
redis杂记
以下内容部分为博客复制。
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
redis是Nosql数据库中使用较为广泛的非关系型内存数据库,redis内部是一个key-value存储系统。它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set –有序集合)和hash(哈希类型,类似于java中的map)。Redis基于内存运行并支持持久化的NoSQL数据库,是当前最热门的NoSql数据库之一,也被人们称为数据结构服务器。
Redis生存时间
在实际开发中经常会遇到一些有时效的数据,比如限时优惠活动、缓存或验证码等,过一段时间需要删除这些数据。在关系数据库中一般需要维护一个额外的字段来存储过期时间,然后定期检测删除过期数据。而在redis中命令就可以搞定。
1、命令
expire key seconds:返回1表示设置成功,0表示设置失败或该键不存在;

127.0.0.1:6379> set lifecycle 'test life cycle' OK 127.0.0.1:6379> get lifecycle "test life cycle" 127.0.0.1:6379> expire lifecycle 30 #设置生存时间为30秒,最小单位是秒 (integer) 1 127.0.0.1:6379> ttl lifecycle #ttl查看还剩多久 (integer) 13 127.0.0.1:6379> ttl lifecycle (integer) 11 127.0.0.1:6379> ttl lifecycle (integer) 9 127.0.0.1:6379> ttl lifecycle (integer) 8 127.0.0.1:6379> ttl lifecycle #当时间到了删除后会返回-2,不存在的键也返回-2 (integer) -2
取消设置时间:persist key
除了专用的取消命令,set,getset命令也会清除key的生存时间。
pexpire key mileseconds 精确到毫秒
Redis持久化原理
Redis提供了两种方式对数据进行持久化,分别是RDB(Redis DataBase)和AOF(APPEND ONLY FILE)。RDB持久化方式能够在指定的时间间隔对数据进行快照存储。AOF持久化方式记录每次服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写操作到文件末尾。Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。不过,出于性能考虑,redis的持久化一般都是不开启的。如果同时开启两种持久化方式,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
了解一下持久化的C语言实现。Redis需要之执行RDB的时候,服务器会执行以下操作:redis调用系统函数fork(),创建一个子进程。子进程将数据集写入到一个临时RDB文件中。当子进程完成对临时RDB文件的写入时,redis用新的临时RDB文件替换原来的RDB文件,并删除旧RDB文件。在执行fork时linux操作系统(一般大公司的服务器都是这个系统)会使用写时复制(copy-on-write)策略,即fork函数发生的一刻父子进程共享同一内存数据,当父进程要更新其中某片数据时,操作系统会将该片数据复制一份以保证子进程的数据不收影响,所以新的RDB文件存储的是之执行fork那一刻的内存数据。(官网:www.fhadmin.org)RDB文件是经过压缩的二进制格式,所以占用的空间会小于内存的数据大小。但是压缩操作很占CPU,所以可以通过配置文件配置禁止压缩。
了解一下对应的redis命令。除了自动快照,还可以手动发送save或者bgsave命令让redis直行快照。save命令是在主进程上进行的,会阻塞其他请求。后者会fork子进程进行快照操作。
和mysql存储比较。RDB方式比较类似于mysql的mysqldump命令备份。而AOF更接近于binlog。
Redis内存优化
redis配置文件中有个maxmemory参数设置,如果没有设置会继续分配内存,因此可以逐渐吃掉所有可用内存。因此,通常建议配置一些限制和策略。这样做的优点是:不会导致因为内存饥饿而整机死亡。缺点是:Redis可能会返回内存不足的错误写命令。redis有6种过期策略。
1>volatile-lru:只对设置了过期时间的key进行LRU
2>allkeys-lur:对所有的key进行LRU
3>volatile-random:随机删除即将过期的key
4>allkeys-random:从所有的key中随时删除
5>volatile-ttl:删除即将过期的,ttl(tiime to live)剩余生存时间
6>noeviction:永不过期,返回错误
参数的设置可以采用命令方式,也可以采用配置文件方式(所有的配置都支持这两种),配置命令如
config set maxmemory-policy volatile-lru
还可以设置随机抽样数,如
config set maxmemory-samples 5 就是说每次进行淘汰的时候,会随机抽取5个key从里面淘汰最不经常使用的。
关于redis队列的实现方式有两种:
1、生产者消费者模式。
