【机器学习十大算法】线性回归(一)
线性回归 (Linear Regression)
在这篇文章中,我努力尝试以一种既通俗易懂又严谨精确的方式,来介绍机器学习中的线性回归这一核心概念,并以此为基础,深入剖析了其背后至关重要的误差项假设。我深信,理解这些假设,是掌握并正确应用线性回归算法的关键。
想象一下:
你是一个侦探 X,正在尝试预测案发现场的“物品丢失数量”(y,目标变量)。你搜集了一些线索,比如“现场有多少个房间” ()、“案发当天天气如何”(可能用数字表示,比如
)等等(自变量)。
线性回归就是你的“经验法则”:
你可能会建立一个经验法则,比如:“物品丢失数量大概等于(房间数量乘以一个系数)加上(天气因素乘以另一个系数)再加上一个‘基本值’(截距)”。
数学上,这就是:
(丢失数量) ≈(截距 ) + (房间数量
) + (天气因素
)
这个“≈”的意思是,你的“经验法则”并不能完全预测出丢失的数量,总是会有一点点偏差。
什么是误差?
定义:误差 是独立且具有相同的分布,并且服从均值为0方差为
的高斯分布
误差项 (ϵ):侦探无法解释的“神秘因素”zhi
这个偏差,我们称之为“误差项” (ϵ)。它代表了你的“经验法则”(线性模型)没能捕捉到的所有其他因素,导致你预测的值和你实际观测到的丢失数量之间的差异。
比如:
- 可能还有其他重要线索你没收集到: 比如“案发时是否有保安在场”。
- 你的“经验法则”本身就不够完善: 也许房间数量和丢失数量的关系不是完全线性的。
- 巧合与随机性: 有些丢失可能就是单纯的巧合,无法用任何具体线索解释。
为什么我们对这个“神秘因素” (ϵ) 做这些假设?
我们给这个“神秘因素”设定一些“规矩”,能帮助我们更好地理解和使用我们的“经验法则”,并且让我们的预测更可靠。
-
“误差是独立” - 每次案子都是独立的:
- 通俗说: 这次案子里的“神秘因素”(比如巧合、没发现的线索)不会影响下一次案子的“神秘因素”。
- 为什么重要: 如果误差不独立,比如这次案子因为“保管不善”丢了东西,下次案子可能也因为“保管不善”丢了东西(关联性),那你的“经验法则”就漏掉了“保管不善”这个重要的解释变量,你的预测就会有系统性的错误。独立性才能保证每次的“经验”都是独立的参考,而不是互相“传染”。
-
“误差具有相同的分布” - 每次“随机性”的“程度”差不多:
- 通俗说: 每次案子里的“神秘因素”对预测结果造成的“波动”或“不确定性”的大小,基本是差不多的。
- 为什么重要: 这意味着误差项有“同方差性”。比如,无论你面对的是大案子还是小案子,你经验法则的“误差程度”都差不多。如果“案子越大,神秘因素造成的误差就越大”(异方差性)那你的模型在一个地方可能很准确,在另一个地方就非常不准确,模型就不够“稳定”和“公平”。
-
“误差服从均值为0的高斯分布 (正态分布)” - “神秘因素”通常往“中间”偏:
-
均值为0 (Zero Mean):
- 通俗说: 那些“神秘因素”造成的偏差,平均来看(不偏不倚的话)是零。也就是说,它们不会系统性地让你的预测值偏高或偏低。
- 为什么重要: 如果误差项平均值不是零,比如总是偏高,那么你的“经验法则”就系统性地低估了丢失的数量。均值为零保证了你的“经验法则”本身是“没有歪斜”的。
-
高斯分布 (Gaussian Distribution/Normal Distribution):
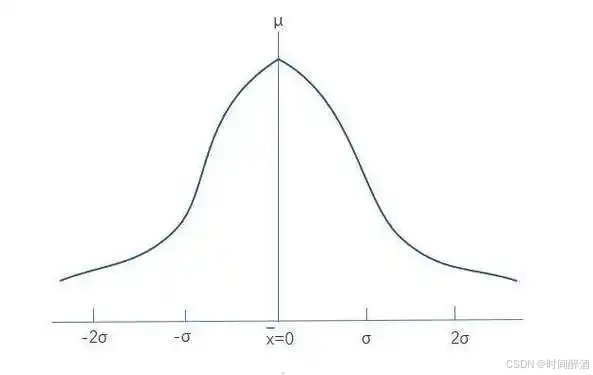
- 通俗说: 大多数时候,“神秘因素”造成的偏差会在“零”附近(也就是你的预测值和你实际值比较接近)。但偶尔也可能出现大的偏差(好的或坏的),只是出现的概率比较小。它就像一个钟形曲线,最常见的是中间(零偏差),两边(大的偏差)发生的几率越来越小。
![]()
- 为什么重要:
- 最佳预测: 在满足其他条件的情况下,这个假设能保证你的“经验法则”(线性回归)是“最佳”的,也就是说,它是最准确、最不浪费信息的。
- 科学推断: 允许我们对预测的准确度进行科学的“量化”,比如计算“这个预测错的概率有多大”或者“我的预测值有多大的可能性在这个范围内”。
- 通俗说: 大多数时候,“神秘因素”造成的偏差会在“零”附近(也就是你的预测值和你实际值比较接近)。但偶尔也可能出现大的偏差(好的或坏的),只是出现的概率比较小。它就像一个钟形曲线,最常见的是中间(零偏差),两边(大的偏差)发生的几率越来越小。
-
总结一下:
-
线性回归: 就像一个“经验法则”,用简单的线性关系来预测目标。
-
误差项 (ϵ): 是模型无法解释的“随机”、“巧合”或“遗漏”的部分。
-
