
mysql学习笔记三--关于索引
当一个表的数据量达到一定程度时,查询速度会急速下降,这时候就需要适当地添加索引来加快查询速度。虽然在日常工作中会经常接触到索引,上周翼赛用户登录部分,当通过oauth_id查询race_user_oauth_token表的数据记录时,平均一次查询需要3s以上,在用户数量集中增长时,导致数据库压力急剧增长,当为oauth_id添加索引后,一切都恢复正常。虽然每天都能接触到索引,但好像对其都是一知半解的,于是决定查看相关的书本、专栏和博客来深入学习一下mysql的InnoDB索引。
1、为什么需要索引?
索引类似于书本的目录,最终都是为了提高查询效率而存在的。
2、常见的索引数据模型主要有三种:哈希表、有序数组以及树。
(1)哈希表是一种键值对存储方式,相信大家都比较熟悉了,把值放在数组里,用一个哈希函数把key换算成一个确定的位置,然后把value放在数组的这个位置。但是这样经常会引发哈希冲突,解决哈希冲突常用的方法是链表,当不同的值经过哈希函数处理后对应的key是同一个是,这些值就用指针连接起来形成链表。哈希表在等值查询的场景中表现非常优秀,比如redis以及memcached等nosql存储方式。但是哈希表并不适用于区间查询,当需要区间查询时,只能全表扫描了。这种存储方式很适合数据库的主键查询,但当不是根据主键查询时,我们需要另外存储一遍key对应的所有记录。例如,当前存储的user记录为uid对应user record,但当我们需要通过user name来获取user record时,我们需要将username作为key再进行存储,因此虽然查询效率非常高,但是确实有点类似于拿空间换时间的做法,之前翼赛用户登录部分防止高并发对用户数据进行redis缓存了就存储了很多遍相同的用户记录,对应不同的key。
(2)有序数组相信大家都非常熟悉了,对于区间查询和等值查询性能都比较优秀,时间复杂度为O(log(N)),但有序数组也有个致命的缺点是更新操作非常耗时,当需要往中间插入一条新记录时,需要把所有的记录都向后挪动,此时成本非常高,因此有序数组比较适用于静态存储引擎。
(3)树结构最经典的应该是二叉搜索树了,每个节点的左儿子小于父节点,父节点又小于右儿子,这样查询起来效率非常高,当我们进行前序遍历的时候,就相当于顺序数组的二分查找了,因为时间复杂度为O(log(N)),每次更新也需要保持二叉树的平衡,时间复杂度也是 O(log(N))。但是,对于使用树作为数据库存储结构,我们通常不采用二叉树,这是因为索引不仅要写到内存中,还要写到磁盘上。例如一棵一百万个节点的二叉树,树高20,那么我们就需要20个数据页来存储,此时最坏的遍历查询需要搜索这20个数据页,这远远不能满足我们高速查询数据的要求。(思考:为什么树的每一层都要对应一个数据页呢?将实际的物理存储结构模拟成一棵树,每个页之间通过指针关联起来)
3、关于InnoDB索引:
因此,为了在查询过程尽可能少的访问数据页,我们就需要将二叉树改为N叉树,这里的N取决于页的大小。为什么是这样的呢?我们拿当下使用很普遍的InnoDB存储引擎来说明:
我们都知道计算机在存储数据的时候,有最小存储单元,这就好比我们今天进行现金的流通最小单位是一毛。在计算机中磁盘存储数据最小单元是扇区,一个扇区的大小是512字节,而文件系统(例如XFS/EXT4)他的最小单元是块,一个块的大小是4k,而对于我们的InnoDB存储引擎也有自己的最小储存单元——页(Page),一个页的大小是16K。可以通过如下语句查看,也可以通过参数自行设置:
mysql> show variables like 'innodb_page_size'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_page_size | 16384 | +------------------+-------+ 1 row in set (0.00 sec)
数据表中的数据都是存储在页中的,所以一个页中能存储多少行数据呢?假设一行数据的大小是1k,那么一个页可以存放16行这样的数据。如果数据库只按这样的方式存储,那么如何查找数据就成为一个问题,因为我们不知道要查找的数据存在哪个页中,也不可能把所有的页遍历一遍,那样太慢了。
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B +树中的。每一个索引在InnoDB中都对应一棵B+树。
如下例子,我们可以看到数据的InnoDB中具体的存储形式:
mysql> create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB;
如上语句,我们建了一个表,id为主键,k上有索引。
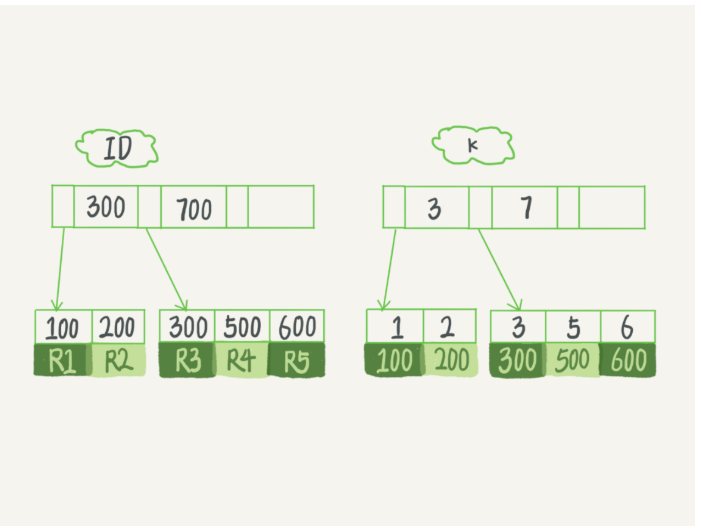
由上图我们可以看到,数据记录按主键进行排序,分别存放在不同的页中,除了存放数据的页以外,还有存放键值+指针的页,如图中ID对应的第一行,即为一页,该页存放键值和指向数据页的指针,这样的页由N个键值+指针组成。当然它也是排好序的。那么要查找一条数据,应该怎么查?如:
select * from T where id=300;
这里id是主键,我们通过这棵B+树来查找,首先找到根页,每张表的根页位置在表空间文件中是固定的,即图中ID索引对应的B+树的第一层,找到根页后通过二分查找法,定位到id=300数据应该在B+树根节点的右儿子对应的页中,那么进一步去该页中查找,同样通过二分查询法即可找到id=300的记录。
上面的例子我们讨论的是主键索引查询数据的情况,那么非主键索引、即字段k上的索引对应的B+树是如何存储的呢?主键索引和非主键索引的区别在哪里呢?
