Spark是什么
官方直达电梯
Spark一种基于内存的通用的实时大数据计算框架(作为MapReduce的另一个更优秀的可选的方案)
- 通用:Spark Core 用于离线计算,Spark SQL 用于交互式查询,Spark Streaming 用于实时流式计算,Spark Mlib 用于机器学习,Spark GraphX 用于图计算
- 实时:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
一、Spark和Storm的区别
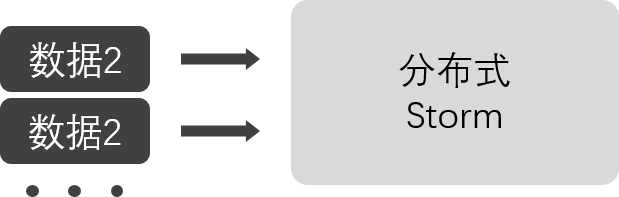
Storm的计算模型(实时)
- Storm是针对每条数据的流式实时计算框架,由于每条数据过来就直接处理,每条数据都会带来大量的资源消耗(传输,通信,校验等)吞吐量不高
- storm可以动态调整并行度
- Storm保证了更高的实时性,毫秒级延迟
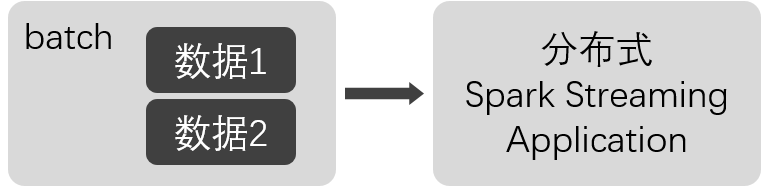
Spark Stream计算模型(准实时)
- 通过设置时间间隔 batch interval 一个时间间隔内的数据作为一个Batch收集起来给Spark Streaming Application处理(少了很多传输,校对开销),保证了高吞吐量
- 秒级延迟
- 结合Spark生态圈可以发挥很大的威力
二、Spark Streaming和MapReduce的对比
Shuffle以及MapReduce的计算模型决定了MapReduce只适合对速度要求不敏感的离线批处理任务
- Spark的多进程任务可能在同一个物理机器的内存上完成(Spark shuffle也会使用磁盘)
- MapReduce死板的模型必须基于磁盘和大量的网络传输
- MapReduce的程度编写复杂,Spark更容易上手,支持(Scale JAVA[8支持函数式编程] Python)
- Spark 在缺少调优时,会出现OOM(Out Of Memory)的问题,导致程序无法执行,而MapReduce就算是慢也能执行

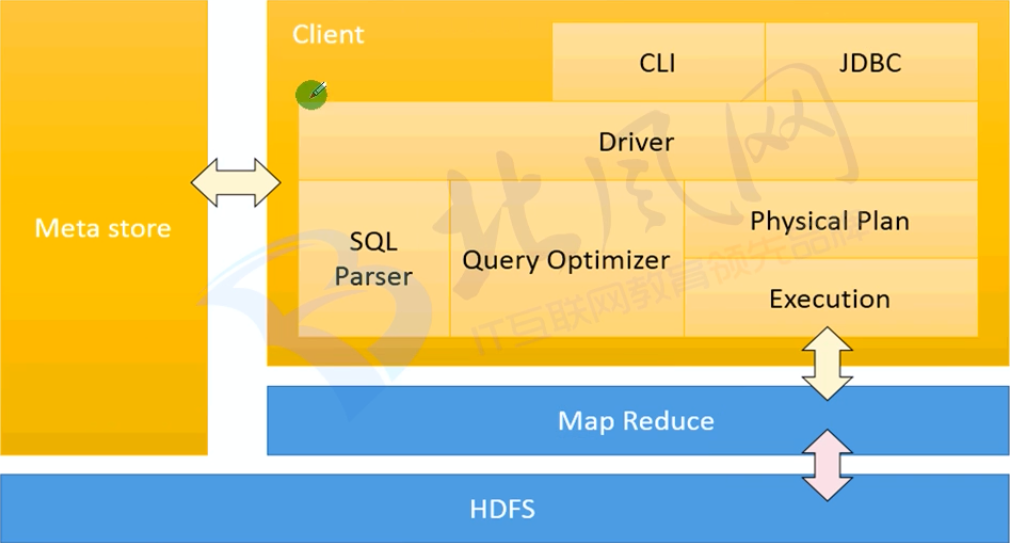
三、Spark SQL对比Hive
- Spark SQL实际上不能完全替代Hive,只是替代了Hive中的查询引擎,针对Hive数据仓库中的表进行SQL查询
- 由于Hive查询底层基于MapReduce决定了Hive的查询慢
- Hive中的一部分高级特性在Spark SQL 中未得到支持
- Spark SQL除了Hive还支持其他数据源(json parquet jdbc等),同时支持直接针对HDFS执行SQL查询
岑忠满的博客新站点
http://cenzm.xyz

 浙公网安备 33010602011771号
浙公网安备 33010602011771号