【机器学习十大算法】线性回归(二)
本文旨在为初学者建立一个直观认知,并激发学习兴趣。因此,讲解将侧重于逻辑脉络与直观理解, 有意地避免了深度的数学计算。关于其严谨的数学推导与实现细节,我们将在后续的文章中进行系统性阐述。
上一期我们通俗的讲了什么是线性回归,这期我们来讲一下什么是梯度下降
可以这么说:
目标函数就是告诉我们“好坏”的标准。
求解就是找到让“好坏”标准最优(通常是最小)的参数。
那就会有一个问题:当得到了目标函数之后,我们要怎么求解呢?怎么样才能找到那个最优参数?
简单的线性回归允许我们通过数学推到直接算出最佳参数,但很多机器学习模型(比如深度学习中的神经网络)的目标函数非常复杂,不是简单的线性关系。
原因:
- 1.非凸性 (Non-convexity): 很多复杂的目标函数会有很多“山谷”和“山峰”,数学上找到那个全局最低点(Global Minimum)非常困难,解析解(直接用数学公式推导出来)几乎不可能。梯度下降可能会停在某个局部最低点(Local Minimum)。
- 2.高维度: 涉及的参数 θ 数量巨大,即使函数是凸的,直接求解的计算量也可能非常大
那么这个时候我们就要借助“梯度下降”这样的方法,通过不断迭代来逼近最优解
所以梯度下降是一种优化算法,用于求解机器学习问题中的目标函数
梯度下降(Gradient Descent)的本质:寻找函数的最小值
在机器学习的背景下,我们主要用梯度下降来最小化一个“损失函数”或“代价函数”。 这个函数衡量了我们模型的预测值与真实值之间的差距有多大。 我们的目标是找到一组模型参数(比如线性回归的斜率和截距,或者神经网络的权重和偏置),使得这个损失函数的值最小。
核心思想:沿着函数下降最快的方向前进
一个经典的比喻:下山
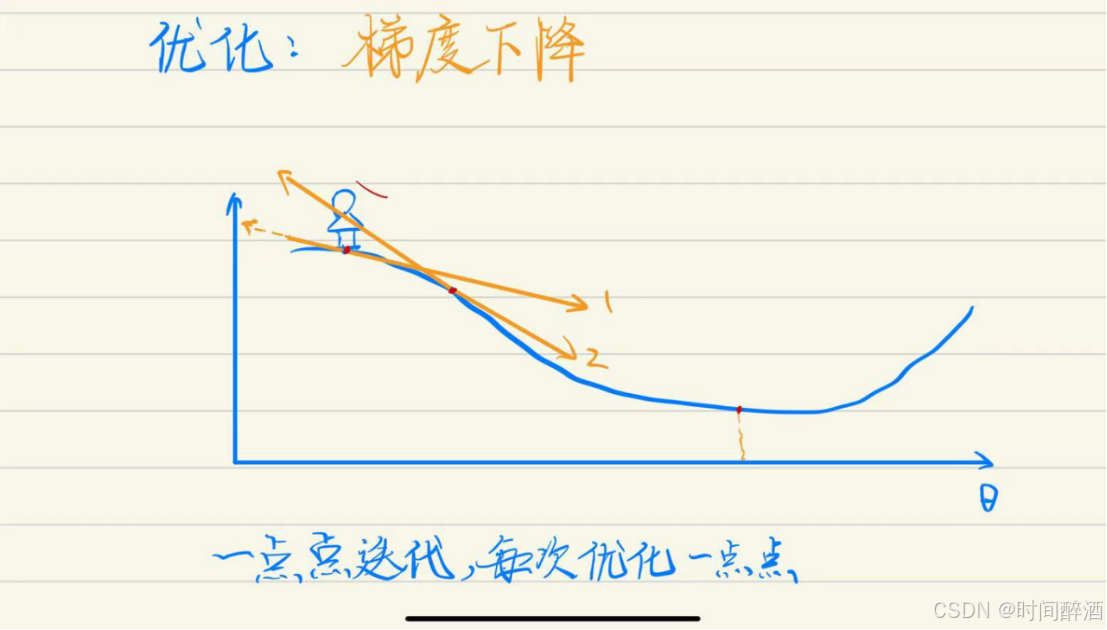
想象一下你站在一座大山的山坡上,目标是到达山谷的最低点(也就是山的最低处)。
你完全看不清整座山的全貌(不知道损失函数的全局形状),你只能依靠脚下的感觉来判断。
你会怎么做?
