扁平化双向链表
 每日一题
每日一题
多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
给你位于列表第一级的头节点,请你扁平化列表,使所有结点出现在单级双链表中。
示例 1:
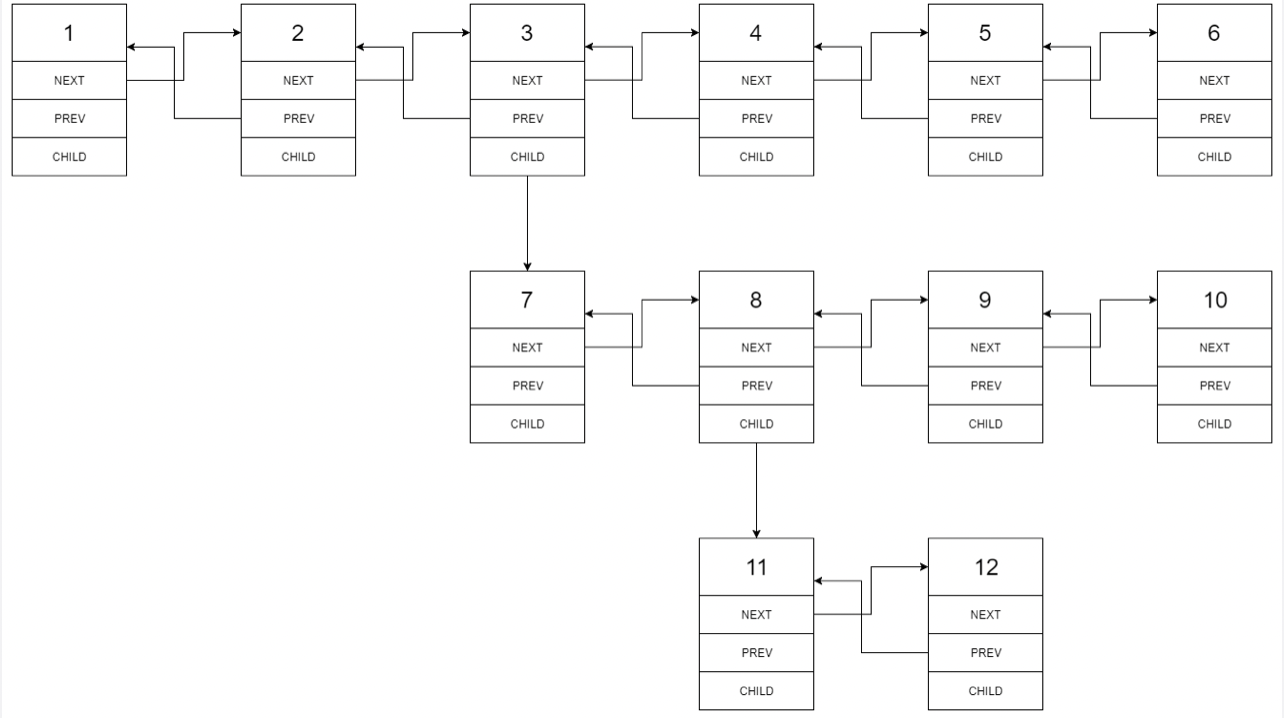
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
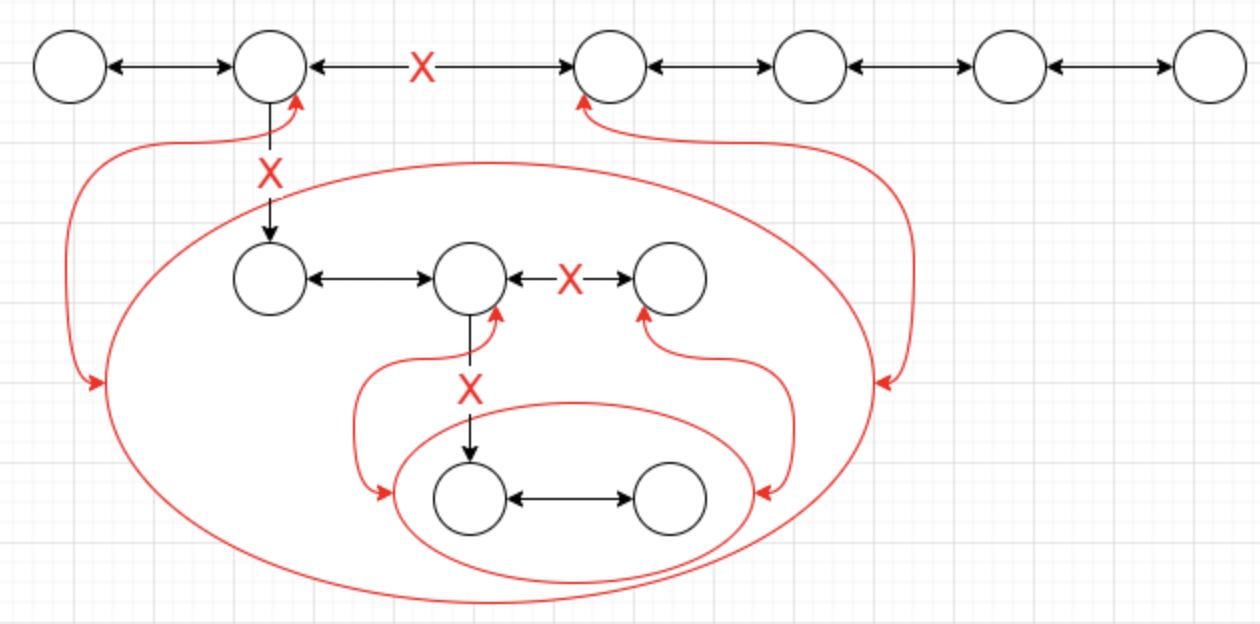
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:
输入的多级列表如下图所示:
扁平化后的链表如下图:

我们从头开始遍历,遇到有子节点的就把其子链表先扁平化,然后把子链表插入到当前节点和next节点之间即可。
DFS 在这里的作用就是先保证子链表已经扁平化,再扁平化当前层的链表,这样,最后全部处理完成就全部扁平化了。
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
};
*/
class Solution {
public Node flatten(Node head) {
// 遍历每一个节点,看它是否有子节点,有子节点的话,把它的子节点那一坨放在它和next之间
dfs(head);
return head;
}
void dfs(Node node){
//退出条件
if (node == null) {
return;
}
//子节点不为空
if(node.child != null){
Node next = node.next;
//先子链扁平化
dfs(node.child);
//把子节点的下一个节点放入主链的下一个借点,并把子节点的上一个节点当作当前节点
node.next = node.child;
node.child.prev = node;
// 寻找扁平化之后的子节点的最后一个节点(即子链表的尾)
Node tail = node.child;
while (tail.next != null) {
tail = tail.next;
}
//把子链表的尾巴和主链条的头节点链接
if(next != null){
next.prev = tail;
}
tail.next = next;
//子链条为空
node.child = null;
}else {
// 子节点为空,不需要处理
dfs(node.next);
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号