
安兔兔数据可视化分析
一、选题背景
安兔兔评测是一款专业级跑分软件,支持Vulkan、UFS3.0等最新技术,可以让您清楚了解手机的真实性能。安兔兔验机应用,则可以检验手机的真伪,获取硬件参数。安兔兔关注业界热点,实时为您更新手机资讯。这些数据让买手机的小白和发烧友有了一个具体的了解,来作为参考。
二、网络爬虫设计方案
名称:安兔兔安卓数据爬虫
内容与数据分析特征:该爬虫主要获取性能榜的数据进行分析。
设计方案:通过request进行请求,使用随机头作为反爬机制。使用etree获取数据,最后使用sys进行数 据保存。技术难点在于获取的数据类型不是text、tostring类型。用bs4里的find难以获取。所以采用etree。以及批量获取数据的算法也是得经过思考才最终批量出来。
三、页面机构与特征分析
主题结构特征:
从布局来看,网页时一个内容导航型。
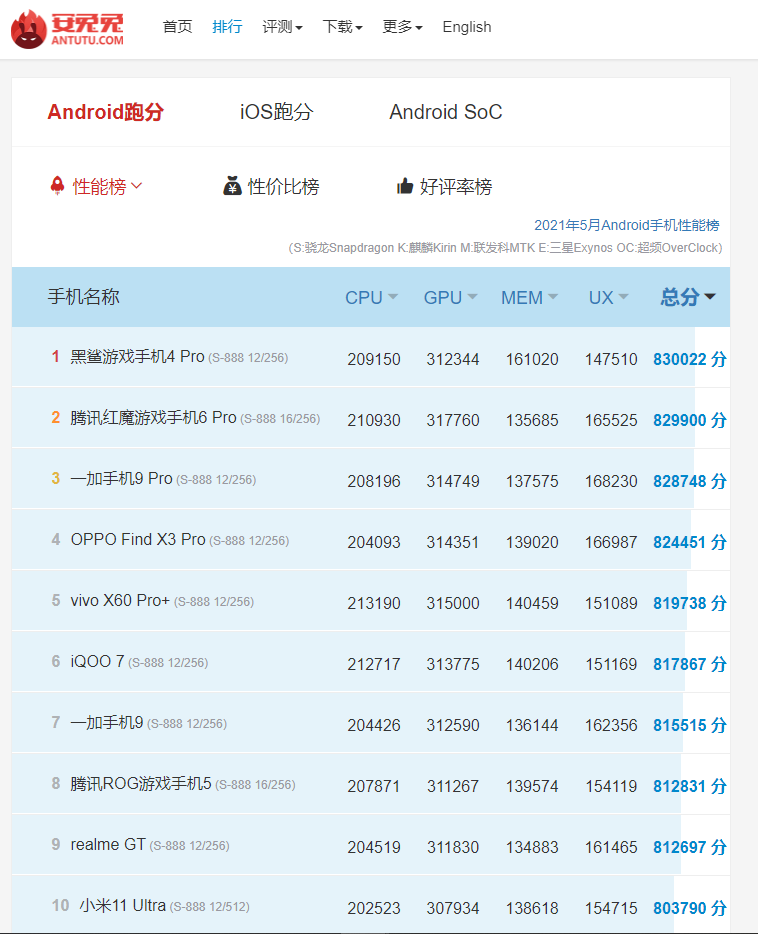
Htmls页面解析:
手机名称:
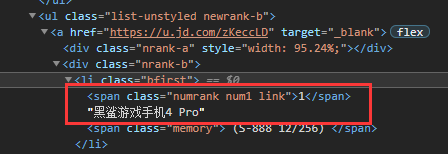
cpu、gpu、mem、ux:
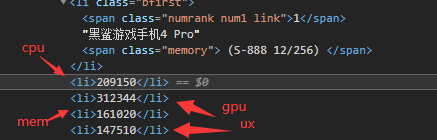
总分:
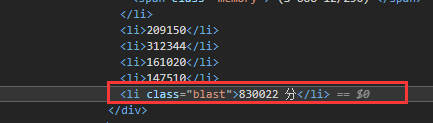
节点查找与遍历方法:
查找方法:
通过:
etree.xpath()
进行查找。
代码:
按顺序依次:手机名称name、手机cpu分数phone_cpu、手机gpu分数phone_gpu、Mem分数phone_me、UX分数phone_ux、总分phone_sum //*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[1]/text() //*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[2]/text() //*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text() //*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text() //*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text() //*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text()
遍历方法:
a = 3 phone_mem_coun = 4 phone_ux_coun = 5 phone_sum_coun = 6 phone_gpu_coun = 3 # 分析手机排行榜信息:手机名称name、手机cpu分数phone_cpu、手机gpu分数phone_gpu、Mem分数phone_me、UX分数phone_ux、总分phone_sum for i in range(3,127): name = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[1]/text()".format(a)) phone_cpu = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[2]/text()".format(a)) phone_gpu = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text()".format(a,phone_gpu_coun)) phone_mem = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text()".format(a,phone_mem_coun)) phone_ux = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text()".format(a,phone_ux_coun)) phone_sum = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text()".format(a,phone_sum_coun)) a += 1
