
102302134陈蔡裔数据采集第四次作业
第一题
核心代码和运行结果
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
import time
import sqlite3
# 配置浏览器
edge_options = Options()
edge_options.add_argument('--headless')
edge_options.add_argument('--disable-gpu')
driver = webdriver.Edge(options=edge_options)
# 初始化数据库
def init_db():
conn = sqlite3.connect('stock_market.db')
conn.execute('''
CREATE TABLE IF NOT EXISTS stocks (
market_type TEXT,
stock_code TEXT,
stock_name TEXT,
current_price REAL,
change_rate REAL,
change_amount REAL,
volume INTEGER,
turnover REAL,
high_price REAL,
low_price REAL,
open_price REAL,
prev_close REAL
)
''')
conn.commit()
conn.close()
# 保存数据到数据库
def save_data(data):
conn = sqlite3.connect('stock_market.db')
conn.execute('''
INSERT INTO stocks
(market_type, stock_code, stock_name, current_price, change_rate, change_amount,
volume, turnover, high_price, low_price, open_price, prev_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', data)
conn.commit()
conn.close()
# 显示数据库数据
def display_data():
conn = sqlite3.connect('stock_market.db')
cursor = conn.cursor()
cursor.execute('SELECT * FROM stocks')
rows = cursor.fetchall()
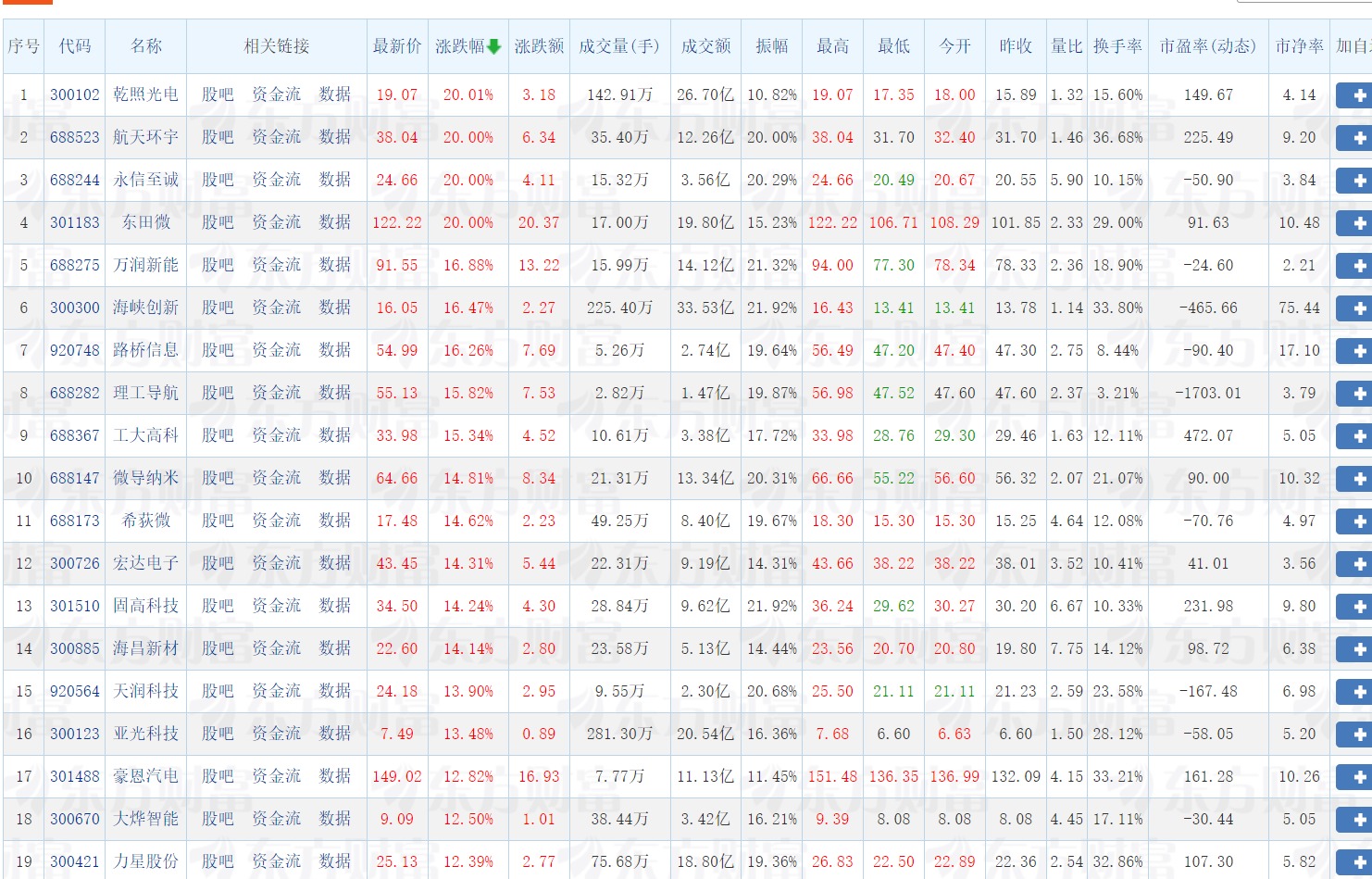
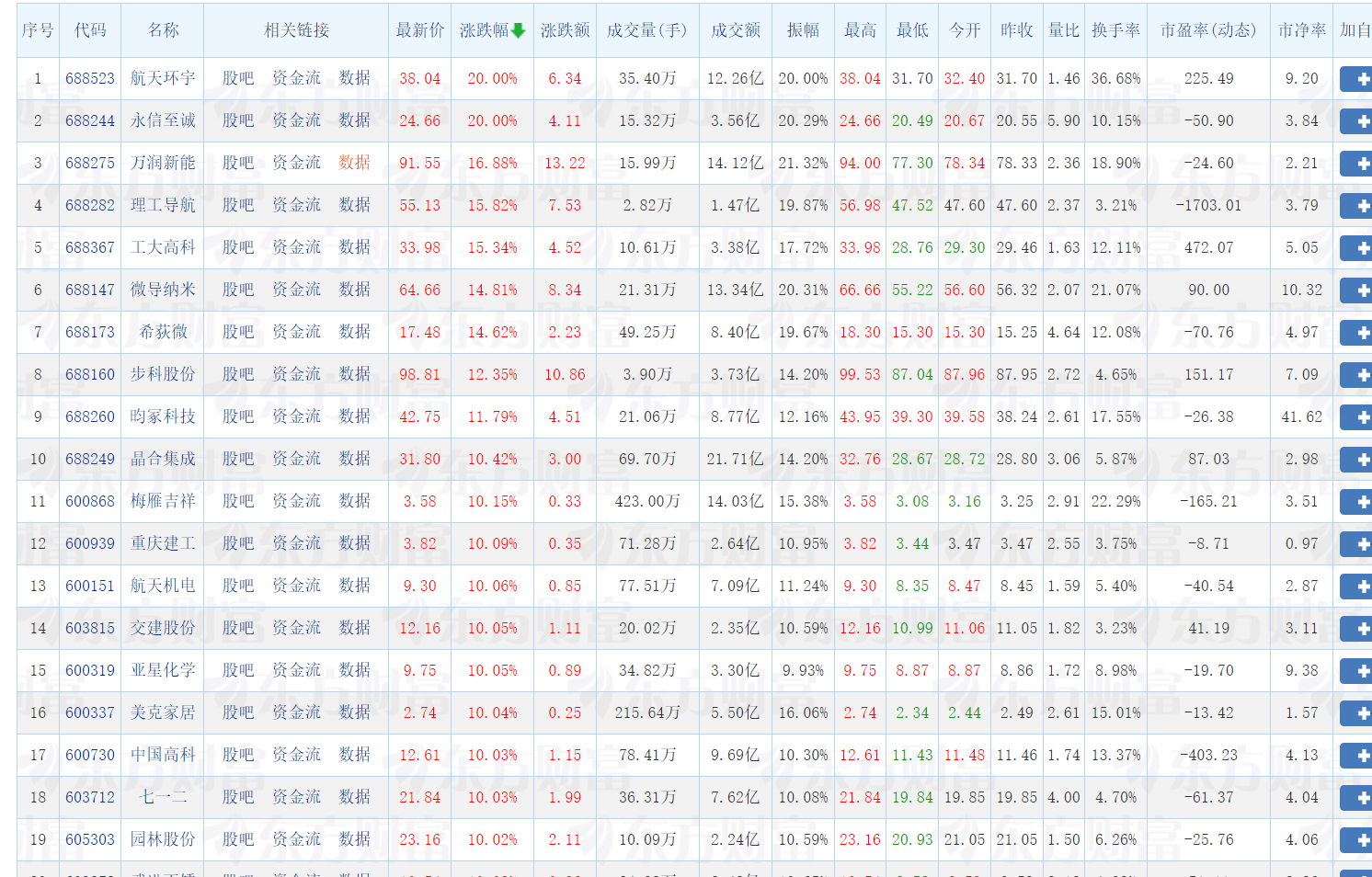
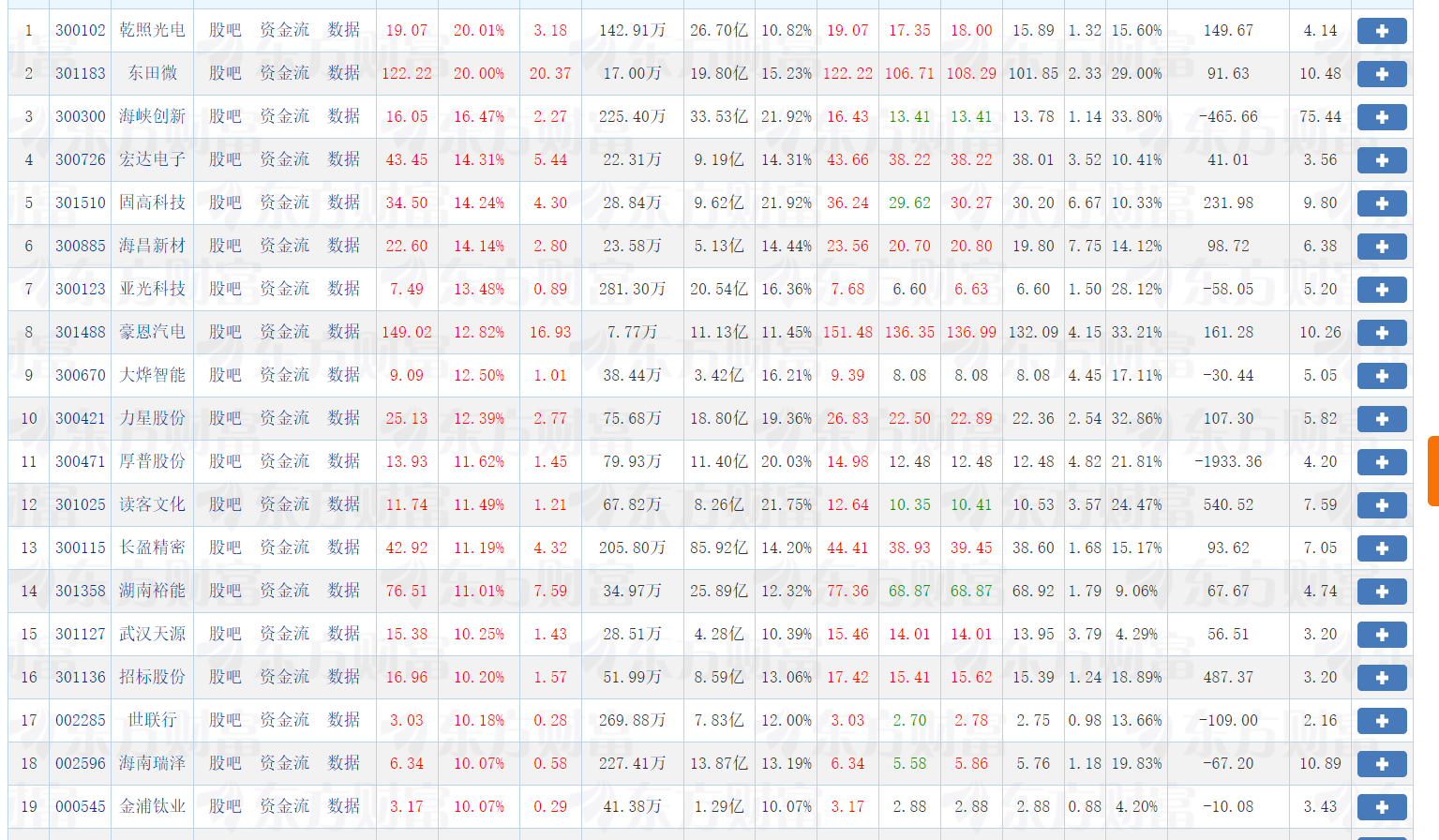
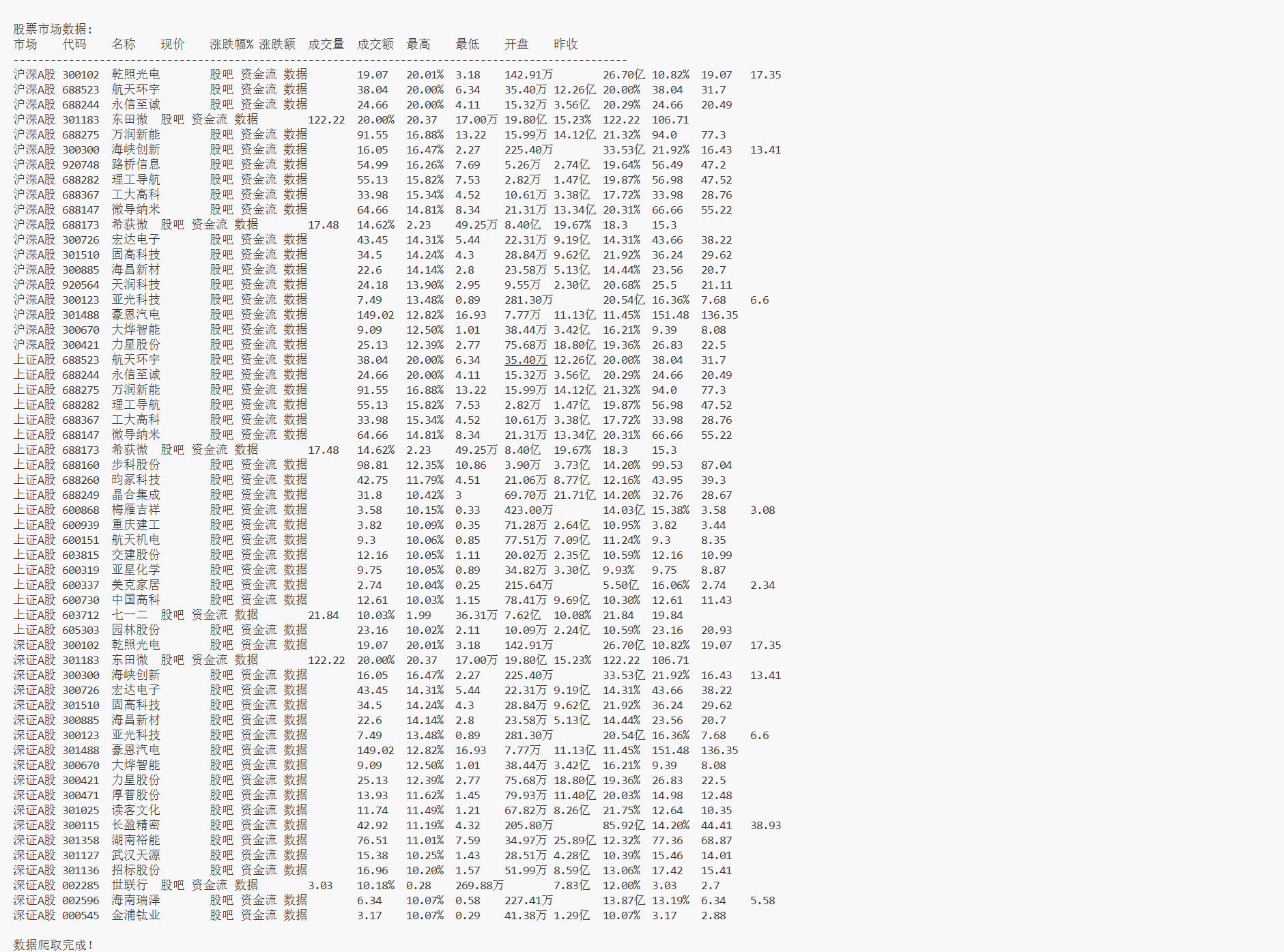
print("\n股票市场数据:")
print("市场\t代码\t名称\t现价\t涨跌幅%\t涨跌额\t成交量\t成交额\t最高\t最低\t开盘\t昨收")
print("-" * 100)
for row in rows:
print(f"{row[0]}\t{row[1]}\t{row[2]}\t{row[3]}\t{row[4]}\t{row[5]}\t{row[6]}\t{row[7]}\t{row[8]}\t{row[9]}\t{row[10]}\t{row[11]}")
conn.close()
# 主爬虫函数
def crawl_stocks():
markets = [
('https://quote.eastmoney.com/center/gridlist.html#hs_a_board', '沪深A股'),
('https://quote.eastmoney.com/center/gridlist.html#sh_a_board', '上证A股'),
('https://quote.eastmoney.com/center/gridlist.html#sz_a_board', '深证A股')
]
for url, market_name in markets:
print(f"正在爬取{market_name}...")
