数据结构(C语言实现)
# 数据结构(c语言)---郝斌
资料
| 课程相关 | 拓展 |
|---|---|
| 课程视频链接 | vs code配置c语言环境 |
| [官方配套源代码链接](D:\研一\Code\数据结构\1. 郝斌笔记\郝斌数据结构源代码【官方】) | vs code解决中文编码问题 |
| 笔记1(博客园) | |
| [笔记2(pdf)](D:\研一\Code\数据结构\1. 郝斌笔记\郝斌数据结构笔记.docx) | |
| 笔记3(gitee) |

概述
-
数据结构的定义
我们如何把现实中大量而复杂的问题以特定的数据类型和特定的存储结构保存到主存储器(内存)中,以及在此基础上为实现某个功能(比如查找某个元素,删除某个元素,对元素进行排序等)而执行的相应操作,这个相应的操作也叫算法。
数据结构 = 个体的存储 + 个体关系的存储
算法 = 对存储数据的操作
-
算法定义
- 通俗的说,算法是解题的方法和步骤
- 衡量算法的标准
- 时间复杂度:程序大概要执行的次数,而非执行时间
- 空间复杂度:程序执行过程中大概所占用的最大内存空间
- 难易程度:易懂,避免过于复杂
- 健壮性
-
数据结构的地位
软件中最核心的课程
程序=数据的存储+数据的操作+可以被计算机执行的语言
预备知识
1.指针
-
定义
- 地址:内存单元的编号,从0开始的非负整数
- 指针就是地址,地址就是指针
- 指针变量是存放内存单元地址的变量
- 本质是一个操作受限的非负整数
-
分类
- 基本类型的指针
- 指针和数组的关系
-
注意
- 指针变量也是变量,只不过它不能存放内存单元的内容,只能存放内存单元的地址
- 普通变量前不能加*
- 常量和表达式前不能加&(需记住)
-
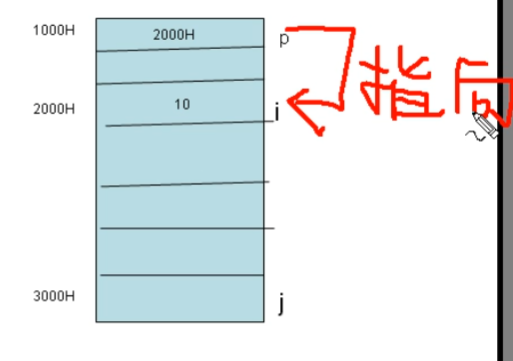
EXAMPLE:指针变量p的定义与使用
int i=10; int *p=&i; //等价于 int *p; p=&i;- p存放了i的地址,所以我们说p指向了i
- p和i是完全不同的两个变量,修改其中的任意一个变量的值不会影响另一个
- **p指向i,*p就是i变量本身。即
*p <==> i**
# include <stdio.h> int main(void) { int *p; //p是个变量名字,int *p表示该p变量只能存储int类型变量的地址 int i=10; int j; //j=*p; //printf("%d\n",j); //error,不知道p指向谁,此时p为野指针(*p为不确定单元) p = &i; //p保存i的地址==>p指向i,修改一个值(p)不影响另一个值(i),*p代表i j=*p; //等价于j=i printf("i=%d,j=%d,*p=%d\n",i,j,*p); //10,10,10 //p=10 //error return 0; }![image-20220321224445797]()
-
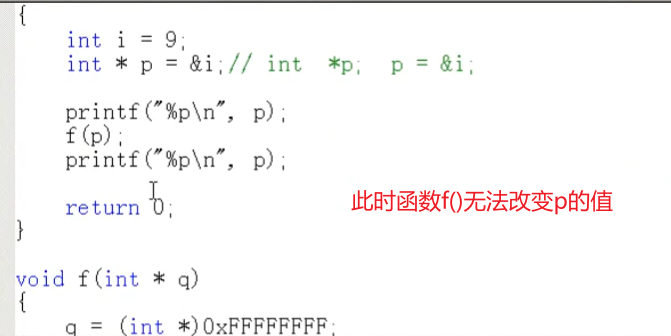
EXAMPLE:如何通过被调函数修改主调函数中普通变量的值?
- 实参为相关变量的地址
- 形参为以该变量的类型为类型的指针变量
- 在被调函数中通过
*形参变量名的方式修改主调函数

-
所有的指针变量在64位系统中只占8个字节,用第一个字节的地址表示整个变量
64位系统:64根地址总线,可以确定264个内存单元,每根线一位,8位一个字节,64/8=8,故一个指针变量占8个字节。(内存单元最小单元为byte形式,232个内存单元为4G)

代码结果:000000000061fe00
000000000061fe08
-
EXAMPLE:如何通过函数修改实参的值。。。。。。。。。。。。???。。。。。。。。。。。。。。
ps:只是方便理解,该程序不安全

2.指针和数组
-
数组名
- 一维数组名是个指针常量,存放的是一维数组第一个元素的地址,其值不能被改编
- 一维数组名指向的是数组的第一个元素
-
下标和指针的关系
a[i] 等价于 *(a+i) 等价于 i[a]a 等价于 &a[0], &a[0]本身就是int *类型假设指针变量的名字为p,则p+i的值是p+i*(p所指向的变量所占的字节数)
-
指针变量的运算
- 指针变量不能相加、相乘、相除
- 如果两指针变量属于同一数组,则可以相减
- 指针变量可以加减一整数,前提是最终结果不能超过指针...?
p+i的值是p+i*(p所指向的变量所占的字节数)
p-i的值是p-i*(p所指向的变量所占的字节数)
p++ <==> p+1
p-- <==> p-1
-
EXAMPLE:如何通过被调函数修改主调函数中一维数组的内容?
