深度学习模型
SSD模型
SSD是一种单阶段检测模型,提出的目的是为了同时保证目标检测的速度和精度。

单阶段检测模型(region free):直接从图片预测结果。如SSD,YOLO
两阶段检测模型(2 stage, region based):图片局部裁剪,然后分类。如R-CNN Fast,R-CNN,Faster R-CNN
SSD使用VGG-16-Atrous作为基础网络,其中黄色部分为在VGG-16基础网络上填加的特征提取层。SSD与yolo不同之处是除了在最终特征图上做目标检测之外,还在之前选取的5个特特征图上进行预测。可以看出,检测过程不仅在填加特征图(conv8_2, conv9_2, conv_10_2, pool_11)上进行,为了保证网络对小目标有很好检测效果,检测过程也在基础网络特征图(conv4_3, conv_7)上进行。
SSD 方法的核心就是 predict object(物体),以及其归属类别的 score(得分);同时,在feature map上使用小的卷积核去 predict 一系列 bounding boxes 的 box offsets,为了得到高精度的检测结果,在不同层次的 feature maps 上去 predict object、box offsets,同时,还得到不同 aspect ratio 的 predictions。
相对于那些需要 object proposals 的检测模型,SSD 方法完全取消了 proposals generation、pixel resampling 或者 feature resampling 这些阶段,为了处理相同物体的不同尺寸的情况,SSD 结合了不同分辨率的 feature maps 的 predictions,SSD将输出一系列离散化(discretization) 的 bounding boxes,这些 bounding boxes是在不同层次(layers)上的feature maps上生成的,并且有着不同的 aspect ratio。需要计算出每一个 default box 中的物体其属于每个类别的可能性,即score,得分,如对于一个数据集,总共有20类,则需要得出每一个 bounding box中物体属于这20个类别的每一种的可能性,同时,要对这些 bounding boxes 的shape进行微调,以使得其符合物体的外接矩形。
先弄清楚 default map cell以及 feature box是什么:
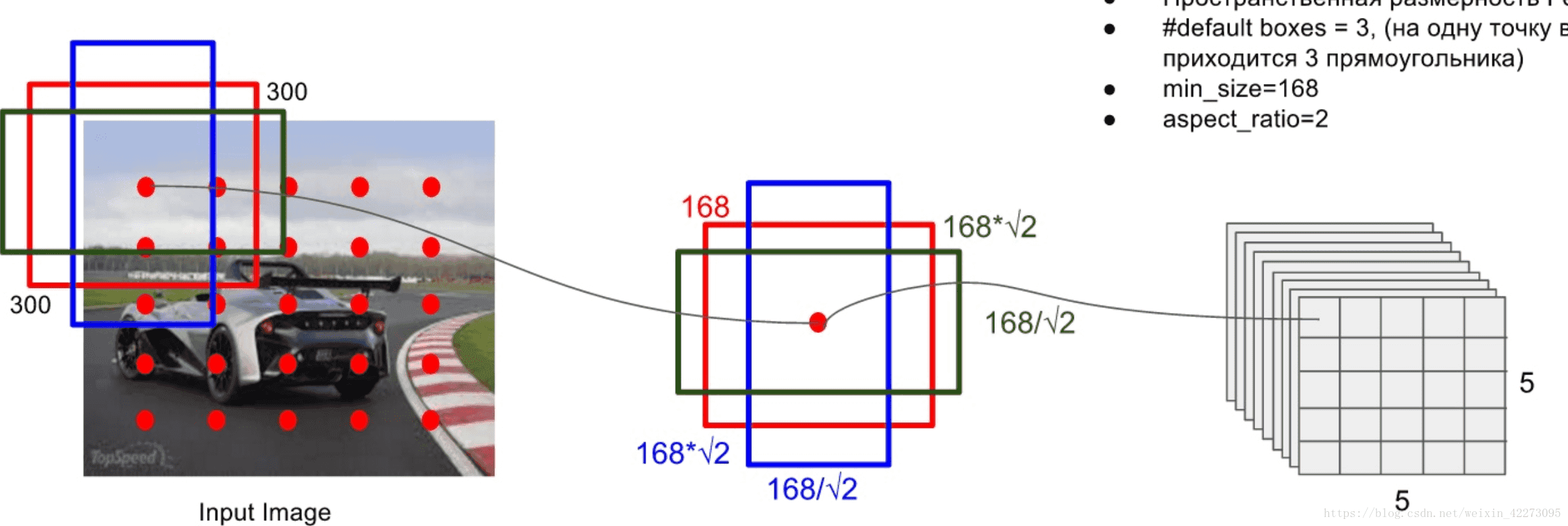
1、feature map cell就是将feature map切分成n*n的格子。
2、default box就是每一个格子上,生成一系列固定大小的 box,即图中虚线所形成的一系列 boxes。

