

沉淀之log4c库
本着学习log4c的设计技巧和设计理念,通过浏览博客和阅读代码,加上自己的一些理解,整理下所思和所得。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
log4c的三个重要概念:
category:就是你想写的日志,可以有多个日志,按照调用参数的形式进行制定日志所对应的位置。需要为category指定一个appender,以确定写日志的方式;现在只支持一个category对应一种appender方式。在主页上说是有一对多实现的规划,没有实现就不再进行代码的维护了(实际是已经完成了这一部分的功能)。
appender:用来指定category的输出方式,可以是stdout、stderr、syslog、文件等。需要为appender指定一个layout,在进行log的输出时,会携带layout中所标定携带的信息,比如,当前的行,当前所执行的函数名字、时间等。有dated、basic等默认的,当然也可以去实现你想制定的输出格式。
layout:就是在输出之前为要输出的message打上一个标签然后再进行输出,变相的给出更详细的信息以方便使用者去根据log文件去定位问题。
三者之间的关系是按照图一进行组织:
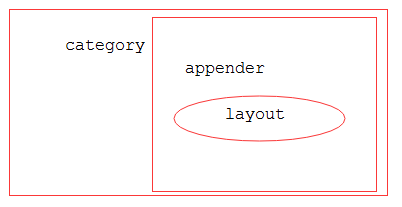
图一:三个概念之间的关系
在一个数据的组装和输出流程上是按照图二的顺序进行的(以basic格式的hello world来进行说明):

图二:一个数据log的流向
以上三种信息都是配置在xml文件中的,对于该配置文件,程序默认是去三个地方去找,按照顺序,找到一个就进行加载并退出。其中有两个是环境变量中的目录(在安装时进行添加的环境变量LOG4C_RCPATH、HOME)加载顺序:$LOG4C_RCPATH>$HOME>当前目录。只有一个最先存在并可以进行访问的会被加载。
log4c的xml配置文件分析:
log4crc配置文件中就是简单的用xml进行组织的配置属性,一般来说每条有效的配置有上面提到的三个规则。由上到下来数的话,首先是category的属性信息,并为category指定一个appender作为一条xml
然后是appender的属性信息并指定一个layout给appender使用。最后给layout指定类型。
现在程序中实现了的layout类型有3种方式(dated、basic、dated_local),然后每种方式对应两个行为(可重入、不可重入)。如果不能满足使用,那么就需要去添加你所需要的方式到程序中全局维护的一个数组里面。下面是一个精简的配置文件:
<log4c version="1.2.4">
<config>
<bufsize>0</bufsize>
<debug level="2"/>
<nocleanup>0</nocleanup>
<reread>1</reread>
</config>
<appender name="stdout" type="stream" layout="basic"/>
<layout name="basic" type="basic"/>
<category name="six13log.log.app" priority="debug" appender="stdout" />
</log4c>
里面的属性标签写的意思都很明了,你要坚信的看到的就是你所想的那个意思。
log4c的使用方式(附件里有一份1.2.4版本的源码):
下载:
log4c的主页上有一些简介,在这里可以找到下载链接。
如果对于log4c比较熟悉了,只是想要下载一个tar包,下面是下载链接
下载链接:https://sourceforge.net/projects/log4c/files/log4c/1.2.4/log4c-1.2.4.tar.gz/download?use_mirror=heanet
安装:
在log4c-1.2.4目录下有一个readme文档,里面有对于log4c是什么、注意事项、编译工具链、安装方法等的详细介绍。
配置:
$ tar -zxvf log4c-1.2.0.tar.gz
$ mkdir build; cd build
$ ../log4c-1.2.0/configure --prefix=/path/of/installation
$ make
$ make install
代码:
使用起来还是比较方便的,在example文件夹下面有几个demo,使用了很少的接口就能完成了工作。可以具体参考下来使用。一般下面4个接口就能满足一般的需求了:
log4c_init();
log4c_category_get();
log4c_category_log();
log4c_fini();
编译:
在编译的时候只需要注意添加上log4c的库文件和路径就可以,以main.c为例进行编译
gcc main.c -L$PATH -llog4c
其中PATH是log4c.a的位置
执行:
按照正常可执行文件进行执行即可;
工厂方法:
工厂方法(Factory Method)模式的意义是定义一个创建产品对象的工厂接口,将实际创建工作推迟到子类当中。核心工厂类不再负责产品的创建,这样核心类成为一个抽象工厂角色,仅负责具体工厂子类必须实现的接口,这样进一步抽象化的好处是使得工厂方法模式可以使系统在不修改具体工厂角色的情况下引进新的产品。
