【C#基础概念】字节顺序(大端、小端)
字节顺序,又称端序或尾序(英語:Endianness),在计算机科学领域中,指電腦記憶體中或在数字通信链路中,组成多字节的字的字节的排列顺序。
例如假设上述变量x类型为int,位于地址0x100处,它的值为0x01234567,地址范围为0x100~0x103字节,其内部排列顺序依赖于机器的类型。大端法从首位开始将是:0x100: 0x01, 0x101: 0x23,..。而小端法将是:0x100: 0x67, 0x101: 0x45,..。
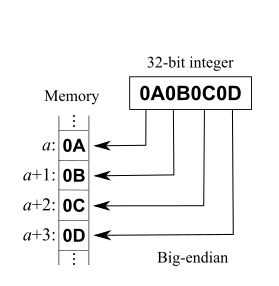
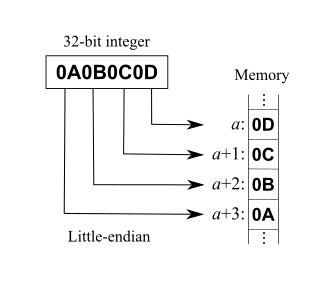
举列子:就像车直接倒进车库(小端),还是直接开入车库(大端)。
处理器体系
- x86、MOS Technology 6502、Z80、VAX、PDP-11等处理器为小端序;
- Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除V9外)等处理器为大端序;
- ARM、PowerPC(除PowerPC 970外)、DEC Alpha、SPARC V9、MIPS、PA-RISC及IA64的字节序是可配置的。
网络序
网络传输一般采用大端序,也被称之为网络字节序,或网络序。IP协议中定义大端序为网络字节序。
C#如何查看字节顺序
BitConverter.IsLittleEndian
Console.WriteLine( "IsLittleEndian: {0}", BitConverter.IsLittleEndian );
将比特数字转成 int32
byte[]bigend = { 0,0, 0,97 };//这个是大端存法 byte[] littleend = { 97, 0, 0, 0 };//这个是小端存法 Console.WriteLine(BitConverter.ToInt32(bigend, 0));//输出1627389952 // Array.Reverse(bigend);或者直接数组转换一下 Console.WriteLine(BitConverter.ToInt32(littleend, 0));//输出97
c# 通信中字节序处理
最近在写一个短信下发功能,客户端使用c#和java的短信网关的进行网络通信。
之前使用java进行开发,一切正常,改用c#无法收到网关应答。
想了半天意识到是不是网络字节序问题,
java默认就是大端字节序,和网络字节序是一至的,所以不转换也不会有问题,
而c#在windows平台上是小端字节序。
网络发送字节流是按大端序发送,也就是从左到右发送,和c#的小端序相反,造成网关不能正常识别协议。
尝试c#中转换一下字节序,通信成功。
c#中字节序转换有两种方法。
非字串使用 System.BitConverter.GetBytes()方法,先读入字节数组中,然后再用Array.Reverse()对byte数组反序一下,得到大端序字节数组。
代码:
short x = 6;
byte[] a=System.BitConverter.GetBytes(x); //得到小端字节序数组
Array.Reverse(a); //反转数组转成大端。
另外c#直接提供了网络字节序转换方法。
System.Net.IPAddress.HostToNetworkOrder(本机到网络转换)
System.Net.IPAddress.NetworkToHostOrder(网络字节转成本机)
推荐使用这种方法,简单有效。
代码示例:
short x = 6;
short b = System.Net.IPAddress.HostToNetworkOrder(x); //把x转成相应的大端字节数
byte[] bb = System.BitConverter.GetBytes(b); //这样直接取到的就是大端字节序字节数组。
对于字符串型:使用 System.Text.Encoding.Default.GetBytes();直接取字串对应字节数组。
不知道为什么这个方法取到的直接就是大端字节数组。不用转换。
后来查了一下,关于字串的字节序问题,因为gbk和utf-8都是以单个字节表示数字的,所以不存在字节序问题,在多个不同系统架构都用。对于utf-16,则是以双字节表示一个整数,所以为会有字节序问题,分大小端unicode。
System.Text.Encoding.Default.GetBytes();在我的简体中文系统上是以gb2312的编码,也就是单个字来进行编码的,所以也不会有字节序问题。
补充:“对于任何字符编码,编码单元的顺序是由编码方案指定的,与endian无关。例如GBK的编码单元是字节,用两个字节表示一个汉字。这两个字节的顺序是固定的,不受CPU字节序的影响。UTF-16的编码单元是word(双字节),word之间的顺序是编码方案指定的,word内部的字节排列才会受到endian的影响。”,所以utf-8也没有字节序的问题。字节序问题之存在于需要使用两个字节以上来表示整数。而UTF-8只是一串字节流,不存在字节序问题,不过将这些字节流翻译成Unicode比其他的传输方式复杂。以字节为单位编码的,无论一个汉字是多少个字节,都无字节序问题。
你注意,字节序问题不是指多个字节传输的先后,这个是固定的无异议的。而是指一个多字节编码在机器中的表示方式问题。
char str[] = "abaksdkakskasklasflk";这个无字节序问题。
但
int str[] = {0x11223344, 2, 3 }就有字节序问题了。因为str[0]同样数值不同机器中表示不同。
而剩下的, 就是字符编码内部的字节序了。比如UTF-16是用两个字节表示一个字符,但是这两个字节内部如何排序,系统并不知道,所以必须指定字节序。但是UTF-8由于几个字节表示并不相同,一定要从那个表示长度的字节开始读,相当于一开始就知道该从哪里是队头队尾,所以不存在字节序问题。
附上字节序说明:
为什么要注意字节序的问题呢?你可能这么问。当然,如果你写的程序只在单机环境下面运行,并且不和别人的程序打交道,那么你完全可以忽略字节序的存在。但是,如果你的程序要跟别人的程序产生交互呢?尤其是当你把你在微机上运算的结果运用到计算机群上去的话。在这里我想说说两种语言。C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而JAVA编写的程序则唯一采用big endian方式来存储数据。试想,如果你用C/C++语言在x86平台下编写的程序跟别人的JAVA程序互通时会产生什么结果?就拿上面的 0x12345678来说,你的程序传递给别人的一个数据,将指向0x12345678的指针传给了JAVA程序,由于JAVA采取big endian方式存储数据,很自然的它会将你的数据翻译为0x78563412。什么?竟然变成另外一个数字了?是的,就是这种后果。因此,在你的C程序传给JAVA程序之前有必要进行字节序的转换工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号