1.环顾四周,感受坡度:你在当前位置转一圈,用脚感受哪个方向是最陡峭的下坡方向。
2.朝着这个方向迈一步:你朝着这个感觉最陡的方向走一小步。这一步不能太大(否则可能会跨过山谷或摔倒),也不能太小(否则下山太慢)。
3.重复过程:到了新的位置,你再次感受最陡的下坡方向,再迈一步。如此循环反复,直到你感觉脚下已经变得平坦( 迭代收敛),找不到明显的下坡方向了,说明你可能已经到达了山谷的最低点。
我们来把这个直觉数学化:
A.你的位置: 代表了当前模型的参数值 θ。
B. 山坡的地势(高度): 代表了损失函数的值 J(θ)。
C.你的目标: 找到能让你到达最低点的那组参数让损失函数最小(换言之,预测值和实际值的差距最小。)
D.感受坡度:计算损失函数在当前参数下的梯度 ∇J(θ)
梯度是一个向量,它指向函数值增长最快的方向。那么,它的反方向(负梯度 -∇J(θ))自然 就是函数值下降最快的方向。(梯度 ∇J(θ) 是由损失函数 J(θ) 对每一个参数 θ_i 求偏导数组成的向量。)
E.“迈一步” → 更新参数
更新公式:θ = θ - η * ∇J(θ)
F.步长由学习率 η (eta) 控制。
学习率:对结果的影响巨大,一般值比较小
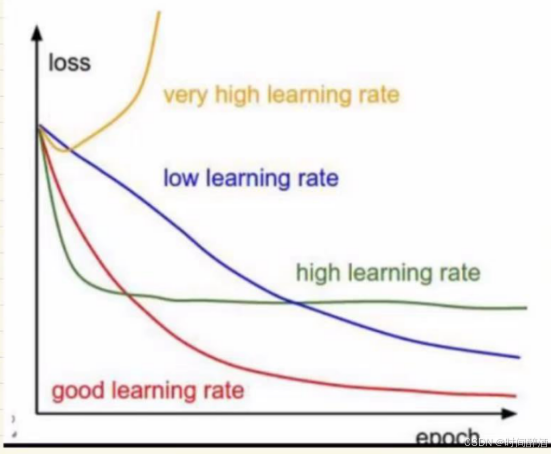
更新公式是梯度下降的核心,它意味着参数沿着损失函数下降最快的方向进行更新。
当梯度 ∇J(θ) 接近零向量时,意味着我们找到了一个(局部)极值点,参数停止更新。对于凸函数,这个局部极值点就是全局最小值。 (值得注意的是,对于非凸函数,它可能只是一个局部最小值,而非全局最小值。 这是梯度下降存在的一个局限性。尽管在很多实际应用中,局部最小值也已经足够好)
梯度下降一般有三种:
批量梯度下降:
容易得到最优解,但是由于每次都考虑所有的样本,速度很慢

随机梯度下降:
每次随机找一个样本,迭代速度虽快,但不一定每次都朝着收敛的方向
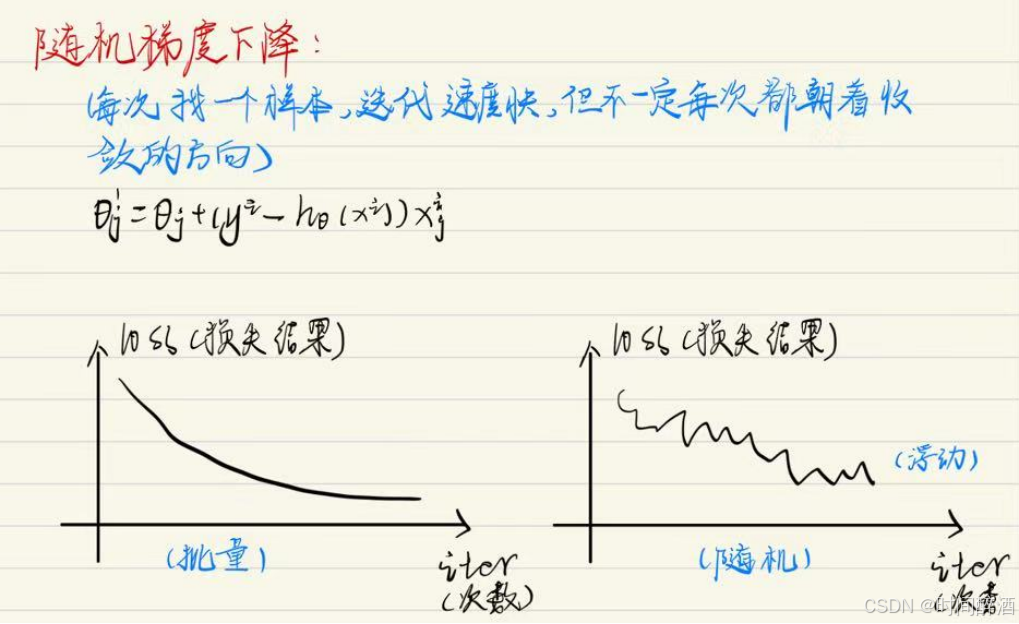
小批量下降:
每次更新选择一小部分数据来算,兼顾了批量梯度下降的稳定性和随机梯度下降的效率,是实际中最常用的方法。

总结:
批量梯度下降 (Batch Gradient Descent):
做法: 每次更新参数时,都使用全部训练样本来计算梯度。
优点: 理论上更容易收敛到全局最小值(对于凸函数),方向稳定。
缺点: 当数据量非常大时,计算成本极高,速度很慢。
随机梯度下降 (Stochastic Gradient Descent, SGD):
做法: 每次更新参数时,随机选择一个训练样本来计算梯度。
优点: 速度非常快,适合处理大规模数据,并且轻微的震荡有时有助于跳出局部最小值。
缺点: 方向不稳定,损失函数的下降过程会像“锯齿状”,可能需要更多次的迭代才能真正收敛。
小批量梯度下降 (Mini-batch Gradient Descent):
做法: 每次更新参数时,选择一个小批量(mini-batch)的训练样本(例如 32、64、128 个)来计算梯度。
优点: 兼顾了批量梯度下降的稳定性和随机梯度下降的效率。 它能够利用向量化计算来加速,同时比 SGD 更稳定,是我们实际应用中最常用的方法。
作者本人水平有限,非常欢迎任何反馈和指正,请随时指出我可能存在的误解、遗漏或表述不当之处。
我将继续深入学习机器学习和统计学领域,并持续更新我的理解和最佳实践。我愿意虚心接受反馈,不断打磨和完善我的内容,以便为读者提供更可靠、更有价值的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号