- 两个参数
- 存放数组首元素的指针变量
- 存放数组元素长度的整型变量
- 两个参数

3.结构体
-
为什么会出现结构体
- 为表示一些复杂的数据,而普通的基本类型变量无法满足要求
-
定义
- 结构体使用户根据实际需要自己定义的复合数据类型
- 与java的类不同,结构体只有属性(成员)没有方法
-
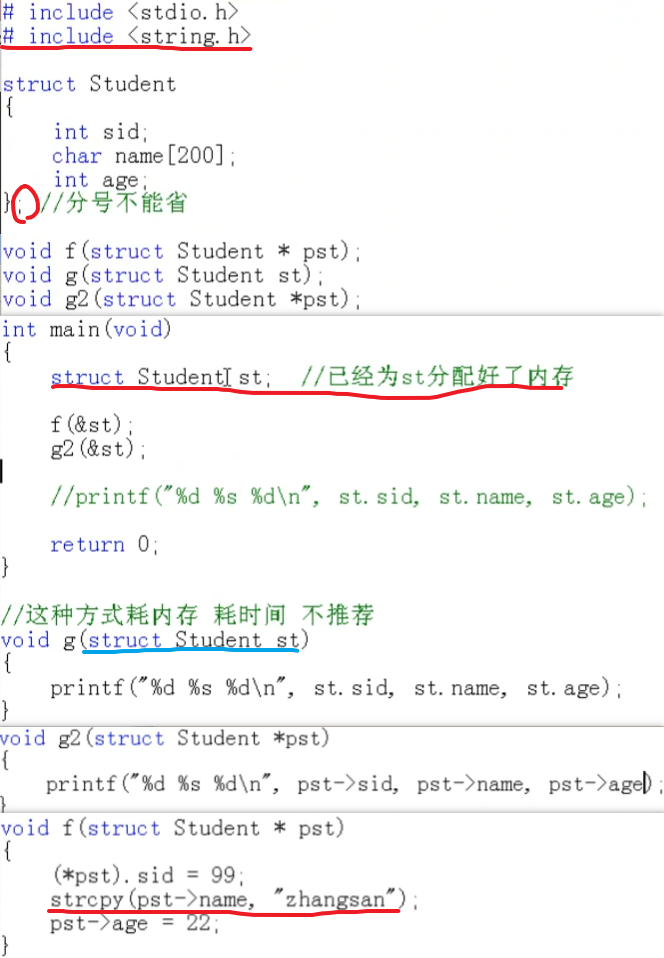
如何使用结构体
struct Student st = {1000,"zhangsan",20}; struct Student * pst = &st; 方式1 st.sid 方式2(更常用) pst->sid //pst->sid 等价于 (*pst).sid 等价于 st.sid pst所指向的结构体变量中的sid这个成员![image-20220323000432782]()
-
方式一:整体赋值,类似于Java中new类的构造函数
![image-20220323000924799]()
-
方式二:通常使用指针的方式赋值
![image-20220323001241402]()
-
-
注意事项
- 结构体变量不能加减乘除,但可以相互赋值
- 普通结构体变量和结构体指针变量作为函数传参的问题



4.动态内存的分配和释放
-
动态构造一维数组
假设动态构造一个int型数组
int *p = (int *)malloc(int len);-
malloc只有一个int型的形参len,表示要求系统分配的字节数
-
malloc函数的功能是请求系统len个字节的内存空间;
如果请求分配成功,则返回第一个字节的地址;
如果分配不成功,则返回NULL;
-
malloc函数能且只能返回第一个字节的地址,所以我们需要把这个无实际意义的第一个字节的地址(俗称干地址)转化为一个有实际意义的地址
malloc前面必须加
(数据类型 *),表示把这个无实际意义的第一个字节的地址转化为相应类型的地址,如:
int *p = (int *)malloc(50);- 表示将系统分配好的50个字节的第一个字节的地址转化为int *型的地址,更准确地说是把第一个字节的地址转化为四个字节的地址。
- 这样p就指向了第一个的四个字节,p+1指向了第2个的四个字节,p+i就指向了第i+1个的四个字节。
- p[0]就是第一个元素,p[i]就是第i+1个元素
静态数组:不需要使用malloc()的数组
动态数组:需要使用malloc()的数组
干地址为什么无意义?
答malloc函数只返回第一个字节地址(干地址/无意义地址),4字节int类型变量用第一个字节地址,8个字节的double类型变量也用第一个字节地址表示,因此仅凭该地址无法确定该变量占多少字节,
-


🔺跨函数使用内存,通过动态内存实现
-
example 1
![image-20220323111213716]()
考查了:
1)指针的指针的使用 2) 动态内存分配与自动变量的内存分配。
动态分配的内存必须调用free()函数才能释放,而自动变量一旦跳出它的代码作用范围,就会由编译器自动释放掉。A) 选项无论fun()中p的值如何变化,都不会影响到主函数中p的值,因为它是值传递
B) 选项倒是把p的地址&p传递给了fun()函数,但遗憾的是,由于s是个自动变量,当推出fun()函数后,s变量所占内存单元会被会被释放掉,此时主函数中的p还是没法指向一个合法的int型单元
C) 选项fun()的形参 int **p;表明p是个指向指针变量的指针变量,即是个指针的指针。 而主函数中的 int *p; 表明p只是个指针变量,但&p则指向了p,&p也是个指向指针变量p的指针变量,实参和形参类型一致。 fun()的功能是使实参p指向了一个int型变量, 又由于该int型变量是由malloc()动态分配的,所以推出fun()函数并不会影响实参p的指向, 故C是对
D) 选项犯了和A同样的错误。 -
example 2
# include <stdio.h> # include <malloc.h> struct Student { int sid; int age; }; struct Student * CreateStudent(void); void ShowStudent(struct Student *); int main(void) { struct Student * ps; ps = CreateStudent(); //函数中使用了动态内存 ShowStudent(ps); return 0; } void ShowStudent(struct Student * pst) { printf("%d %d\n", pst->sid, pst->age); } struct Student * CreateStudent(void) { struct Student * p = (struct Student *)malloc(sizeof(struct Student)); //重要 p->sid = 99; p->age = 88; return p; }

线性结构
把所有的结点用一条直线串起来
连续存储【数组】
-
什么是数组:元素类型相同,大小相等
-
优缺点
- 优点:存取速度很快
- 缺点:
- 插入、删除元素的效率很低
- 事先必须知道数组长度
- 空间通常有限制
- 需要大块连续的内存块
-
🔺数组算法
//数组例程 #include <stdio.h> #include <malloc.h> //malloc()函数 #include <stdlib.h> //exit()函数 struct Arr { int len;//数组长度 int cnt;//当前数组内已有元素长度 int *pbase;//数组首地址 }; // 1.初始化条件 // 2.各参数含义 // 3.