源码组织方式很是缜密,使用C语言来实现面向对象的思想对功能进行实现。也就是这里提到的工厂方法,这样所有的appender和layout都可以单独实现后将自己的地址给到工厂入口里,根据工厂所提供的接口执行各自的方法去操作需要打印的日志。那么需要增加一种日志类型的时候,可以在程序中全局数组中添加一个需要的类型就可以完成功能,而不需要去每一个步骤上修改源代码。在log4c里面用到这一思想,在源码分析里面会在使用这一思想的部分进行展开。
log4c源码分析:
以example/helloworld程序的执行流程来进行说明log4c使用时候的调用关系,以及每个接口内部的设计,所展现的缩进关系代表调用关系在用到某一个结构或者某一个操作的时候会在调用关系下面进行展开;在阅读的时候应该参考着源码来看,在使用log系统之前应该有如下的几个步骤:初始化,获得category,输出log信息,销毁。
1、初始化的调用关系如下:
log4c_init:
start
①log4c_layout_type_set(layout_types[i]);
②sd_hash_lookadd(log4c_layout_types(), a_type->name)
③log4c_appender_type_set(appender_types[i]);
sd_hash_lookadd(log4c_appender_types(), a_type->name)
④log4c_load(rcfiles[i].name)
log4c_rc_load(&__log4c_rc, a_filename);
⑤category_load(this, node);
log4c_category_get(name->value);
sd_factory_get(log4c_category_factory, a_name);
log4c_category_set_priority(cat, log4c_priority_to_int(priority->value));
log4c_category_set_additivity(cat, 0);
log4c_category_set_appender(cat, log4c_appender_get(appender->value));
⑥appender_load(this, node);
log4c_appender_get(name->value);
sd_factory_get(log4c_appender_factory, a_name);
log4c_appender_set_type(app, log4c_appender_type_get(type->value));
log4c_appender_set_layout(app, log4c_layout_get(layout->value));
⑦layout_load(this, node);
log4c_layout_get(name->value);
sd_factory_get(log4c_layout_factory, a_name);
log4c_layout_set_type(layout, log4c_layout_type_get(type->value));
⑧config_load(this, node);
end
①循环设置系统中支持的layout_type,当前log4c工程中已经支持的layout_type如下所示,有六种,其中后三种是前三个的_r形式,也就是说对多线程安全的模式。以basic格式的layout_type进行了说明,其他的情况的实现手法类似;
- //已经实现的layout类型都集合在一个指针数组里
static const log4c_layout_type_t * const layout_types[] = {&log4c_layout_type_basic,&log4c_layout_type_dated,&log4c_layout_type_dated_local,&log4c_layout_type_basic_r,&log4c_layout_type_dated_r,&log4c_layout_type_dated_local_r,};//计算这个指针数组的元素static size_t nlayout_types = sizeof(layout_types) / sizeof(layout_types[0]);- //basic类型的结构体的定义
- const log4c_layout_type_t log4c_layout_type_basic = {
"basic",basic_format,};- //basic类型的结构体元素中,函数的实现
- static const char* basic_format(const log4c_layout_t* a_layout,
const log4c_logging_event_t* a_event){static char buffer[1024];........return buffer;}
上面代码结构列出了layout_types的组织关系,所表达的具体组织结构可以用图三来进行说明:

图三:layout_types的组织形式
②将layout_types[i]中的数据放到一个hash表里,在这里对于这个hash表的结构以及操作方式进行展开,流程性的说明都在代码里面以注释的方式进行说明,代码是自上向下进行分析的,也就是说下面出现的函数,是当前函数中调用到的;对于逻辑性的东西以及设计会在代码的下面进行展开说明,对应于当前hash表已经实现的操作还有很多,但是这里就是一个抛砖引玉的过程,对于这里没有用到的操作就没有展开,对于一些简单的或者是没有必要进行展开的比如申请内存(我承认我错了,如果有时间还是可以好好看看内存相关部分的操作,虽然就是对于系统调用加了一层封装,不过还是很有借鉴性的),就没有去展开。之后还会有很多hash相关的操作,就会以这里所展开的描述为标准。不再进行赘述。
extern const log4c_layout_type_t* log4c_layout_type_set(const log4c_layout_type_t* a_type){sd_hash_iter_t* i = NULL;void* previous = NULL;if (!a_type)return NULL;//hash表的操作入口在这里进入,在进入之前先用log4c_layout_types()进行创建,或者称之为检查hash表存在与否if ( (i = sd_hash_lookadd(log4c_layout_types(), a_type->name)) == NULL)return NULL;//将layout_type的首地址赋值到hash表的item中,没错,这个hash表里放的又都是地址previous = i->data;i->data = (void*) a_type;//返回这个hash中之前指向的内容。return previous;}//在这里作为sd_hash_lookadd第一个参数,利用static的特性在第一次调用时创建一个hash表。之后就一直返回这个表static sd_hash_t* log4c_layout_types(void){//static很重要static sd_hash_t* types = NULL;//判断若是第一次进入该函数,那么就创建一个hash表出来,这里创建了一个有20个item的hash表if (!types)types = sd_hash_new(20, NULL);//将这个hash表给出来。return types;}//新建一个hash表extern sd_hash_t* sd_hash_new(size_t a_size, const sd_hash_ops_t* a_ops){//一个默认的hash相关的操作结构体,如果有传入a_ops也可以另外指定操作,很显然我们当前传入的是NULL,//也就是说现在默认的操作就已经满足了我们的需求const static sd_hash_ops_t default_ops = {(void*) &sd_hash_hash_string,(void*) &strcmp,0, 0, 0, 0};//hash表结构的指针以及一个item的指针定义sd_hash_t* hash;sd_hash_iter_t** tab;//根据传入的size来进行分配内存给hash表使用if (a_size == 0) a_size = SD_HASH_DEFAULT_SIZE;hash = sd_calloc(1, sizeof(*hash));tab = sd_calloc(a_size, sizeof(*tab));//检查内存申请成功与否if (hash == 0 || tab == 0) {free(hash);free(tab);return 0;}//最后对hash表进行填充,如果a_ops不为NULL,就进行替换opshash->nelem = 0;hash->size = a_size;hash->tab = tab;hash->ops = a_ops != 0 ? a_ops : &default_ops;return hash;}//a_this是上面log4c_layout_types调用返回的一个hash表,a_key可以理解成hash值,这里是拿名字来做的hash键值计算//名字也很显然,先看在没在hash表里,不在的话再进行添加,在hash表里就返回hash表中该item的地址extern sd_hash_iter_t* sd_hash_lookadd(sd_hash_t* a_this, const void* a_key){int h;sd_hash_iter_t* p;//判断参数有效性if (a_this == 0 || a_key == 0) return 0;//查找hash表中当前传入的key值所对应的item是否已经存在。如果存在就返回。