四、爬虫程序设计
1 import requests 2 from bs4 import BeautifulSoup 3 import time 4 import random 5 import sys 6 import re 7 from tqdm import tqdm 8 from lxml import etree 9 10 # 随机头 11 USER_AGENTS = [ 12 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", 13 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", 14 "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", 15 "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", 16 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", 17 "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", 18 "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", 19 "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", 20 "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", 21 "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", 22 "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", 23 "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", 24 "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", 25 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", 26 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", 27 "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", 28 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11", 29 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER", 30 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)", 31 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)", 32 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER", 33 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", 34 "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", 35 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11", 36 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER", 37 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)", 38 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)", 39 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER" 40 ] 41 headers = { 42 'User-Agent':random.choice(USER_AGENTS), 43 # 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0', 44 'Connection':'keep-alive', 45 'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2' 46 } 47 48 url = 'http://www.antutu.com/ranking/rank1.htm' 49 50 file = open("Phone_pop.csv", "a") 51 file.write("name" + "," + "phone_cpu" + "," + "phone_gpu" + "," + "phone_mem" + "," + "phone_ux" + "," + "phone_sum" + '\n') 52 file = file.close() 53 54 def Antutu(): 55 ress = requests.get(url,headers=headers) 56 ress.encoding = 'utf-8' 57 # soup = BeautifulSoup(ress.text,'lxml') 58 html = etree.HTML(ress.text) 59 # print(html) 60 # 初始化查询数据 61 a = 3 62 phone_mem_coun = 4 63 phone_ux_coun = 5 64 phone_sum_coun = 6 65 phone_gpu_coun = 3 66 # 分析手机排行榜信息:手机名称name、手机cpu分数phone_cpu、手机gpu分数phone_gpu、Mem分数phone_me、UX分数phone_ux、总分phone_sum 67 for i in range(3,127): 68 name = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[1]/text()".format(a)) 69 phone_cpu = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[2]/text()".format(a)) 70 phone_gpu = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text()".format(a,phone_gpu_coun)) 71 phone_mem = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text()".format(a,phone_mem_coun)) 72 phone_ux = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text()".format(a,phone_ux_coun)) 73 phone_sum = html.xpath("//*[@id='rank']/div[1]/div/div/div[1]/div/div[1]/div/ul[{}]/a/div[2]/li[{}]/text()".format(a,phone_sum_coun)) 74 a += 1 75 sum = name + phone_cpu + phone_gpu + phone_mem + phone_ux + phone_sum 76 print(sum) 77 # 保存数据至Phone_pop.csv 78 for j in sum: 79 # print(j) 80 with open('Phone_pop.csv',"a",encoding='utf-8') as file1: 81 file1.writelines(sum[0] + "," + sum[1] + "," + sum[2] + "," + sum[3] + "," + sum[4] + "," + sum[5] +'\n') 82 83 if __name__ == '__main__': 84 Antutu()
运行:
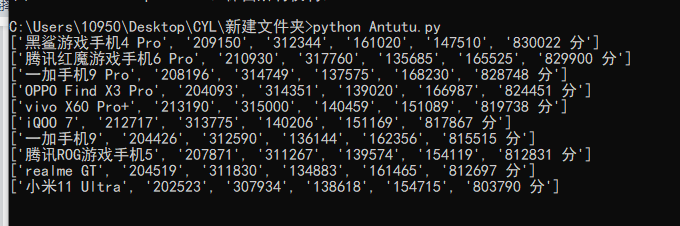
输出结果:

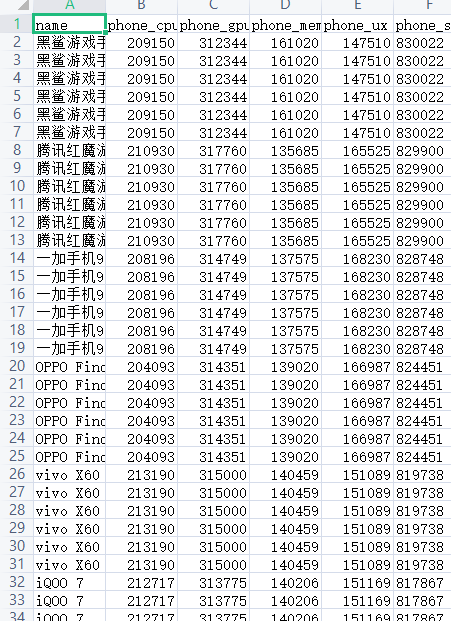
数据清洗处理:
import pandas as pd import numpy as np #导入数据 phone = pd.read_csv(r'C:\Users\CDW\Desktop\CYL\Phone_pop.csv',encoding='gbk') phone.head(20)
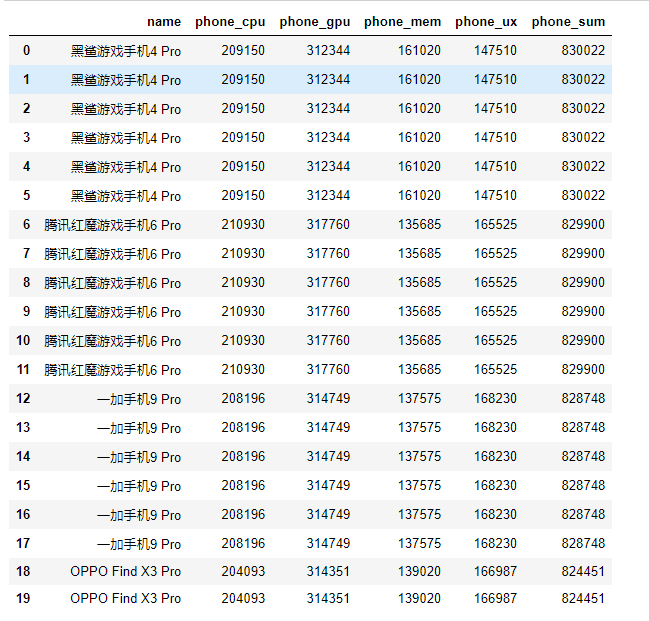
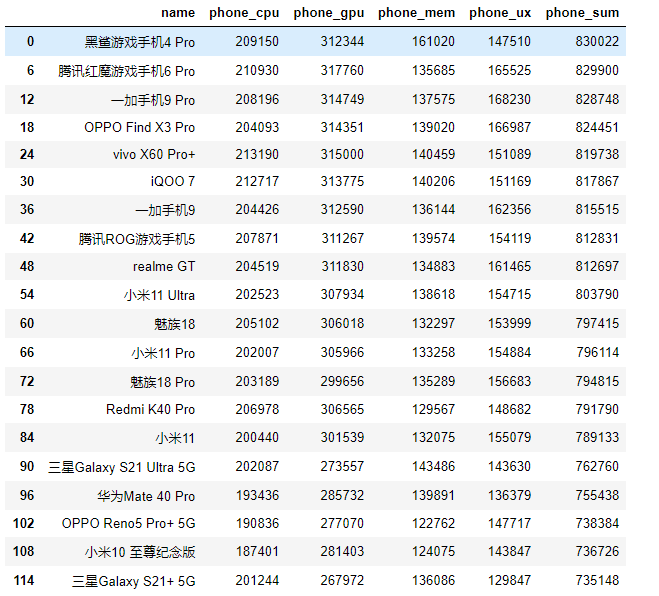
清洗:
由于爬虫保存时的机制想不出来怎么才没有重复值,所以在循环的时候重新做了几次工作。
# 由于爬虫保存数据算法的原因出现5次重复值等会做处理 # pc_name重复值处理 phone = phone.drop_duplicates() phone.head(20)
可视化分析:
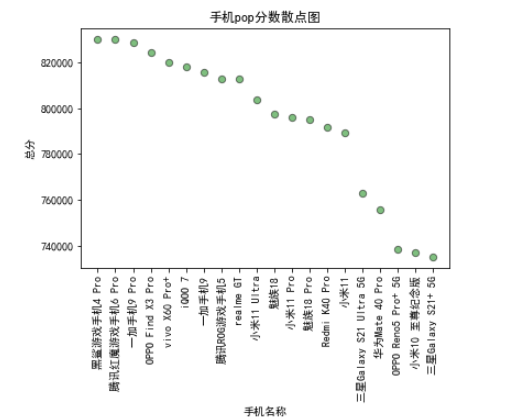
import matplotlib.pyplot as plt # top数据可视化分析 x = phone['name'].head(20) y = phone['phone_sum'].head(20) z = phone['phone_ux'].head(20) w = phone['phone_mem'].head(20) q = phone['phone_cpu'].head(20) e = phone['phone_gpu'].head(20) plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.plot(x,y,'s-',color = 'r',label="总分")#s-:方形 plt.plot(x,z,'-',color = 'c',label="ux") plt.plot(x,w,'-',color = 'k',label="mem") plt.plot(x,q,'-',color = 'b',label="cpu") plt.plot(x,e,'-',color = 'y',label="cpu") # plt.plot(x,y) plt.xticks(rotation=90) plt.legend(loc = "best")#图例 plt.title("pop综合趋势图") plt.xlabel("手机",)#横坐标名字 plt.ylabel("总分")#纵坐标名字 plt.show()
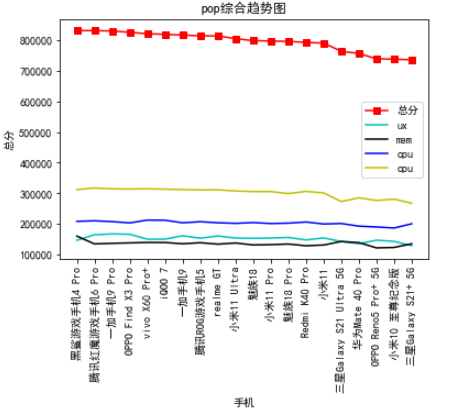
# 柱状图 plt.bar(x,y,alpha=0.2, width=0.4, color='yellow', edgecolor='red',label='Sum_coun', lw=3) plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.title("pop总分柱状图") plt.xticks(rotation=90) plt.xlabel("手机",)#横坐标名字 plt.ylabel("总分")#纵坐标名字 plt.show()
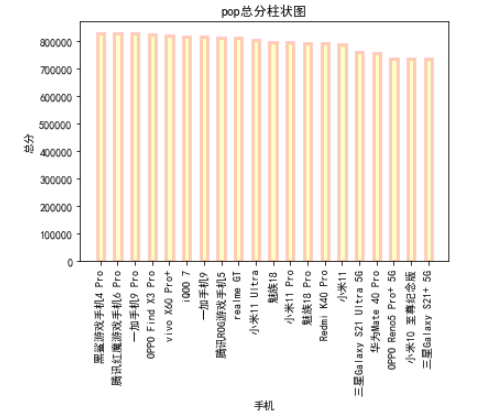
# 水平图 plt.barh(x,y, alpha=0.2, height=0.4, color='white', edgecolor='gray',label='Sum_coun', lw=3) plt.title("手机pop分数水平图") plt.legend(loc = "best")#图例 plt.xlabel("总分",) plt.ylabel("手机") plt.show()
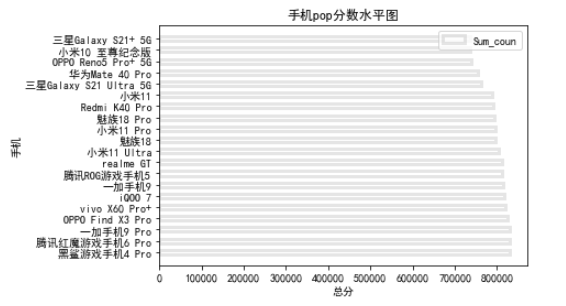
# 散点图 plt.scatter(x,y,color='green',marker='o',s=40,edgecolor='black',alpha=0.5) plt.xticks(rotation=90) plt.title("手机pop分数散点图") plt.xlabel("手机名称")#横坐标名字 plt.ylabel("总分")#纵坐标名字 plt.show()
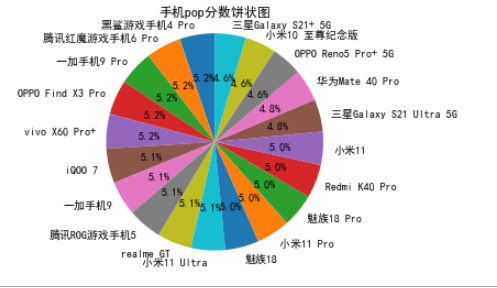
