【机器学习十大算法】逻辑回归(一)
本文是逻辑回归系列的第一篇,将聚焦于其核心思想、函数转换原理和参数估计的底层逻辑(极大似然估计)。旨在帮助大家建立一个直观而深刻的理解,关于模型训练、评估和多分类等实战内容,我们将在后续篇章中探讨。”
引言:
上期我们讲了什么是线性回归,是不是对线性回归有了个基本的了解了呢,那么这次我们继续来讲一下什么是逻辑回归。
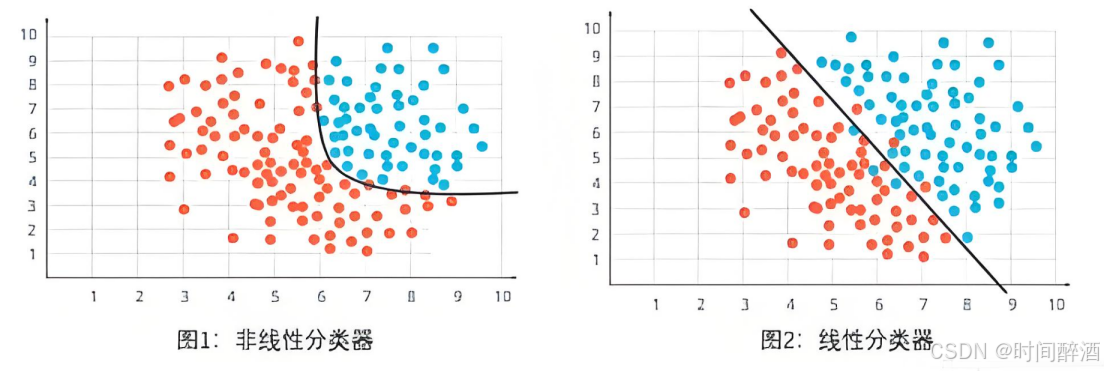
(注:逻辑回归的决策边界可以是非线性的或者是线性的)
分类和上期我们讲的回归有什么区别呢?
回归会得到一个数,而分类得到的是两个结果。举个例子。我们要预测一个同学的成绩,回归得到的是一个0到100的其中一个值,而分类判断的是这个学生的成绩是好的或者坏的。
逻辑回归虽然名字里带有“回归”,但它的本质上是一个分类算法,尤其擅长解决二分类问题,也就是将数据划分到两个类别中的一个,例如“是/否”、“成功/失败”、“正常/异常”。
那么,一个看似用于预测数值的“回归”模型,如何能帮助我们进行“分类”呢?这里就涉及到逻辑回归最核心的数学工具——Sigmoid 函数。
在此之前,我们来捋一下流程:
-
输入特征: 你的原始数据(例如用户的年龄)。
-
线性模型计算得分 (Logit): 使用线性模型(权重和偏置)对输入特征进行加权求和,得到一个任意范围的数值
。但这个
本身不足以直接用于分类。
-
Sigmoid 函数转换: 将
输入 Sigmoid 函数
。
-
概率输出: Sigmoid 函数输出一个介于 0 和 1 之间的数值,这个数值代表了样本属于“正类”的概率。
-
决策: 根据预设的阈值(通常是 0.5),将概率值转换为最终的类别预测(正类或负类)。
看到这你是否有个疑问,为什么在线性回归中不直接预测概率?