if ((p = sd_hash_lookup(a_this, a_key)) != 0) return p;//申请item的内存if ((p = sd_calloc(1, sizeof(*p))) == 0) return 0;//如果有复制数据功能那么就复制一份否则就用原始数据if (a_this->ops->key_dup != 0)p->key = a_this->ops->key_dup(a_key);elsep->key = (void*) a_key;//下面是对于item进行填充,计算等操作p->hash = a_this;p->__hkey = a_this->ops->hash(a_key);//如果当前hash表存满了,那重新扩充一个的hash表,将原有的数据原样拷贝if (a_this->nelem > SD_HASH_FULLTAB * a_this->size) rehash(a_this);//获得item的指针、以及链表操作进行连接h = hindex(p->__hkey, a_this->size);p->__next = a_this->tab[h];a_this->tab[h] = p;if (p->__next != 0) p->__next->__prev = p;a_this->nelem++;return p;}//查找hash表a_this中,是否存在a_key所对应的itemextern sd_hash_iter_t* sd_hash_lookup(sd_hash_t* a_this, const void* a_key){int h;sd_hash_iter_t* p;//检查参数有效性。if (a_this == 0 || a_key == 0) return 0;//计算索引h = hindex(a_this->ops->hash(a_key), a_this->size);//在表里进行遍历,并进行比较函数回调进行操作,知道找到返回地址或者返回NULLfor (p = a_this->tab[h]; p != 0; p = p->__next)if (a_this->ops->compare(a_key, p->key) == 0) {return p;}return 0;}//计算hash值,其实就是个模除#define hindex(h, n) ((h)%(n))//扩充hash表a_this,当前SD_HASH_GROWTAB为4,也就是扩大之后为4倍关系static void rehash(sd_hash_t* a_this){size_t i;int h, size;sd_hash_iter_t** tab;sd_hash_iter_t* p;sd_hash_iter_t* q;size = SD_HASH_GROWTAB * a_this->size;tab = sd_calloc(size, sizeof(*tab));if (tab == 0) return;//将原有的数据原样拷贝for (i = 0; i < a_this->size; i++) {for (p = a_this->tab[i]; p; p = q) {q = p->__next;h = hindex(p->__hkey,size);p->__next = tab[h];tab[h] = p;if (p->__next != 0) p->__next->__prev = p;p->__prev = 0;}}free(a_this->tab);//填充新得到的hash表a_this->tab = tab;a_this->size = size;}
贴的代码有点长,长到我自己都不想看。节点性的注释都有,帮助理解这个hash操作的过程。其实我还是愿意分析这个hash所对应的设计,逻辑。有了思想,实现只是一个编码和调试的过程。
hash表的结构如图四所示:
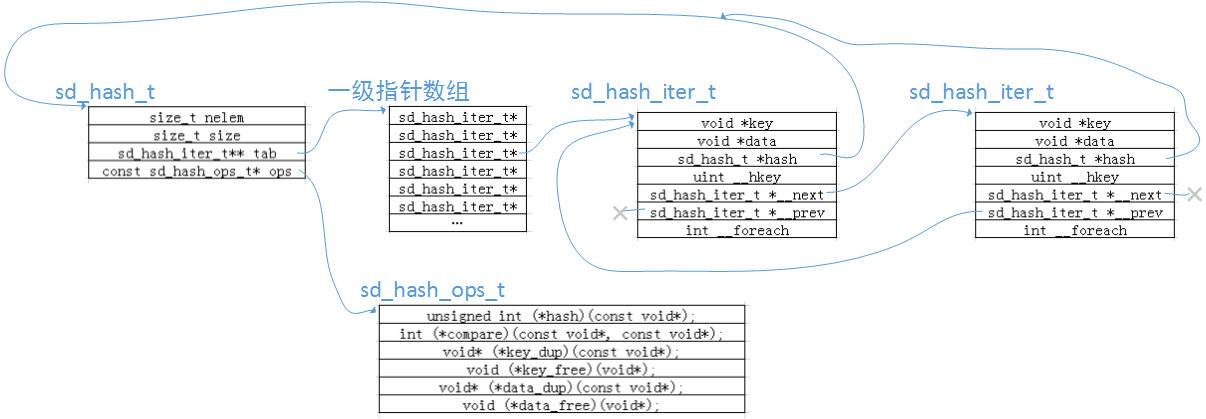
图四:hash表的组织结构
初始化完成之后,该hash表的内容如图五所示:
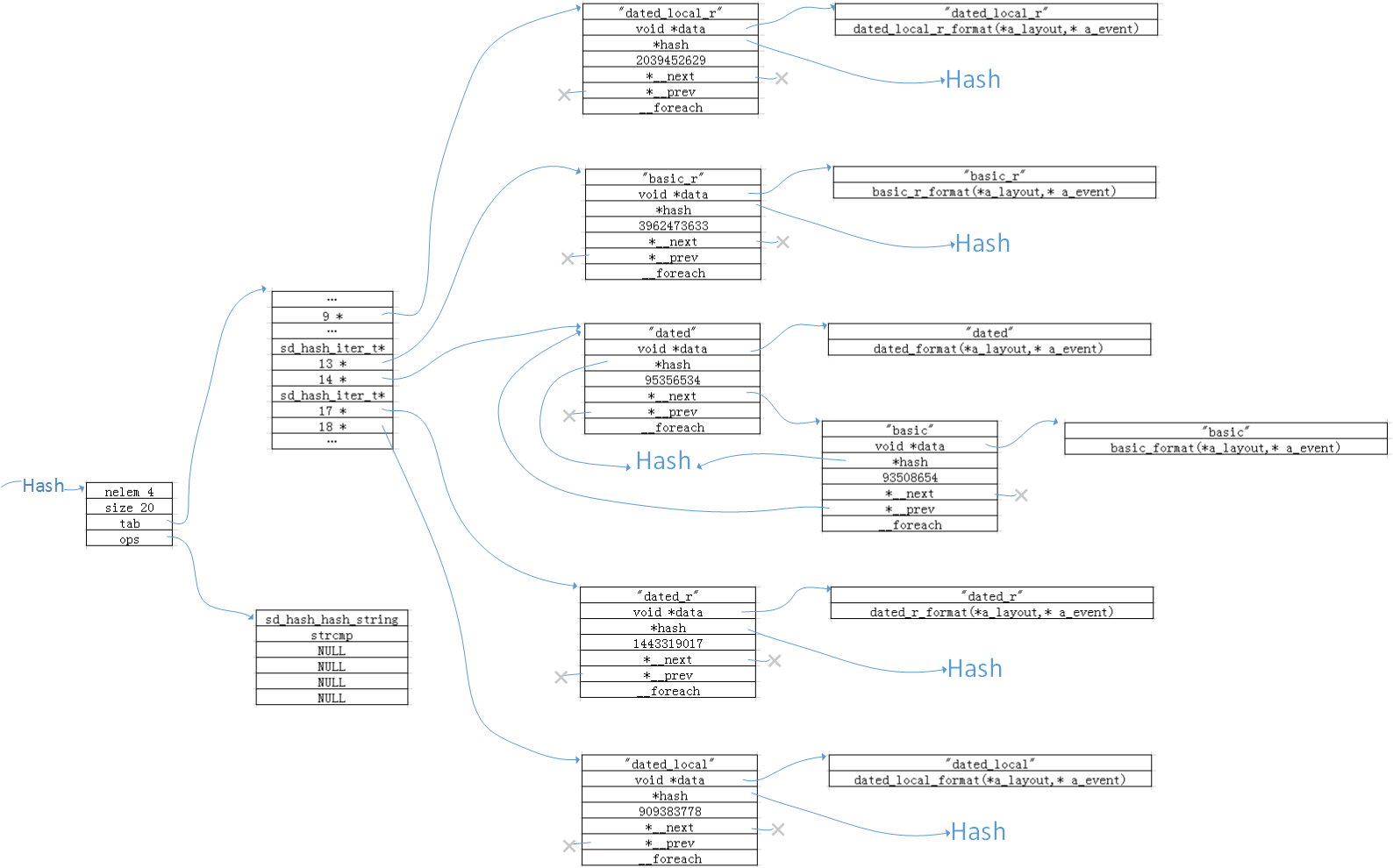
图五:layout_types初始化完成后的hash结构
好吧,对于hash的分析总感觉不是很尽兴,单独的对于这一个hash操作做一个系统的分析。具体的的内容可以看《沉淀之log4c的hash操作》
③循环设置系统中支持的appender_type,当前log4c工程中已经支持的appender_type如下所示,有五种,其中后三种是根据条件编译来进行选择的,由于条件编译是在预处理阶段进行处理的,所以nappender_types永远都是当前系统中支持的appender的个数。以log4c_appender_type_stream格式的appender_type进行了说明,其他的情况的实现手法类似;
//appender_types是结构体指针数组,里面集合了所有的以实现appender类型static const log4c_appender_type_t * const appender_types[] = {&log4c_appender_type_stream,&log4c_appender_type_stream2,#ifdef HAVE_MMAP&log4c_appender_type_mmap,#endif#ifdef HAVE_SYSLOG_H&log4c_appender_type_syslog,#endif#ifdef WITH_ROLLINGFILE&log4c_appender_type_rollingfile#endif};//获取当前指针数组中的元素static size_t nappender_types = sizeof(appender_types) / sizeof(appender_types[0]);- //具体的结构体定义,以stream类型为例
