逻辑回归(二):从原理到实战 - 训练、评估与应用指南
引言:
上期我们讲了什么是逻辑回归,了解了它如何利用Sigmoid函数将线性回归的输出转化为概率,并通过最大似然估计来寻找最佳参数。今天,我们将继续这段旅程,学习如何训练这个
模型、如何评估它的表现,以及如何在真实世界中应用它。
回顾第一篇结尾,我们得到了(对数)似然函数,目标是找到使其最大化的参数θ。但如何找到呢?—— 梯度下降,如果模型训练好了,如何衡量它的好坏?—— 评估指标,在本篇文章当中我们用鸢尾花分类这个经典案例讲解如何运用我们之前所学的知识,构建一个预测模型。
(找到使其最大化的参数θ所用到的梯度下降在这篇文章【机器学习十大算法】线性回归(二)中有详细的理论解释。)
Step1:下载数据集
链接: https://pan.baidu.com/s/1yIMbV6xO_P_3TdTNLGs4NQ?pwd=732q提取码: 732q
先简单观察一下这个数据集
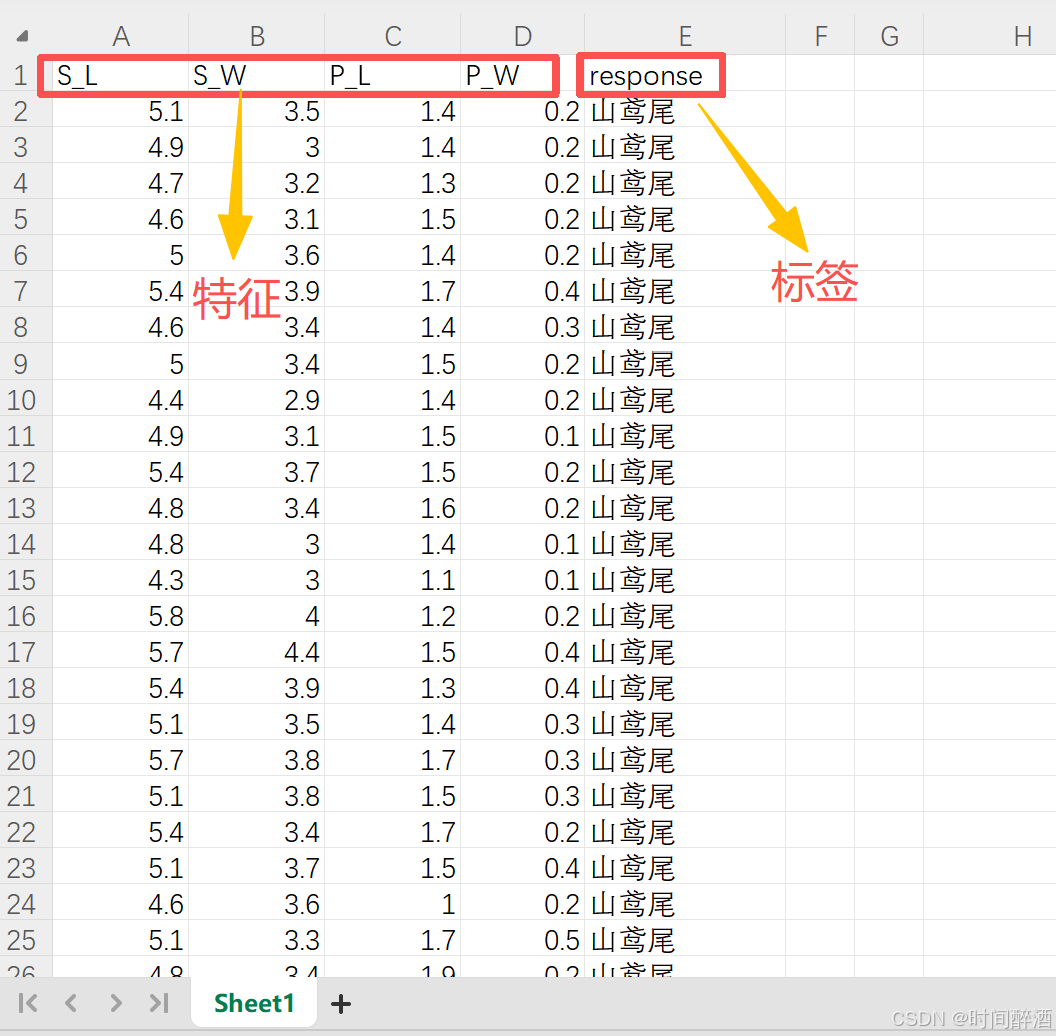
特征说明:
| 列名 | 含义 | 数据类型 | 说明 |
|---|---|---|---|
| S_L | 花萼长度 | 数值型 | Sepal Length |
| S_W | 花萼宽度 | 数值型 | Sepal Width |
| P_L | 花瓣长度 | 数值型 | Petal Length |
| P_W | 花瓣宽度 | 数值型 | Petal Width |
| response | 鸢尾花种类 | 文本型 | 分类标签 |
类别分布:
数据集中包含三种鸢尾花:
| 类别 | 样本数量 |
|---|---|
| 山鸢尾 | 50 |
| 杂色鸢尾 | 50 |
| 维吉尼亚鸢尾 | 50 |
(这给数据集只是方便教学使用,在实际开发当中我们并不总能找到这么完美的数据集)
Step2:导入必要的库(我用的软件是pycharm,用conda管理环境,具体可参考这篇Conda 环境管理与 PyCharm 集成实战:从创建到包安装的全方位指南)
pip install pandas numpy matplotlib seaborn scikit-learn openpyxl或者激活conda环境后:
conda install pandas numpy matplotlib seaborn scikit-learn openpyxl分析一下这些库:
pandas: 数据分析和处理的“瑞士军刀”,提供 DataFrame 来轻松处理表格数据。numpy: 用于高效数值计算的底层库,核心是多维数组 (ndarray)。matplotlib: Python 中最基础、最通用的数据可视化库,用于创建各种图表。seaborn: 基于 Matplotlib,提供更美观、更强大的统计图表,尤其适合探索性数据分析。scikit-learn: 机器学习的标准库,提供易于使用的算法和工具,用于模型训练和评估。openpyxl: 用于读取和写入.xlsx格式 Excel 文件的库。
Step3:数据加载和探索
这步主要是让你清楚数据集的结构等等,在数据集较为庞大的时候尤为重要
# -*- coding: gbk -*- #编码声明,防止非 UTF-8 报错
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 加载数据(记得将数据集导入pycharm项目,最简单的方法就是拖进去)
df = pd.read_excel('Data1-train.xlsx', sheet_name='Sheet1')
# 数据探索
print("数据集形状:", df.shape)
print("\n前5行数据:")