3、和faster R-CNN相似,SSD也提出了anchor的概念。卷积输出的feature map,每个点对应为原图的一个区域的中心点,以这个点为中心,构造出6个宽高比例不同,大小不同的anchor(SSD中称为default box),每个anchor对应4个位置参数(x,y,w,h)和21个类别概率(voc训练集为20分类问题,在加上anchor是否为背景,共21分类)。
Training
在训练时,SSD与那些用region proposals + pooling方法的区别是,SSD训练图像中的 groundtruth 需要赋予到那些固定输出的 boxes 上,在前面也已经提到了,SSD输出的是事先定义好的,一系列固定大小的 bounding boxes。如下图中,狗狗的groundtruth是红色的bounding boxes,但进行label标注的时候,要将红色的groundtruth box赋予图(c)中一系列固定输出的 boxes 中的一个,即 图(c)中的红色虚线框。

像这样定义的groundtruth boxes不止在SSD中用到。在 YOLO中、 Faster R-CNN中的 region proposal阶段,以及在 MultiBox中都用到了,当这种将训练图像中的groundtruth与固定输出的boxes对应之后,就可以end-to-end的进行loss function的计算以及back-propagation的计算更新了。
损失函数
SSD训练的目标函数(training objective)源自于 MultiBox 的目标函数,但是又将其拓展,使其可以处理多个目标类别。总的目标损失函数(objective loss function)就由localization loss(loc)与 confidence loss(conf)的加权求和,其中:localization loss(loc)是 Fast R-CNN中 Smooth L1 Loss,用在 predict box,confidence loss(conf)是Softmax Loss,输入为每一类的置信度。SSD的损失函数由每个默认框的定位损失与分类损失构成(每个默认框的位置为(x, y, w, h)四个值):

训练中会遇到一些问题:
1、如何将 groundtruth boxes 与 default boxes 进行配对,以组成 label 呢?
在开始的时候,用MultiBox中的best jaccard overlap 来匹配每一个ground truth box与default box,这样就能保证每一个groundtruth box与唯一的一个default box 对应起来。但是又不同于 MultiBox ,SSD后面又将default box与任何的 groundtruth box配对,只要两者之间的jaccard overlap 大于一个阈值,这里的阈值一般设置为0.5。
2、多尺寸feature map上进行目标检测
每一个卷积层,都会输出不同大小感受野的feature map。在这些不同尺度的feature map上,进行目标位置和类别的训练和预测,从而达到多尺度检测的目的,可以克服yolo对于宽高比不常见的物体,识别准确率较低的问题。在yolo v1中,只在最后一个卷积层上做目标位置和类别的训练和预测,这是SSD相对于yolo能提高准确率的一个关键所在。SSD在每个卷积层上都会进行目标检测和分类,最后由NMS进行筛选,输出最终的结果。多尺度feature map上做目标检测,就相当于多了很多宽高比例的bounding box,可以大大提高泛化能力。