函数功能 //初始化数组 void init_arr(struct Arr *, int); //打印数组内所有元素 void show_arr(struct Arr *); //判断数组是否为空 bool is_empty(struct Arr *); //判断数组是否已经满了 bool is_full(struct Arr *); //向数组中追加元素 bool append_arr(struct Arr *, int); //向数组某个位置插入元素 bool insert_arr(struct Arr *, int pos, int); // pos值从1开始 //删除数组某个位置元素 bool delete_arr(struct Arr *, int pos, int *); //倒置 void inversion_arr(struct Arr * ); //排序 void sort_arr(struct Arr * ); int main(void) { struct Arr arr; int val; init_arr(&arr, 6); // printf("%d\n", arr.len); // show_arr(&arr); append_arr(&arr, 7); append_arr(&arr, 5); append_arr(&arr, 3); show_arr(&arr); insert_arr(&arr, 2, 0); show_arr(&arr); // if (delete_arr(&arr, 1, &val)) // { // printf("删除成功,删除的元素为:%d\n", val); // } // else // { // printf("删除失败\n"); // } inversion_arr(&arr); show_arr(&arr); sort_arr(&arr); show_arr(&arr); return 0; } void init_arr(struct Arr *parr, int length) { (*parr).pbase = (int *)malloc(sizeof(int) * length); //指针变量parr所指向的结构体变量中的pBse这个成员 if (NULL == parr->pbase) { printf("动态内存失败"); exit(-1); //终止整个程序 } else { parr->len = length; parr->cnt = 0; } return; //告知别人函数终止 } bool is_empty(struct Arr *parr) { if (0 == parr->cnt) return true; else return false; } void show_arr(struct Arr *parr) { if (is_empty(parr)) // parr是否需要&??? { printf("数组为空"); } else { for (int i = 0; i < parr->cnt; ++i) { printf("%d", parr->pbase[i]); //🔺应为int *类型;parr是结构体名字,struct Arr * 类型 } printf("\n"); } } bool is_full(struct Arr *parr) { if (parr->cnt == parr->len) return true; else return false; } bool append_arr(struct Arr *parr, int val) { //满时返回false if (is_full(parr)) return false; //不满时追加 else parr->pbase[parr->cnt] = val; parr->cnt++; return true; } bool insert_arr(struct Arr *parr, int pos, int val) { int i; if (is_full(parr)) return false; if (pos < 1 || pos > parr->cnt + 1) return false; for (i = parr->cnt - 1; i >= pos - 1; --i) { parr->pbase[i + 1] = parr->pbase[i]; } parr->pbase[pos - 1] = val; parr->cnt++; return true; } bool delete_arr(struct Arr *parr, int pos, int *pval) { if (is_empty(parr)) return false; if (pos < 1 || pos > parr->cnt) return false; *pval = parr->pbase[pos - 1]; //🔺 int i; for (i = pos; i < parr->cnt; i++) { parr->pbase[i - 1] = parr->pbase[i]; } parr->cnt--; return true; } void inversion_arr(struct Arr * parr) { int i=0; int j=parr->cnt-1; int t; while(i<j) { t=parr->pbase[i]; parr->pbase[i]=parr->pbase[j]; parr->pbase[j]=t; ++i; --j; } return; } void sort_arr(struct Arr * parr) { int i,j,t; //选择排序 for(i=0;i<parr->cnt;++i) { for(j=i+1;j<parr->cnt;++j) { if(parr->pbase[i]>parr->pbase[j]) { t=parr->pbase[i]; parr->pbase[i]=parr->pbase[j]; parr->pbase[j]=t; } } } return; }
离散结构【链表】
-
typedef用法
#include <stdio.h> typedef int ZHANG; //为int多取一个名字,ZHANG等价于int typedef struct Student { int sid; char name[100]; char sex; }STU,* PSTU; // PSTU等价于struct Student *;STU等价于struct Student; int main(void) { STU st; PSTU ps = &st; ps->sid = 99; printf("%d\n", ps->sid); return 0; } -
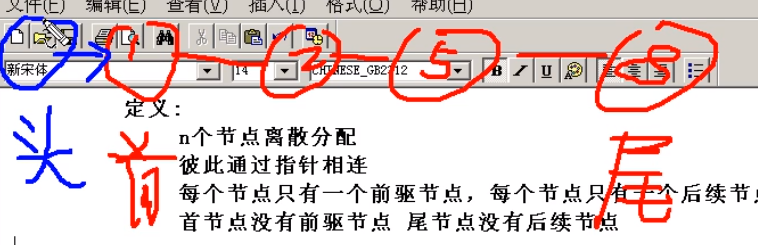
定义
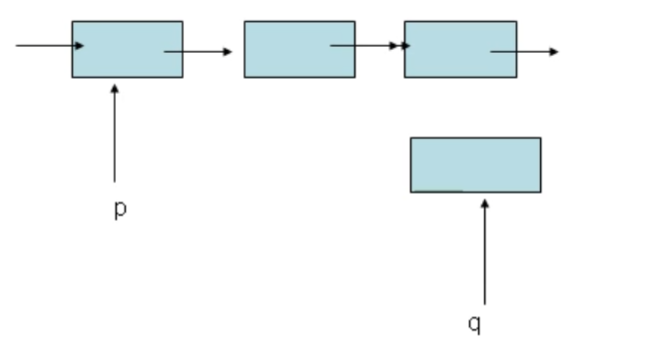
- n个节点离散分配,彼此通过指针相连,
- 每个节点只有一个前驱节点同时每个节点只有一个后续节点,
- 首节点没有前驱节点,尾节点没有后续节点
专业术语
- 首节点:存放第一个有效数据的节点
- 尾节点:存放最后一个有效数据的节点
- 头结点:
- 位于首节点之前的一个节点,(头节点的数据类型与首节点类型一样)
- 头结点并不存放有效的数据,
- 加头结点的目的主要是为了方便对链表的操作
- 头指针:指向头结点的指针变量(通过头指针可以推算出链表的所有信息)
- 尾指针:指向尾节点的指针变量(NULL)
![image-20220326213712534]()
-
若希望通过一个函数对链表进行处理,至少需要接受链表的哪些参数?
