
Python学习—数据库篇之SQL补充
一、SQL注入问题
在使用pymysql进行信息查询时,推荐使用传参的方式,禁止使用字符串拼接方式,因为字符串拼接往往会带来sql注入的问题


1 # -*- coding:utf-8 -*- 2 # author: cdc 3 # date: 2019/3/18 4 5 import pymysql 6 7 conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',password='cdc19951216',db='test',charset='utf8') 8 9 cursor = conn.cursor() 10 11 # 传参方式查询数据 12 cursor.execute('select * from user_info where name=%s and password=%s',('cdc','123456',)) 13 res = cursor.fetchone() 14 print(res) 15 16 # 执行结果 >>>> (1, 'cdc', '123456')
1 # -*- coding:utf-8 -*- 2 # author: cdc 3 # date: 2019/3/18 4 5 import pymysql 6 7 conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',password='cdc19951216',db='test',charset='utf8') 8 9 cursor = conn.cursor() 10 11 # 字符串拼接方式查询 12 sql = 'select * from user_info where name="%s" and password="%s"' 13 inp = ('cdc','123456') 14 sql = sql % inp 15 cursor.execute(sql) 16 res = cursor.fetchone() 17 print(res) 18 19 # 执行结果 >>>>> (1, 'cdc', '123456')
乍一看,两种方式都可以执行成功,但是只要对字符串拼接的方法稍微改动一下就能很明显的看出此类方式的弊端
# -*- coding:utf-8 -*- # author: cdc # date: 2019/3/18 import pymysql conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',password='cdc19951216',db='test',charset='utf8') cursor = conn.cursor() sql = 'select * from user_info where name="%s" and password="%s"' inp = ('cdc" and 1=1 -- ','123456') sql = sql % inp cursor.execute(sql) res = cursor.fetchone() print(res) # 执行结果 >>>>> (1, 'cdc', '123456')
按理来说,数据库中并未满足条件的数据,但是还是可以执行成功,这是因为将字符串'cdc" and 1=1 -- '替换掉对应的占位符后会将sql语句变为:
1 select * from user_info where name="cdc" and 1=1 -- " and password="%s"
此时后面password的条件已经被注释掉了,真正执行的判断条件是name='cdc'和1=1,这个条件恒为true,因此无论如何都可以从数据库中查询到信息,因此使用字符串拼接的方式进行查询风险很大。
二、视图
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,用户使用时只需使用【名称】即可获取结果集,并可以将其当作表来使用。(实例化来说,可能某个需求需要重复的对某张表中的某些数据进行反复操作,每次重写重复的sql与是十分没有必要的,可以先将要操作的数据提取出来,作为一张临时的表)
1、创建视图
1 --格式:CREATE VIEW 视图名称 AS SQL语句 2 3 CREATE VIEW temp1 AS SELECT no,name from tb3 where tb3.part_no>2
2、删除视图
1 --格式:DROP VIEW 视图名称 2 3 DROP VIEW temp1
3、修改视图
1 -- 格式:ALTER VIEW 视图名称 AS SQL语句 2 3 ALTER VIEW temp1 AS SELECT no,name,part_no FROM tb3 WHERE part_no!=1
4、使用视图
使用视图时,将其当作表进行操作即可,由于视图是虚拟表,所以无法使用其对真实表进行创建、更新和删除操作,仅能做查询用。
1 select * from v1
三、存储过程
存储过程是一个SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行。(进一步提升了视图的简洁性和功能,使用方式类似于python中函数调用)
1、创建存储过程
1 -- 创建存储过程 2 3 delimiter // 4 create procedure p1() 5 BEGIN 6 select * from tb3; 7 END// 8 delimiter ; 9 10 -- delimiter的作用是修改sql语句执行结束的判断标志,即若按照原来的方式,每当遇到 ; 则sql语句输入结束并运行,这样后面的END就不会生效,现先将执行结束的标志改为 // ,sql语句遇到//时才表示结束
