OO第一单元作业总结
1.作业概述
第一单元的作业总共有三次,分为三周完成,核心目标是在逐步提高要求和难度的基础上,迭代开发对表达式进行恒等化简的程序。其中,第一次作业仅仅包含单一变量和单层括号,第二次作业增加了简单三角函数因子,求和函数,自定义函数和多层括号嵌套,第三次作业要求支持三角函数因子内部嵌套一般表达式。可见,程序的功能是逐步强大和完善的,对编程能力和面向对象思维的要求也是逐步提高的。需要指出的是,每次作业都有两种输入模式可以选择,分别为预解析模式和一般输入模式,其中预解析模式已经完成对输入的解析,只需完成计算和化简,是对于不熟悉java语言和面向对象思维的同学的一种降低难度的选择。
2.思路与架构设计
2.1第一次作业
2.1.1 输入模式选择及理由
一般输入模式。第一次作业难度较低,我对求解有一定自信,而且预留了两天时间写代码,故选择一般输入模式。
2.1.2 思路
对输入的表达式,先借助正则表达式祛除空白符(题目中为空格和制表符),把连续的正负号转变为单一的正负号。由于第一次作业只涉及单层括号,因此我的解析过程只专注于括号内和括号外两个方面,亦即,识别到左括号进行括号内层的解析,未识别到左括号进行括号外层的解析,解析终止点为正负号,括号内层解析的结果最终会并入括号外层解析的结果。同时,解析和计算的同时进行的,计算指的是项内因子的乘法化简。对最后的解析计算结果进行输出即为所求。
2.1.3 架构分析和说明
第一次作业的UML图如下:
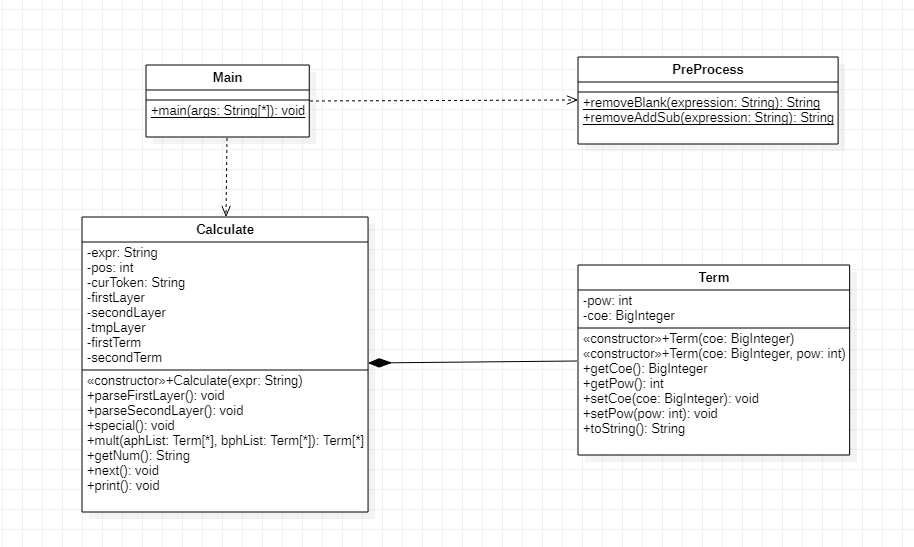
第一次作业总共设计了4个大类,其中main作为主类,为程序的入口,是直接面向用户的,它依赖于PreProcess和Caculate两个类。PreProcess完成了对表达式的初步化简,亦即借助正则表达式祛除空白符(题目中为空格和制表符),把连续的正负号转变为单一的正负号。Calculate负责的是对表达式括号内外层的解析和化简计算,有三个关于Term类的arraylist集合,其中firstLayer保存的是括号外解析计算的结果,secondLayer保存括号内解析计算的结果,tmLayer保存括号内临时解析计算的结果。