- 只需要一个参数:头指针
- 通过头指针可以推算出链表的所有信息
-
分类
- 单链表:每个节点的指针域指向后面的节点
- 双链表:每一个节点有两个指针域
- 循环链表:能通过任何一个节点找到其它所有的节点
- 非循环链表
-
🔺链表算法(p26 p28)
-
预备知识
![image-20220328102335035]()
-
插入节点
![image-20220328101254155]()
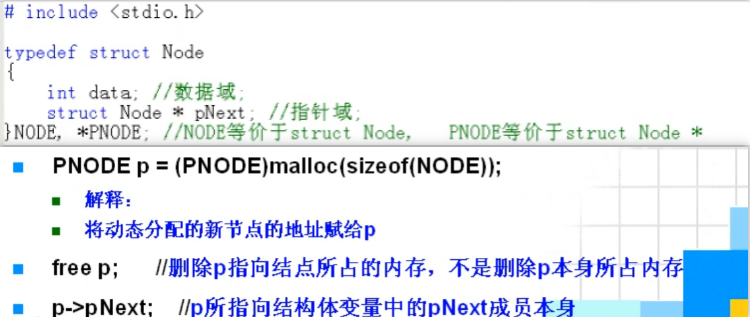
r = p->pNext; p->pNext = q; q->pNext = r; //方式一 //p,q为指针变量,存放节点地址 //p->pNext:指针变量p所指向的结构体变量中的pNext这个成员,指向和它本身数据类型一样的下一个节点 q->pNext = p->pNext; p->pNext = q; //方式二 -
删除节点
r = p->pNext; p->pNext = p->pNext->pNext; free(r); //避免内存泄漏 //c++ free==>delete -
创建、遍历、是否为空、求长度、插入、删除、排序
//链表例程 # include <stdio.h> # include <malloc.h> # include <stdlib.h> typedef struct Node { int data; //数据域 struct Node * pNext; //指针域 }NODE, *PNODE; //NODE等价于struct Node PNODE等价于struct Node * //函数声明 PNODE create_list(void); //创建链表 void traverse_list(PNODE pHead); //遍历链表 bool is_empty(PNODE pHead); //判断链表是否为空 int length_list(PNODE); //求链表长度 bool insert_list(PNODE pHead, int pos, int val); //在pHead所指向链表的第pos个节点的前面插入一个新的结点,该节点的值是val, 并且pos的值是从1开始 bool delete_list(PNODE pHead, int pos, int * pVal); //删除链表第pos个节点,并将删除的结点的值存入pVal所指向的变量中, 并且pos的值是从1开始 void sort_list(PNODE); //对链表进行排序 int main(void) { PNODE pHead = NULL; //等价于 struct Node * pHead = NULL; int val; pHead = create_list(); //create_list()功能:创建一个非循环单链表,并将该链表的头结点的地址付给pHead traverse_list(pHead); //insert_list(pHead, -4, 33); if ( delete_list(pHead, 4, &val) ) { printf("删除成功,您删除的元素是: %d\n", val); } else { printf("删除失败!您删除的元素不存在!\n"); } traverse_list(pHead); //int len = length_list(pHead); //printf("链表的长度是%d\n", len); //sort_list(pHead); //traverse_list(pHead); /* if ( is_empty(pHead) ) printf("链表为空!\n"); else printf("链表不空!