为什么假设是独立同分布的高斯分布,均值为0,方差为
”:
-
独立: 保证每次的“神秘因素”都互不干扰,数据是干净的。
-
same distribution (同分布) / Same variance (同方差):保证“神秘因素”造成的“乱动的程度”基本一样,模型在不同情况下表现稳定。
-
零均值: 保证“神秘因素”平均来看不会让你的预测系统性地偏高或偏低。
-
高斯分布: 使得我们的“经验法则”在使用上最方便、最准确,并能进行科学的“概率”分析。
-
把这些假设看作是侦探为了让自己的“经验法则”更强大、更可靠而设定的一些“理想条件”。在实际中,这些条件可能不总是完全满足,但它们提供了一个非常好的起点,让我们能够理解和应用线性回归。
接下来,我将用更严谨的语言解释线性回归
线性回归 (Linear Regression)
线性回归是一种基础且常用的监督学习算法,用于建模一个或多个自变量(也称为特征或预测变量)与一个因变量(也称为目标变量或响应变量)之间的线性关系。
基本概念:
- 目标变量 (y): 我们想要预测的变量。
- 自变量 (x): 用来预测目标变量的变量。
- 线性关系: 假设目标变量是自变量的线性函数。
模型形式:
-
简单线性回归 (Simple Linear Regression): 只有一个自变量。
模型可以表示为:
y =+
+ ϵ
- y: 因变量
- x: 自变量
: 截距 (intercept),当 x=0 时,y的期望值。
: 斜率 (slope),表示 x 每增加一个单位时,y 的平均变化量。
- ϵ: 误差项 (error term)。
-
多元线性回归 (Multiple Linear Regression): 有多个自变量。
模型可以表示为:
y =+
+
+⋯+
+ ϵ
目标:
在训练过程中,我们的目标是找到最佳的系数 (,
,…,
),使得模型预测的值 (
) 与实际观测值 (
) 之间的“差距”(误差)最小。最常用的方法是最小二乘法 (Ordinary Least Squares, OLS),它通过最小化残差平方和 (Sum of Squared Residuals, SSR) 来估计系数。
残差 (residual) 是实际观测值与模型预测值之间的差: =
-
SSR =
误差项 (ϵ) 的假设
在统计学和机器学习中,对线性回归的误差项 ϵϵ 通常会做一些关键性的假设。这些假设不仅仅是为了让模型“好用”,更是为了:
- 保证最小二乘法估计的性质: 在某些条件下,这些假设可以证明普通最小二乘法 (OLS) 估计出的系数是最佳线性无偏估计量 (Best Linear Unbiased Estimator, BLUE),即在所有线性无偏估计量中,OLS 估计量是方差最小的。
- 推导统计推断: 例如,计算系数的置信区间、进行假设检验(如 t 检验、F 检验)等,都需要对误差项的分布做出假设。
- 建立模型的一致性: 确保模型在数据量增加时能够收敛到真实参数。
最核心的假设通常是高斯-马尔可夫定理 (Gauss–Markov theorem) 和最大似然估计 (Maximum Likelihood Estimation, MLE) 所要求的条件。
误差项的假设是:
-
零均值 (Zero Mean): E(ϵi)=0
- 含义: 这意味着在给定自变量 x 的情况下,目标变量 y 的条件期望就是由模型的线性部分
+
+
+⋯+
决定的。模型只解释了 y的系统性部分,而误差项代表了未能通过线性模型解释的随机变异。
- 为什么重要: 如果误差项有非零均值,那么我们的线性模型
实际上是 E(y∣x)−E(ϵ),这会导致模型预测出现系统偏差。最小二乘法在零均值假设下能够得到无偏估计。
- 含义: 这意味着在给定自变量 x 的情况下,目标变量 y 的条件期望就是由模型的线性部分
-
独立 (Independence): 任意两个误差项是相互独立的。
- 含义: 第 ii个观测值的误差不会影响或被第 jj个观测值的误差所影响。换句话说,一个数据点的误差不会“传播”到另一个数据点。
- 为什么重要:
- OLS 渐近性质: 独立性是证明 OLS 估计量方差的渐近性质(如渐近正态性)的关键。
- 模型解释: 如果误差项不独立(例如,存在自相关性,像时间序列数据中),那么在不同观测值之间就会有模式化的关系,这表明我们的模型可能没有充分捕捉到数据中的依赖结构。
- 统计推断: 独立性是进行许多统计检验(如 t 检验、F 检验)的前提,因为这些检验的有效性依赖于样本的随机性和独立性。
-