输入的表达式可能出现连续多个带括号的表达式因子相乘,需要一个tmLayer保存临时的括号内解析计算的结果,如果secondlayer是空的,就将临时结果存入secondLayer,否则替换secondLayer中的内容,无论是直接存入还是替换,都要清空tmLayer,直到识别到正负号,将secondLayer中的结果存入fisrtLayer,并且清空secondLayer。至于Term类,指的是化简以后的项,在第一次作业中只需要考虑x的指数pow和系数coe。其他类的属性和方法含义含义明显,不再赘述。
2.2 第二次作业
2.2.1 输入模式选择及理由
预解析模式。因为各种原因耽误了时间,只有一天写代码,加之对面向思维参悟不够,出于稳妥考虑,不得不采用了降低难度的预解析模式。
2.2.2 思路
解决问题的核心在于HashMap的嵌套使用。HashMap的优势在于,可以针对唯一的key,快速寻找到对应的value。我将表达式的每一项除以其系数的部分作为key,每一项的系数作为value,存放在顶层的HashMap中。每一项除以其系数的部分的信息,又单独作为一个类,其中成员有关于三角函数sin因子乘积的HashMap和三角函数cos因子乘积的HashMap。两种三角函数的HashMap,都以函数括号内部的信息作为key,函数的指数作为value。整体采用边计算边合并同类项的操作。关于输出,同样借助于HashMap。预解析模式得到的子表达式包含的内容都是标签,操作符,操作数。我以标签作为key,标签对应的表达式作为value,每次计算出一个标签对应的表达式,就把标签和对应表达式的键值对存入HashMap中。最后结果只需要针对最后一个标签寻到到对应表达式输出即可。
2.2.3 架构分析和说明
第二次作业的UML图如下:
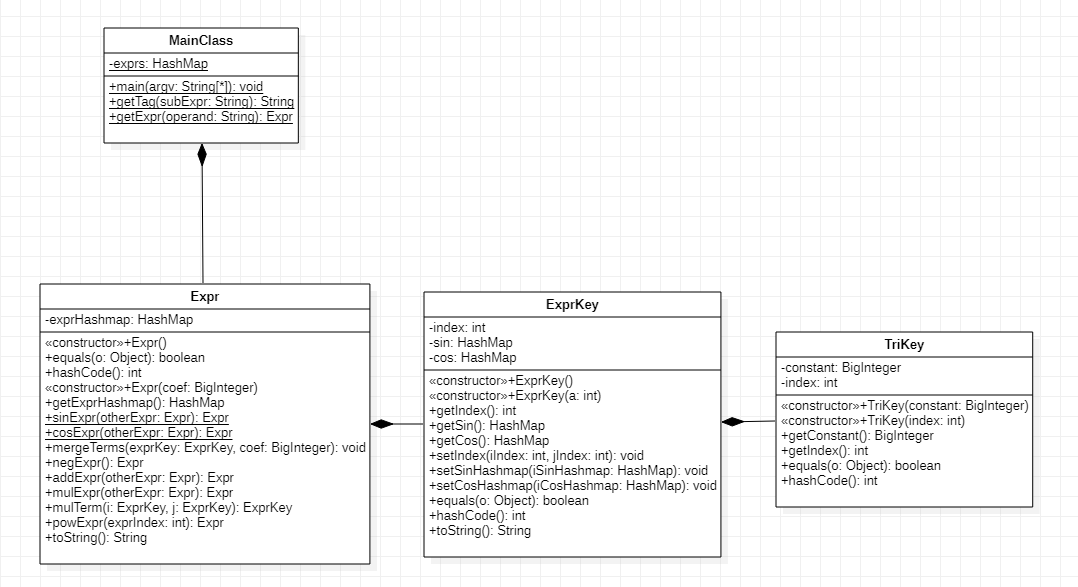
第二次作业总共设计了4个大类,其中MainClass作为主类,为程序的入口,是直接面向用户的。MainClass的getExpr方法以预解析后子表达式中的操作数(或者x或者常数)为参数,对应的表达式为返回值,getTag方法以以标签()为参数,对应的表达式作为返回值。Expr类的属性只有一个以ExprKey类作为key,Biginteger作为value的HashMap,其中ExprKey保存的是每一项除以其系数后的信息,Biginteger是每一项的系数。