driver.get(url)
time.sleep(4)
# 获取股票行数据
rows = driver.find_elements(By.CSS_SELECTOR, "table tbody tr")
for row in rows[:25]: # 每个市场取25条
cells = row.find_elements(By.TAG_NAME, "td")
if len(cells) > 10:
stock_data = (
market_name,
cells[1].text, # 股票代码
cells[2].text, # 股票名称
cells[3].text, # 最新价
cells[4].text, # 涨跌幅
cells[5].text, # 涨跌额
cells[6].text, # 成交量
cells[7].text, # 成交额
cells[8].text, # 最高
cells[9].text, # 最低
cells[10].text, # 今开
cells[11].text # 昨收
)
save_data(stock_data)
# 运行主程序
if __name__ == "__main__":
init_db()
crawl_stocks()
driver.quit()
display_data()
print("\n数据爬取完成!")
作业心得
通过这次股票数据爬虫项目,我深刻体会到理论与实践的结合。在爬取东方财富网数据时,遇到了页面结构复杂、数据重复存储等问题,通过不断调试和优化代码,学会了如何更精准地定位元素和处理异常数据。特别是在处理数据库重复记录时,明白了数据清洗和去重的重要性。这次实践不仅提升了我的Python编程能力和Selenium自动化操作技巧,更培养了我解决实际问题的能力和耐心,认识到一个完整的数据采集系统需要考虑到数据质量、效率和稳定性等多个方面。
https://gitee.com/chen-caiyi041130/chen-caiyi/tree/master/作业4
第二题
核心代码和运行结果
模拟登录
# 模拟登录
#点击登录按钮
def click_login():
login_xpaths = [
"//button[contains(text(), '登录')]",
"//a[contains(text(), '登录')]",
"//*[contains(text(), '登录')]"
]
for xpath in login_xpaths:
try:
elements = driver.find_elements(By.XPATH, xpath)
for element in elements:
if element.is_displayed():
element.click()
print("点击登录按钮")
return True
except:
continue
return False
#在登录表中填写用户名和密码,处理iframe中的登录表单
def fill_login_form(username, password):
iframes = driver.find_elements(By.TAG_NAME, "iframe")
for iframe in iframes:
try:
driver.switch_to.frame(iframe)
inputs = driver.find_elements(By.CSS_SELECTOR, "input")
username_filled = False
password_filled = False
for field in inputs:
field_type = field.get_attribute('type') or ''
placeholder = field.get_attribute('placeholder') or ''
if not username_filled and field_type in ['text', 'tel'] and '手机' in placeholder:
field.clear()
field.send_keys(username)
print("输入用户名")
username_filled = True
continue
if not password_filled and field_type == 'password' and '密码' in placeholder:
field.clear()
field.send_keys(password)
print("输入密码")
password_filled = True
continue
driver.switch_to.default_content()
return username_filled and password_filled
except:
driver.switch_to.default_content()
return False
#提交登录表单
def submit_login():
iframes = driver.find_elements(By.TAG_NAME, "iframe")
for iframe in iframes:
try:
driver.switch_to.frame(iframe)
submit_selectors = [
"button[type='submit']",
"input[type='submit']",
"button:contains('登')",
".j-login-btn",
".u-loginbtn"
]
for selector in submit_selectors:
try:
if "contains" in selector:
for btn in driver.find_elements(By.XPATH, "//button[contains(text(), '登')]"):
if btn.is_displayed():
btn.click()
print("提交登录")
driver.switch_to.default_content()
return True
else:
submit_btn = driver.find_element(By.CSS_SELECTOR, selector)
if submit_btn.is_displayed():
submit_btn.click()
print("提交登录")
driver.switch_to.default_content()
return True
except:
continue
driver.switch_to.default_content()
except:
driver.switch_to.default_content()
return False
#检查登录是否成功
def check_login():
time.sleep(3)
user_selectors = [".user-info", ".user-name", "a[href*='user']"]
for selector in user_selectors:
try:
element = driver.find_element(By.CSS_SELECTOR, selector)
if element.is_displayed():
print("登录成功")
return True
except:
continue
return False
#登录主函数
def login(username, password):
print("开始登录...")