\n"); */ return 0; } PNODE create_list(void) { int len; //用来存放有效节点的个数 int i; int val; //用来临时存放用户输入的结点的值 //分配了一个不存放有效数据的头结点 PNODE pHead = (PNODE)malloc(sizeof(NODE)); if (NULL == pHead) { printf("分配失败, 程序终止!\n"); exit(-1); } PNODE pTail = pHead; pTail->pNext = NULL; printf("请输入您需要生成的链表节点的个数: len = "); scanf("%d", &len); for (i=0; i<len; ++i) { printf("请输入第%d个节点的值: ", i+1); scanf("%d", &val); PNODE pNew = (PNODE)malloc(sizeof(NODE)); if (NULL == pNew) { printf("分配失败, 程序终止!\n"); exit(-1); } pNew->data = val; pTail->pNext = pNew; pNew->pNext = NULL; pTail = pNew; } return pHead; } void traverse_list(PNODE pHead) { PNODE p = pHead->pNext; while (NULL != p) { printf("%d ", p->data); p = p->pNext; } printf("\n"); return; } bool is_empty(PNODE pHead) { if (NULL == pHead->pNext) return true; else return false; } int length_list(PNODE pHead) { PNODE p = pHead->pNext; int len = 0; while (NULL != p) { ++len; p = p->pNext; } return len; } void sort_list(PNODE pHead) { int i, j, t; int len = length_list(pHead); PNODE p, q; for (i=0,p=pHead->pNext; i<len-1; ++i,p=p->pNext) { for (j=i+1,q=p->pNext; j<len; ++j,q=q->pNext) { if (p->data > q->data) //类似于数组中的: a[i] > a[j] { t = p->data;//类似于数组中的: t = a[i]; p->data = q->data; //类似于数组中的: a[i] = a[j]; q->data = t; //类似于数组中的: a[j] = t; } } } return; } //在pHead所指向链表的第pos个节点的前面插入一个新的结点,该节点的值是val, 并且pos的值是从1开始 bool insert_list(PNODE pHead, int pos, int val) { int i = 0; PNODE p = pHead; while (NULL!=p && i<pos-1) { p = p->pNext; ++i; } if (i>pos-1 || NULL==p) return false; //如果程序能执行到这一行说明p已经指向了第pos-1个结点,但第pos-1个节点是否存在无所谓 //分配新的结点 PNODE pNew = (PNODE)malloc(sizeof(NODE)); if (NULL == pNew) { printf("动态分配内存失败!