Expr类中含有跟表达式的加减乘除等题目涉及的计算的方法。ExprKey类的成员中,index表示该项x的指数,sin存的的是该项涉及的各个不同sin因子的信息,cos存的的是该项涉及的各个不同cos因子的信息,sin和cos都是HashMap,以函数内部的信息也就是TriKey类作为key,函数的指数作为value。由于第二次作业三角函数内部只可能是常数或者冥函数,因此TriKey只有常数constant和冥函数的指数index作为属性。特别指出,为了保证除系数相同的项只作为Expr的唯一key,函数内部信息相同的三角函数因子只作为ExprKey中sin或者cos唯一的key,对ExprKey和TriKey都重写了hashcode和equals方法,具体写法只需使用alt+insert快捷键在idea中自动生成。所有类其余方法根据方法名即可判定其含义,不再赘述。
2.3 第三次作业
2.3.1 输入模式选择及理由
预解析模式。第二次作业已经使用了预解析模式,而且第三次作业难度最大,考虑到时间有限和能力的可行性,依然坚持沿用第二次作业的思路,故选择预解析模式。
2.3.2 思路
整体思路几乎与第二次作业一致。区别主要在于,表示三角函数因子乘积信息的HashMap不需要额外构建一个表示三角函数内部信息的类作为key,可以直接以表达式本身作为key。在此基础上,对表达式有关计算的相关方法稍作更改即可。
2.3.3 架构分析和说明
第三次作业的UML图如下:
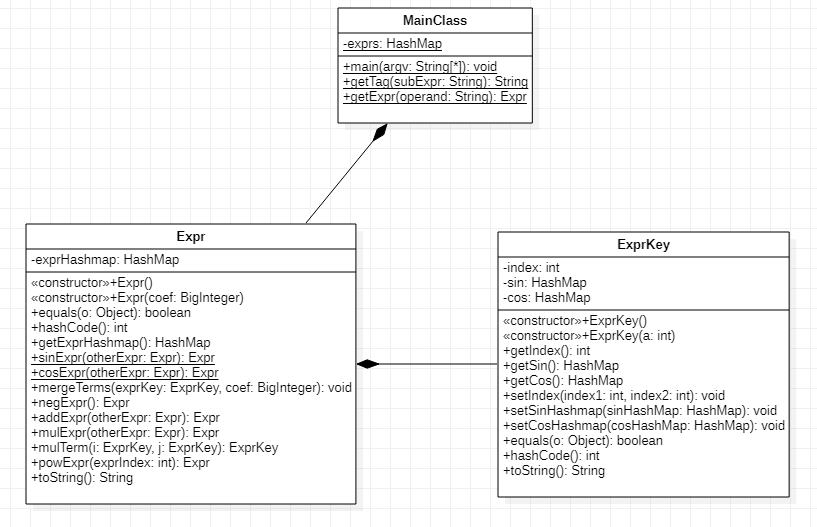
相比第二次作业,少了一个类,除了以Expr类直接作为ExprKey类中sin和cos两个HashMap中的key以外,其余属性和方法含义与第二次作业完全相同。特别指出,为了保证函数内部信息相同的三角函数因子只作为ExprKey中sin或者cos唯一的key,重写了Expr的hashcode和equals方法,具体写法仍然是使用alt+insert快捷键在idea中自动生成。
3.复杂度分析
表1和表2分别为类的复杂度分析指标信息和方法的复杂度分析指标信息。
表1 类复杂度评价指标信息
|
指标 |
信息 |
|
OCavg |
代表类的方法的平均循环复杂度。 |
|