同分布 (Identically Distributed, i.i.d. for simplicity in many cases): 所有误差项 都服从相同的分布。
- 含义: 误差项的变异性(方差)在所有观测值上都是恒定的,不受自变量取值的影响。
- 为什么重要:
- 同方差性 (Homoscedasticity): 这是同分布假设的一个直接推论。如果方差不是恒定的(称为异方差性),那么 OLS 估计量仍然是无偏的,但不再是最优的(方差不是最小的),并且标准误差的计算会失真,导致统计推断错误。
- 模型稳定性: 保证了模型在不同数据区域具有相似的预测不确定性。
-
服从均值为0方差为 σ2的高斯分布 (Normally Distributed with mean 0 and variance σ2): ϵi∼N(0,σ2)
- 这个假设是上面三个假设(零均值,独立,同分布)的进一步细化和具体化,并且指定了误差的概率分布形式。
- 为什么重要:
- 最大似然估计 (MLE): 如果我们假设误差项服从高斯分布,那么最小二乘法(最小化残差平方和)实际上就等价于对模型参数 β进行最大似然估计。这是因为,在高斯分布下,似然函数的形式与残差平方和直接相关。
- 统计推断的精确性: 许多统计推断方法(如 t 检验、F 检验)的严格有效性依赖于误差项服从正态分布。例如,t 分布是基于正态分布的。在样本量小的情况下,这个假设尤其重要。
- 最优化性质 (BLUE): 高斯分布假设使得 OLS 成为 Minimum Variance Unbiased Estimator (MVUE),这是比 BLUE 更强的最优性结论。
- 概率预测: 允许我们对预测值 y 的概率分布进行建模,例如计算预测区间的“预测概率”。
总结这些假设 (有时称为“经典线性回归假设”):
- E(εᵢ) = 0 (零均值)
- Var(εᵢ) = σ² (同方差性)
- Cov(εᵢ, εⱼ) = 0 for i ≠ j (独立性)
- εᵢ ~ N(0, σ²) (正态分布)
当这些假设全部满足时,我们可以非常有信心地使用 OLS 来估计模型参数,并进行可靠的统计推断。
为什么这些假设如此重要?
-
最优性 (Optimality): OLS 估计量在满足这些假设时,是所有线性无偏估计量中方差最小的。这意味着我们得到的 β 估计值是最“精确”的,其不确定性(方差)最小。
-
无偏性 (Unbiasedness): 在前三个假设(零均值、独立、同方差)下,OLS 估计量是无偏的,意味着我们估计出的系数的期望值等于真实的参数值。
-
统计推断 (Statistical Inference): 正态分布假设使得我们能够使用标准的统计方法(如 t 检验、F 检验、置信区间)来检验模型参数的显著性、模型整体的拟合优度等。如果我们没有这个假设,这些方法的有效性将大打折扣,特别是在样本量较小的情况下。
-
模型的可解释性: 误差项代表了数据中未能被自变量解释的随机性。假设它服从一个已知的、简单的分布(如高斯)简化了问题的分析。
现实世界中的情况
值得注意的是,在实际应用中,这些假设很少能完美满足。
-
异方差性 (Heteroscedasticity): 常见于金融数据、医学数据等。
-
自相关性 (Autocorrelation): 常见于时间序列数据。
-
非正态误差: 误差分布可能偏斜,或有重尾,尤其是在处理包含异常值的数据集时。
当这些假设被违反时,研究人员会采用其他方法:
-
异方差稳健的标准误 (Heteroscedasticity-Robust Standard Errors): 可以计算出在异方差情况下仍然有效的标准误。
-
广义最小二乘法 (Generalized Least Squares, GLS): 用于处理自相关和异方差。
-
加权最小二乘法 (Weighted Least Squares, WLS): 一种特殊情况的GLS,用于处理异方差。
-
稳健回归 (Robust Regression): 不依赖于误差分布假设,对异常值更不敏感。
-
更复杂的模型: 如使用非线性模型、混合效应模型等。
但在没有进一步信息的情况下,线性回归模型从假设误差项是独立同分布的零均值高斯分布开始,这是一个强大且常用的起点,能够提供有用的模型和洞察。
作者本人水平有限,非常欢迎任何反馈和指正,请随时指出我可能存在的误解、遗漏或表述不当之处。
我将继续深入学习机器学习和统计学领域,并持续更新我的理解和最佳实践。我愿意虚心接受反馈,不断打磨和完善我的内容,以便为读者提供更可靠、更有价值的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号