\n"); exit(-1); } pNew->data = val; //将新的结点存入p节点的后面 PNODE q = p->pNext; p->pNext = pNew; pNew->pNext = q; return true; } bool delete_list(PNODE pHead, int pos, int * pVal) { int i = 0; PNODE p = pHead; while (NULL!=p->pNext && i<pos-1) { p = p->pNext; ++i; } if (i>pos-1 || NULL==p->pNext) return false; //如果程序能执行到这一行说明p已经指向了第pos-1个结点,并且第pos个节点是存在的 PNODE q = p->pNext; //q指向待删除的结点 *pVal = q->data; //删除p节点后面的结点 p->pNext = p->pNext->pNext; //释放q所指向的节点所占的内存 free(q); q = NULL; return true; }
-
-
优缺点
- 优点:空间没有限制;插入删除元素很快
- 缺点:存取速度很慢
-
算法
-
狭义的算法是与数据的存储方式密切相关
-
广义的算法是与数据的存储方式无关
-
泛型:利用某种技术达到的效果就是:不同的存储方式,执行的操作是一样的
-
重载:赋予一个事物不同的含义
- 函数重载;
- 运算符重载
-
看不懂正常,多看答案多动手,实在不行背过
-
看算法三个步骤:
- 流程
- 每个语句的功能
- 试数
-
线性结构的应用--栈Stack
c语言中,静态内存在栈中分配;动态内存在堆中分配,需要手动释放

-
定义
-
一种可以实现“先进后出”的存储结构
-
栈类似于箱子
-
-
分类
- 静态栈
- 动态栈:内核是链表
-
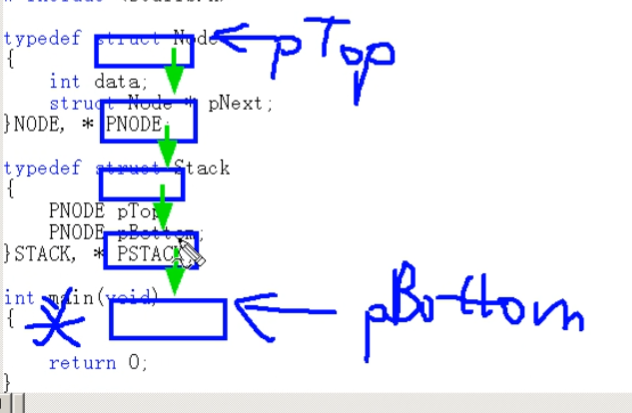
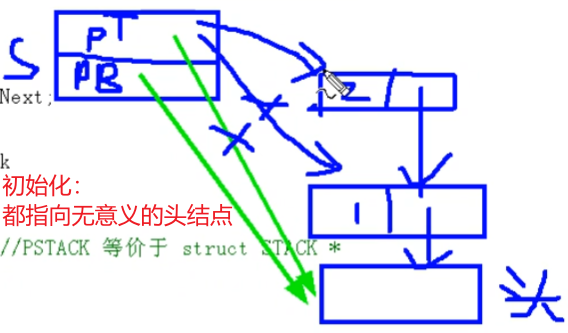
🔺算法(P33)
- 出栈
- 压栈
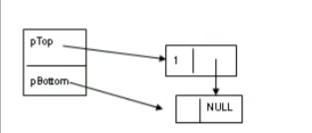
#include <stdio.h> #include <malloc.h> #include < typedef struct Node{ int data; strct Node * pNext; }NODE,*PNODE; typedef struct Stack{ PNODE pTop; //永远指向栈顶元素 PNODE pBottom; //永远指向栈底元素下一个没有实际含义的元素 }STACK,*PSTACK; void init(PSTACK); int main(void){ STACK S; init(&S); push(&S,1); //不能指定插入位置,只能放在栈顶位置 traverse(&S); } void init(PSTACK S){ } -
应用
链式栈不存在满或者不满的问题

线性结构的应用--队列Queue
-
定义
- 一种可以实现“先进先出”的存储结构
-
分类
- 链式队列--用链表实现,对链表进行一部分限制变成队列
- 静态队列--用数组实现,通常都必须是循环队列
-
循环队列
-
静态队列为什么必须是循环队列
入队、出队front和rear都需增加,前面的元素不可能用一次就舍弃
-
循环队列需要几个参数来确定
2个参数,front,rear
-
循环队列各个参数的含义
不同场合有不同含义
-
队列初始化
front和rear的值都是0
-
队列非空
front:队列第一个元素
rear:队列最后一个有效元素的下一个元素
-
队列空
front和rear的值相等,但不一定是0
-
-
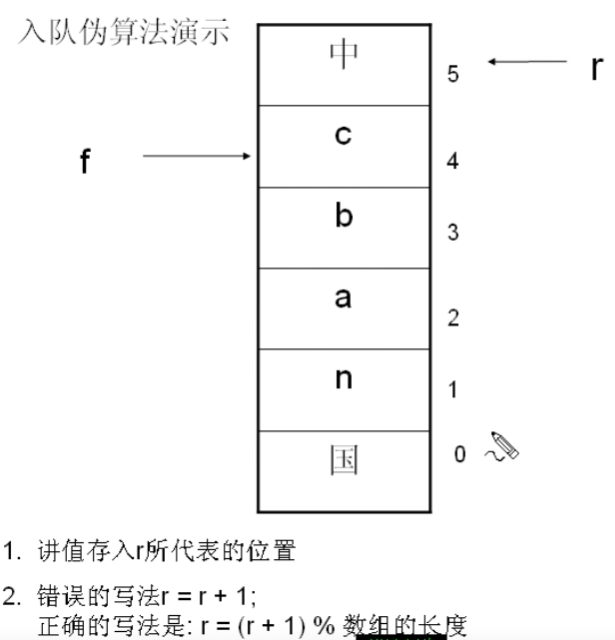
循环队列入队伪算法讲解
![image-20220402165529437]()
-
循环队列出队伪算法讲解
f=(f+1)%数组长度
-
如何判断循环队列是否为空
front和rear的值相等,队列一定为空
-
如何判断循环队列是否已满
