逻辑回归(三):从原理到实战-训练,评估与应用指南
引言:
在上一篇文章中,我们并肩完成了机器学习项目中至关重要的一步:数据预处理。我们成功地将一个原始数据集——清除了异常值、填补了缺失信息、将文本标签转换为数字、并进行了标准化处理——转变为了干净、规整、可供模型直接“消化”的格式 (
X_train, X_test, y_train, y_test)。现在,是时候让这些数据发挥真正的价值了!
Step1:数据可视化
作用是:检查数据质量。
这时有人就会问了,怎么又检查数据质量,上一篇Step3数据加载那里不是已经检查了吗?
数据加载后的初步检查(如df.info(), df.describe())确实是检查数据质量的第一步,并且根据这些发现来进行预处理(如处理缺失值)是标准流程。
然而,数据可视化并不是重复这一步,而是在此基础上进行的更深入、更直观的探索。它们的关系是递进和互补的,而不是替代。
举个例子:
-
数据加载
.describe():就像医生拿到了一份详细的体检报告文本,上面有各种指标的数值、最大值、最小值、平均值。医生能从中发现一些明显问题,比如“白细胞计数远高于正常值”。 -
数据可视化:就像是医生在看了报告后,又亲自查看X光片、CT扫描影像。它能揭示数值本身无法直接传达的深层信息,比如肿瘤的具体形状、位置和与周围组织的关系。
以下是两者具体的分工与合作:
1. 处理“异常值”的不同维度
-
数值检查(
.describe(),.info()):-
能发现:一个年龄字段出现了
-1或300这种明显错误的异常值。 -
不能发现:一个身高字段的值是
1.85m,在数值上是合理的,但对于一个“2岁婴儿”这个类别来说,它就是一个上下文异常值(Contextual Outlier)。这种异常需要通过散点图(例如年龄-身高散点图)才能清晰地被发现。
-
2. 理解特征之间的关系
-
数值检查:可以计算出特征之间的相关系数矩阵(比如
P_L和P_W的相关系数是0.96)。你知道它们相关性强,但不知道它们是如何相关的。 -
数据可视化(散点图):
-
不仅能验证这种相关性。
-
更能展示这种关系的具体形态:是线性关系?还是指数关系?是否存在明显的分组?(正如我们在鸢尾花数据中看到的三个清晰的簇)。这种直观印象对于选择正确的模型(线性vs非线性)至关重要。
-
3. 评估特征对于分类任务的有效性
这是可视化无可替代的核心价值。
-
数值检查:你可以看到
山鸢尾的P_L平均值是1.46,维吉尼亚鸢尾的是5.55。你知道它们有差异。 -
数据可视化(箱线图或小提琴图):
-
可以一眼看出:两个类别的
P_L分布重叠区域非常小,几乎完全分离。这立刻告诉你,单凭这一个特征就能很好地区分这两个类别。 -
可以对比发现:
S_W(花萼宽度)的分布在不同类别间重叠很大,说明其区分能力较弱。
-
4. 发现意想不到的模式
数值指标是你要主动去查询才能得到的。而可视化有时能让你被动地发现一些你没想到要去查询的潜在模式。
-
例子:在绘制所有特征的分布直方图时,你可能意外发现
花萼宽度是双峰分布。这可能会引导你去思考:“为什么会出现两个峰值?是不是数据中混入了另一个未被标注的类别?或者是测量系统存在两种不同的模式?”