- const log4c_appender_type_t log4c_appender_type_stream = {
"stream",stream_open,stream_append,stream_close,};//一下是三个回调函数的实现/*******************************************************************************/static int stream_open(log4c_appender_t* this){FILE* fp = log4c_appender_get_udata(this);........return 0;}/*******************************************************************************/static int stream_append(log4c_appender_t* this,const log4c_logging_event_t* a_event){........}/*******************************************************************************/static int stream_close(log4c_appender_t* this){........}
上面代码结构列出了appender_types的组织关系,所表达的具体组织结构与图三特别类似。本着一个东西不说两遍的原则,这个地方的图自行思考(抠图太费劲了呵呵)。
④log4c_load,光看名字也知道是加载什么,在这里需要从外部加载也只有配置文件了。这个函数就是加载配置文件中信息的入口地址。参数是配置文件名字,至于配置文件的名字是按照什么顺序怎么获得的,在前面已经说过了,另外最好是结合着源码。
log4c_load里面其实只是调用了一个内部接口log4c_rc_load,参数中增加了一个用来保存全局的配置信息结构变量。进入到这个函数内部之后,在开始的部分是对于xml文件进行加载,具体加载的算法没有去关注,这里只需要知道有接口可以从xml文件里获取自己想要的字段,并且能够按照节点进行遍历;其实也可以找个时间单独的把log4c工程里面实现的功能模块一个一个的拉出来枪毙,后续再说。在遍历节点的过程中如果遇到了category节点,那么就进入了category_load函数进行加载;同样的方式会根据不同的节点类型分别的进入到appender_load、layout_load、config_load里面进行分别加载。这里不得不提一下这一系列加载函数里面都是有两个参数,一个是刚刚提到的保存全局的配置信息结构体,这个只有config_load中起了作用。另外的三个都没有用到这个参数,另外一个参数就是当前这个xml节点的入口。
⑤category_load;陷入到该函数之后,先将name、priority、additivity、appender等属性值提取出来,然后如调用关系所说的接着进入到了log4c_category_get(name),对于源码的分析展开到了这里,前面所提到的工厂模式才接触到。对于源码的分析也集合在源码里,以注释的形式存在,另外调用关系是自上向下。具体分析会在后面给出。
extern log4c_category_t* log4c_category_get(const char* a_name){//sd_factory_ops_t是一个通用性的结构,包含了一些通用的接口,在这里对于这几个//通用性接口进行赋值,后续直接使用工厂模式的接口就可以了。//下面三个函数对应了category的三个操作。另:static很重要,const也很重要static const sd_factory_ops_t log4c_category_factory_ops = {(void*) log4c_category_new,(void*) log4c_category_delete,(void*) log4c_category_print,};//看是否已经建立了log4c_category_factory,并初始化了。如果是第一次陷入则调用sd_factory_newif (!log4c_category_factory) {//创建一个category的工程对象log4c_category_factory = sd_factory_new("log4c_category_factory",&log4c_category_factory_ops);}//在这个工厂对象里查找是否存在,不存在则创建return sd_factory_get(log4c_category_factory, a_name);}//通用结构的定义,和类型struct __sd_factory_ops{void* (*fac_new) (const char*);void (*fac_delete) (void*);void (*fac_print) (void*, FILE*);};typedef