预备知识:
front的值可能比rear大、小或者相等
两种方式:
-
多增加一个表标识参数
-
少用一个元素,两个元素即可判断是否已满(常用)
如果f和r的值紧挨着,则队列已满
if ((r+1)%数组长度==f) 已满else 不满
-
-
-
🔺队列算法(P47)
-
队列具体应用
所有和时间有关的操作都有队列的影子
递归
-
一个函数为什么能够调用自己?
![image-20220403120048767]()
-
定义:一个函数自己直接或间接调用自己
-
递归要满足的三个条件
- 递归必须得有一个明确的中止条件
- 递归的值可以递增,但是该函数所处理的数据规模必须在递减
- 这个转化必须是可解的(数学意义)
-
循环和递归的关系
- 循环==>递归
递归:
- 易于理解
- 速度慢(调用)
- 存储空间大(调用)
循环:
- 不易理解
- 速度快
- 存储空间小
-
举例:
-
求阶乘
#include <stdio.h>//1.阶乘的循环实现方式// int main(void)// {// int val;// int i,mult=1;// printf("请输入一个数字:\n");// printf("val=");// scanf("%d",&val);// for(i=1;i<=val;++i)// {// mult = mult*i;// }// printf("%d的阶乘为%d:\n",val,mult);// return 0;// }//2.阶乘的递归实现方式//假定n的值是1或大于1的值long f(long n){ if (1 == n) return 1; else return f(n - 1) * n;}int main(void){ printf("%d\n", f(1)); return 0;} -
1+2+3+......+100的和
# include <stdio.h>long sum(long n){ if(1==n) return n; else return n + sum(n - 1);}int main(void){ printf("%ld\n", sum(100)); return 0;} -
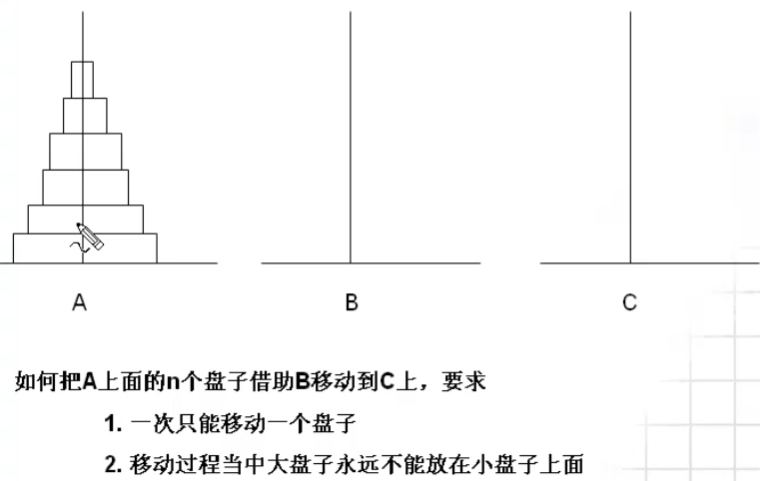
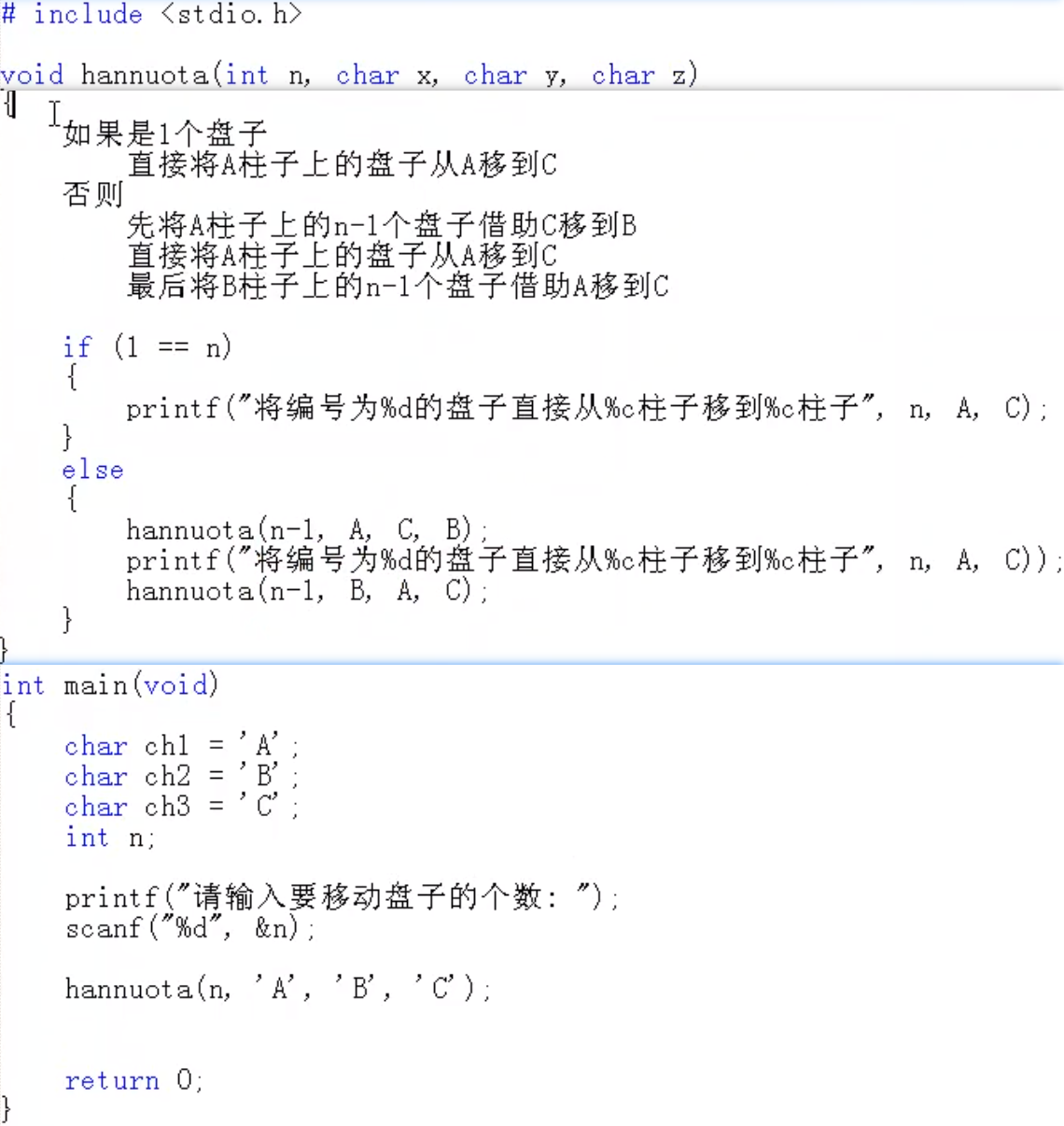
🔺汉诺塔
![image-20220404194423957]()
![image-20220404200102801]()
![image-20220404202102456]()
![image-20220404202723706]()
-
走迷宫
稍复杂
-
-
递归的应用
树和森林就是以递归的方式定义的
树和图的很多算法就是以递归来实现的
很多数学公式就是以递归的方式定义的:斐波那契序列 1 2 3 5。。。



总结
-
逻辑结构(大脑中存储数据的方式,与计算机无关)
-
线性结构:用一根线穿起来;算法已成熟
- 数组
- 链表
关系:线性结构的物理存储方式是数组和链表,栈和队列是线性结的一种特殊表现形式或者是一种具体应用(栈和队列都可以用链表实现,用数组实现更复杂)
Java中ArrayList和LinkedList分别是数组和链表实现的集合/线性表???
-
非线性结构:算法不成熟
一般还没有用非线性结构为核心的工具,有应用但还不广泛
Java中treeset,set为容器,无序不允许重复,内部以树排序方式,但本质上不是一个树,只是运用到树的一部分知识
-
-
物理结构(如何将大脑中的东西保存到计算机里)
-
数据结构的难点
将生活中复杂多维的问题存储到线性一维的内存中
非线性结构
树
必考内容:先序遍历、已知两种遍历将整个树确定出来
● 树的定义
-
专业定义
- 有且只有一个成为根的节点
- 有 若干个互不相交的子树,这些子树本身也是一棵树
-
通俗定义