OCmax |
代表类的方法的最高循环复杂度。 |
|
WMC |
代表类的总循环复杂度。 |
表2 方法的复杂度评价指标信息
|
指标 |
信息 |
|
Cogc |
代码可读性,数值越大代码可读性越差 |
|
ev(G) |
代码非结构化复杂度,数值越高代码的结构性越差 |
|
iv(G) |
函数调用关系的复杂度,数值越高函数耦合就越紧密。 |
|
v(G) |
圈复杂度,它由if,else,while,for,break,continue,switch等流程控制语句计算出,数值越大代表函数复杂度越大,可扩展性越差,维护成本越高。一般来说,各函数的圈复杂度应控制在10以内 |
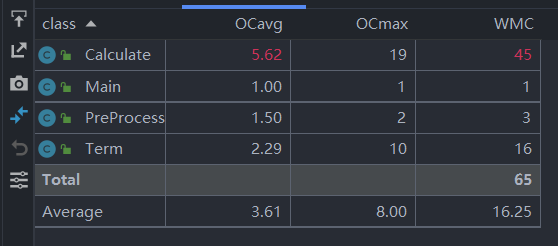
使用IDEA的MetricsReload插件对三次作业的复杂度进行分析,结果如下。
第一次作业:
·类的复杂度分析
·方法的复杂度分析
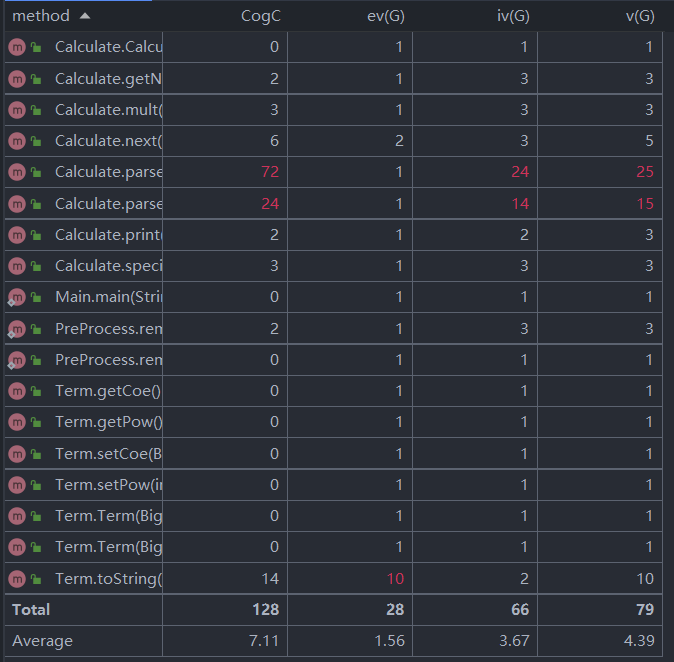
第二次作业:
·类的复杂度分析
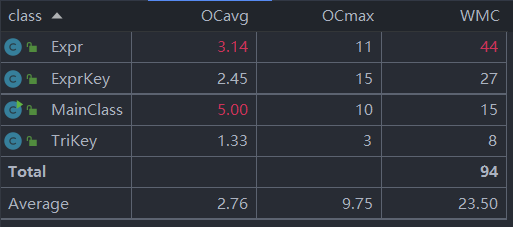
·方法的复杂度分析

第三次作业:
·类的复杂度分析

·方法的复杂度分析
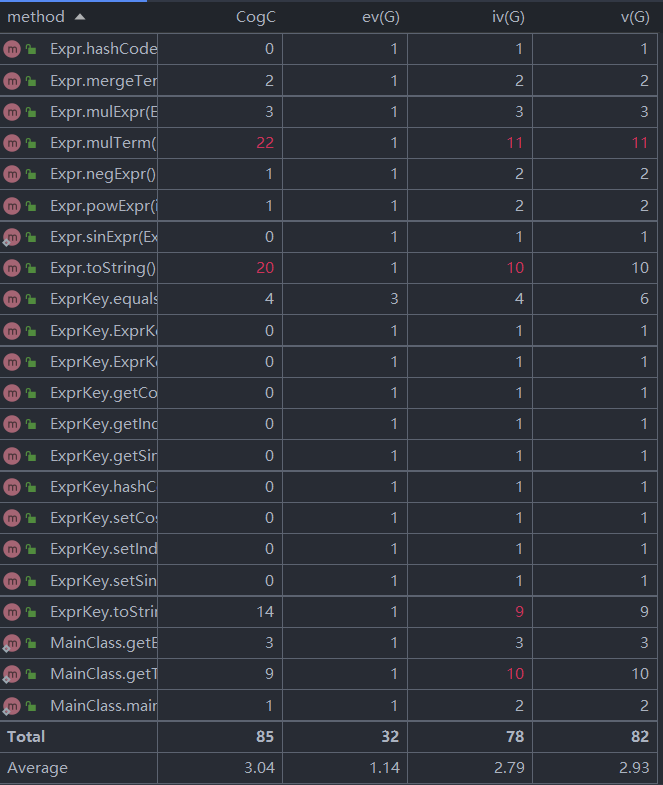
对以上表格分析可以得出,我的三次作业复杂度数据相近。平均而言,类的循环复杂度都比较低,方法都满足可读性较好,结构性较好,耦合性较低,圈复杂度较低。基本实现了代码编译的高内聚,低耦合的目标。只有部分类和方法相关数值偏大,于于我的能力而言,这在可以接受的范围内。
4.优缺点分析
4.1 优点
三次作业思路明确,代码可读性高,算法难度低。以上复杂度分析的数据表明,三次作业基本实现了面向对象高内聚、低耦合的开发原则。尤其是第二次作业到第三次作业的跨越,只需更改不到二十行的代码,什么可以减少一个类,让更高难度的第三次作业反倒比第二次作业代码有所简化,符合迭代开发的特点。
4.2 缺点
没有完全采用面向对象的思维,类的数量太少,单一类代码量过于庞大。其中第一次作业没有做足够的有关结果化简的性能优化,代码没有复用性,以至于第二次作业必须彻底重构。并且,三次作业涉及结果输出的toString方法都有bug,为后期的强侧和互测留下了隐患。