如果直接尝试用线性回归来预测一个概率值(期望输出在 [0, 1] 区间),会有以下问题:
- 输出范围不受限: 线性模型可能输出小于 0 或大于 1 的值,这不符合概率的定义。
- 非对称性: 线性模型在处理极端值时,其对概率的影响可能不够“敏感”或“平滑”。
- (不够敏感: 指的是在线性模型里,当输入分数非常极端(非常大或非常小)时,即使分数本身有较大的改变,输出的“概率”(如果在 [0, 1] 之间)变化却变得很小。模型像是“麻木”了。)
- (不够平滑: 指的是线性模型在将分数映射到输出时,如果试图强制其在 [0, 1] 之间(例如通过裁剪),会在 0 和 1 处产生断崖式的跳变,连接处不平滑,这对机器学习的训练(梯度下降)非常不利,也与现实中很多现象的连续变化规律不符。)
举个例子:
- 线性回归的“情绪温度计”: 就像一个只能用直尺在一条线上量长度。你可能会量出“负的长度”或“无限长的长度”,而且在两端,尺子的一点点移动,可能根本够不到终点,或者早已越过终点。
- Sigmoid 函数的“情绪温度计”: 就像一个弹簧。你用力向下拉(负分数),它会渐渐拉伸,但总有一个极限(非常接近 0)。你用力向上推(正分数),它也会渐渐压缩,同样有个极限(非常接近 100%)。而且,在中间最“有弹性”的时候,你稍微用点力,它的形变(高兴程度变化)会最明显。整个过程都是连续、平滑、有弹性的。
进而引出Sigmoid 函数的优点:
- 将任意输入映射到 (0, 1) 区间: 解决了输出范围问题。
- S 形曲线(非线性): 在中间区域(接近 0.5)对输入的微小变化更敏感,而在两端(接近 0 或 1)更“平缓”,这有助于对概率进行更精细的建模。
那么接下来我们详细解释一下什么是Sigmoid 函数
Sigmoid 函数 (也称为 Logistic 函数)
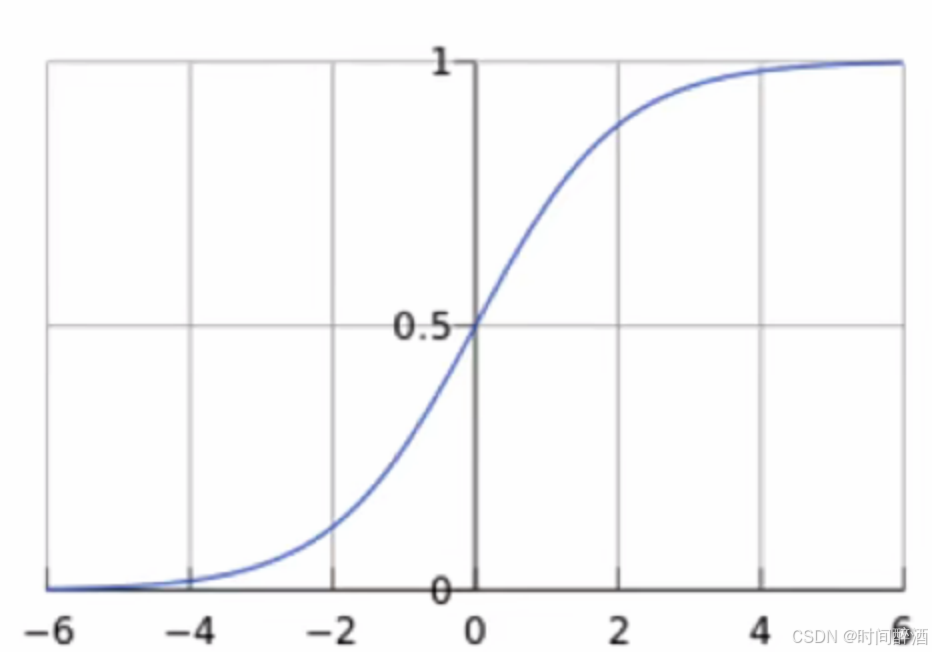
数学表达式是:
=
(自变量取任意实数,值域是[0,1])
解释:
将任意的输入映射到[0,1]区间,我们在线性回归中可以得到一个预测值,再将该值映射到Sigmoid函数中,这样就完成了由值到概率的转换(这就是Sigmoid 函数的精髓之处),也就是分类任务、
预测函数:
(其中
+
+ ,...., +
=
=
)
分类任务:
P(y = 1 | x ; ) =
p ( y = 0 | x ; ) =
![]()
解析:
对于二分类任务(0,1),整合后 y 取 0 只保留
y 取 1只保留
通过Sigmoid函数,我们已经能得到一个概率预测了。但这个预测是否准确,完全取决于我们模型参数 θ 的取值。那么,如何找到那一组‘最佳’的参数 θ,使得我们的模型做出的预测最符合我们已有的数据呢?这时,我们就需要请出‘判官’——似然函数。
1. 似然函数 (Likelihood Function)
1.1. 几个关键点:
- 数据是已知的、固定的: 你已经收集到了你的数据点。
- 模型参数是未知的: 你想找到最能解释这些数据的模型参数。
- “可能性”是关于参数的: 似然函数衡量的是,在给定的观测数据下,不同的模型参数值,哪个“看起来”最合理、最可能导致这个数据的出现。
1.2. 举个例子:抛硬币
假设你有一枚硬币,你想知道它是否是公平的。
-
“公平的”硬币: 抛出正面(H)的概率 P(H) = 0.5,抛出反面(T)的概率 P(T) = 0.5。
-
“不公平的”硬币: P(H) 可能不是 0.5,比如 P(H) = 0.7。
-
你的实验: 你抛了这枚硬币 5 次,结果是:H, T, H, H, T (2 正 3 反)。
-
你的模型: 这是一个简单的概率模型,它只有一个参数:p = 抛出正面的概率。如果有 p,那么抛出反面的概率就是 (1-p)。