driver.get("https://www.icourse163.org/")
time.sleep(3)
if not click_login():
return False
time.sleep(3)
if not fill_login_form(username, password):
return False
if not submit_login():
return False
return check_login()
爬取Ajax
#爬取Ajax
def get_course_info(url, course_id):
driver.get(url)
time.sleep(3)
info = {
"course_id": course_id, "course_name": f"课程{course_id}",
"university": "未知学校", "instructor": "未知教师",
"team_members": "未知教师", "student_count": "未知",
"schedule": "未知", "description": "暂无简介"
}
# 课程名称
for selector in [".course-title", "h1", ".u-course-title"]:
try:
title = driver.find_element(By.CSS_SELECTOR, selector).text.strip()
if title and len(title) > 2:
info['course_name'] = title
break
except:
continue
# 学校名称
try:
school = driver.find_element(By.XPATH, "//*[@id='j-teacher']/div/a/img").get_attribute('alt')
if school:
info['university'] = school
except:
for selector in [".u-course-org", ".school-name"]:
try:
school = driver.find_element(By.CSS_SELECTOR, selector).text
if school:
info['university'] = school
break
except:
continue
# 主讲教师
teacher_selectors = [".f-fc3", ".teacher-name", ".instructor", "h3.f-fc3"]
for selector in teacher_selectors:
try:
teacher_elems = driver.find_elements(By.CSS_SELECTOR, selector)
for elem in teacher_elems:
teacher = elem.text.strip()
# 过滤掉"位授课老师"这样的文本,只保留真实姓名
if (teacher and len(teacher) > 1 and
'位授课老师' not in teacher and
'课程团队' not in teacher and
len(teacher) < 10): # 中文姓名通常2-4个字
info['instructor'] = teacher
break
if info['instructor'] != "未知教师":
break
except:
continue
# 团队成员
team_members = []
try:
# 查找所有教师姓名元素
name_elements = driver.find_elements(By.CSS_SELECTOR, ".f-fc3, .teacher-name, .t-name, .name")
for elem in name_elements:
name = elem.text.strip()
if (name and len(name) > 1 and
'位授课老师' not in name and
'课程团队' not in name and
len(name) < 10 and
name != info['instructor']): # 排除主讲教师
team_members.append(name)
# 去重
team_members = list(set(team_members))
if team_members:
info['team_members'] = ', '.join(team_members)
else:
info['team_members'] = info['instructor'] # 如果没有其他成员,使用主讲教师
except Exception as e:
print(f"抓取团队成员失败: {e}")
info['team_members'] = info['instructor']
# 参与人数
try:
count_text = driver.find_element(By.CSS_SELECTOR, "span.count").text
match = re.search(r"\d+", count_text)
if match:
info['student_count'] = match.group()
except:
pass
# 课程进度
try:
progress = driver.find_element(By.XPATH, "//*[@id='course-enroll-info']/div/div[1]/div[4]/span[@class='text']").text
if progress:
info['schedule'] = progress
except:
# 备用选择器
for selector in [".course-schedule", ".progress", ".schedule"]:
try:
progress_elem = driver.find_element(By.CSS_SELECTOR, selector)
if progress_elem.text:
info['schedule'] = progress_elem.text
break
except:
continue
# 课程简介
try:
intro = driver.find_element(By.XPATH, "//*[@id='j-rectxt2']").text
if intro:
info['description'] = intro[:200] + "..." if len(intro) > 200 else intro
except:
# 备用选择器
for selector in [".course-description", ".intro", ".description", ".m-courseintro"]:
try:
intro_elem = driver.find_element(By.CSS_SELECTOR, selector)
if intro_elem.text:
intro_text = intro_elem.text.strip()
info['description'] = intro_text[:200] + "..." if len(intro_text) > 200 else intro_text
break
except:
continue
print(f"课程信息: {info['course_name']} | 学校: {info['university']} | 教师: {info['instructor']} | 参与人数: {info['student_count']}")
print(f"团队成员: {info['team_members']}")
print(f"课程进度: {info['schedule']}")
print(f"课程简介: {info['description'][:50]}...")