1 # *************** 终端调用 **************** 2 call p1() 3 4 # ************* pymysql调用 ***************** 5 import pymysql 6 # 创建连接 7 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='cdc19951216', db='test',charset='utf8') 8 # 创建游标 9 cursor = conn.cursor() 10 cursor.callproc('p1') 11 12 result = cursor.fetchone() 13 print(result) 14 15 # 关闭游标 16 cursor.close() 17 # 关闭连接 18 conn.close()
对于存储过程,可以接收参数,其参数有三类:
- in 仅用于传入参数用
- out 仅用于返回值用
- inout 既可以传入又可以当作返回值
1 -- 创建存储过程 2 delimiter \\ 3 create procedure p1( 4 in i1 int, -- 可以理解为i1为整型参数,且只提供输入值的功能,使用前必须赋值 5 in i2 int, 6 inout i3 int, -- 可以理解为i3为整型参数,既要提供输入值又要提供返回值的功能,使用前必须赋值 7 out r1 int -- 可以理解为r1为整型参数,且只提供返回值的功能,开始时不必赋值,如果有值也会被后期覆盖掉 8 ) 9 BEGIN 10 DECLARE temp1 int; -- 定义一个整型变量temp1 11 DECLARE temp2 int default 0; -- 定义一个整型变量temp2,初始值为0 12 13 set temp1 = 1; -- 赋值 14 15 set r1 = i1 + i2 + temp1 + temp2; -- r1 = 1+2+1+0 16 17 set i3 = i3 + 100; -- i3=4+100 18 19 end\\ 20 delimiter ; 21 22 -- 执行存储过程 23 set @t1 =4; 24 set @t2 = 0; 25 CALL p1 (1, 2 ,@t1, @t2); 26 SELECT @t1,@t2; -- 最后返回的是i3和r1的值
1 -- 创建存储过程 2 delimiter // 3 create procedure p1() 4 begin 5 select * from v1; 6 end // 7 delimiter ; 8 9 -- 调用存储过程 10 call p1();
1 -- 创建存储过程 2 delimiter // 3 CREATE PROCEDURE p2 ( IN n1 INT, INOUT n3 INT, OUT n2 INT, ) BEGIN 4 DECLARE 5 temp1 INT; 6 DECLARE 7 temp2 INT DEFAULT 0; 8 SELECT 9 * 10 FROM 11 v1; 12 13 SET n2 = n1 + 100; 14 15 SET n3 = n3 + n1 + 100; 16 17 END // 18 delimiter; 19 20 -- 调用存储过程 21 set @t1 = 3; 22 set @t2 = 5; 23 24 -- 执行到这一步时,会将结果集打印出来,并将@t1和@t2的值分别传给n3和n2,但是不会还没有进行结果计算操作 25 call p2(1,@t1,@t2) 26 27 -- 执行这一步才会进行运算并返回结果 28 select @t1,@t2
1 -- 存储过程与游标操作 2 delimiter // 3 CREATE PROCEDURE p3 ( ) BEGIN 4 DECLARE 5 ssid INT;-- 自定义变量1 6 DECLARE 7 ssname VARCHAR ( 50 );-- 自定义变量2 8 DECLARE 9 done INT DEFAULT FALSE; 10 DECLARE 11 my_cursor CURSOR FOR SELECT 12 sid, 13 sname 14 FROM 15 student; 16 DECLARE 17 CONTINUE HANDLER FOR NOT FOUND 18 SET done = TRUE; 19 OPEN my_cursor; 20 xxoo : 21 LOOP 22 FETCH my_cursor INTO ssid, 23 ssname; 24 IF 25 done THEN 26 LEAVE xxoo; 27 28 END IF; 29 INSERT INTO teacher ( tname ) 30 VALUES 31 ( ssname ); 32 33 END LOOP xxoo; 34 CLOSE my_cursor; 35 36 END // delimter;
1 -- 动态执行sql可以防止sql注入 2 -- 创建存储过程 3 delimiter // 4 CREATE PROCEDURE p6( in num int) 5 BEGIN 6 set @age = num 7 PREPARE prod FROM 'select * from student where age>?'; -- prod相当于一个变量 8 EXECUTE prod USING @age; -- 字符串格式化 9 DEALLOCATE prepare prod; -- 执行sql语句 10 END// 11 delimiter ; 12 13 -- 调用存储过程 14 call p6(18);
2、删除存储过程
drop procedure proc_name;
3、执行存储过程
1 -- 无参数 2 call proc_name() 3 4 -- 有参数,全in 5 call proc_name(1,2) 6 7 -- 有参数,有in,out,inout 8 set @t1=0; 9 set @t2=3; 10 call proc_name(1,2,@t1,@t2)