-
我们现在怎么用“似然函数”来评估不同的“p”值?
-
假设 p = 0.5 (公平硬币):
- H 出现的概率是 0.5
- T 出现的概率是 0.5
- 那么,观测到 H, T, H, H, T 这个序列的概率是:
P(H, T, H, H, T | p = 0.5) = P(H | p = 0.5) * P(T | p = 0.5) * P(H | p = 0.5) * P(H | p = 0.5) * P(T | p = 0.5) = 0.5 * 0.5 * 0.5 * 0.5 * 0.5 = (0.5)^5 = 0.03125
-
假设 p = 0.7 (一个不公平的硬币):
- H 出现的概率是 0.7
- T 出现的概率是 1 - 0.7 = 0.3
- 那么,观测到 H, T, H, H, T 这个序列的概率是:
P(H, T, H, H, T | p=0.7) = P( H | p = 0.7) * P( T | p = 0.7) * P( H | p = 0.7) * P( H | p = 0.7) * P(T | p = 0.7 )= 0.7 * 0.3 * 0.7 * 0.7 * 0.3 = (0.7)^3 * (0.3)^2 = 0.343 * 0.09 = 0.03087
-
假设 p = 0.6 (另一个不公平的硬币):
- H 出现的概率是 0.6
- T 出现的概率是 1 - 0.6 = 0.4
- 那么,观测到 H, T, H, H, T 这个序列的概率是:
P(H, T, H, H, T | p=0.6) = (0.6)^3 * (0.4)^2 = 0.216 * 0.16 = 0.03456
-
-
定义似然函数 L(p):
- 我们把刚才计算的在给定参数 p 下,观测到数据的概率看作一个关于参数 p 的函数。这就是似然函数。
- L(p) = P(观测到的数据 | p)
- 对于我们的例子,L(p) = p^3 * (1-p)^2
-
似然函数的作用:
- 它帮助我们比较:哪一个
p值,能够 “最有可能” 产生我们看到的 H, T, H, H, T 这个结果? - 在上面的计算中,L(0.5) = 0.03125,L(0.7) = 0.03087,L(0.6) = 0.03456。
- 显然,L(0.6) 比 L(0.5) 和 L(0.7) 都大。这意味着,根据我们观测到的 2 正 3 反的数据,p=0.6 这个参数值,比 p=0.5 或 p=0.7 更能“解释”我们观测到的结果。
- 它帮助我们比较:哪一个
-
最大似然估计 (Maximum Likelihood Estimation, MLE):
- 我们的目标就是找到那个能使似然函数 L(p) 达到最大的 p 值。
- 通过微积分的方法,我们可以找到使 L(p) = p^3 * (1-p)^2 最大的
p值。对于这个例子:- 对 L(p) 求导,令导数为 0,可以解出 p = 3/5 = 0.6。
- 所以,最大似然估计告诉我们,基于观测到的 2 正 3 反的结果,我们最“相信”硬币抛出正面的概率是 0.6。
1.3. 总结似然函数:
-
输入: 模型参数。
-
输出: 观测到的数据出现的可能性(概率)。
-
目标: 寻找使这个输出值最大的模型参数。
上面我们提到,似然函数衡量的是,在给定的观测数据下,不同的模型参数值,哪个“看起来”最合理、最可能导致这个数据的出现。有点绕是不是?因为可能性”是针对“数据的”,但它的评估(似然值)却是关于“参数的”。那么接下来我们引进对数似然,这样,我们就不再是找哪个参数能让观测到的结果发生的可能性最大,而是哪个参数能让观测到的结果发生的对数可能性最大。
2. 对数似然 (Log-Likelihood)
-
为什么要用对数?