而数据可视化是在这个基础上,进行的更深层次的“诊断”。它让我们超越冰冷的数字,真正地“看见”数据,从而做出更明智的、基于直觉和洞察的决策,而不仅仅是基于统计指标。
代码如下:
# 创建子图
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 特征分布直方图
features = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']
colors = ['red', 'green', 'blue']
for i in range(4):
row, col = i // 2, i % 2
for label, color in zip(range(3), colors):
axes[row, col].hist(X[y == label, i], alpha=0.7,
label=f'{le.inverse_transform([label])[0]}',
color=color)
axes[row, col].set_title(features[i])
axes[row, col].legend()
plt.tight_layout()
plt.show()
# 特征相关性热力图
df_numeric = df.iloc[:, :-1]
df_numeric.columns = features
#确保数据是数值类型
df_numeric = df.iloc[0:, :-1].copy()
df_numeric.columns = features
# 将每列转换为数值类型,无法转换的值设为NaN
for col in df_numeric.columns:
df_numeric[col] = pd.to_numeric(df_numeric[col], errors='coerce')
# 删除包含NaN的行
df_numeric = df_numeric.dropna()
plt.figure(figsize=(8, 6))
sns.heatmap(df_numeric.corr(), annot=True, cmap='coolwarm')
plt.title('特征相关性热力图')
plt.show()
# 散点图矩阵
df_vis = df_numeric.copy()
# 确保y的长度与df_vis一致
if len(y) != len(df_vis):
# 如果长度不一致,我们需要调整y
# 找到df_numeric的索引与原始数据的对应关系
valid_indices = df_numeric.index
y_filtered = y[valid_indices]
