数据类型
数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。
我们通过Python内置的type()函数可以查看变量所致的对象类型:
a = 10 # 整型
b = 1.5 # 浮点型
c = True # 布尔型
d = 5+2j # 复数
# 也可以同时给多个变量赋值
# a, b, c, d = 10, 1.5, True, 5+2j
print(type(a), type(b), type(c), type(d))
输出结果:
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
在Python中,能够直接处理的数据类型有以下几种:
整数
Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样,例如:1,100,-8080,0,等等。
计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2,等等。
Python3 中的数字支持int(整型)、float(浮点型)、complex(复数)。Python文档中bool(布尔值)不属于数字类型,但是这里也把bool类型放在这里来说,因为bool是int的子类。就像大多是语言一样,Python中的数据类型也是很直观的。
说明:
Python2 中的数字类型还包括一个long(长整型),且会自动将超过整型长度的数字转换为长整型(数字最后加上L字母表示长整形)。但是Python3中已经没有long类型了,int和long都叫整型(int)。
bool(布尔型)之所以属于数字类型,是因为bool是int的子类。
浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是完全相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。
字符串
字符串是以单引号'或双引号"括起来的任意文本,比如'abc',"xyz"等等。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这6个字符。
如果字符串内部既包含'又包含"怎么办?可以用转义字符\来标识,比如:
'I\'m \"OK\"!'
表示的字符串内容是:
I'm "OK"!
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\,可以在Python的交互式命令行用print()打印字符串看看:
>>> print('I\'m ok.')
I'm ok.
>>> print('I\'m learning\nPython.')
I'm learning
Python.
>>> print('\\\n\\')
\
\
如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r''表示''内部的字符串默认不转义,可以自己试试:
>>> print('\\\t\\')
\ \
>>> print(r'\\\t\\')
\\\t\\
如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容,可以自己试试:
>>> print('''line1
... line2
... line3''')
line1
line2
line3
当输入完结束符``` 和括号)后,执行该语句并打印结果。
如果写成程序并存为.py文件,就是:
print('''line1
line2
line3''')
多行字符串'''...'''还可以在前面加上r使用,请自行测试:
str和bytes之间的关系
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
两种写法完全是等价的。
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python 3最重要的新特性之一是对字符串和二进制数据流做了明确的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,你不能拼接字符串和字节流,也无法在字节流里搜索字符串(反之亦然),也不能将字符串传入参数为字节流的函数(反之亦然)。
下面让我们深入分析一下二者的区别和联系。
