
Linux sort命令
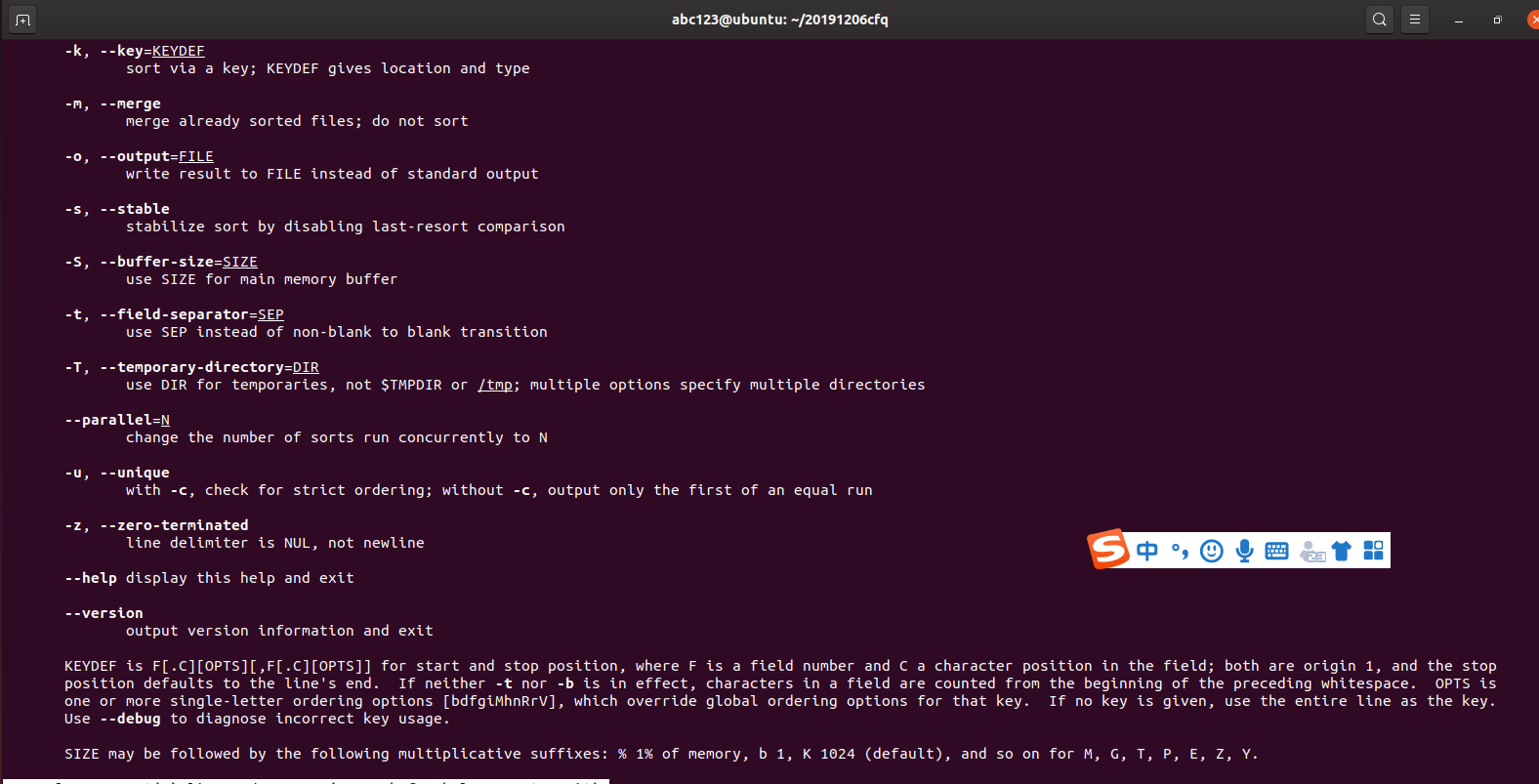
1. 用man sort 查看sort的帮助文档

2. sort常用选项功能与使用截图
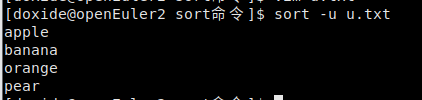
- sort的-u选项
它的作用很简单,就是在输出行中去除重复行。
u.txt:
banana
apple
pear
orange
pear
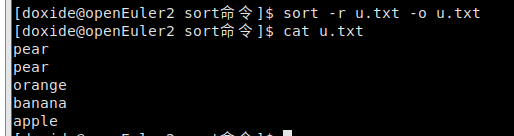
- sort的-r选项
sort默认的排序方式是升序,如果想改成降序,就加个-r就搞定了。

- sort的-o选项
由于sort默认是把结果输出到标准输出,所以需要用重定向才能将结果写入文件,形如sort filename > newfile。
但是,如果你想把排序结果输出到原文件中,用重定向不会更新文件,反而会把原文件清空。

- sort的-n选项
你有没有遇到过10比2小的情况。我反正遇到过。出现这种情况是由于排序程序将这些数字按字符来排序了,排序程序会先比较1和2,显然1小,所以就将10放在2前面喽。这也是sort的一贯作风。
这种状况,就要使用-n选项,来告诉sort,“要以数值来排序”!

