config.file=/etc/prometheus/prometheus.yml \ --web.enable-lifecycle
注:启动时加上--web.enable-lifecycle: 启用远程热加载配置文件
--config.file:启动时加载配置文件
浏览器访问prometheus:http://192.168.1.20:9090
五、安装Grafana展示(server安装)
Grafana是用于可视化大型测量数据的开源程序,它提供了强大和优雅的方式去创建、共享、浏览数据。
1、先启动测试grafana
docker pull grafana/grafana
docker run --name=grafana -p 3000:3000 -itd grafana/grafana
将配置文件复制到宿主机:
docker cp grafana:/etc/grafana/grafana.ini /server/docker/prometheus/grafana/
docker rm -f grafana
修改配置文件grafana.ini,配置smtp邮件报警信息(报警会用到)
vim /server/docker/prometheus/grafana/grafana.ini

根据实际添加上面这几条,host、password可以登录邮箱查看。
2、启动正式grafana
docker run -p 3000:3000 --name grafana \ -v /server/docker/prometheus/grafana/grafana.ini:/etc/grafana/grafana.ini \ -v /server/docker/prometheus/grafana/data:/var/lib/grafana \ -e "GF_SECURITY_ADMIN_PASSWORD=grafana123" \ -itd grafana/grafana
注:-e "GF_SECURITY_ADMIN_PASSWORD=grafana123" 是设置grafana登陆页面的密码,如不添加这条,默认账号密码为admin/admin
访问:http://192.168.1.20:3000 账号密码为:admin/grafana123
3、nginx实现域名访问grafana
server {
server_name grafana.aa.com;
listen 80;
location / {
proxy_pass http://192.168.1.20:3000;
}
}
访问:http://grafana.aa.com
4、添加prometheus数据源

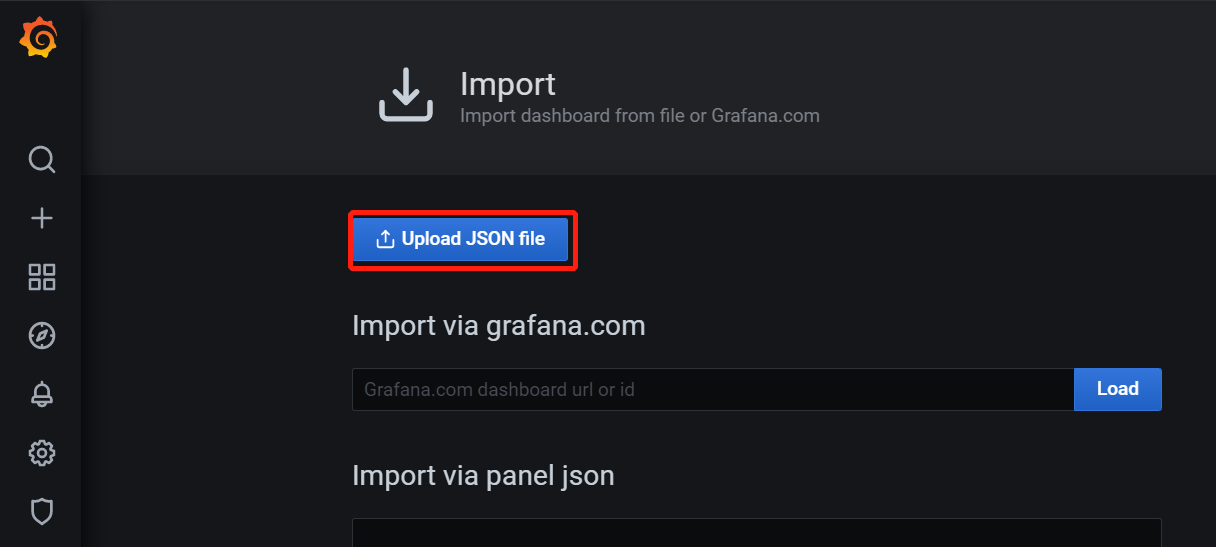
5、添加模板文件:(监控主机信息)
https://www.jianshu.com/p/367d52fe1171 #grafana常用监控模板大全 https://grafana.com/grafana/dashboards/ #grafana官网模板
根据自己需求下载网址中模板,下载到本地后,导入grafana:
也可以根据官网的模板ID号下载:


展示:

六、 安装cAdvisor——监控容器信息(server、client都安装)
1、docker安装cAdvisor
docker pull google/cadvisor