return info
数据库保存与查询
def save_course(conn, cursor, data):
cursor.execute('''
INSERT INTO course_info VALUES (NULL, %s, %s, %s, %s, %s, %s, %s, %s)
''', (data['course_id'], data['course_name'], data['university'],
data['instructor'], data['team_members'], data['student_count'],
data['schedule'], data['description']))
conn.commit()
print(f"已保存: {data['course_name']}")
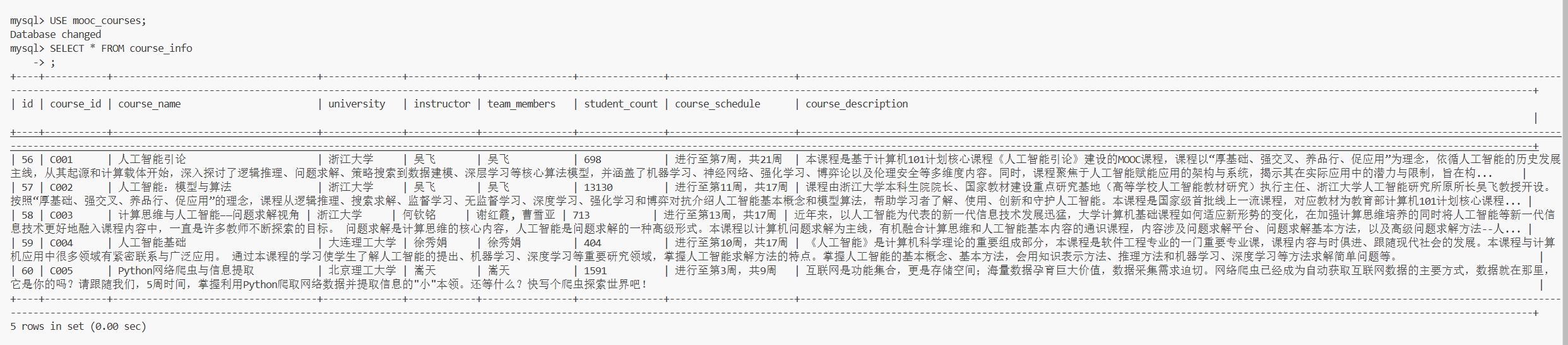
def display_data(cursor):
cursor.execute("SELECT * FROM course_info")
records = cursor.fetchall()
print("\n" + "="*150)
print("MySQL课程信息:")
print("="*150)
print(f"{'ID':<3} {'课程号':<8} {'课程名称':<25} {'学校':<15} {'主讲教师':<12} {'团队成员':<15} {'参与人数':<10} {'进度':<20} {'简介':<30}")
print("-"*150)
for record in records:
# 截断简介长度避免显示过长
description = record[8][:30] + "..." if record[8] and len(record[8]) > 30 else record[8]
print(f"{record[0]:<3} {record[1]:<8} {record[2]:<25} {record[3]:<15} {record[4]:<12} {record[5]:<15} {record[6]:<10} {record[7]:<20} {description:<30}")
print(f"\n总计: {len(records)} 门课程")
主函数
if __name__ == "__main__":
print("中国大学MOOC课程爬虫")
conn, cursor = setup_database()
cursor.execute("DELETE FROM course_info")
conn.commit()
if login("18065097076", "ccy20041130"):
print("登录成功,开始爬取课程...")
else:
print("登录失败,爬取公开课程...")
courses = [
"https://www.icourse163.org/course/ZJU-1472847200",
"https://www.icourse163.org/course/ZJU-1003377027",
"https://www.icourse163.org/course/ZJU-1472836187",
"https://www.icourse163.org/course/DUT-1463110162",
"https://www.icourse163.org/course/BIT-1001870001",
]
print(f"爬取 {len(courses)} 个课程...")
for i, url in enumerate(courses, 1):
print(f"处理第 {i} 个课程...")
data = get_course_info(url, f"C{i:03d}")
save_course(conn, cursor, data)
time.sleep(2)
display_data(cursor)
driver.quit()
cursor.close()
conn.close()
print("执行完成!")