print(df.head())
print("\n数据基本信息:")
print(df.info())
print("\n描述性统计:")
print(df.describe())
print("\n类别分布:")
print(df['response'].value_counts())结果:
数据集形状: (154, 5)
前5行数据:
S_L S_W P_L P_W response
0 5.1 3.5 1.4 0.2 山鸢尾
1 4.9 3 1.4 0.2 山鸢尾
2 4.7 3.2 1.3 0.2 山鸢尾
3 4.6 3.1 1.5 0.2 山鸢尾
4 5 3.6 1.4 0.2 山鸢尾
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 154 entries, 0 to 153
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 S_L 151 non-null object
1 S_W 151 non-null object
2 P_L 151 non-null object
3 P_W 151 non-null object
4 response 151 non-null object
dtypes: object(5)
memory usage: 6.1+ KB
None
描述性统计:
S_L S_W P_L P_W response
count 151 151 151.0 151.0 151
unique 36 24 44.0 23.0 4
top 5 3 1.5 0.2 山鸢尾
freq 10 26 14.0 28.0 50
类别分布:
response
山鸢尾 50
杂色鸢尾 50
维吉尼亚鸢尾 50
response 1
Name: count, dtype: int64
Process finished with exit code 0
这样我们不仅对数据集有个大概的了解还能及时发现异常,看完之后我们就可以将数据探索这部分的代码注释掉了,结果会决定我们后面对数据进行预处理的方法(前面我们提到,数据集不总是完美的,可能会有数据缺失,类别不平衡的问题,这个时候我们就可以根据需要选择重采样等方法去进行数据预处理)
观察后我们发现了异常,类别分布中显示将response错误认为是一种类别并且显示数量为1,在Step4我们做些处理删掉这一行。
Step4:数据预处理
#删除异常值
df_0 = df[df['response'] != 'response']
# 删除空行,删除缺失值
df_0 = df_0.dropna()
# 确认数据清理后的形状
print("清理后数据集形状:", df_0.shape)
# 分离特征和目标变量
X = df_0.iloc[:, :-1].values # 所有行,除最后一列外的所有列
y = df_0.iloc[:, -1].values # 所有行,只取最后一列
# 将类别标签转换为数值
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# 查看编码映射
print("类别编码:", list(le.classes_))
print("编码对应:", dict(zip(le.classes_, le.transform(le.classes_))))
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y)
print(f"训练集大小: {X_train.shape}") # (样本数, 特征数)
print(f"测试集大小: {X_test.shape}")
# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
结果如下:

代码解析:
# 分离特征和目标变量:
x = df_0.iloc[:, :-1].values
iloc 是基于整数位置的索引。 : 表示选择所有行。 :-1 表示选择从第一列到倒数第二列(不包含最后一列)。.values 将选取的 DataFrame 部分转换为 NumPy 数组。(这部分代码用于提取所有特征列,并将它们存储在 NumPy 数组 x 中)
y = df_0.iloc[:, -1].values
其他同上,.values 将选取的 最后一列转换为 NumPy 数组。(这部分代码用于提取目标变量列(通常是分类标签),并存储在 NumPy 数组 y 中。)
简单来说就是这么选的:
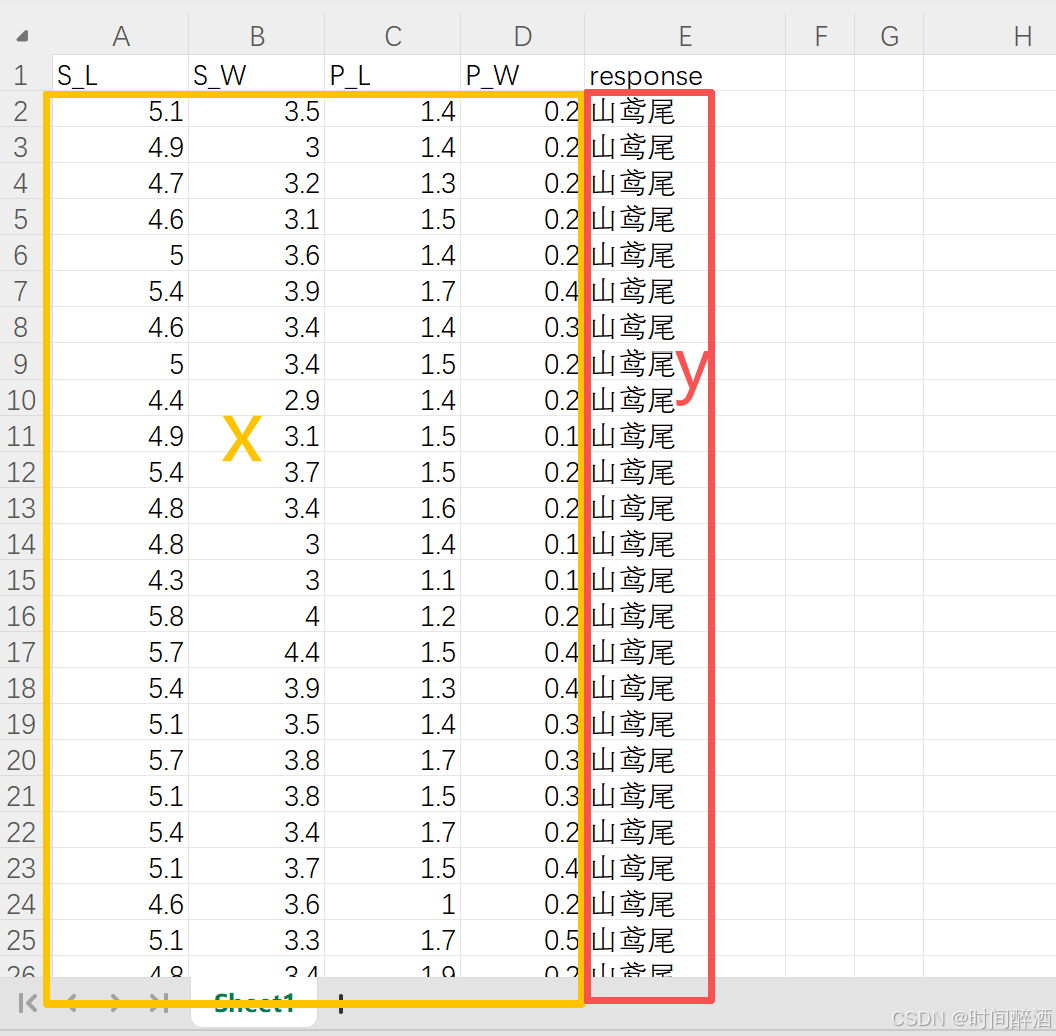
# 将类别标签转换为数值:
from sklearn.preprocessing import Label
le = LabelEncoder( )
(LabelEncoder 的作用是将分类的文本标签(如 '山鸢尾', '杂色鸢尾')转换为机器可以理解的数字格式(如 0, 1, 2)。)
y = le.fit_transform(y)
le.fit(y) :LabelEncoder会扫描 y 数组,找出所有唯一的类别标签,并学习它们之间的映射关系。 le.transform(y) :根据学习到的映射关系,将 y 数组中的每个文本标签替换为对应的数字。 fit_transform(y) 结合了上述两个步骤,一步完成学习和转换。 转换后的数值型 y 已经被重新赋值,供后续模型使用。
# 查看并打印编码映射:
list(le.classes_)
le.classes_ 是 LabelEncoder 在 fit 过程中学习到的所有唯一类别标签(按字母顺序排序)。这里将其转换为列表,方便查看。
dict(zip(le.classes_, le.transform(le.classes_)))
le.transform(le.classes_) : 将所有唯一的类别标签再次进行转换,得到它们对应的数字编码。 zip(le.classes_, le.transform(le.classes_)) : 将原始类别标签和它们的数字编码一 一配对。 dict(...): 将这些配对转换成一个字典,例如 `{'山鸢尾': 0, '杂色鸢尾': 1, '维吉尼亚鸢尾': 2}`。 ( 这段代码的作用是清晰地展示原始文本标签和它们被转换后的数字标签之间的对应关系。)
#划分训练集和测试集
from sklearn.model_selection import train_test_split : 导入用于划分数据集的函数。
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y) :
test_size=0.2 : 指定将 20% 的数据用作测试集,剩下的 80% 用作训练集。
random_state=42 : 这是一个种子值,用于确保每次运行代码时,数据集的划分都是相同的,这有助于复现实验结果。如果省略,每次划分都会不同。
stratify = y: 这是非常重要的一点。它表示在划分训练集和测试集时,保持原始 y 数组中各类别的比例分布。 (例如,如果原始数据中有 50% 的 '山鸢尾',那么训练集和测试集中的 '山鸢尾' 比例也应该大致是 50%。 这样做对于处理类别不平衡的数据集非常重要,可以确保模型的训练和评估在各个类别上都尽可能公平。)
# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)scaler = StandardScaler(): 创建一个标准化工具,准备好进行标准化的“算法”。
scaler.fit_transform(X_train):
学习 (fit) 训练集 X_train 的每个特征的均值和标准差。
应用 (transform) 学习到的均值和标准差,将 X_train 的数值标准化。
scaler.transform(X_test):
应用 (transform) 之前从 X_train 中学习到的相同的均值和标准差,将测试集 X_test 的数值标准化。
最终的效果:
X_train 和 X_test 中的所有数值都被缩放到一个共同的尺度(均值为 0,标准差为 1)。这样,在后续的机器学习模型训练和预测中,各个特征之间的数值差异就不会因为其原始的量级不同而造成不公平的影响,模型可以更有效地学习。
本文总结
在本篇文章中,我们以一个经典的鸢尾花分类数据集为例,完整地演示了构建一个机器学习预测模型的第一步和第二步:
-
数据加载与探索 (Data Loading & Exploration)
-
使用
pandas库读取 Excel 格式的数据集。 -
通过
.shape,.head(),.info(),.describe(),.value_counts()等方法快速了解数据集的全貌,包括数据规模、特征类型、缺失值、统计信息和类别分布。 -
关键发现:在探索过程中,我们敏锐地发现了数据中的异常行(
‘response‘被错误地当作了一个类别标签)和数据缺失问题。
-
-
数据预处理 (Data Preprocessing)
-
数据清洗 (Data Cleaning):果断地删除了包含异常值和缺失值的行,保证了数据质量。
-
特征与标签分离 (Feature/Target Split):使用
.iloc将数据明确划分为特征矩阵X和目标变量y。 -
标签编码 (Label Encoding):利用
LabelEncoder将文本形式的花卉种类标签(如‘山鸢尾’)转换为数值形式(如 0, 1, 2),这是模型能够处理的前提。 -
数据集划分 (Train-Test Split):使用
train_test_split方法将数据划分为训练集和测试集,并设置了stratify参数以确保训练集和测试集中各类别的比例一致,这对于获得可靠的模型评估结果至关重要。 -
特征标准化 (Feature Standardization):使用
StandardScaler对特征数据进行标准化处理,将不同尺度的特征缩放到同一标准正态分布下,从而大幅提升许多机器学习模型(如逻辑回归、SVM)的性能和训练速度。
-
至此,我们已经拥有了一个干净、规整、且经过预处理的训练集 (X_train, y_train) 和测试集 (X_test, y_test),为下一步的模型训练做好了万全准备。
下一步预告:数据准备就绪后,我们将进入下一个环节——数据可视化。在下一篇文章中,我们将:
-
使用预处理好的数据集进行可视化。
-
详细分析可视化图标所蕴含的信息
-
详细分析每一条代码的含义一步步敲出数据可视化
-
深入讲解并运用三种可视化图标来全面观察数据集,对比分析不同模型反映出什么样的数据信息。
敬请期待:逻辑回归(三):从原理到实战 - 训练、评估与应用指南 (链接将在文章发布后更新)
作者本人水平有限,非常欢迎任何反馈和指正,请随时指出我可能存在的误解、遗漏或表述不当之处。
我将继续深入学习机器学习和统计学领域,并持续更新我的理解和最佳实践。我愿意虚心接受反馈,不断打磨和完善我的内容,以便为读者提供更可靠、更有价值的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号