docker run -p 8088:8080 --name cadvisor \ -v /:/rootfs:ro \ -v /var/run:/var/run:rw \ -v /sys:/sys:ro \ -v /var/lib/docker/:/var/lib/docker:ro \ -itd google/cadvisor:latest
将ip、端口加入到prometheus.yml 文件,重启prometheus服务
global:
scrape_interval:
external_labels:
monitor: 'codelab-monitor'
# 这里表示抓取对象的配置
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s #重写了全局抓取间隔时间,由15秒重写成5秒
static_configs:
- targets: ['localhost:9090','192.168.1.20:9100','192.168.1.20:8088']
- job_name: 'client-node1'
static_configs:
- targets: ['192.168.1.30:9100','192.168.1.30:8088']
docker restart prometheus #重启prometheus让配置生效
2、添加模板,监控docker容器
模板在上文给的俩个地址里,请自行选择,展示: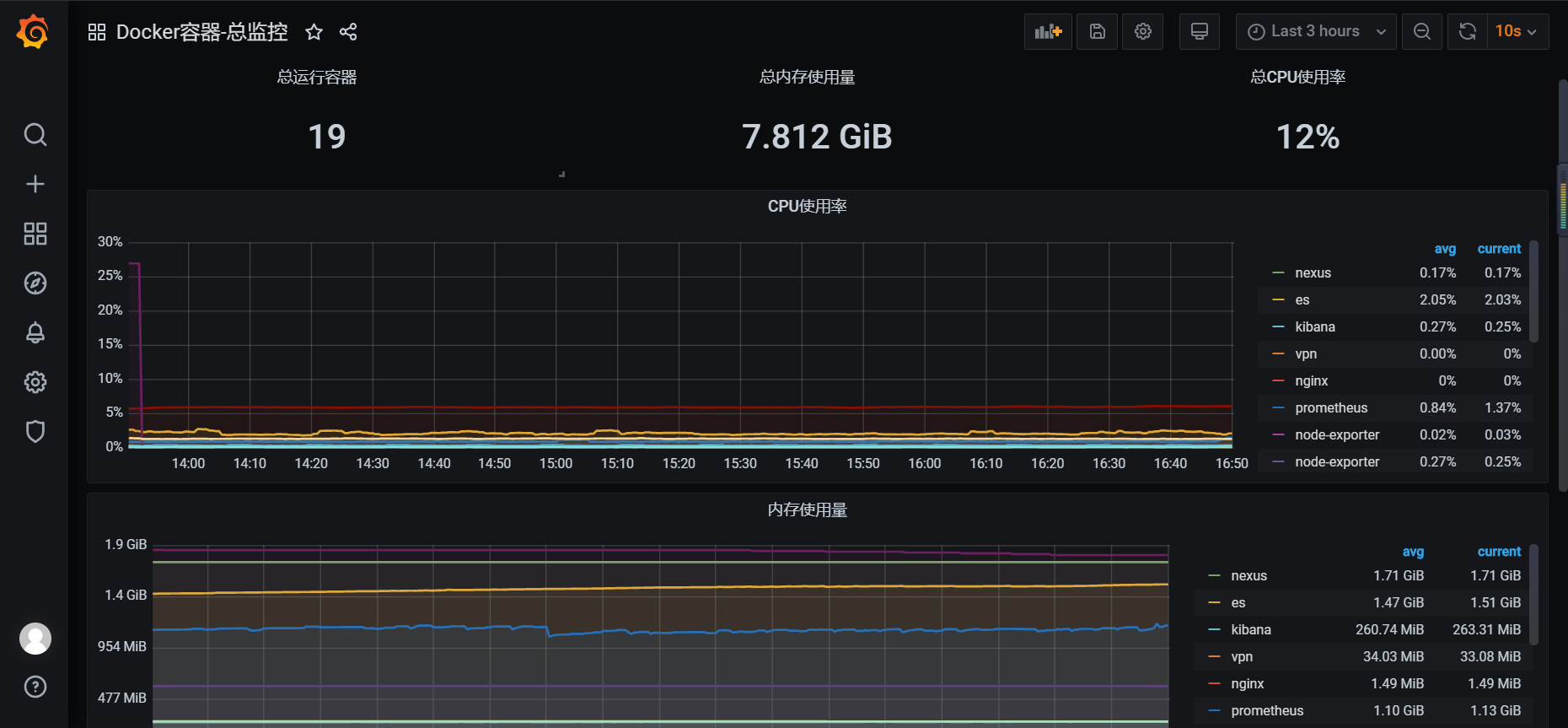
七、blackbox_exporter监控端口(server安装)
1、docker安装blackbox_exporter
docker pull prom/blackbox-exporter
docker run --name blackbox -p 9115:9115-itd prom/blackbox-exporter
在prometheus.yml文件添加监控配置:(注意:格式不对prometheus会报错)
#监控主机端口存活状态
- job_name: 'prometheus_port_status'
metrics_path: /probe
params:
module: [tcp_connect]
static_configs:
- targets: ['192.168.1.20:8088','192.168.1.20:9100','192.168.1.20:8091','192.168.1.30:8088','192.168.1.30:9100','192.168.1.30:8091']
labels:
instance: 'port_status'
group: 'tcp'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.1.20:9115
#监控主机存活状态
- job_name: 'node_status'
metrics_path: /probe
params:
module: [icmp]
static_configs:
- targets: ['192.168.1.20','192.168.1.30']
labels:
instance: 'node_status'
group: 'node'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: 192.168.1.20:9115
#监控网站状态
- job_name: 'web_status'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets: ['https://www.baidu.com']