struct __sd_factory_ops sd_factory_ops_t;//a_name要建立模块的名字,a_ops对应于这个模块的一些操作extern sd_factory_t* sd_factory_new(const char* a_name,const sd_factory_ops_t* a_ops){sd_factory_t* this;if (!a_name || !a_ops)return NULL;//创建对象并进行赋值this = sd_calloc(1, sizeof(*this));this->fac_name = sd_strdup(a_name);this->fac_ops = a_ops;this->fac_hash = sd_hash_new(20, NULL);return this;}//在这个工厂对象里查找是否存在,不存在则创建extern void* sd_factory_get(sd_factory_t* this, const char* a_name){sd_hash_iter_t* i;sd_factory_product_t* pr;//查找是否存在于hash表里。if ( (i = sd_hash_lookup(this->fac_hash, a_name)) != NULL)return i->data;if (!this->fac_ops->fac_new)return NULL;//不存在则创建,这里调用的是上面static修饰的log4c_category_newif ( (pr = this->fac_ops->fac_new(a_name)) == NULL)return NULL;//把创建出来的这个模块加到hash里面sd_hash_add(this->fac_hash, pr->pr_name, pr);return pr;}//新建一个categoryextern log4c_category_t* log4c_category_new(const char* a_name){log4c_category_t* this;if (!a_name)return NULL;//申请内存并进行赋值this = sd_calloc(1, sizeof(log4c_category_t));this->cat_name = sd_strdup(a_name);this->cat_priority = LOG4C_PRIORITY_NOTSET;this->cat_additive = 1;this->cat_appender = NULL;this->cat_parent = NULL;/* skip root category because it has a NULL parent */if (strcmp(LOG4C_CATEGORY_DEFAULT, a_name)) {char* tmp = sd_strdup(this->cat_name);//获取父节点,或者将父节点插入到hash里面//a.b.c 的关系是 a是b的父,b是c的父//若tmp为a.b.c那么就会在hash里面存放三个节点a、a.b、a.b.c;this->cat_parent = log4c_category_get(dot_dirname(tmp));free(tmp);}return this;}//就是去掉名字的最后一个.static const char* dot_dirname(char* a_string){char* p;if (!a_string)return NULL;if ( (p = strrchr(a_string, '.')) == NULL)return LOG4C_CATEGORY_DEFAULT;*p = '\0';return a_string;}
其实通俗点来讲,这个log4c_category_get有两个作用,一个是在要查找的category不存在时候,把这个待查找的category插入到hash里面,并返回一个这个新建立的category。如果category存在,那么就直接返回这个category。对于返回的category具体的组织形式可以见图六:

图六:category的结构组织
所出现的工厂方法给出了对应的结构体,这里用到的有sd_factory_ops_t、sd_factory_t。对于其直观的描述如图七所示:
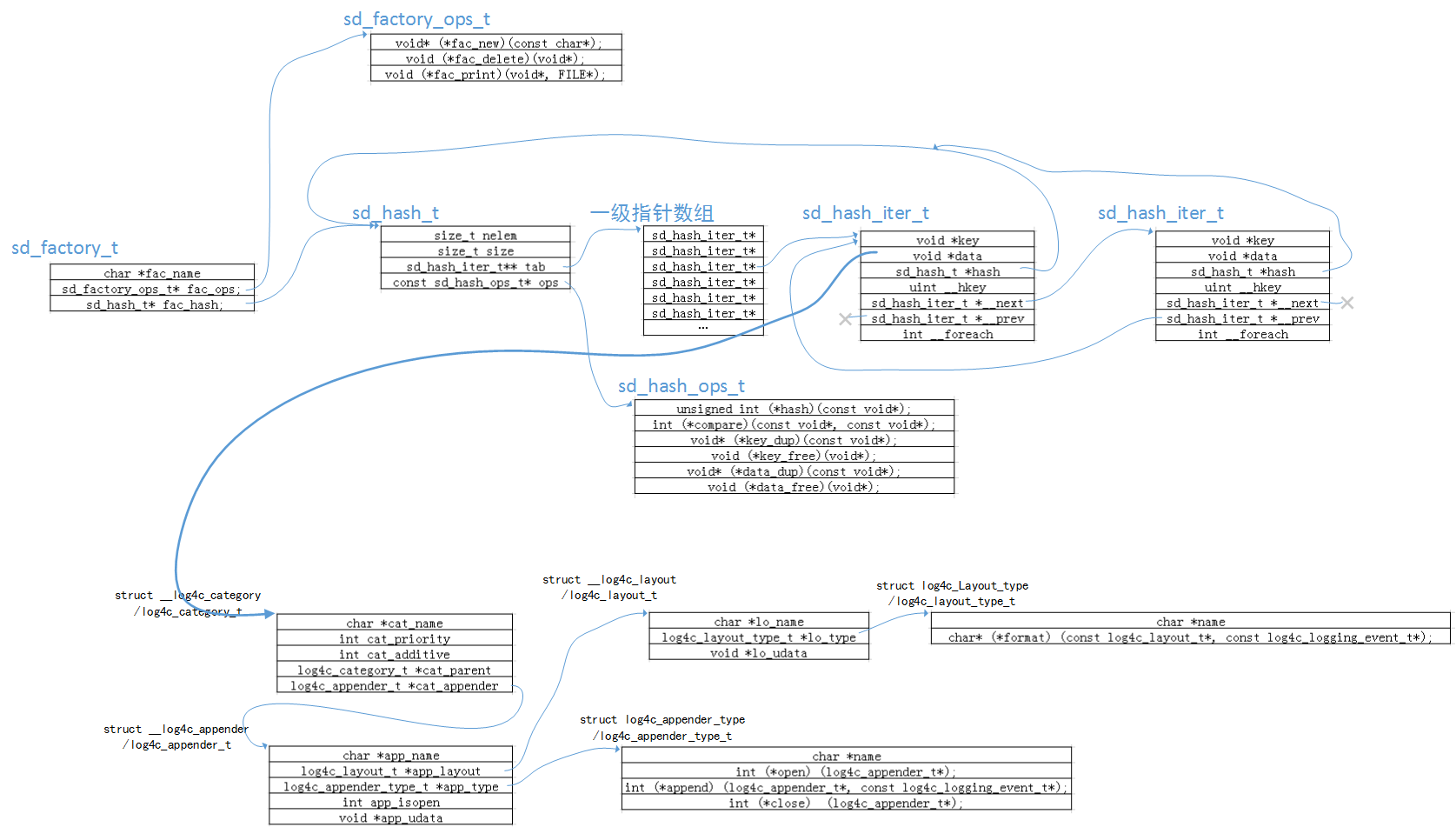
图七:sd_factory_t的组织结构
一个看着就头疼的结构,不过拆分成几个部分就比较清晰了。其实最终初始化完成之后,上面途中的hash表的data指向的都是一个个的category结构体,由于绘制出来太过于庞大,而且其结构有了上面的基础也都比较容易想象,就不在这里画初始化完成后的数据图了。
在得到category之后,接下来就是往这个category结构体里面进行属性值的填充,所有就有了下面的 log4c_category_set_priority,log4c_category_set_additivity,比较简单就不进行展开了。在加载的最后会将这个category所对应着的appender给赋值上。调用方式如下:
log4c_category_set_appender( cat, log4c_appender_get(appender->value));
extern const log4c_appender_t* log4c_category_set_appender(log4c_category_t* this,log4c_appender_t* a_appender){log4c_appender_t* previous;if (!this)return NULL;previous = this->cat_appender;this->cat_appender = a_appender;return previous;}
其实单就这个函数来说,没有什么可以说的,但是在调用的时候给出的第二个参数是:log4c_appender_get(appender->value)。这个玩意所得到的就是图八中的log4c_appender_t,然后得到了所保存的位置,或者说是所填充的位置就是上面得到的category中。如图八所示:

图八:log4c_appender_t的组织形式
上面提到的是log4c_appender_get这个调用的结果,但是得到这个结果过程的复杂程度一点儿也不亚于刚刚展开完毕的category的get过程,同样是以工厂方法进行的,同样有hash,有递归(不是相同的机制),比较值得一说的是log4c_appender_t中的udata是在这里进行初始化的,调用了log4c_appender_set_udata(log4c_appender_get("stderr"), stderr);,从这里就看到了递归不同点了。代码:
extern void* log4c_appender_set_udata(log4c_appender_t* this, void* a_udata){void* previous;if (!this)return NULL;previous = this->app_udata;this->app_udata = a_udata;return previous;}
也很显然,这个过程之后,udata的值其实就是一个文件描述符。
⑥是加载appender的内容,组织和调用关系与⑤相似。
⑦是加载layout的内容,组织和调用关系与⑤相似。
⑤⑥⑦这三个标签所用到的都是工厂方法,调用形式和组织形式都是非常像的,另外在数据填充上来说,三个之间有一个不分你我的过程,上面初始化了的hash位置,下面的初始化时就是来填充数据。在这里把三种加载方式统一的对比进行一下总结,能够体现到上面说过的工厂方法的概念,见图九:

图九:对于⑤⑥⑦三种方式调用关系
在初始化完之后,整个工厂方法在内存中所创建出来的结构如下图所示:所有的category都存在于category的工厂中,appender存在于appender的工厂中,同样layout也存在于layout的工厂中,他们之间是通过上下文查找之后用指针进行关联。最终的初始化完成后的结构图示例如下所示(用一套category->appender->layout关系进行示意):
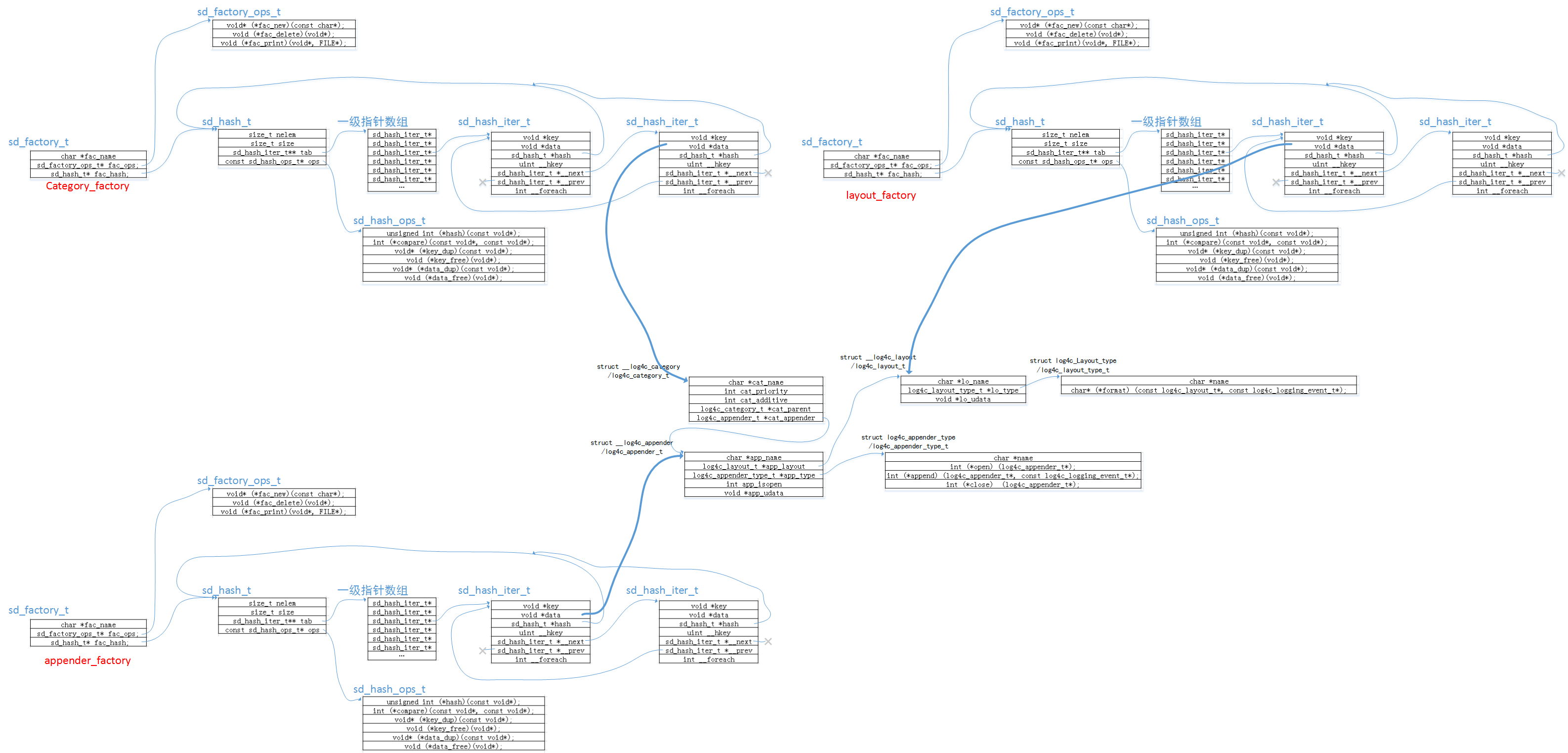
⑧config_load;就是对log4c_rc_load传进来的全局配置指针进行了几个属性的初始化,只用到了xml解析。
2、获得category的调用关系:
log4c_category_get:调用成功之后返回一个category结构体,具体组织形式见图六。这里会得到一个category,并且该category的各种信息和操作都已经填充完成,所以这个地方的数据结构的填充直接影响到了后续的使用,所以给出这里得到的category中的内容。就以helloworld中的配置文件来进行展开,我把精简后的配置情况列一下:
<?xml version="1.0" encoding="ISO-8859-1"?><!DOCTYPE log4c SYSTEM ""><log4c version="1.2.4"><config><bufsize>0</bufsize><debug level="2"/><nocleanup>0</nocleanup><reread>1</reread></config><appender name="stdout" type="stream" layout="dated"/><layout name="dated" type="dated"/><category name="log4c.examples" priority="debug" appender="stdout"/></log4c>
然后根据这个精简后的配置文件,具体得到的数据情况见图十:
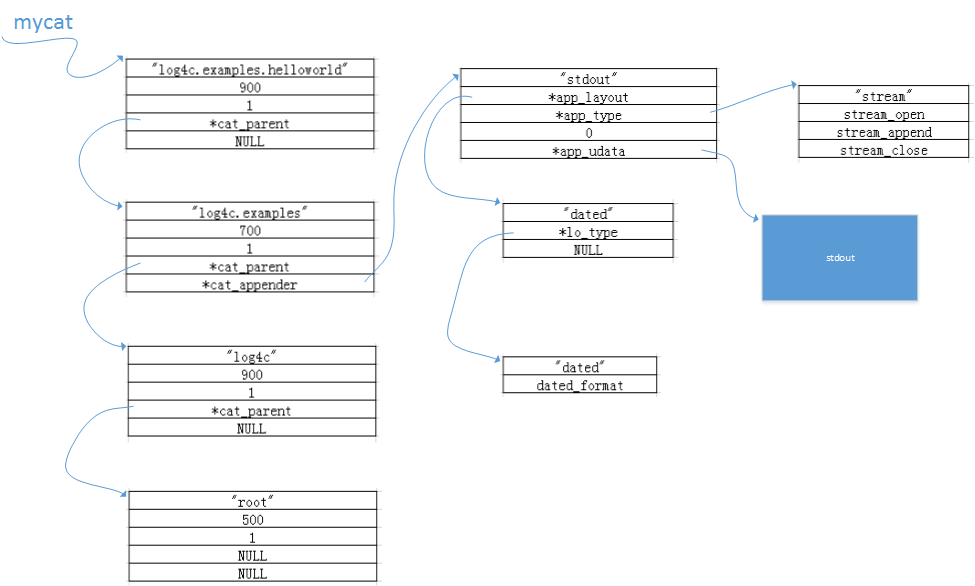
图十:得到的category结构数据
3、输出log信息的调用关系:
log4c_category_log:
start
log4c_category_is_priority_enabled(a_category, a_priority) //判断优先级决定是否打印log
①log4c_category_vlog(a_category, a_priority, a_format, va);