5.作业bug分析和互测策略
5.1 作业bug分析
三次作业的强侧和互测bug全部来自于toString,错误来源主要是输出格式不符合要求。第一次作业后,我非常疲劳而且情绪低落,因而当时没有关注强侧和互测结果。第二次作业在提交截止前算法出错,没有形成有效作业,虽然纠正了算法错误,并在此基础上完成了第三次作业,但是并不知道自己相对第一次作业重构后的toString方法有bug,直到第三次作业强侧和互测结果公布,如今已经修复。
5.2 互测策略
老实说我是非常反感这个环节的,我到第三次互测才参与进来。也没啥特别的方法,随机选取互测房内某个同学的代码阅读,根据自己的理解在本地用一些极端或者临界数据测试,或者用他人写的python程序随机生成数据并生成标准答案与房内某位同学的这些随机数据对应答案比对,发现错误就发起hack,成功了6次。
6.心得与体会
6.1 心得
初步理解面向对象的思维,其重在成员和行为的包装,代码的抽象性和复用性,也感受到了迭代开发的乐趣。通过向助教和同学请教,学到了不少技巧和算法,让自己的编程能力有了一定提高。
6.2 体会
我想我最真实的体会,除了学习本身有关的之外,更多是是心累和无奈吧。我寒假没有预习,开学就做这种难度的作业无异于暴击。以我的能力而言,这就是揠苗助长了。我多次熬夜感到绝望,无奈地落泪。我寒假没有偷懒,冯如杯和美赛都耗费了很多时间,我也只是一个普通人,不是机器,需要休息,这样的情况下,开学留给我一个缓冲器去适应,是很过分的要求吗?更何况,我身体条件一直欠佳,实在经不起这种强度的折腾,开学的这三次作业的消耗,我至今都没有完全恢复过来。课程组一直强调这样的锻炼很有意义,老师也说难度逐年提高,并且不在乎背后大家的议论,我真心无法认可,意义再大,还是要讲究人道,老师可以不在乎别人怎么评价,作为学生的我们,可以不在乎自己的感受吗?这实在是自我中心了。不管我怎么说,我终归人微言轻,一个人的力量不可能是体制的对手,除了选择继续坚持,也就最多骂骂咧咧中寻求所谓的意义了。希望这门课,至少能在很多年后,能站在学生的角度想想怎么去发展,而不是只以自己的立场为动力。最后附上本人一张心情图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号