Hadoop学习笔记
————厦门大学mooc:大数据技术原理与应用
两大核心:
分布式文件系统(HDFS)、分布式并行框架(MapReduce)
hadoop的特性:
1.高可靠性:Hadoop平台采用冗余副本机制
2.高效率
3.很好的扩展性
4.高容错性
5.成本低
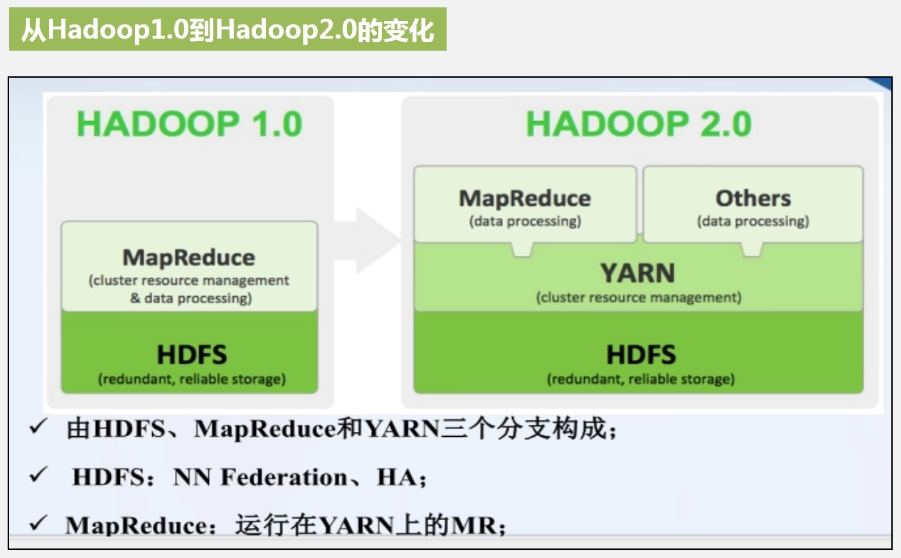
Hadoop的结构:
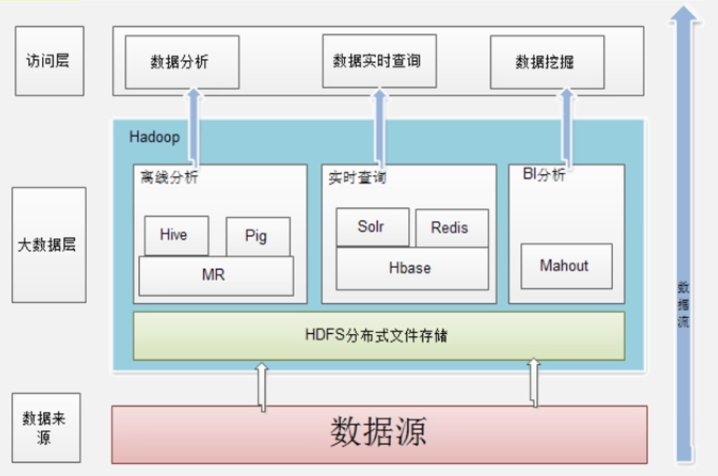
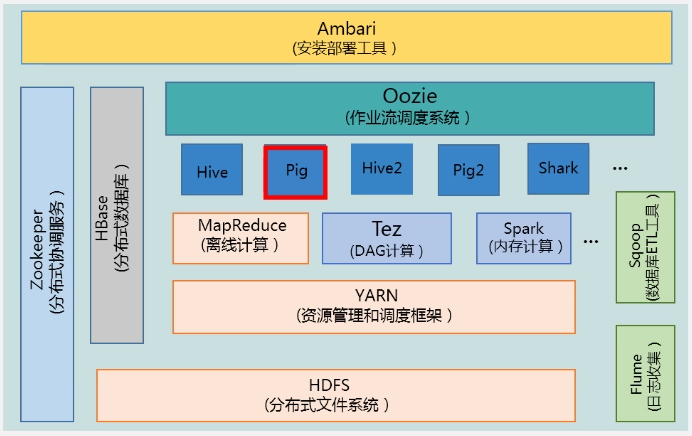
Hive:在Hadoop中实现数据仓库的功能,可支持SQL语句(通过Hive转换成MapReduce语句)
Pig:实现流式处理,提供类似SQL的查询语言:Pig Latin(轻量级)
Oozie:调度完成不同的作业
zookeeper:负责分布式锁、集群管理等
HBase:支持随机读写和实时应用
Flume:日志收集,如收集实时性的流
Sqoop:用于在Hadoop与传统数据库之间进行数据传递
Ambari:部署、管理
3.1分布式文件系统HDFS
两大核心问题:分布式存储->HDFS、分布式处理->MapReduce
HDFS已实现的目标:
兼容廉价的硬件设备、实现流数据的读写、支持大数据集、支持简单的文件模型、强大的跨平台兼容性
HDFS的局限性:
1.不能满足实时的数据处理需求(HBase可解决)
2.无法高效存储大量的小文件
3.不支持多用户写入及仍以修改文件(只允许追加、不允许修改)
HDFS中的核心概念:块(降低分布式节点的寻址开销、比普通文件系统的块大)
HDFS中采用抽象块的概念设计的好处:
1.支持大规模文件存储
2.简化系统设计
3.适合数据备份
HDFS中的名称节点(name node)和数据节点(data node):
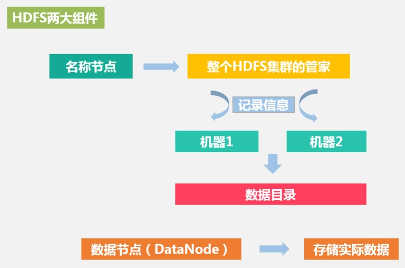
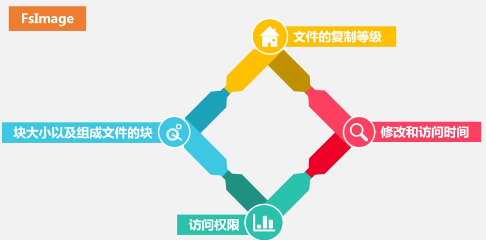
名称节点存储元数据,元数据包括:

名称节点的结构:

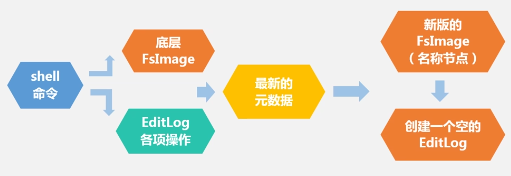
名称节点的运作过程:
第二名称节点(secondary name node) :
1.考虑到性能+占用内存:解决EditLog不断增大的问题
2.作为名称节点的冷备份(冷,意味着名称节点发生故障后,第二名称节点还要做数据恢复的工作,必须停止一段时间,不能马上恢复[在1.0版本中存在的问题])
数据节点:

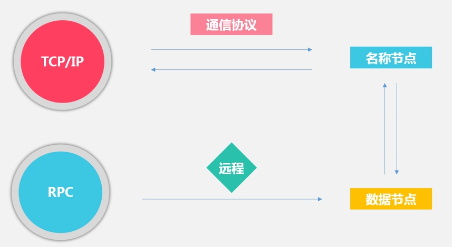
与客户端的交互过程:
HDFS体系结构的局限性:

HDFS的存储原理:
1.冗余数据保存的问题
冗余因子
带来优点:a.加快数据传输速度(并行)
b.容易检查数据错误
c.保证数据可靠性
2.数据保存策略问题
数据块的方式:相应的存放策略
数据块的读取:就近读取
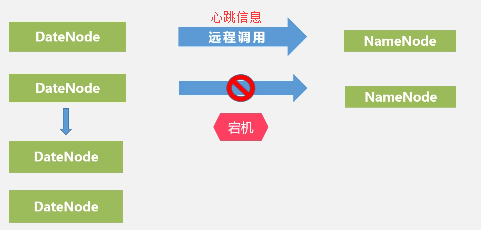
3.数据恢复的问题
名称节点出错:第二名称节点顶替
数据节点出错:
数据本身出错:校验码检查,出错则进行冗余副本的再次复制