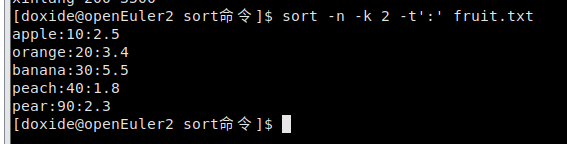
- sort的-t选项和-k选项
如果有一个文件的内容是这样:
banana:30:5.5
apple:10:2.5
pear:90:2.3
orange:20:3.4
peach:40:1.8
这个文件有三列,列与列之间用冒号隔开了,第一列表示水果类型,第二列表示水果数量,第三列表示水果价格。
那么我想以水果数量来排序,也就是以第二列来排序,如何利用sort实现?
幸好,sort提供了-t选项,后面可以设定间隔符。
指定了间隔符之后,就可以用-k来指定列数了。
- 更复杂一点
data.txt
公司 人数 工资
google 110 5000
baidu 100 5000
guge 50 3000
sohu 100 4500
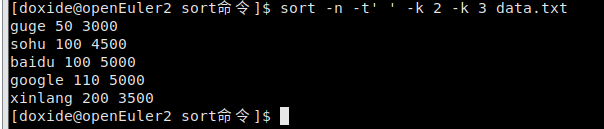
- 让fdata.txt按照人数排序 ,人数相同的按照员工平均工资升序排序:
sort -n -t‘ ’ -k 2 -k 3 data.txt
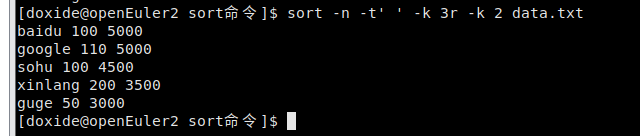
- 让data.txt按照员工工资降序排序,如果工资相同的,则按照公司人数升序排序
sort -n -t ‘ ‘ -k 3r -k 2 data.txt
- 其他的sort常用选项
-f会将小写字母都转换为大写字母来进行比较,亦即忽略大小写
-M会以月份来排序,比如JAN小于FEB等等
-b会忽略每一行前面的所有空白部分,从第一个可见字符开始比较。
3. sort实现
写出伪代码和相关的函数或系统调用
本来只想写个最简单的功能,没有参数的,但写着写着,觉得实现个 -o 也不难,
又写着写着,觉得实现个 -r也不难,又写着写着,觉得实现个 -k也不难
再写着写着,觉得实现个 -t加-k 虽然有点难度,但也不是不能实现,
既然都这样了,也没差几个参数了,再实现个 -n、-u 和 -f吧。。。
最后也不差个 -b了
代码全部原创,肯定还是有疏忽之处,欢迎留言评论
Linux C编程
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define N 100
#include <ctype.h>
//位图(字符图)
unsigned char flag[10];
char *token;
int key=1;
//-f 小写转大写
char *strupr(char *str){
char *orign=str;
for (; *str!='\0'; str++)
*str = toupper(*str);
return orign;
}
//-b 删除前导空格
char *trim(char *str){
char *p = str;
while (*p == ' '){
p++;
}
return p;
}
/*
flag[0] : -u
flag[1] : -r
flag[2] : -n
flag[3] :-o
flag[4] :-k
flag[5] : -t
flag[6] : -b
flag[7] : -f
*/
int cmp_string(const void* _a , const void* _b) //参数格式固定
{
int result = 0;
char *a = (char*)malloc(sizeof((char*)_a));
strcpy(a,(char*)_a);
char *b = (char*)malloc(sizeof((char*)_b));
strcpy(b,(char*)_b);
//-f
if(flag[7]){
strupr(a);
strupr(b);
}
//-b 删除前导空格
if(flag[6]){
a = trim(a);
b = trim(b);
}
//不切分
result = strcmp(a,b);