df_vis['类别'] = le.inverse_transform(y_filtered)
else:
df_vis['类别'] = le.inverse_transform(y)
sns.pairplot(df_vis, hue='类别', palette='viridis')
plt.suptitle('特征散点图矩阵', y=1.02)
plt.show()结果如下:
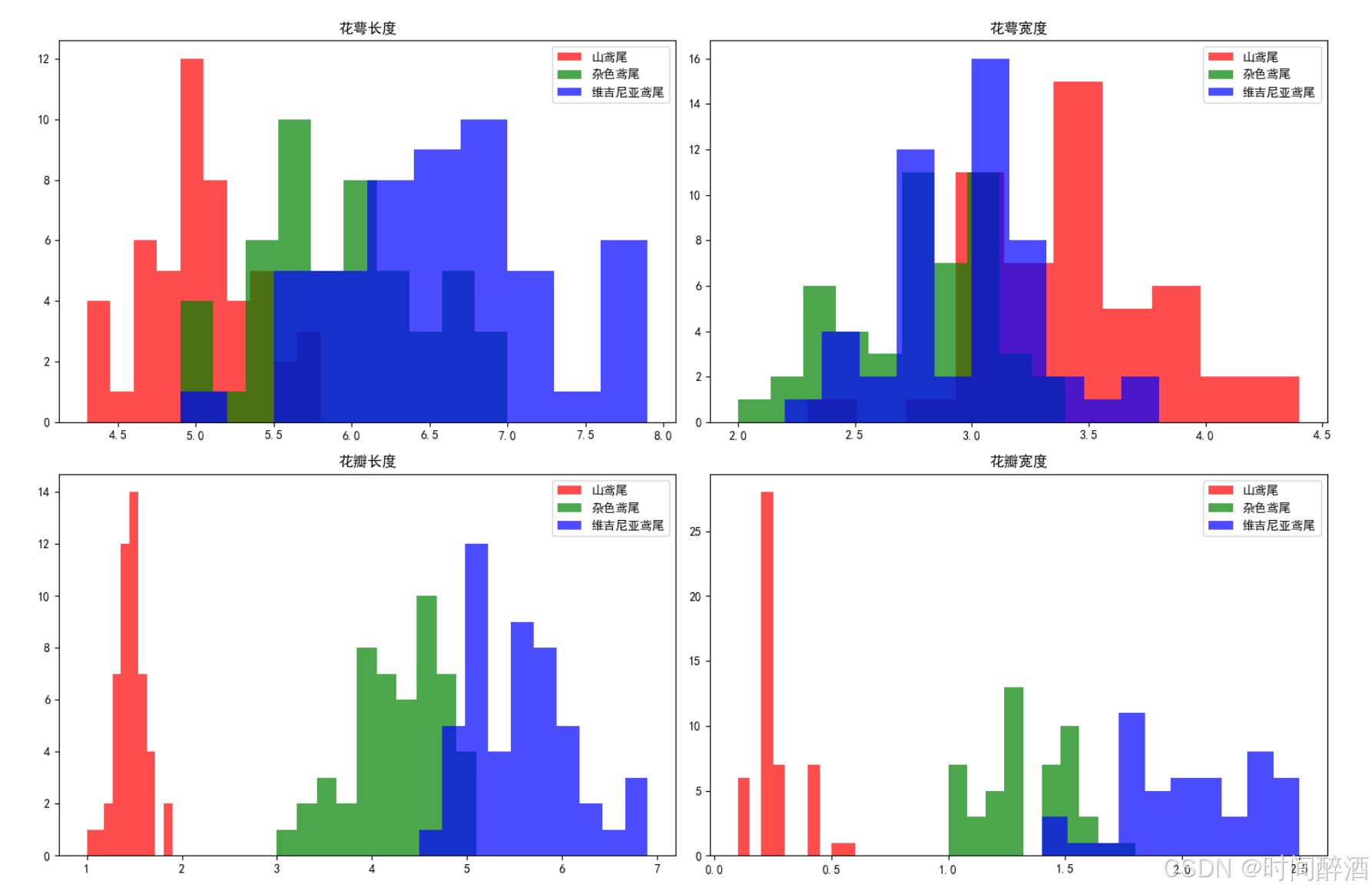
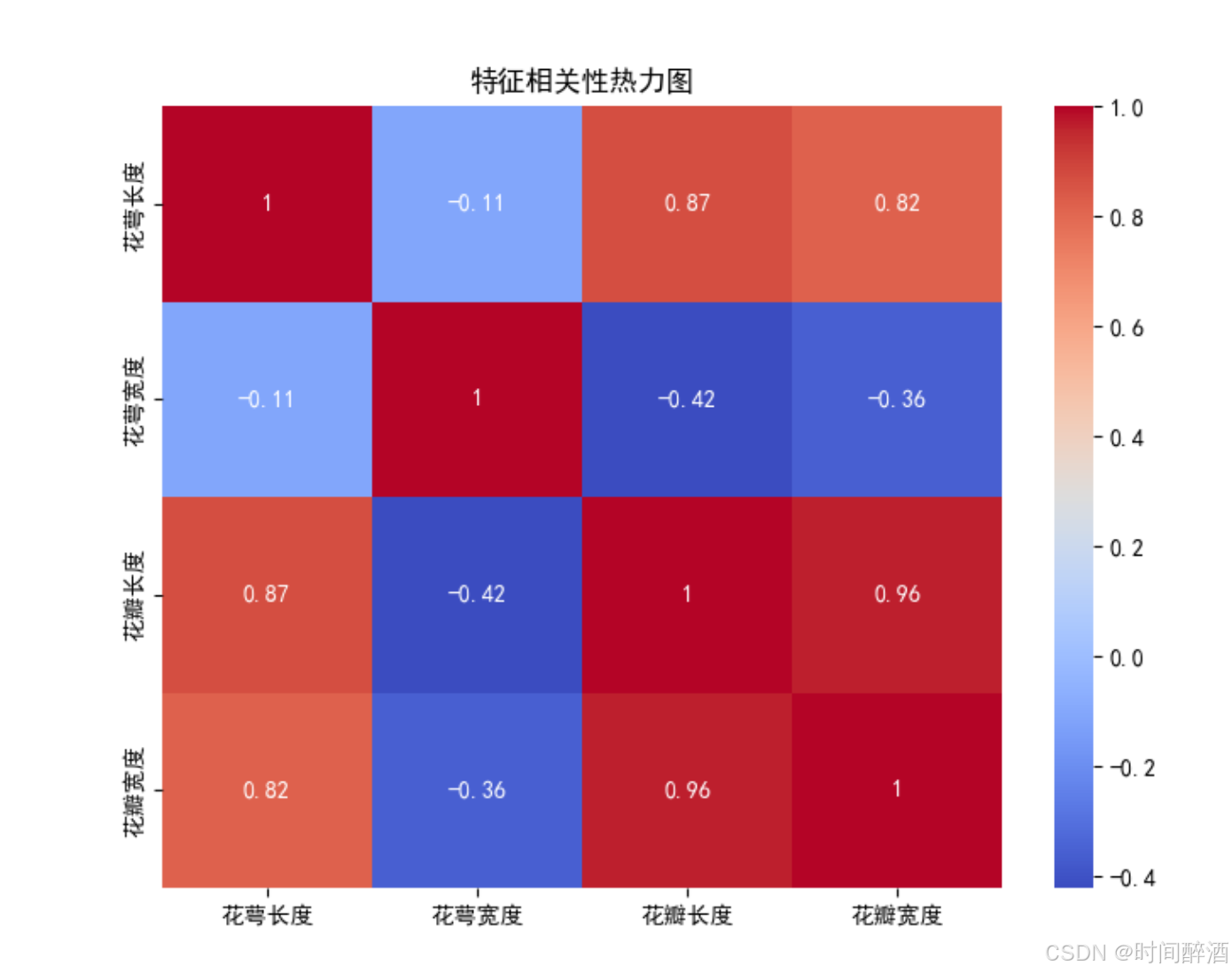
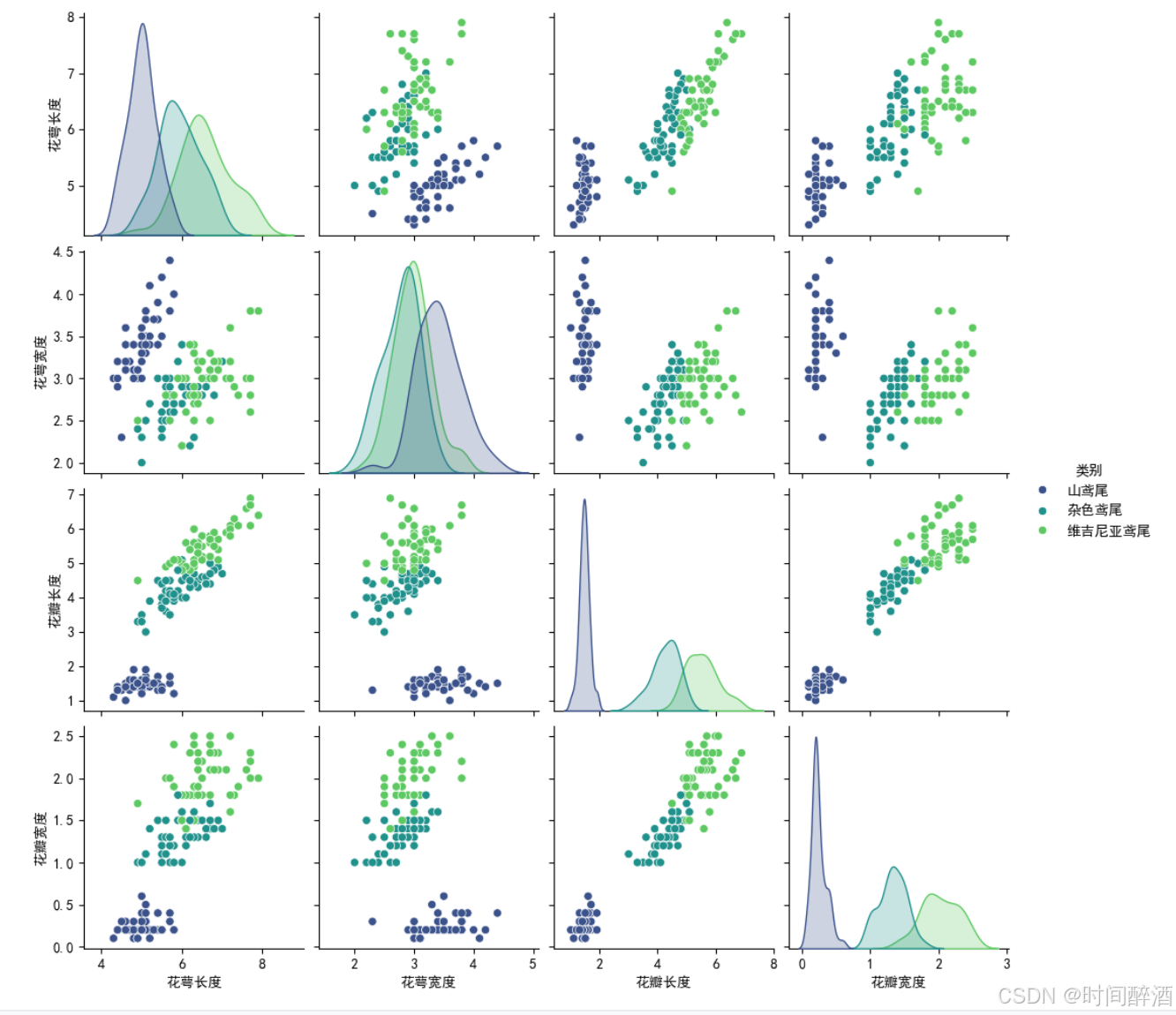
图表解读:
每个子图都显示了一个特征(花萼长度或花萼宽度)的分布,并用不同颜色区分了三种鸢尾花(山鸢尾、杂色鸢尾、维吉尼亚鸢尾)。Y轴表示样本数量或密度,X轴表示特征的测量值(单位为厘米)。
分特征分析
1. 花萼长度(Sepal Length)
-
分布形态:三个种类的分布都接近正态分布(钟形曲线)。
-
区分度:
-
山鸢尾的分布整体偏左(值较小),平均值最低。
-
维吉尼亚鸢尾的分布整体偏右(值较大),平均值最高。
-
杂色鸢尾的分布位于中间,与另外两个类别有较多的重叠。
-
-
结论:花萼长度在一定程度上可以区分山鸢尾和维吉尼亚鸢尾,但由于杂色鸢尾与两者都有大量重叠,仅凭这一个特征无法完美区分三个类别。
2. 花萼宽度(Sepal Width)
-
分布形态:分布形态不如花萼长度规整,尤其是杂色鸢尾的分布显示出双峰形态。
-
区分度:
-
重叠非常严重。三个类别的分布曲线几乎完全重叠在一起,集中在3.0 cm左右的区域。
-
虽然山鸢尾的分布感觉更宽一些,维吉尼亚鸢尾更紧凑一些,但差异极其微小,几乎没有区分能力。
-
-
结论:花萼宽度是三个类别中区分效果最差的特征。单独使用它来分类,效果会非常随机,接近于瞎猜。
总结:
-
特征重要性排序:
从这组图可以直观地看出,在这个数据集中,花萼长度 > 花萼宽度。花萼长度至少提供了一些有用的信息,而花萼宽度几乎无法提供区分信息。 -
为什么需要多特征模型:
-
单一特征的局限性:没有一个特征能独自完美区分所有类别。
-
模型需要组合特征:机器学习模型(如逻辑回归、决策树)的强大之处在于能够同时考虑多个特征(例如同时使用花萼长度、花萼宽度、花瓣长度、花瓣宽度)来构建一个复杂的决策边界,从而实现高精度分类。
-
-
为模型选择提供参考:
-
由于特征分布有重叠且关系复杂,简单的线性分类器(如逻辑回归)可能无法达到极高的准确率,因为它会试图用一条直线去划分。
-