HDFS读取数据的示例:
Hadoop中对应的实现:
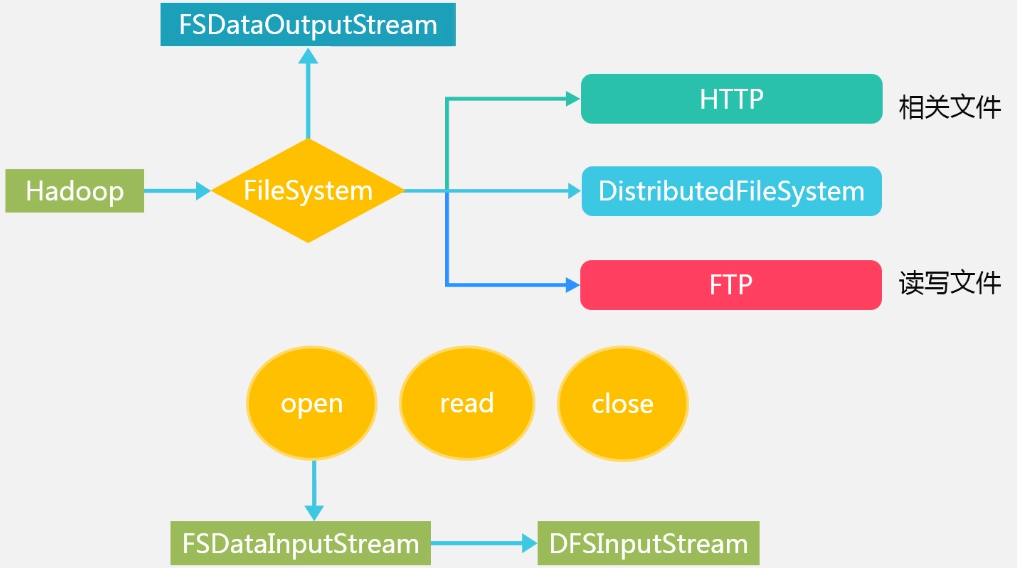
其中,DFInputStream与名称节点打交道;FSDataInputStream与客户端打交道
读过程的具体实现:

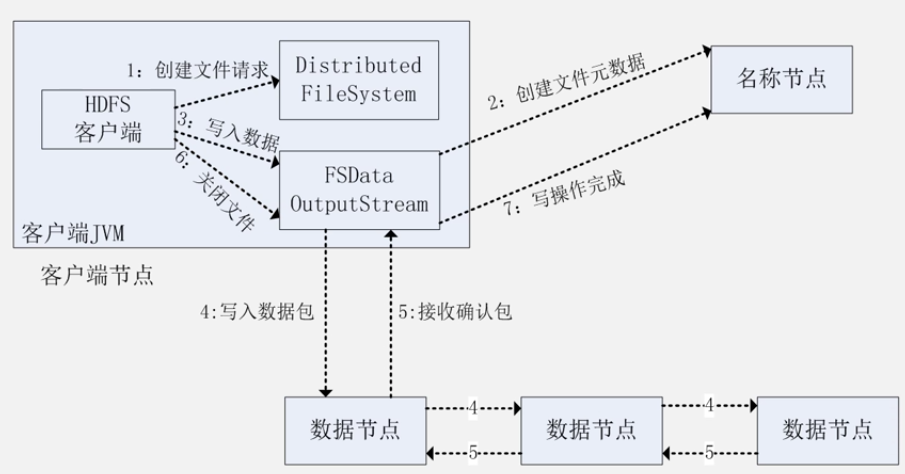
HDFS写数据过程:
HDFS的编程实践:

4.1HBase
Bigtable:
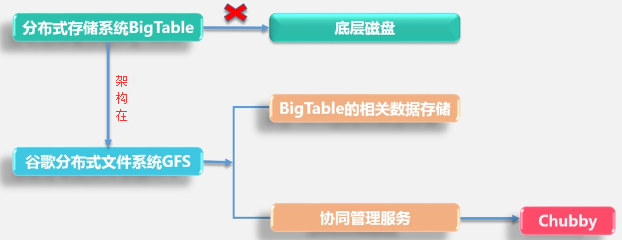
优点:可支持PB级别的数据、具有非常好的扩展性能
HBase:是BigTable的一个开源实现。
HBase的特点:高可靠、高性能、面向列、可伸缩,是一个分布式数据库,可以用来存储非结构化和半结构化的松散数据。

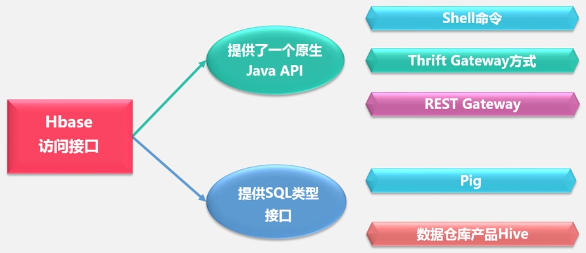
HBase的访问方式:
4.2HBase的数据模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号