2、发布者订阅者模式。
详解:
1、生产者消费者模式。
普通版本:
比如一个队列里面,生产者A push了一个数据进去,消费者B pop 了这个数据,那个这个队列依旧为空。所以是一对一的。
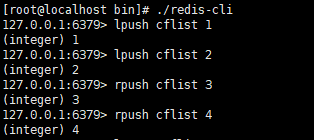
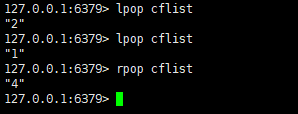
至于是先进先出还是先进后出等,可以依照函数lpush(从队列左边,也就是队首push一个数据) rpush(从队列右边也就是队尾push一个数据) lpop(同理) rpop等来控制。
插入数据:
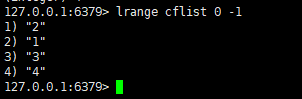
显示数据:
取出数据:
阻塞版本:
但是上面的命令都是立即返回的,无论数据有无,关于取数据lpop有个增强版本,blpop(block left pop)阻塞版本,
使用方法:blpop key1 key2 ... keyn 10
同时预获取多个key的值,并设置超时时间为10s,按顺序获取每个队列中的value,如果所有的队列都被清空了,则阻塞3秒返回
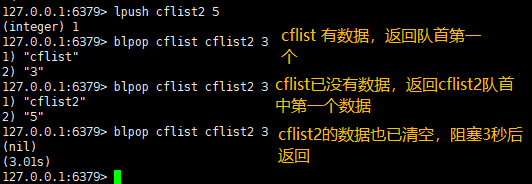
关于blpop多个key返回数据的顺序,比如blpop cflist cflist2 3这个命令,先检查cflist有数据就返回,如果没有数据,就检查cflist2依次。。。。直到所有key检查完如果都没有数据就阻塞。
这种从多个队列里面取数据的方式可以用来做优先级的队列,比如cflist队列的优先级高于mcflist2,push的时候,高优先级就push到cflist里面,普通优先级就push到cflist2里面,
这样就会先取mylist里面的高优先级的数据来处理。
但是,如果遇到队列的优先级等级过多,比如有(0-9999)个优先级,上面就不行了。解决思路是插入的时候先把数据取出来自己实现二分查找找出该插入的位置,用lset命令插入。
如果数据过多,比如队列有几十万,可以把队列分成几十个或几百个小队列,比如0号队列存优先级为(0-1000),1号队列存优先级为(1001-2000)的数据,依次。。。。。
由于这种队列模式pop出来一个后就返回了,所以处理业务的时候最好把pop写在一个while(true){pop.....do logic}循环里面。
2、发布者订阅者模式
概念:
三个用户A,B,C同时都订阅了一个channel名字叫msg,然后发布者往msg的channel里面发布了一个数据,那么A,B,C三个用户都会收到该数据。
注意:
1、很明显,三个用户ABC需要阻塞。怎么收到订阅的数据呢,肯定是依靠注册在redis里面的回调函数。
2、发布的数据不会在redis里面复现,意思就是发布了以后,A,B,C由于种种原因没收到就没收到。。。。
直接上代码:
发布者:

$redis = new Redis();
$re = $redis->connect('127.0.0.1','6379');
// var_dump($re);exit;
$type = 'msg';
$msg = "fuck sem";
$result = $redis->publish($type , $msg); //同步操作,第一个参数是channel,第二个参数是数据
if (empty($result)) {
echo 'publish failed';
}else{
echo 'publish success';
}
订阅者:
$redis = new Redis();
$redis->connect('127.0.0.1','6379');
$type = 'msg';
$msg = "fuck sem";
// $result = $redis->publish($type , $msg);
$result = $redis->subscribe(array($type) , 'callback'); //异步阻塞,有消息来自动调用callback函数
function callback($redis , $type , $msg){
//这里处理逻辑
echo $type."==>". $msg."\r\n";
}
两种方式比较:
1、生产者消费者模式需要 消费者主动去拉数据,如果写成死循环并且阻塞模式,就和第二种方式差不多了。
2、发布者订阅者模式的数据并不存在于某个key里面,如果订阅者没收到则该数据就丢失了。
用redis的list当作队列可能存在的问题
1)redis崩溃的时候队列功能失效
2)如果入队端一直在塞数据,而出队端没有消费数据,或者是入队的频率大而多,出队端的消费频率慢会导致内存暴涨
3)Redis的队列也可以像rabbitmq那样 即可以做消息的持久化,也可以不做消息的持久化。
当做持久化的时候,需要启动redis的dump数据的功能.暂时不建议开启持久化。
Redis其实只适合作为缓存,而不是数据库或是存储。它的持久化方式适用于救救急啥的,不太适合当作一个普通功能来用。应为dump时候,会影响性能,数据量小的时候还看不出来,当数据量达到百万级别,内存10g左右的时候,非常影响性能。
4)假如有多个消费者同时监听一个队列,其中一个出队了一个元素,另一个则获取不到该元素
5)Redis的队列应用场景是一对多或者一对一的关系,即有多个入队端,但是只有一个消费端(出队)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号