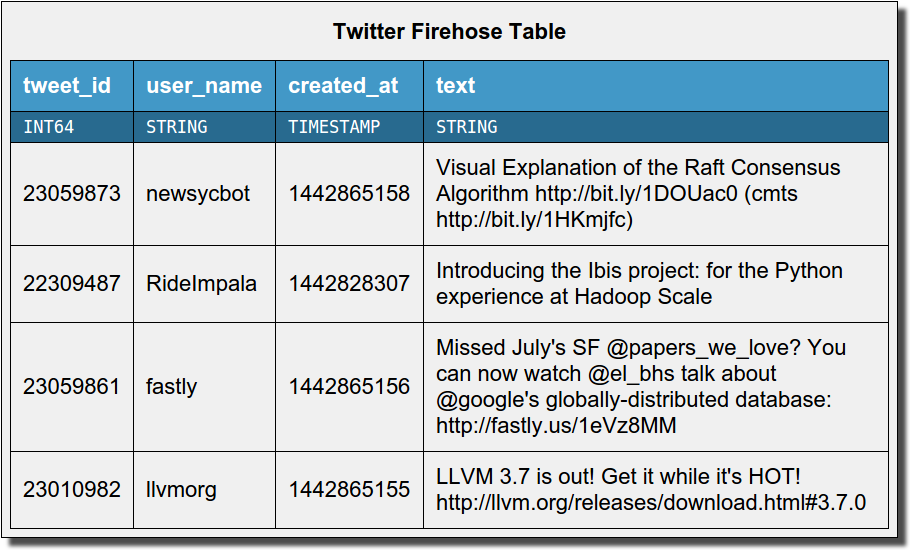
kudu是什么
Apache Kudu Overview
建议配合[Apache Kudo]审阅本文(http://kudu.apache.org/overview.html)
数据模式
Kudo是一个列式存储的用于快速分析的NoSQL数据库,提供了类似SQL的查询语句,与RDBMS十分类似,有**PRIMARY KEY **,基于主键查询而不是HBase的RowKey
低延迟随机存取
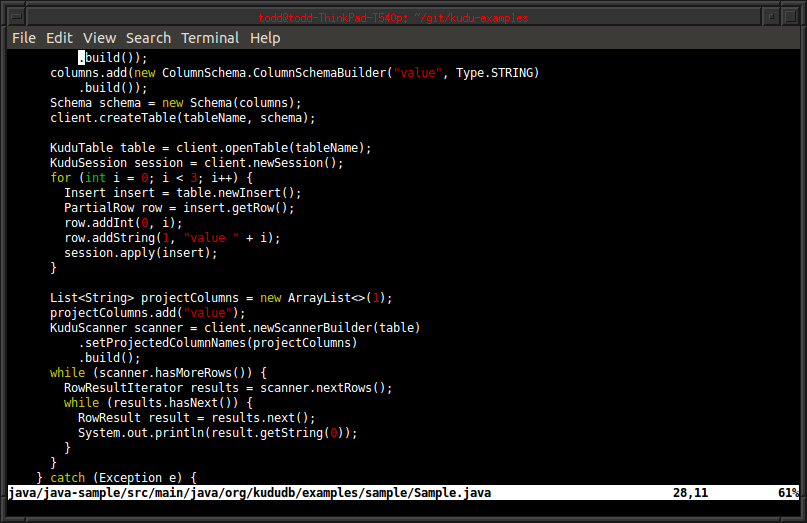
与其他大数据数据库不同,Kudu不仅仅是一个文件格式。行访问达到毫秒级延迟,支持C++ JAVA, API PyThon API 拥有简单好用的API
融会贯通入Hadoop生态系统
你可以使用Java Client实时导入数据,同时也支持Spark(运算) impala(分析工具,比Hive快) MapReduce HDFS HBase 很容易从HDFS中获取数据,占用内存小于1G
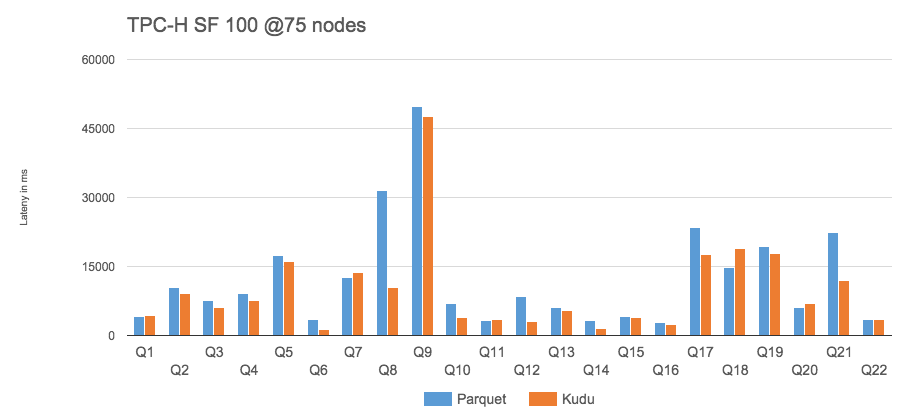
Super-fast Columnar Storage
列式存储有利于编码和压缩,数据比使用Parquet压缩还省空间。这样的高压缩,降低了数据的IO,为计算服务。使用如laze data这样的技术,使得超高速成为可能
分布式和容错机制
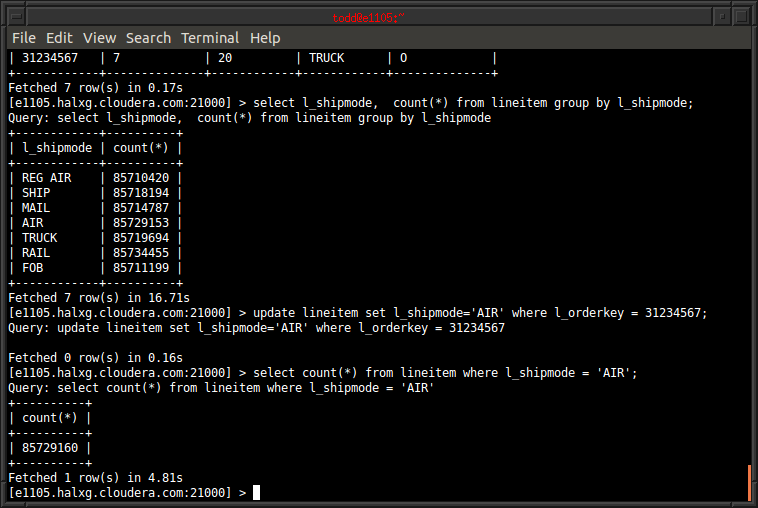
Kudu通过把tables切分成tablets,每个表都可以配置切分的哈希,分区和组合
Kudu使用了Raft来复制给定的操作,保证了数据同时存储在两个节点上,因此不村子单点故障。

为下一代硬件设计
说的是他们深入了解了下一代处理器架构等等,在IO和资源优化等等方面做了一下改进
![]()
岑忠满的博客新站点
http://cenzm.xyz

 浙公网安备 33010602011771号
浙公网安备 33010602011771号