//-k
if(flag[4]==1 && flag[5]==0){
result = b[key-1] - a[key-1];
}
//如果-t切分,会分成count个组
int count = 1;
if(flag[5]==1){
for(int i=0;i<strlen(a);i++){
if(a[i]==token[0]){
count++;
}
}
}
char *array1[count];
char *array2[count];
//-t
if(flag[5]){
//split,把字符串a,b分成字符串数组array[1],array[2]
char * str1;
str1 = strtok(a,token);
int aut=6;
int i = 0;
while( str1 != NULL ) {
array1[i] = str1;
str1 = strtok(NULL, token);
i++;
}
char * str2;
str2 = strtok(b,token);
i = 0;
while( str2 != NULL ) {
array2[i] = str2;
str2 = strtok(NULL, token);
i++;
}
}
//-k & -t 没有n || 只有 -t
if(flag[5]==1 && flag[2]==0){
if(key<1){
perror("-K Error");
exit(1);
}
result = strcmp(array1[key-1],array2[key-1]);
}
//-k & -t & -n
if(flag[4]==1 && flag[5]==1 && flag[2]==1){
if(key<1){
perror("-K Error");
exit(1);
}
result = atoi(array1[key-1]) - atoi(array2[key-1]);
}
//-r
if(flag[1]){
return result*-1;
}
return result;
}
void sortFile(const char *route,const char *outFile){
//打开文件输入文件
FILE *fp;
if(strcmp(route,"stdin")==0){
fp = stdin;
}else{
fp = fopen(route,"r");
}
if(fp == NULL){
perror("inFile Open Error");
exit(1);
}else{
printf("File open Success\n");
}
//读取文件
char buf[N][N];
char hor=12;
int n = 0;
while(fgets(buf[n],N,fp)!=NULL){
if(strcmp(buf[n],"EOF\n")==0){
break;
}
n++;
if(n>=N){
printf("buffer overflow\n");
break;
}
}
fclose(fp);
// for(int i=0;i<n;i++){
// printf("%s",buf[i]);
// }
//排序
qsort(buf,n,sizeof(buf[0]),cmp_string);
//输出
printf("\nAfter sorted:\n");
if(strcmp(route,"stdout")==0){
fp = stdout;
}else{
fp = fopen(outFile,"w");
}
if(fp == NULL){
perror("outFile Open Error");
exit(1);
}else{
printf("File open Success\n");
}
for(int i=0;i<n;i++){
//-u
if(flag[0] && i!=0){