作业心得
在完成这个中国大学MOOC课程爬虫项目的过程中,我深刻体会到了网络爬虫开发的挑战与乐趣。最初遇到了诸多困难:登录按钮无法定位、iframe处理复杂、表单填写失败等问题频发。通过不断调试,我发现网站使用了动态iframe加载登录表单,需要先切换到正确的iframe才能操作输入框。在数据爬取阶段,教师信息经常被错误地识别为"1位授课老师"这样的描述文本,通过添加过滤条件和备用选择器才解决了这个问题。数据库操作也遇到了表结构不匹配的报错,通过重新设计表结构得以解决。这个项目让我学会了如何处理复杂的网页结构、优化选择器策略、完善错误处理机制,最终成功实现了稳定登录和完整数据爬取的功能。
https://gitee.com/chen-caiyi041130/chen-caiyi/tree/master/作业4
第三题
开通MapReduce服务
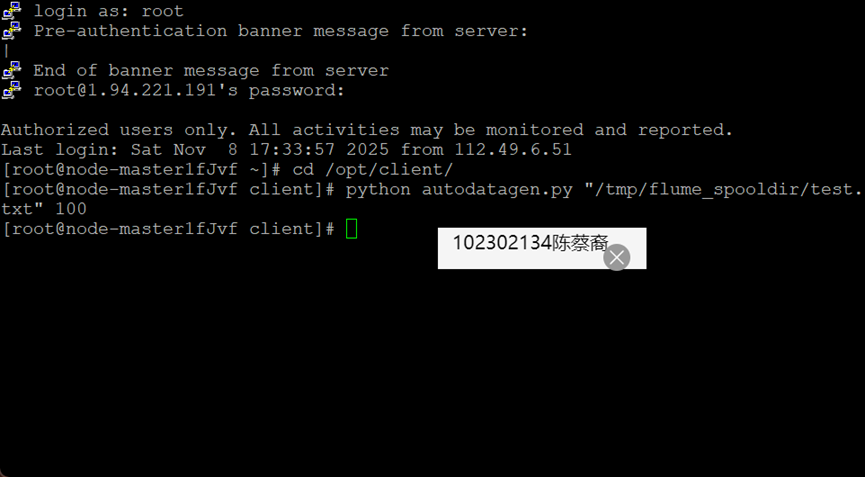
Python脚本生成测试数据
配置Kafka
安装Flume客户端
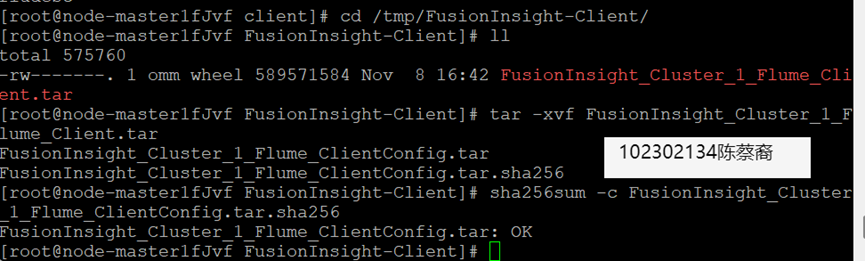

配置Flume采集数据
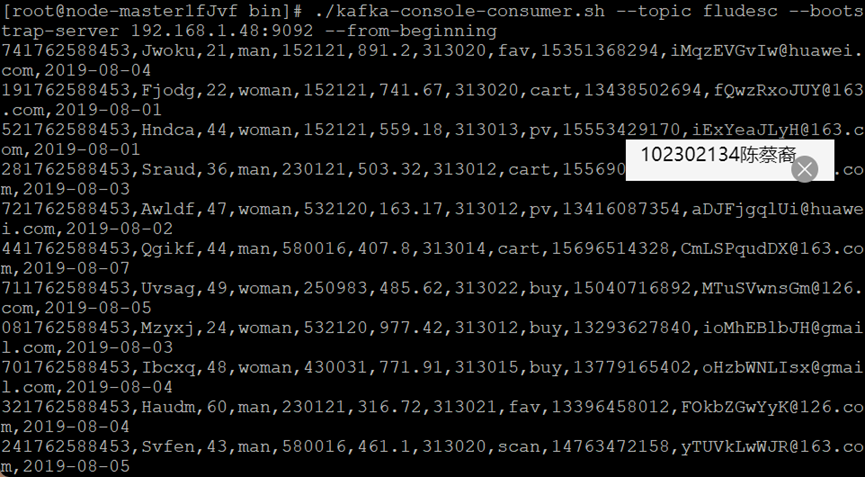
作业心得
实验将课堂上学习到的Hadoop、Hive、Spark、Flink等理论知识与云上的具体操作相结合,解决了“纸上谈兵”的问题,遇到了真实环境中才会出现的配置、网络、性能问题,极大地提升了解决问题的能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号