而非线性模型(如决策树、随机森林或带RBF核的SVM)更能捕捉这些特征之间复杂的交互关系,从而表现出更好的性能。(但本篇仍选择逻辑回归做模型方便教学)
-
总之,这张图非常经典地展示了特征效用的差异,可以很好的解释“为什么要看数据”以及“要用什么模型”。
代码解析:
# 创建子图
fig, axes = plt.subplots(2, 2, figsize=(15, 10))plt.subplots(2, 2): 创建一个包含 2 行 2 列(共 4 个)子图的图形。fig: 返回的是整个图形对象,可以用来存储或操作图形级别的信息(例如设置整体标题,虽然这里没用到)。axes: 返回的是一个 NumPy 数组,形状为(2, 2),包含了每个子图的 Axes 对象。我们可以通过axes[row, col]来访问特定的子图。figsize=(15, 10): 设置整个画布(figure)的尺寸为 15 英寸宽,10 英寸高。
# 特征分布直方图
features = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']
colors = ['red', 'green', 'blue']
for i in range(4):
row, col = i // 2, i % 2
for label, color in zip(range(3), colors):
axes[row, col].hist(X[y == label, i], alpha=0.7,
label=f'{le.inverse_transform([label])[0]}',
color=color)
axes[row, col].set_title(features[i])
axes[row, col].legend()
plt.tight_layout()
plt.show()-
colors = [...]: 定义一个包含三个颜色的列表,用于区分三个不同的鸢尾花类别。zip函数会依次取出'red'对应标签0,'green'对应标签1,'blue'对应标签2。 -
for i in range(4):: 这个外层循环负责遍历数据集中的四个特征。i的值将是 0, 1, 2, 3,分别对应X数组中的四列。 -
row, col = i // 2, i % 2:- 这个计算将一维的特征索引
i映射到二维axes数组的行 (row) 和列 (col) 索引。 - 当
i=0时,row=0//2=0,col=0%2=0->axes[0, 0](左上角) - 当
i=1时,row=1//2=0,col=1%2=1->axes[0, 1](右上角) - 当
i=2时,row=2//2=1,col=2%2=0->axes[1, 0](左下角) - 当