- 我们经常需要将多个事件的可能性相乘。比如,连续观测到两个人买了东西,我们想知道“两个人同时都买”的概率,就需要把第一个人买的概率乘以第二个人买的概率。
- 问题是: 概率通常是小于 1 的小数(比如 0.8, 0.9)。如果概率很小,连续相乘很多次,结果会变得非常非常小,小到计算机可能都会算成 0(发生“下溢”)。
- 对数的神奇之处:
log(a * b) = log(a) + log(b)log(a / b) = log(a) - log(b)log(a^b) = b * log(a)
- 它把“乘法”变成了“加法”。 这样,我们就可以把一连串非常小的数相乘,变成一连串数相加。这样计算起来更稳定,也不容易因为数太小而出错。
- 另外, 对数函数
log(x)对于x > 0是一个单调递增的函数。这意味着,如果 Likelihood 越大,它的 Log-Likelihood 也越大;如果 Likelihood 越小,它的 Log-Likelihood 也越小。所以,最大化 Likelihood 和最大化 Log-Likelihood,最终会找到同样的模型参数。 - 而这个对数似然函数的负数,就是我们今天在机器学习中训练逻辑回归模型时真正最小化的目标函数——交叉熵损失函数(Cross-Entropy Loss)。最小化交叉熵损失等价于最大化似然函数,都是为了找到最优参数。机器学习框架更喜欢最小化(求最小值)的优化问题,因此这个转换在实践中最常用。
-
对数似然是什么?
- 就是把似然函数的值取个对数。
- 这样,我们就不再是找哪个参数能让观测到的结果发生的可能性最大,而是哪个参数能让观测到的结果发生的对数可能性最大。
- 这在数学计算上更方便。
篇幅有限,本篇文章已经接近尾声啦。我们总结一下本期内容
总结:
本期文章深入浅出地讲解了逻辑回归的核心思想。虽然名字中带有“回归”,但它实质上是一个二分类算法,用于预测样本属于某个类别(如“是/否”)的概率,而非连续的数值。
其核心流程在于:
-
线性计算:像线性回归一样,计算特征的加权和(
z)。 -
概率映射:通过神奇的 Sigmoid 函数,将任意范围的
z值平滑地、非线性地压缩到(0, 1)区间,将其转化为一个概率值。这是逻辑回归得名的原因,也是它能完成分类任务的关键。 -
决策分类:设定一个阈值(通常为0.5),将得到的概率转化为最终的类别标签。
为了找到最佳的模型参数,文章引入了似然函数的概念。我们追求的是让当前观测到的数据“最有可能”发生的那个参数(最大似然估计)。为了计算方便,实践中通常使用对数似然函数(即将连乘转化为求和),其本质与最大化似然函数是等价的。
总而言之,逻辑回归通过Sigmoid函数搭建起了回归与分类之间的桥梁,并用最大似然估计作为“判官”来寻找最优参数,是一个非常强大且基础的分类模型。
作者本人水平有限,非常欢迎任何反馈和指正,请随时指出我可能存在的误解、遗漏或表述不当之处。
我将继续深入学习机器学习和统计学领域,并持续更新我的理解和最佳实践。我愿意虚心接受反馈,不断打磨和完善我的内容,以便为读者提供更可靠、更有价值的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号