__log4c_category_vlog(a_category, &locinfo, a_priority, a_format, a_args);
②log4c_appender_append(cat->cat_appender, &evt);
log4c_appender_open(this)
log4c_layout_format(this->app_layout, a_event)
this->app_type->append(this, a_event);
end
① log4c_category_vlog:将log优先级,log串以及变参传入,根据category中保存的各种信息来进行组装log和输出log。
__log4c_category_vlog:在上面说的四个参数中有多加了一个locinfo结构体,里面含着当前文件,当前函数,当前行,等信息;
② log4c_appender_append:在这里将输出位置和输出格式进行确定,并且evt作为上下层之间数据交互的媒介。首先evt的结构图如图十一所示:

图十一:evt结构图(左边为结构,右边为填充后)
log4c_appender_open用来打开没有被打开的文件指针;
log4c_layout_format用来将layout指定的输出提示信息添加到log信息中。
this->app_type->append将组合好的log信息打印到指定的输出位置;
都是流式化的东西。
不过需要提到的一点就是log4c可以实现一条log消息打印到不同的输出位置。实现的该功能的代码如下:
for (cat = this; cat; cat = cat->cat_parent) {if (cat->cat_appender)log4c_appender_append(cat->cat_appender, &evt);if (!cat->cat_additive) break;}
也就是说在上诉所给出的配置信息中再多增加一些信息,这里给出一个例子,让log即输出到文件中,也输出到stdout上。
<?xml version="1.0" encoding="ISO-8859-1"?><!DOCTYPE log4c SYSTEM ""><log4c version="1.2.4"><config><bufsize>0</bufsize><debug level="2"/><nocleanup>0</nocleanup><reread>1</reread></config><rollingpolicy name="myrollingpolicy" type="sizewin" maxsize="1024" maxnum="10" /><appender name="stdout" type="stream" layout="dated"/><appender name="myrollingfileappender" type="rollingfile" logdir="." prefix="myprefix" layout="dated" rollingpolicy="myrollingpolicy" /><layout name="dated" type="dated"/><category name="log4c.examples" priority="debug" appender="stdout"/><category name="log4c.examples.helloworld" priority="debug" appender="myrollingfileappender"/></log4c>
主要就是因为在初始化的时候根据category名字中的点号进行父子关系的确认,然后在打印的时候会将孩子的信息依次根据父子关系进行输出。
4、销毁的调用关系:
log4c_fini:
start
①sd_factory_delete(log4c_category_factory);
sd_hash_delete(this->fac_hash);
sd_factory_delete(log4c_appender_factory);
sd_hash_delete(this->fac_hash);
②log4c_appender_types_free();
sd_hash_delete(this->fac_hash);
sd_factory_delete(log4c_layout_factory);
sd_hash_delete(this->fac_hash);
log4c_layout_types_free();
sd_hash_delete(this->fac_hash);
end
没啥好说的,就是先遍历hash把节点挨个的释放掉,然后再释放掉hash表。
sd_factory_delete:先释放工厂模式中hash表节点中udata,数据部分的动态申请内存,再释放hash节点。最后释放这个工厂节点
log4c_xxx_types_free:只是释放hash表中的节点就够了。
对于log4c中所实现的几个数据结构还是很有必要去一一的做一下分析和学习:
stack
hash
list
malloc
error
va_list
会逐一进行学习和记录。
附件列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号