i=3时,row=3//2=1,col=3%2=1->axes[1, 1](右下角)
- 这个计算将一维的特征索引
-
for label, color in zip(range(3), colors)::- 这个内层循环负责在同一个子图中,为当前特征绘制每个类别的直方图。
range(3)生成类别标签 0, 1, 2。zip将0与red配对,1与green配对,2与blue配对。le变量(LabelEncoder的实例)用于将标签(如 0)转换回原始字符串类别名,以便图例更易读。
-
(这是绘制直方图的核心语句。)axes[row, col].hist(X[y == label, i], alpha=0.7, label=f'{le.inverse_transform([label])[0]}', color=color): X[y == label, i]: 这是 NumPy 的高级索引。, i: 进一步从选取的行中,只选取第i列(即当前正在处理的特征)的值。X[...]: 使用这个布尔数组来选择X中的行(即属于当前类别的样本)。y == label: 创建一个布尔数组,其中True对应于y中值等于当前label的位置,False对应其他位置。alpha=0.7: 直方图的透明度,这样当不同类别的直方图重叠时,我们能看到它们。label=f'{le.inverse_transform([label])[0]}: 为这个直方图条目设置图例文字。le.inverse_transform是LabelEncoder的一个方法,用于将编码后的数字标签(如[0])转换回原始的类别名称。color=color: 指定该类别直方图的颜色。
-
axes[row, col].set_title(features[i]): 将当前子图的标题设置为对应特征的中文名称。 -
axes[row, col].legend(): 显示当前子图的图例,指示每种颜色代表的类别。 -
plt.tight_layout(): 这是一个非常实用的函数,它能够自动调整子图之间的间距,防止标题、轴标签等元素重叠,使整个图形看起来更整洁。 -
plt.show(): 显示最终渲染出来的图形。
# 特征相关性热力图
df_numeric = df.iloc[:, :-1]
df_numeric.columns = features
plt.figure(figsize=(8, 6))
sns.heatmap(df_numeric.corr(), annot=True, cmap='coolwarm')
plt.title('特征相关性热力图')
plt.show()补充一下有关热力图的知识:
目的:
可视化数据集中不同数值特征之间的线性相关性。热力图通过颜色深浅和数值标注来展示相关系数的大小。
- 相关系数: 通常指皮尔逊相关系数,取值范围在 -1 到 +1 之间。
- +1: 完全正相关 (一个特征增加,另一个也按比例增加)。
- 0: 无线性相关。
- -1: 完全负相关 (一个特征增加,另一个按比例减少)。
- 价值:
- 识别高度相关的特征。如果两个特征高度相关,它们可能携带了相似的信息,可以考虑保留其中一个,以减少模型的复杂性或避免多重共线性问题。
- 了解哪些特征与目标变量(虽然这里是计算数值特征之间的相关性,但后续通常会扩展到包括目标变量)之间存在较强的关系。
-
df_numeric = df.iloc[:, :-1]:df: 一个 Pandas DataFrame,存储了鸢尾花数据,最后一列是类别标签。.iloc[:, :-1]:iloc是基于整数位置进行索引。:表示选取所有行。:-1表示选取从第一列到倒数第二列的所有列。这样就排除了最后一列的类别标签。
-
df_numeric.columns = features:- 为
df_numericDataFrame 设置列名。这里将原本可能是默认的列名(如 0, 1, 2, 3)替换成了我们之前定义的中文特征名称列表features。这使得后续的df_numeric.corr()结果中的列名也更具可读性。
- 为
-
plt.figure(figsize=(8, 6)):- 创建一个新的图形(figure),而不是在之前的
axes子图上绘制。 figsize=(8, 6): 设置这个图形的尺寸为 8 英寸宽,6 英寸高。
- 创建一个新的图形(figure),而不是在之前的
-
sns.heatmap(df_numeric.corr(), annot=True, cmap='coolwarm'):sns.heatmap(): Seaborn 库功能强大的函数,用于绘制热力图。df_numeric.corr(): 这是 Pandas DataFrame 的一个方法,用于计算 DataFrame 中所有数值列的 pairwise (两两之间) 的皮尔逊相关系数。它返回一个 DataFrame,其行和列都是原始 DataFrame 的数值列名,单元格的值是对应的相关系数。annot=True: 在热力图的每个单元格上显示相关系数的数值。这对于精确查看相关性非常有用。cmap='coolwarm': 指定颜色映射表。'coolwarm'(冷暖)是一种常见的选择,它用冷色调(如蓝色)表示负相关,暖色调(如红色)表示正相关,接近于零的值则用中间色(如白色或浅灰色)。
-
plt.title('特征相关性热力图'): 设置当前图形的标题。 -