# pop总分分饼状图 label_list = x explode = (0,0,0,0.1,0,0) plt.rcParams['font.sans-serif']=['SimHei'] plt.xticks(rotation=0) plt.pie(y,labels=label_list,labeldistance=1.1, autopct="%1.1f%%", shadow=False, startangle=90, pctdistance=0.6) plt.title("手机pop分数饼状图") plt.axis("equal") plt.show()
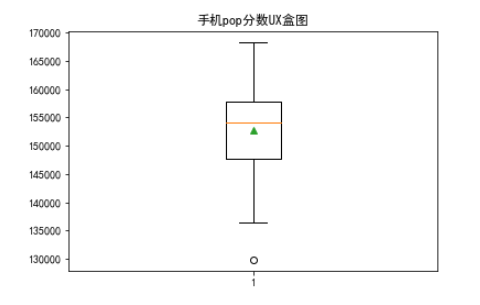
# pop_UX分盒图 plt.boxplot(z, # 值 vert=True, # true:纵向,false:横向 showmeans=True) # 显示均值 plt.title("手机pop分数UX盒图") plt.show()
词云:
1 import pandas as pd 2 import numpy as np 3 import wordcloud as wc 4 import matplotlib.pyplot as plt 5 6 phone = pd.read_csv(r'C:\Users\CYL\Desktop\CYL\Phone_pop.csv',encoding='gbk') 7 phone = phone.drop_duplicates() 8 9 # 词云 10 word_cloud = wc.WordCloud(font_path='msyh.ttc') 11 text = phone['name'] 12 phone = [] 13 for i in text: 14 phone.append(i) 15 text = " ".join(phone) 16 word_cloud.generate(text) 17 plt.imshow(word_cloud) 18 plt.show()

总代码:
1 import pandas as pd 2 import numpy as np 3 4 phone = pd.read_csv(r'C:\Users\CDW\Desktop\CYL\Phone_pop.csv',encoding='gbk') 5 phone.head(20) 6 7 # 由于爬虫保存数据算法的原因出现5次重复值等会做处理 8 # pc_name重复值处理 9 phone = phone.drop_duplicates() 10 phone.head(20) 11 12 import matplotlib.pyplot as plt 13 # top数据可视化分析 14 x = phone['name'].head(20) 15 y = phone['phone_sum'].head(20) 16 z = phone['phone_ux'].head(20) 17 w = phone['phone_mem'].head(20) 18 q = phone['phone_cpu'].head(20) 19 e = phone['phone_gpu'].head(20) 20 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 21 plt.plot(x,y,'s-',color = 'r',label="总分")#s-:方形 22 plt.plot(x,z,'-',color = 'c',label="ux") 23 plt.plot(x,w,'-',color = 'k',label="mem") 24 plt.plot(x,q,'-',color = 'b',label="cpu") 25 plt.plot(x,e,'-',color = 'y',label="cpu") 26 27 # plt.plot(x,y) 28 plt.xticks(rotation=90) 29 plt.legend(loc = "best")#图例 30 plt.title("pop综合趋势图") 31 