回到bytes和str的身上。bytes是一种比特流,它的存在形式是01010001110这种。我们无论是在写代码,还是阅读文章的过程中,肯定不会有人直接阅读这种比特流,它必须有一个编码方式,使得它变成有意义的比特流,而不是一堆晦涩难懂的01组合。因为编码方式的不同,对这个比特流的解读也会不同,对实际使用造成了很大的困扰。下面让我们看看Python是如何处理这一系列编码问题的:
>>> s = "中文"
>>> s
'中文'
>>> type(s)
<class 'str'>
>>> b = bytes(s, encoding='utf-8')
>>> b
b'\xe4\xb8\xad\xe6\x96\x87'
>>> type(b)
<class 'bytes'>
如果知道字符的整数编码,还可以用十六进制这么写str:
20013 -----16进制------>4e2d 25991-------16进制---------6587
>>> '\u4e2d\u6587'
'中文'
从例子可以看出,s是个字符串类型。Python有个内置函数bytes()可以将字符串str类型转换成bytes类型,b实际上是一串01的组合,但为了在ide环境中让我们相对直观的观察,它被表现成了b'\xe4\xb8\xad\xe6\x96\x87'这种形式,开头的b表示这是一个bytes类型。\xe4是十六进制的表示方式,它占用1个字节的长度,因此”中文“被编码成utf-8后,我们可以数得出一共用了6个字节,每个汉字占用3个,这印证了上面的论述。在使用内置函数bytes()的时候,必须明确encoding的参数,不可省略。
我们都知道,字符串类str里有一个encode()方法,它是从字符串向比特流的编码过程。而bytes类型恰好有个decode()方法,它是从比特流向字符串解码的过程。除此之外,我们查看Python源码会发现bytes和str拥有几乎一模一样的方法列表,最大的区别就是encode和decode。
从实质上来说,字符串在磁盘上的保存形式也是01的组合,也需要编码解码。
如果,上面的阐述还不能让你搞清楚两者的区别,那么记住下面两几句话:
1.在将字符串存入磁盘和从磁盘读取字符串的过程中,Python自动地帮你完成了编码和解码的工 作,你不需要关心它的过程。
2.使用bytes类型,实质上是告诉Python,不需要它帮你自动地完成编码和解码的工作,而是用户自己手动进行,并指定编码格式。
3.Python已经严格区分了bytes和str两种数据类型,你不能在需要bytes类型参数的时候使用str参数,反之亦然。这点在读写磁盘文件时容易碰到。
在bytes和str的互相转换过程中,实际就是编码解码的过程,必须显式地指定编码格式。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换
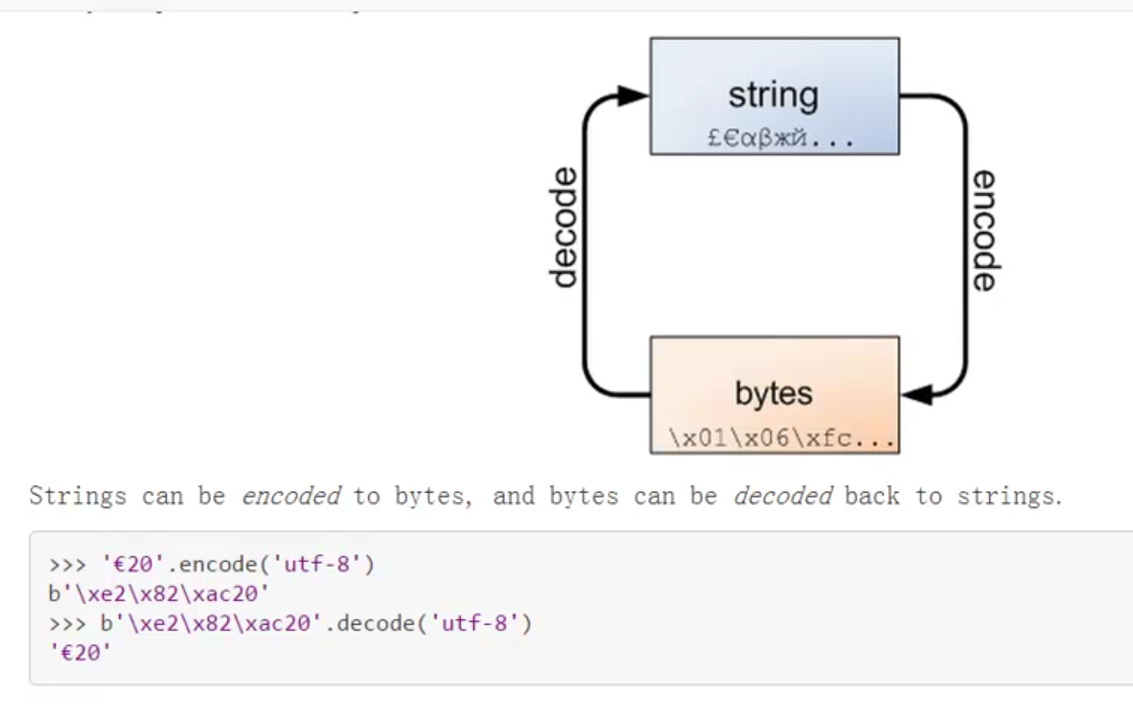
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
如果bytes中包含无法解码的字节,decode()方法会报错:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8')
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte
如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'
还可以用内置发方法转换
>>> b
b'\xe4\xb8\xad\xe6\x96\x87'
>>> type(b)
<class 'bytes'>
>>> s1 = str(b)
>>> s1
"b'\\xe4\\xb8\\xad\\xe6\\x96\\x87'"
>>> type(s1)
<class 'str'>
>>> s1 = str(b, encoding='utf-8')
>>> s1
'中文'
>>> type(s1)
<class 'str'>
我们再把字符串s1,转换成gbk编码的bytes类型:
>>> s1
'中文'
>>> type(s1)
<class 'str'>
>>> b = bytes(s1, encoding='utf-8')
>>> b
b'\xd6\xd0\xce\xc4'
布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来:
>>> True
True
>>> False
False
>>> 3 > 2
True