- 树是由节点和边组成
- 每个节点只有一个父节点但是有多个子节点
- 但有一个节点除例外,该节点没有父节点,此节点称为根节点
-
专业术语
节点 父节点 子节点
子孙 堂兄弟
深度:从根节点到最低层节点的层数(根节点是第一层)
叶子节点:没有子节点的节点
非终端节点:实际就是非叶子节点
度:(最大)子节点的个数
● 树的分类
-
一般树
任意一个节点的子节点的个数不受限制
-
二叉树
任意一个节点的子节点的个数最多两个,且子节点的位置不可更改(有序树)
▪分类:
-
一般二叉树
-
满二叉树(只是过渡的概念)
在不增加树的层数前提下,无法再多添加一个节点的二叉树就是满二叉树
-
完全二叉树
如果只是删除了满二叉树最底层最右边的连续若干个节点,这样形成的二叉树就是完全二叉树
➡解决数据存储问题,用数组存储必须用完全二叉树形式
-
-
森林
n个互不相交的树的集合
● 树的存储
一般树、森林一般都是转化为二叉树进行存储
-
二叉树的存储
-
连续存储[完全二叉树]
把一般的二叉树以数组方式存储,需先将其转化为完全二叉树
![image-20220405131425219]()
非线性==>线性结构:先序、中序、后序
优点/为什么必须转化为完全二叉树:
- 仅保留有效节点的话,无法根据一种线性结构(先中后)推断出原来的非线性结构
- 优点1:结点的个数可以推出树的层数
- 优点2:查找某个节点的父节点和子节点速度很快,包括判断有没有子节点(时间复杂度为0)
缺点:
- 耗用内存空间过大
-
链式存储
耗用内存小,2指针域,1数据域
-
-
一般树的存储
-
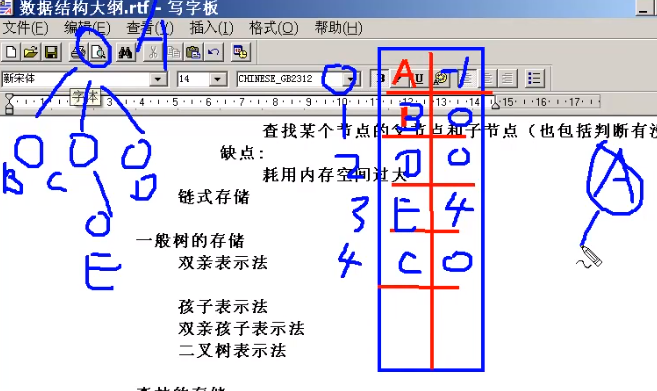
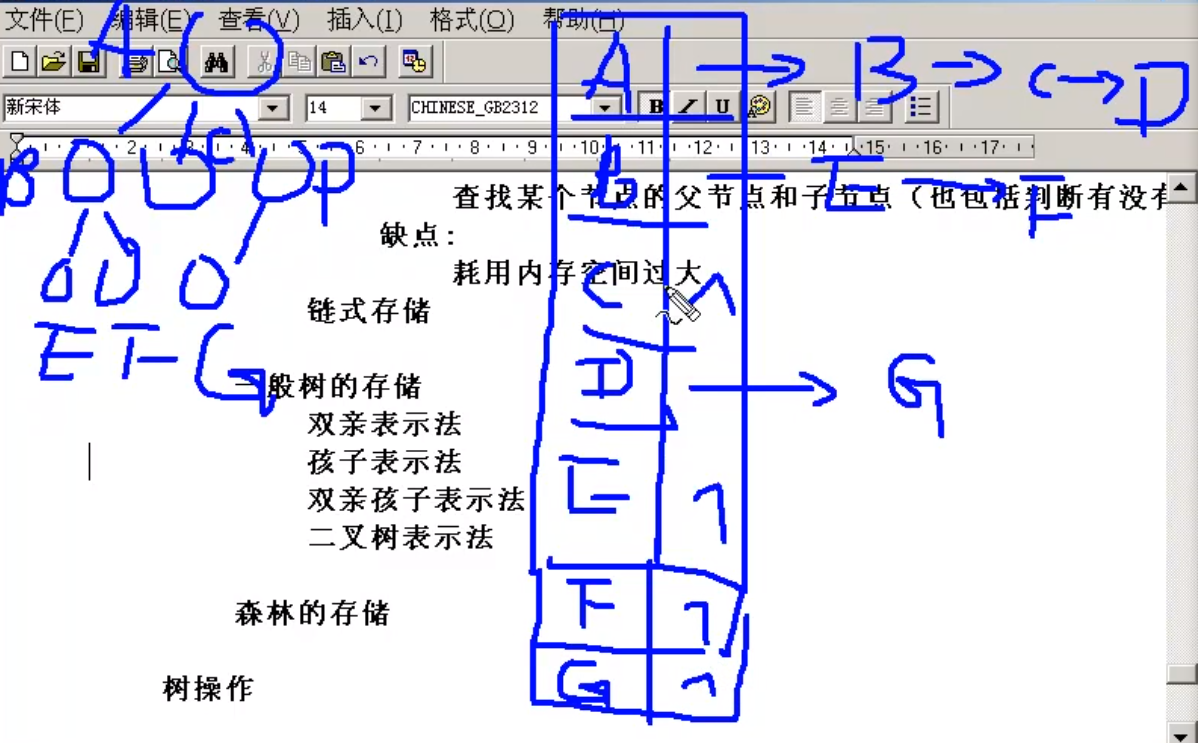
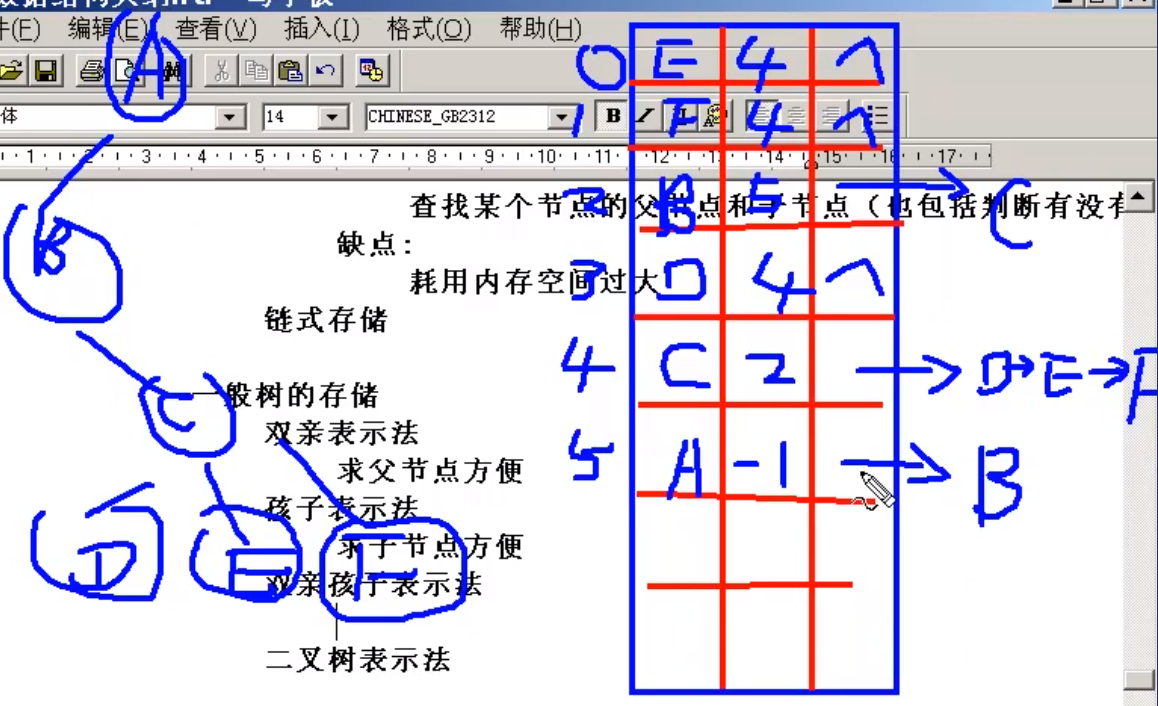
双亲表示法
求父节点方便
![image-20220405135812710]()
-
孩子表示法
求子节点方便
![image-20220405134317459]()
-
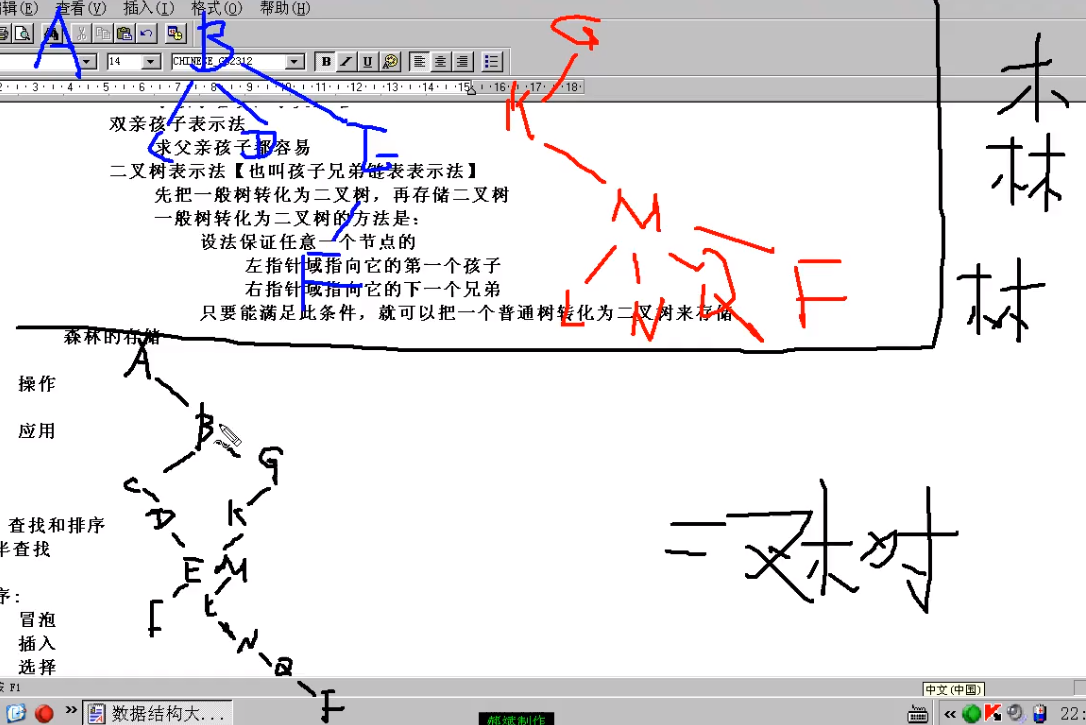
双亲孩子表示法
求父节点和子节点都很方便
![image-20220405134719502]()
-
二叉树表示法
普通树转化成二叉树来存储:
- 设法保证任意一节点的左指针域指向它的第一个孩子,右指针域指向它的下一个兄弟,只要满足此条件,即可转换
- 普通树转化成的二叉树一定没有右子树
-
-
森林的存储
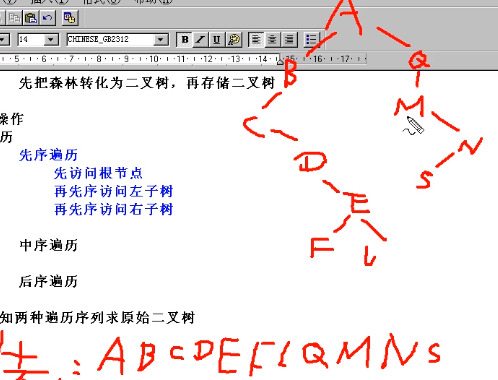
先把森林转化为二叉树,再存储二叉树
![image-20220405140455369]()

● 二叉树操作
-
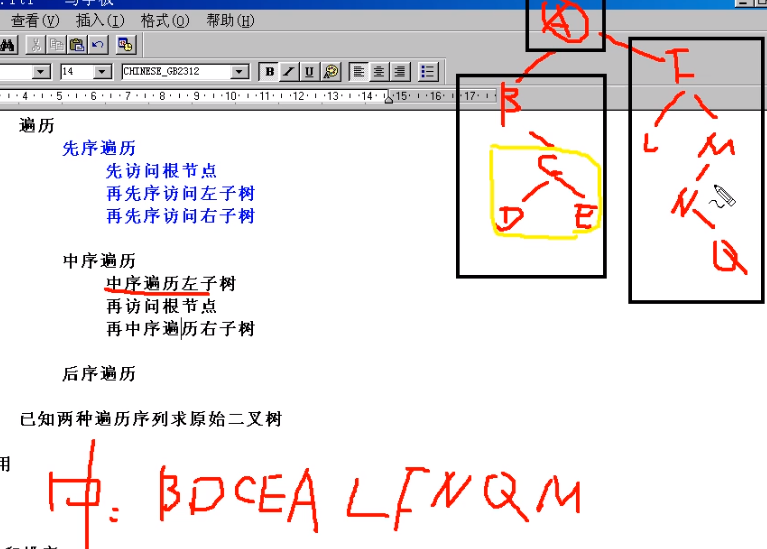
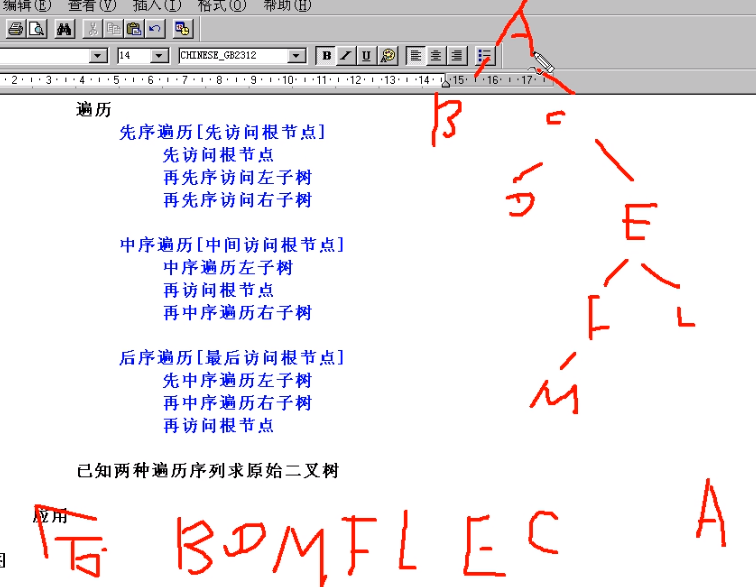
先序遍历(非线性转化为线性序列)[先访问根节点]
先访问根节点,
再先序访问左子树,
再先序访问右子树
![image-20220405171925043]()
![image-20220405171943566]()
-
中序遍历[中间访问根节点]
中序遍历左子树,
再访问根节点,
再中序遍历右子树
![image-20220405165840272]()
![image-20220405170111029]()
-
后序遍历[最后访问根节点]
后序遍历左子树
后序遍历右子树
再访问根节点
![image-20220405171215696]()
![image-20220405171722489]()
-
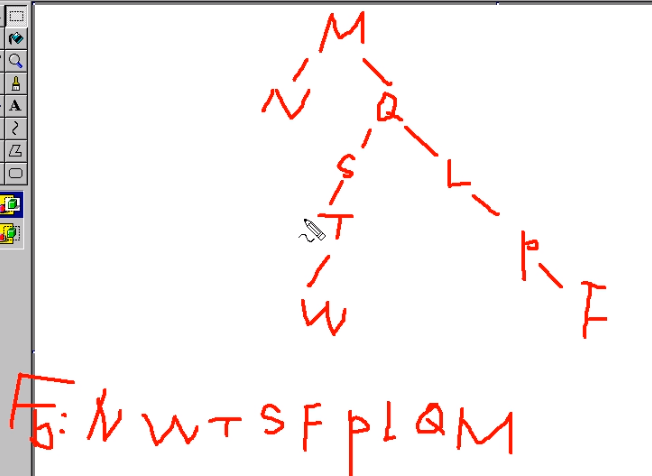
已知两种遍历序列求原始二叉树



 浙公网安备 33010602011771号
浙公网安备 33010602011771号