plt.xlabel("手机",)#横坐标名字 32 plt.ylabel("总分")#纵坐标名字 33 plt.show() 34 35 # 柱状图 36 plt.bar(x,y,alpha=0.2, width=0.4, color='yellow', edgecolor='red',label='Sum_coun', lw=3) 37 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 38 plt.title("pop总分柱状图") 39 plt.xticks(rotation=90) 40 plt.xlabel("手机",)#横坐标名字 41 plt.ylabel("总分")#纵坐标名字 42 plt.show() 43 44 # 水平图 45 plt.barh(x,y, alpha=0.2, height=0.4, color='white', edgecolor='gray',label='Sum_coun', lw=3) 46 plt.title("手机pop分数水平图") 47 plt.legend(loc = "best")#图例 48 plt.xlabel("总分",) 49 plt.ylabel("手机") 50 plt.show() 51 52 # 散点图 53 plt.scatter(x,y,color='green',marker='o',s=40,edgecolor='black',alpha=0.5) 54 plt.xticks(rotation=90) 55 plt.title("手机pop分数散点图") 56 plt.xlabel("手机名称")#横坐标名字 57 plt.ylabel("总分")#纵坐标名字 58 plt.show() 59 60 # pop总分分饼状图 61 label_list = x 62 explode = (0,0,0,0.1,0,0) 63 plt.rcParams['font.sans-serif']=['SimHei'] 64 plt.xticks(rotation=0) 65 plt.pie(y,labels=label_list,labeldistance=1.1, autopct="%1.1f%%", shadow=False, startangle=90, pctdistance=0.6) 66 plt.title("手机pop分数饼状图") 67 plt.axis("equal") 68 plt.show() 69 70 # pop_UX分盒图 71 plt.boxplot(z, # 值 72 vert=True, # true:纵向,false:横向 73 showmeans=True) # 显示均值 74 plt.title("手机pop分数UX盒图") 75 plt.show()
import pandas as pd
import numpy as np
import wordcloud as wc
import matplotlib.pyplot as plt
phone = pd.read_csv(r'C:\Users\CYL\Desktop\CYL\Phone_pop.csv',encoding='gbk')
phone = phone.drop_duplicates()
# 词云
word_cloud = wc.WordCloud(font_path='msyhl.ttc')
text = phone['name']
phone = []
for i in text:
phone.append(i)
text = " ".join(phone)
word_cloud.generate(text)
plt.imshow(word_cloud)
plt.show()
五、总结
经过数据分析可以看出来,各个家的最新旗舰机的总分水平相差不算太大。UX的均值在大多数处于15w5左右。数据分期达到预期,对于给小白或者发烧友有一定的参考价值。此次设计过程中,可能有些小遗憾的时爬虫保存数据的时候存在重复保存,暂时找不到解决方案。此次课程完结使我对爬虫及数据可视化的认知加深,受益匪浅。对于不足的地方一定要找到解决方案,不然有些可惜!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号