

102302134陈蔡裔数据采集第二次作业
第一题
核心代码和运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import sqlite3
import re
def get_weather_data():
# 城市列表
cities = [
{"name": "北京", "code": "101010100"},
{"name": "上海", "code": "101020100"},
{"name": "广州", "code": "101280101"},
{"name": "深圳", "code": "101280601"},
{"name": "杭州", "code": "101210101"},
{"name": "成都", "code": "101270101"},
{"name": "武汉", "code": "101200101"},
{"name": "西安", "code": "101110101"},
{"name": "南京", "code": "101190101"},
{"name": "重庆", "code": "101040100"}
]
# 创建数据库
conn = sqlite3.connect('weather_data.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS weather_forecast (
id INTEGER PRIMARY KEY AUTOINCREMENT,
city_name TEXT,
city_code TEXT,
forecast_date TEXT,
weather TEXT,
temperature TEXT,
wind_direction TEXT,
wind_power TEXT,
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
total_records = 0
for city in cities:
try:
print(f"正在获取 {city['name']} 的天气预报...")
# 构造7天天气预报URL
url = f"http://www.weather.com.cn/weather/{city['code']}.shtml"
response = requests.get(url, headers=headers, timeout=10)
response.encoding = 'utf-8'
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 查找7天天气预报数据
weather_data = []
days = soup.find_all('li', class_='sky')
for i, day in enumerate(days[:7]): # 只取7天数据
try:
# 提取日期
date_tag = day.find('h1')
date = date_tag.get_text() if date_tag else f"第{i+1}天"
# 提取天气状况
weather_tag = day.find('p', class_='wea')
weather = weather_tag.get_text() if weather_tag else "未知"
# 提取温度
temp_tag = day.find('p', class_='tem')
if temp_tag:
high_temp = temp_tag.find('span')
low_temp = temp_tag.find('i')
temperature = f"{high_temp.get_text() if high_temp else ''}/{low_temp.get_text() if low_temp else ''}"
else:
temperature = "未知"
# 提取风力风向
wind_tag = day.find('p', class_='win')
if wind_tag:
wind_direction = wind_tag.find('em')
wind_power = wind_tag.find('i')
wind_dir = wind_direction.get_text() if wind_direction else "未知"
wind_pwr = wind_power.get_text() if wind_power else "未知"
else:
wind_dir = "未知"
wind_pwr = "未知"
weather_data.append({
'date': date,
'weather': weather,
'temperature': temperature,
'wind_direction': wind_dir,
'wind_power': wind_pwr
})
except Exception as e:
print(f" 解析第{i+1}天数据时出错: {e}")
continue
# 保存到数据库
for data in weather_data:
cursor.execute('''
INSERT INTO weather_forecast
(city_name, city_code, forecast_date, weather, temperature, wind_direction, wind_power)
VALUES (?, ?, ?, ?, ?, ?, ?)
''', (
city['name'], city['code'], data['date'],
data['weather'], data['temperature'],
data['wind_direction'], data['wind_power']
))
total_records += len(weather_data)
print(f"✓ {city['name']}: 成功获取{len(weather_data)}天天气预报")
else:
print(f"✗ {city['name']}: 请求失败,状态码 {response.status_code}")
except Exception as e:
print(f"✗ {city['name']}: 获取失败 - {e}")
conn.commit()
# 预览数据
print("\n" + "="*60)
print("天气预报数据预览:")
print("="*60)
# 显示各城市数据统计
cursor.execute("SELECT city_name, COUNT(*) FROM weather_forecast GROUP BY city_name")
stats = cursor.fetchall()
print("\n各城市天气预报统计:")
for city, count in stats:
print(f" {city}: {count}天预报")
# 显示每个城市的第一天预报
print(f"\n各城市首日天气预报:")
print(f"{'城市':<6} {'日期':<10} {'天气':<8} {'温度':<12} {'风力':<10}")
print("-" * 60)
for city in cities:
cursor.execute('''
SELECT forecast_date, weather, temperature, wind_power
FROM weather_forecast
WHERE city_name = ?