1 # -*- coding:utf-8 -*- 2 import pymysql 3 4 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') 5 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) 6 # 执行存储过程 7 cursor.callproc('p1', args=(1, 22, 3, 4)) 8 # 获取执行完存储的参数 9 cursor.execute("select @_p1_0,@_p1_1,@_p1_2,@_p1_3") 10 result = cursor.fetchall() 11 12 conn.commit() 13 cursor.close() 14 conn.close() 15 16 17 print(result)
四、触发器
对某个表进行【增/删/改】操作的前后如果希望触发某个特定的行为时,可以使用触发器,触发器用于定制用户对表的行进行【增/删/改】前后的行为。
1、创建触发器
1 -- 插入前:即在执行向tb1表插入数据前先执行固定操作 2 CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW 3 BEGIN 4 ... 5 END 6 7 # 插入后:即在执行向tb1表插入数据后再执行固定操作 8 CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW 9 BEGIN 10 ... 11 END 12 13 # 删除前 14 CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW 15 BEGIN 16 ... 17 END 18 19 # 删除后 20 CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW 21 BEGIN 22 ... 23 END 24 25 # 更新前 26 CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW 27 BEGIN 28 ... 29 END 30 31 # 更新后 32 CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW 33 BEGIN 34 ... 35 END
1 delimiter // 2 CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW 3 BEGIN 4 IF NEW. num = 666 THEN 5 INSERT INTO tb2 (NAME) 6 VALUES 7 ('666'), 8 ('666') ; 9 ELSEIF NEW. num = 555 THEN 10 INSERT INTO tb2 (NAME) 11 VALUES 12 ('555'), 13 ('555') ; 14 END IF; 15 END // 16 delimiter ;
1 delimiter // 2 CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW 3 BEGIN 4 IF NEW. NAME == 'alex' THEN 5 INSERT INTO tb2 (NAME) 6 VALUES 7 ('aa') 8 ENDIF; 9 END // 10 delimiter ;
注:NEW表示用户新输入的原来没有的数据,OLD表示即将删除的原来有的数据。
-- 删除student中的姓名为alex的数据,并在删除操作前将删除的姓名记录到tb3中 delimiter // CREATE TRIGGER tri_before_insert_tb3 AFTER INSERT ON tb3 FOR EACH ROW BEGIN insert into tb3(name) values(OLD.sname); ENDIF; END // delimiter ;
-- 将原来student中学号为1的sname记录到tb3中,再将该记录的sname更新为alex delimiter // CREATE TRIGGER tri_before_delete_student BEFORE DELETE ON student FOR EACH ROW BEGIN insert into tb3(name) values(OLD.sname); insert into student(sname) values(NEW.sname) where sid=1; ENDIF; END // delimiter ; -- 若原数据:sname:cdc sid:1 -- 执行update student set name='alex' where sid=1; OLD.sname为cdc,NEW.sname为alex
2、删除触发器
DROP TRIGGER tri_after_insert_tb1;
五、函数
1、部分内置函数
CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D) 将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: '12,332.1000' INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 LTRIM(str) 返回字符串 str ,其引导空格字符被删除。 RTRIM(str) 返回字符串 str ,结尾空格字符被删去。 SUBSTRING(str,pos,len) 获取字符串子序列 LOCATE(substr,str,pos) 获取子序列索引位置 REPEAT(str,count) 返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。 若 count <= 0,则返回一个空字符串。 若str 或 count 为 NULL,则返回 NULL 。 