plt.show(): 显示绘制的热力图。
# 散点图矩阵
df_vis = df_numeric.copy()
df_vis['类别'] = le.inverse_transform(y)
sns.pairplot(df_vis, hue='类别', palette='viridis')
plt.suptitle('特征散点图矩阵', y=1.02)
plt.show()同样这里补充一下有关散点图矩阵的知识:
目的:
可视化数据集中任意两个数值特征之间的散点图。这种图的布局是:
- 对角线上:通常会显示单个特征的直方图或 KDE (核密度估计) 图,用于显示该特征的分布。
- 非对角线上:显示两个不同特征之间的散点图。
hue参数: 使用不同的颜色来区分不同的类别(鸢尾花种类)。
价值:
- 洞察特征关系: 直观地展示两个特征之间是否存在线性、非线性关系。
- 类别可分性: 最重要的是,它能非常清晰地展示不同类别在二维特征空间中的分布。我们可以很容易地看到哪些特征组合能最好地将不同的鸢尾花类别分开。例如,如果 Setosa 类别在某个散点图的区域非常清晰地与其他类别分离,那么这对特征组合(x轴特征和y轴特征)对区分 Setosa 非常有效。
- 模式识别: 发现不同类别个体在特征空间中的聚集趋势和离散程度。
-
df_vis = df_numeric.copy():- 创建一个
df_numeric的深拷贝。这样做是为了确保我们后续的操作(如添加 '类别' 列)不会影响到原始df_numericDataFrame,这是良好的编程习惯。
- 创建一个
-
df_vis['类别'] = le.inverse_transform(y):le.inverse_transform(y): 将目标向量y(里面是 0, 1, 2 这样的数字标签)转换回原始的字符串类别名称。df_vis['类别'] = ...: 将这些转换后的类别名称作为一个新的列,添加到df_visDataFrame 中,列名为'类别'。
-
sns.pairplot(df_vis, hue='类别', palette='viridis'):sns.pairplot(): Seaborn 库的核心函数之一,用于绘制数据集的成对关系图。df_vis: 输入的 DataFrame,它包含了数值特征和用于分组的 '类别' 列。hue='类别': 这是pairplot最重要的参数之一。它告诉 Seaborn,根据df_visDataFrame 中名为'类别'的列的值,来对散点图上的点进行着色。这样,每个类别的点就会显示为不同的颜色。palette='viridis': 指定用于hue着色的颜色方案。'viridis'是一种感知均匀的颜色映射,视觉效果不错。seaborn 和 matplotlib 提供了许多预设的颜色方案pairplot的内部机制:- 它会找到