labels:
instance: 'web_status'
group: 'web'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: 192.168.1.20:9115
blackbox-exporter在grafana页面展示需要安装grafana-piechart-panel插件 下载完后,上传到/server/docker/prometheus/grafana/data/plugins
docker restart grafana #重载grafana配置
docker exec -it grafana grafana-cli plugins install grafana-piechart-panel #grafana安装插件
docker restart grafana
2、在grafana面板添加模板:(模板ID:9965)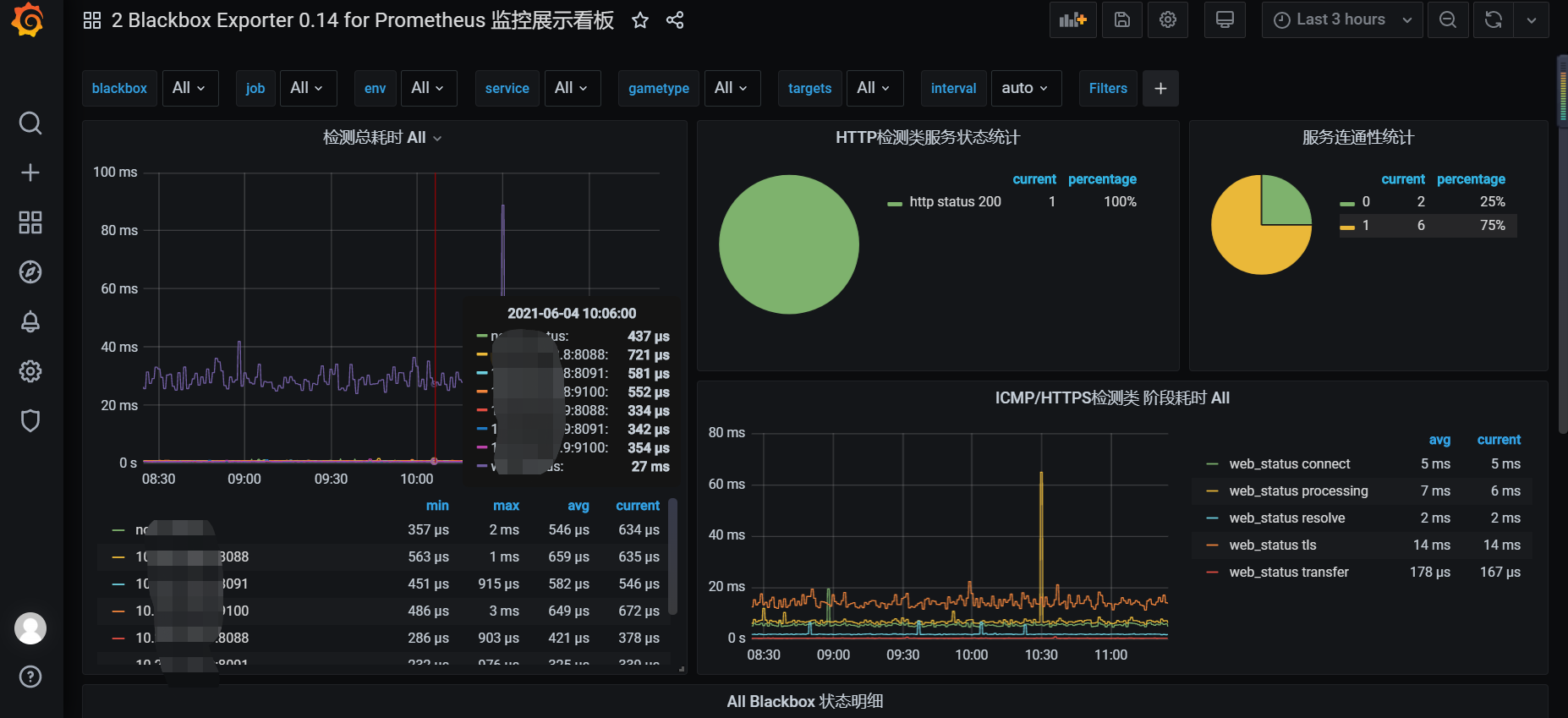
这个仪表盘监控信息不完全,目前还没找到更合适的。
八、Alert警报(两种方式)
1、AlertManager告警(server安装)
Alertmanager是一个独立的告警模块,接收Prometheus等客户端发来的警报。
Prometheus的警报分为两个部分:
报警:Prometheus服务器中的警报规则将警报发送到Alertmanager。
通知:该Alertmanager 管理这些警报, 通过邮件、hipchat等方式发送通知
运行测试alertmanager:
docker pull prom/alertmanager
docker run --name alert -p 9093:9093 -itd prom/alertmanager
docker cp alert:/etc/alertmanager/alertmanager.yml /server/docker/prometheus/alert/
编写alertmanager配置文件实现邮件告警:vim /server/docker/prometheus/alert/alertmanager.yml
# 全局配置
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '166xxxxxxx@qq.com'
smtp_auth_username: '166xxxxxxx@qq.com'
smtp_auth_password: 'bxxxxxxxxxxacdif'
smtp_require_tls: true
# 定义路由树信息
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'mail'
#定义警报接收者信息
receivers:
- name: 'mail'
email_configs:
- to: '136xxxxxxx@qq.com'
send_resolved: true
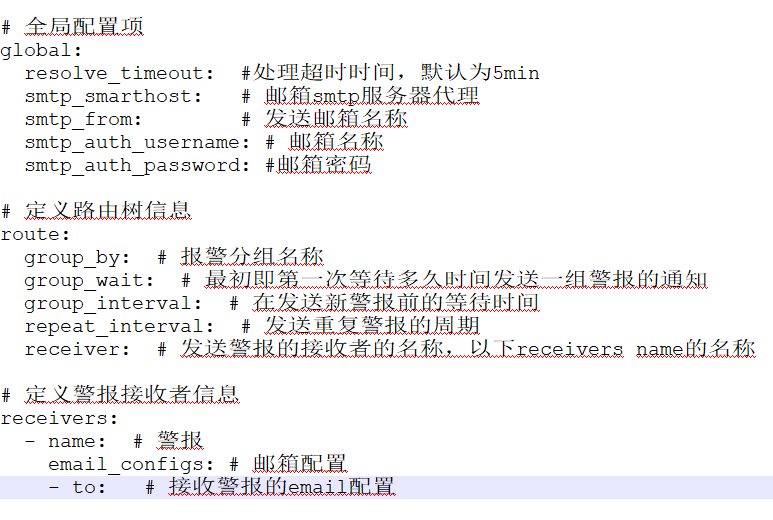
停止测试alertmanager,启动正式:
docker rm -f alert
docker run -p 9093:9093 --name alert \ -v /server/docker/prometheus/alert/alertmanager.yml:/etc/alertmanager/alertmanager.yml \ -itd prom/alertmanager