if(strcmp(buf[i],buf[i-1])==0){
continue;
}
}
fputs(buf[i],fp);
}
fclose(fp);
}
int main(int argc,char *argv[]){
printf("argc = %d\n",argc);
char *outFile="stdout";
//如果没有参数
if(argc==1){
sortFile("stdin",outFile);
return 0;
}
//获取参数,做成假位图
memset(flag,0,10);
/*
char[0] : -u
char[1] : -r
char[2] : -n
char[3] :-o
char[4] :-k
char[5] : -t
char[6] : -b
char[7] : -f
*/
const char *inFile = NULL;
int skip=0;
for(int i=1;i<argc;i++){
//跳过-o后的参数(outFile)
if(skip==1){
skip = 0;
continue;
}
if(strcmp(argv[i],"-u")==0){
flag[0]=1;
}else if(strcmp(argv[i],"-r")==0){
flag[1]=1;
}else if(strcmp(argv[i],"-n")==0){
flag[2]=1;
}else if(strcmp(argv[i],"-o")==0){
flag[3]=1;
skip=1;
outFile =argv[i+1];
}else if(strcmp(argv[i],"-k")==0){
flag[4]=1;
key=atoi(argv[i+1]);
skip=1;
}else if(strcmp(argv[i],"-t")==0){
flag[5]=1;
token = argv[i+1];
skip=1;
}else if(strcmp(argv[i],"-b")==0){
flag[6]=1;
}else if(strcmp(argv[i],"-f")==0){
flag[7]=1;
}else{
inFile = argv[i];
}
}
// for(int i=0;i<10;i++){
// printf("%d",flag[i]);
// }
// printf("\n");
// printf("%s\n",inFile);
sortFile(inFile,outFile);
return 0;
}
Afer sorted: 之前都是调试信息,不必在意
Afer sorted: 之后没有终端输出的,就是输出到 -o 的文件里了
运行效果:
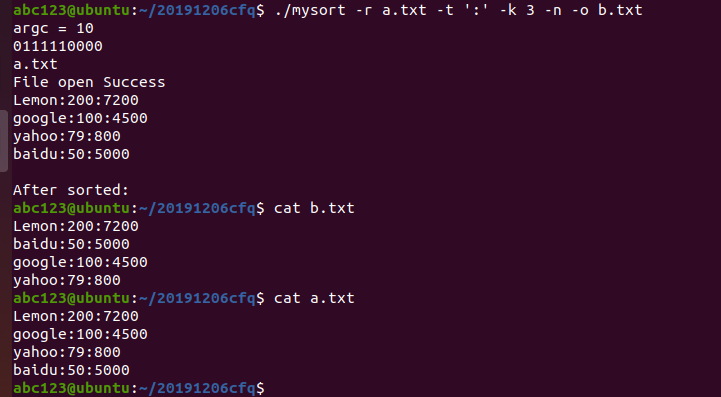
./mysort -r a.txt -t ':' -k 3 -n -o b.txt
以':'分割成多个字段,按照第三个字段的数值大小,降序排序,输出到b.txt
./mysort a.txt -k 3 -r
按照第3个字符,降序排序

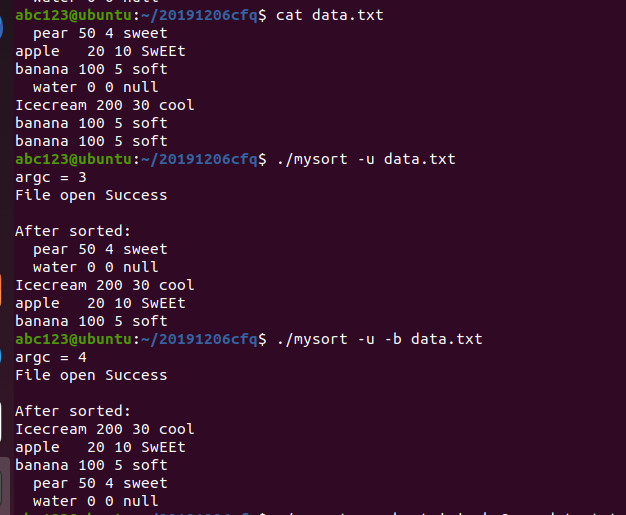
./mysort -u -b data.txt
忽略重复数据,忽略前导空格
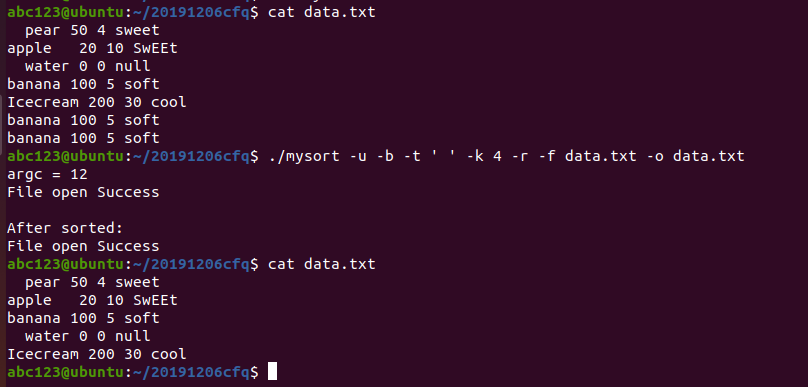
./mysort -u -b -t ' ' -k 4 -r -f data.txt -o data.txt
忽略重复数据,忽略前导空格,以空格为分割符,取分割后的第四个域的数据为key,忽略大小写,降序排序,并将结果输出到原文件
https://gitee.com/cfqlovem-521/linux-sys-program1206/tree/master/lesson

 浙公网安备 33010602011771号
浙公网安备 33010602011771号