主键索引又称为聚簇索引,存储的是对应的完整的一行数据记录,若一个表没有设置主键,mysql会添加一个row_id作为主键,非主键索引只存储对应行数据的主键,通过主键再去查询对应的行记录,此过程称为回表。在不影响排序结果的情况下,在取出主键后,回表之前,会在对所有获取到的主键排序,这就是mysql的Multi-Range Read (MRR)策略。当我们使用count、sum等统计函数或select id from T where k=3 等只查询主键字段语句时,甚至不用进行回表操作便可以直接得到结果,也就是说k上的索引已经“覆盖”了我们的查询要求,称为覆盖索引,时间可大大缩减。也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应尽可能地使用主键索引。
接下来又有一个新的问题?为什么非主键索引不存储对应的行数据,而只存储对应的主键呢?为了在有限的空间内存储尽可能多的数据,也即时间和空间代价相权衡的问题。
4、一个比较经典的问题是:InnoDB一棵B+树可以存放多少行数据?
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,那么这棵B+树的存放总记录数为:根节点指针数*单个叶子节点记录行数。
上文我们说过通常一页的大小为16k,则单个叶子节点(页)中的记录数=16K/1K=16。(这里假设一行记录的数据大小为1k,实际上现在很多互联网业务数据记录大小通常就是1K左右)。那么现在我们需要计算出非叶子节点能存放多少指针,其实这也很好算,我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即16384/14=1170。那么可以算出一棵高度为2的B+树,能存放1170*16=18720条这样的数据记录。根据同样的原理我们可以算出一个高度为3的B+树可以存放:1170*1170*16=21902400条这样的记录。所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。
5、既然索引能大大的提高查询速度,那么我们是不是每个字段都加上索引呢?
答案肯定是no了,别忘了我们对数据库的操纵包括增删改查,当我们更新数据库、插入一行数据、或者删除主键索引时都需要维护相应的索引,如果索引数目过多,可能会需要非常高的更新成本。当一个数据页满了,按照B+树算法,需新增加一个数据页,叫做页分裂,会导致性能下降。空间利用率降低大概50%。当相邻的两个数据页利用率很低的时候会做数据页合并,合并的过程是分裂过程的逆过程。如果删除,新建主键索引,会同时去修改普通索引对应的主键索引,性能消耗比较大。
6、关于联合索引:
联合索引也对应为一棵B+树,如下图所示:

关于联合索引,大部分都和普通索引类似,关键在于联合索引的最左前缀原则。当我们需要所有名字是“张三”的人时,可以快速定位到 ID4,然后向后遍历便可以得到所有结果。当我们要查询所有名字第一个字是“张”的人,SQL语句如“select * from user where name like '张%'”,这时,你也能够用上这个索引,查找到第一个符合条件的记录是 ID3,然后向后遍历,直到不满足条件为止。
可以看到,不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。需要注意的时候联合索引的存储顺序就是定义索引时的字段顺序,我们在建立索引时,需要考虑这个最左前缀原则,充分发挥联合索引的效用,以及尽可能少地建立功能一样的单个索引。也即当我们有了(username,age)这个联合索引时,就不需要再单独建立username这个索引了。还有就是需要基于空间上的考虑,username字段所需的空间大于age所需空间,因此我们可以用联合索引(username,age)联合索引和age单独索引,而非(username,age)联合索引和username单独索引。
最后在mysql5.6之后的版本,新增了联合索引上的索引下推功能,即当我们查询姓“张”且年龄为10岁的人时,sql语句为“select * from user where username like '张%' and age=10”,当我们在联合索引的B+树中查询出张姓用户时,此时可以不用先去回表查询用户记录后再筛选出年龄为10的用户,而是直接在当前的B+树中过滤掉年龄不为10的用户,这就大大地提高了查询效率。
7、学习资料:
《MySQL技术内幕.SQL编程》、专栏MySQL实战45讲--深入浅出MySQL索引(上)、(下)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号