编写报警规则:vim /server/docker/prometheus/server/rules.yml (参考配置)
groups:
- name: test-rules
rules:
- alert: HttpprometheusDown
expr: up == 0
for: 1m
labels:
team: node
annotations:
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: job {{$labels.job}} has been down "
value: {{$value}}
参数解释: - alert: # 告警名称 expr: # 告警的判定条件,参考Prometheus高级查询来设定(是promSQL简单改写的,参考上面CPU的,建议先做一个低数值测试,成功后改为需要的告警数值) for: # 满足告警条件持续时间多久后,才会发送告警 labels: #标签项 team: node annotations: # 解析项,详细解释告警信息 {{$labels.instance}}可以显示故障机ip端口 {{ $value }}当前的值
在prometheus配置文件中引入AlertManager配置文件:
global:
scrape_interval:
external_labels:
monitor: 'codelab-monitor'
rule_files:
- rules.yml
# 这里表示抓取对象的配置
scrape_configs:
#这个配置是表示在这个配置内的时间序例,每一条都会自动添加上这个{job_name:"prometheus"}的标签
- job_name: 'prometheus'
scrape_interval: 5s #重写了全局抓取间隔时间,由15秒重写成5秒
static_configs:
- targets: ['localhost:9090','192.168.1.20:9100','192.168.1.20:8088']
- job_name: 'node1'
static_configs:
- targets: ['192.168.1.30:9100','192.168.1.30:8088']
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.1.20:9093']
docker restart prometheus #重启prometheus让配置生效
访问:http://192.168.1.20:9093/#/alerts 即可查看所监控到的报警信息
2、grafana自带alert告警(在grafana页面配置)



设置完成,但是grafana自带的alert功能有限,太复杂的报警功能无法实现。
原文链接:https://www.cnblogs.com/cfzy/p/14750004.html
人生的意义是什么,人生真的有意义吗?
作者:等风来~~
本博客所有文章仅用于学习、研究和交流目的,欢迎转载。
如果觉得文章写得不错,或者帮助到您了,请点个赞。
如果文章有写的不足的地方,请你一定要指出,因为这样不光是对我写文章的一种促进,也是一份对后面看此文章的人的责任。谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号