>>> 3 > 5
False
布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为True,and运算结果才是True:
>>> True and True
True
>>> True and False
False
>>> False and False
False
>>> 5 > 3 and 3 > 1
True
or运算是或运算,只要其中有一个为True,or运算结果就是True:
>>> True or True
True
>>> True or False
True
>>> False or False
False
>>> 5 > 3 or 1 > 3
True
not运算是非运算,它是一个单目运算符,把True变成False,False变成True:
>>> not True
False
>>> not False
True
>>> not 1 > 2
True
布尔值经常用在条件判断中,比如:
if age >= 18:
print('adult')
else:
print('teenager')
空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
此外,Python还提供了列表、字典等多种数据类型,还允许创建自定义数据类型,我们后面会继续讲到。
类型转换
强制类型转换
顾名思义,强制类型转换就是把一个数据类型强制转换为另一数据类型。这里,我们先说下数字类型(int、float、bool、complex)间的相互转换。
int与bool类型
在Python解释器的交互式终端通过help(bool)可以查看bool类的完整定义,会发现bool是int类型的子类。另外bool类型只有两个值:True和False,因此bool与int类型的值必然存在某种关联。
>>> int(True)
1
>>> int(False)
0
>>> bool(1)
True
>>> bool(-1)
True
>>> bool(0)
False
结论:
bool 转 int时, Ture->1, False->0
int 转 bool时, 非0->True, 0->False
int、bool与float类型
bool类型可以看作一个特殊的int类型
>>> float(5)
5.0
>>> float(True)
1.0
>>> float(False)
0.0
>>> int(5.0)
5
>>> bool(5.0)
True
>>> bool(0.0)
False
int、bool、float与complex
>>> complex(5)
(5+0j)
>>> complex(5.0)
(5+0j)
>>> complex(True)
(1+0j)
>>> complex(False)
0j
>>> bool((5+0j))
True
>>> bool((0+0j))
False
>>> int((5+0j))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't convert complex to int
>>> float((5+0j))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't convert complex to float
结论:complex类型 不能强制转换为 int 和 float类型
自动类型转换
自动类型转换是指两个不同类型的操作数参与运算时,Python会先按照以下规则先对其中一个操作数进行自动类型转换,然后再进行运算。
如果有一个操作数是复数,另一个操作数会被转换为复数
否则,如果有一个操作数是浮点型,另一个操作数会被转换为浮点型
(Python 2)否则,如果有一个操作数是长整形,另一个操作数会被转换为长整型
否则,如果有一个是整型,另一个是布尔型,则布尔型会被转换为整型0或1
否则,两个都是相同数据类型,无需类型转换
>>> 2 + (5+2j) # 整型转复数
(7+2j)
>>> 2.0 + (5+2j) # 浮点型转复数
(7+2j)
>>> True + (5+2j) # 布尔型转复数
(6+2j)
>>> 2 + 5.0 # 整型转浮点型
7.0
>>> True + 5.0 # 布尔型转浮点型
6.0
>>> True + 2 # 布尔型转整型
3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号