3、Choosing scales and aspect ratios for default boxes
大部分 CNN 网络在越深的层,feature map的尺寸(size)会越来越小。这样做不仅仅是为了减少计算与内存的需求,还有个好处就是,最后提取的 feature map 就会有某种程度上的平移与尺度不变性。同时为了处理不同尺度的物体,一些文章将图像转换成不同的尺度,将这些图像独立的通过CNN网络处理,再将这些不同尺度的图像结果进行综合,但是其实,如果使用同一个网络中的、不同层上的feature maps,也可以达到相同的效果,同时在所有物体尺度中共享参数,可以用 CNN前面的layers来提高图像分割的效果,因为越底层的layers保留的图像细节越多。因此,SSD同时使用lower feature maps、upper feature maps 来predict detections,上图展示了SSD中使用的两种不同尺度的feature map。
一般来说,一个CNN网络中不同的layers有着不同尺寸的感受野(receptive fields)。这里的感受野指的是输出的feature map上的一个节点,其对应输入图像上尺寸的大小。所幸的是,SSD结构中default boxes不必要与每一层layer的 receptive fields 对应,而是采用feature map中特定的位置来负责图像中特定的区域以及物体特定的尺寸,设置每一个default box的中心结合在feature maps上,所有不同尺度、不同aspect ratios的default boxes在进行预测 predictions 之后,我们得到许多个predictions,包含了物体的不同尺寸、形状。
4、Hard negative mining
训练集给定了输入图像以及每个物体的真实区域(ground true box),将default box和真实box最接近的选为正样本,然后在剩下的default box中选择任意一个与真实box IOU大于0.5的,作为正样本,而其他的则作为负样本。在生成一系列的predictions之后,会产生很多个符合ground truth box的predictions boxes,但同时,不符合ground truth boxes也很多,而且negative boxes远多于 positive boxes,这会造成negative boxes、positive boxes之间的不均衡,训练时难以收敛,因此,SSD先将每一个物体位置上对应 predictions(default boxes)是negative的boxes进行排序,按照default boxes的confidence的大小选择最高的几个出来,SSD将正负样本比例定位为1:3,这样可以更快的优化,训练也更稳定。
5、既想利用已经训练好的模型进行fine-tuning,又想改变网络结构得到更加 dense的score map。
这个解决办法就是采用 Hole 算法。如下图 (a) (b) 所示,在以往的卷积或者 pooling中,一个filter中相邻的权重作用在feature map上的位置都是物理上连续的。如下图 (c) 所示,为了保证感受野不发生变化,某一层的 stride 由 2 变为 1 以后,后面的层需要采用 hole 算法,具体来讲就是将连续的连接关系是根据 hole size 大小变成 skip 连接的(图 (c) 为了显示方便直接画在本层上了)。不要被(c)中的padding为2吓着了,其实2个 padding不会同时和一个 filter 相连。pool4的stride由2变为1,则紧接着的conv5_1、conv5_2 和 conv5_3中hole size 为2。接着pool5由2变为1 ,则后面的fc6中 hole size 为4。

6、SSD使用的VGG-16作为基础网络,VGG-16虽然精度与darknet-19相当,但运算速度慢。

Result
SSD模型对bounding box的size非常的敏感。也就是说,SSD对小物体目标较为敏感,在检测小物体目标上表现较差。其实这也算情理之中,因为对于小目标而言,经过多层卷积之后,就没剩多少信息了。虽然提高输入图像的size可以提高对小目标的检测效果,但是对于小目标检测问题,还是有很多提升空间的,同时,积极的看,SSD 对大目标检测效果非常好,SSD对小目标检测效果不好,但也比YOLO要好。另外,因为SSD使用了不同aspect ratios的default boxes,SSD 对于不同aspect ratios的物体检测效果也很好,使用更多的 default boxes,结果也越好。Atrous使得SSD又好又快 ,通常卷积过程中为了使特征图尺寸保持不变,都会在边缘打padding,但人为加入的padding值会引入噪声,而使用atrous卷积能够在保持感受野不变的条件下,减少padding噪声,SSD训练过程中并没有使用atrous卷积,但预训练过程使用的模型为VGG-16-atrous,意味着作者给的预训练模型是使用atrous卷积训练出来的。使用atrous版本VGG-16作为预训模型比较普通VGG-16要提高0.7%mAP。
因为 COCO 数据集中的检测目标更小,我们在所有的layers上,使用更小的default boxes。SSD一开始会生成大量的bounding boxes,所以有必要用 Non-maximum suppression(NMS)来去除大量重复的 boxes。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号