REPLACE(str,from_str,to_str) 返回字符串str 以及所有被字符串to_str替代的字符串from_str 。 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。 RIGHT(str,len) 从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N) 返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING('Quadratically',5); -> 'ratically' mysql> SELECT SUBSTRING('foobarbar' FROM 4); -> 'barbar' mysql> SELECT SUBSTRING('Quadratically',5,6); -> 'ratica' mysql> SELECT SUBSTRING('Sakila', -3); -> 'ila' mysql> SELECT SUBSTRING('Sakila', -5, 3); -> 'aki' mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2); -> 'ki' TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str) 返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。 mysql> SELECT TRIM(' bar '); -> 'bar' mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx'); -> 'barxxx' mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx'); -> 'bar' mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz'); -> 'barx' 部分内置函数
2、自定义函数
1 delimiter \\ 2 create function f1( 3 i1 int, 4 i2 int) 5 returns int 6 BEGIN 7 declare num int; 8 set num = i1 + i2; 9 return(num); 10 END \\ 11 delimiter ;
3、删除函数
drop function func_name;
4、执行函数
1 # 获取返回值 2 declare @i VARCHAR(32); 3 select UPPER('alex') into @i; 4 SELECT @i; 5 6 7 # 在查询中使用 8 select f1(11,nid) ,name from tb2;
5、函数与存储过程的比较
存储过程:a) 可以执行sql语句
b) 只能通过out和inout来构造返回值
函数: a) 不能执行sql语句,除赋值语句:(例) select nid into a from student where sname='cdc';
b) 可以直接通过return返回
六、循环判断
1、条件语句
1 delimiter \\ 2 CREATE PROCEDURE proc_if () 3 BEGIN 4 5 declare i int default 0; 6 if i = 1 THEN 7 SELECT 1; 8 ELSEIF i = 2 THEN 9 SELECT 2; 10 ELSE 11 SELECT 7; 12 END IF; 13 14 END\\ 15 delimiter ;
2、循环语句
1 delimiter \\ 2 CREATE PROCEDURE proc_while () 3 BEGIN 4 5 DECLARE num INT ; 6 SET num = 0 ; 7 WHILE num < 10 DO 8 SELECT 9 num ; 10 SET num = num + 1 ; 11 END WHILE ; 12 13 END\\ 14 delimiter ;
1 delimiter \\ 2 CREATE PROCEDURE proc_repeat () 3 BEGIN 4 5 DECLARE i INT ; 6 SET i = 0 ; 7 repeat 8 select i; 9 set i = i + 1; 10 until i >= 5 11 end repeat; 12 13 END\\ 14 delimiter ;
1 BEGIN 2 3 declare i int default 0; 4 loop_label: loop 5 6 set i=i+1; 7 if i<8 then 8 iterate loop_label; 9 end if; 10 if i>=10 then 11 leave loop_label; 12 end if; 13 select i; 14 end loop loop_label; 15 16 END
六、慢日志记录和查询
通过设置日志相关信息,可以查到查询较慢、是否使用索引等相关操作的日志记录。
1、在配置文件中设置慢日志
slow_query_log = OFF 是否开启慢日志记录
long_query_time = 2 时间限制,超过此时间,则记录
slow_query_log_file = /usr/slow.log 日志文件
log_queries_not_using_indexes = OFF 为使用索引的搜索是否记录

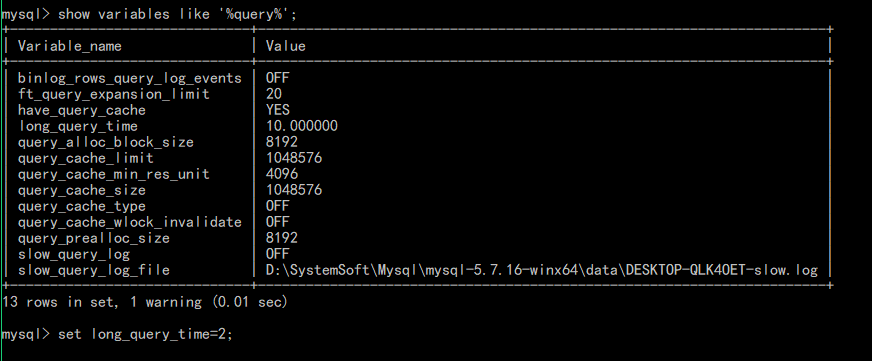
2、在终端设置慢日志
查看当前配置信息:show variables like '%query%'
设置变量值:set 变量名=值
重启服务器,带上日志文件存储路径

完结撒花,掰掰 !!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号