df_vis中所有非hue参数指定的列(在这里是 '花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度')。 - 对于每一对这样的数值特征,它都会创建一个散点图,其中一个特征作为 x 轴,另一个作为 y 轴。
- 在对角线上,它会绘制与该行/列对应的单一特征的分布图。默认情况下,如果指定了
hue,对角线会是 KDE 图;如果没有,可能是直方图。 - 总共会生成 N x N 个子图,其中 N 是数值特征的数量。对于鸢尾花,N=4,所以会生成 4x4 = 16 个子图。
- 它会找到
-
plt.suptitle('特征散点图矩阵', y=1.02):plt.suptitle(): 用于为整个图形(figure)设置一个总的标题。y=1.02: 控制标题的垂直位置。y=1通常表示图形的顶部边缘,y=1.02稍微将标题向上移动一点,以避免它与pairplot生成的顶部子图上的标题重叠。
-
plt.show(): 显示最终渲染出来的所有散点图构成的矩阵。
总结:
这段代码通过三个不同的可视化工具(直方图、热力图、散点图矩阵)系统地探索了鸢尾花数据集:
-
直方图:聚焦于单个特征及其在不同类别下的分布,帮助理解每个特征如何描述不同类别。
-
热力图:聚焦于数值特征之间的线性相关性,帮助识别冗余特征或强关联特征。
-
散点图矩阵:集成了两个特征之间的关系以及类别在二维空间中的可分性,是识别分类边界和理解整体数据结构最有力的工具之一。
这些可视化步骤共同为理解鸢尾花数据的内在结构、特征的有效性以及不同类别之间的区分度提供了丰富的视觉洞察。
下一步预告:数据可视化准备就绪后,我们将进入最核心的环节——模型训练与评估。在下一篇文章中,我们将:
1.使用 scikit-learn 轻松调用分类算法(逻辑回归)在训练集上进行训练。
2.使用训练好的模型对测试集进行预测。
3.深入讲解并运用多种评估指标(如准确率、混淆矩阵、分类报告)来全面衡量模型的性能。
4.对比不同模型在此任务上的表现。
敬请期待:逻辑回归(四):从原理到实战 - 训练、评估与应用指南 (链接将在文章发布后更新)
作者本人水平有限,非常欢迎任何反馈和指正,请随时指出我可能存在的误解、遗漏或表述不当之处。
我将继续深入学习机器学习和统计学领域,并持续更新我的理解和最佳实践。我愿意虚心接受反馈,不断打磨和完善我的内容,以便为读者提供更可靠、更有价值的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号