ORDER BY forecast_date
LIMIT 1
''', (city['name'],))
result = cursor.fetchone()
if result:
date, weather, temp, wind = result
print(f"{city['name']:<6} {date:<10} {weather:<8} {temp:<12} {wind:<10}")
# 显示详细数据预览(前20条)
cursor.execute('''
SELECT city_name, forecast_date, weather, temperature, wind_power
FROM weather_forecast
ORDER BY city_name, forecast_date
LIMIT 20
''')
preview_data = cursor.fetchall()
print(f"\n详细数据预览 (前20条):")
print(f"{'城市':<6} {'日期':<10} {'天气':<8} {'温度':<12} {'风力':<10}")
print("-" * 60)
for data in preview_data:
city, date, weather, temp, wind = data
print(f"{city:<6} {date:<10} {weather:<8} {temp:<12} {wind:<10}")
conn.close()
print(f"\n天气预报数据获取完成!总计 {total_records} 条预报记录")
if __name__ == "__main__":
get_weather_data()
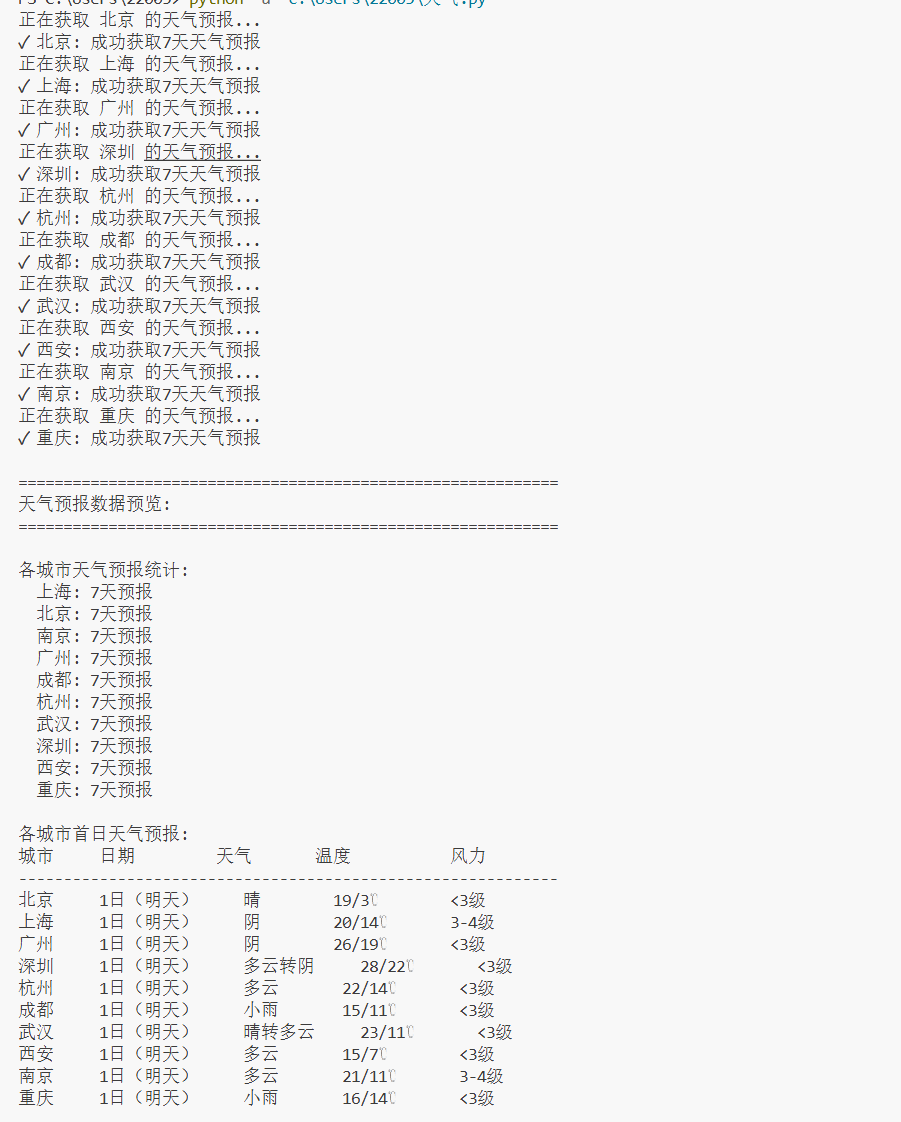
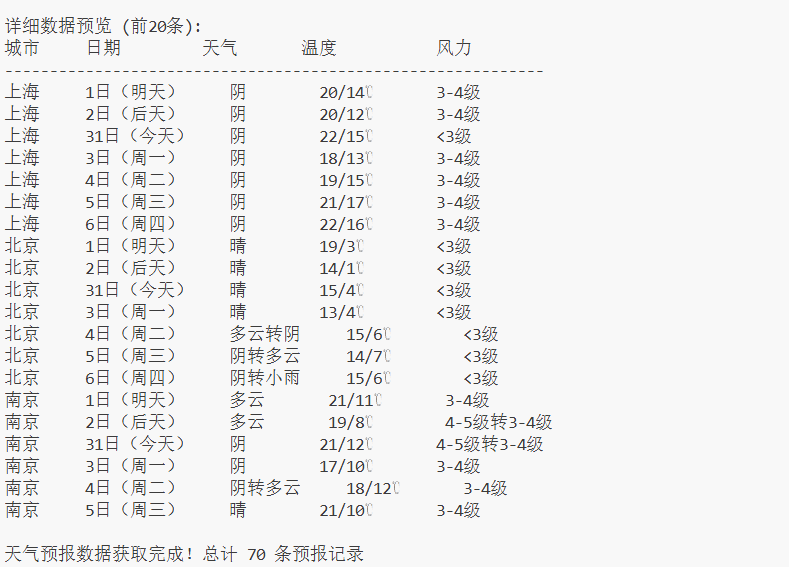
作业心得
通过开发天气预报爬虫,掌握了网页解析和数据存储的核心技术,学会了如何从复杂HTML结构中精准提取所需信息,并将数据持久化到数据库,实现了从网络采集到本地管理的完整数据流程。
https://gitee.com/chen-caiyi041130/chen-caiyi/tree/master/作业2
第二题
核心代码和运行结果
点击查看代码
import requests
import sqlite3
def get_stock_data():
# 创建数据库
conn = sqlite3.connect('stock_data.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
market TEXT,
stock_code TEXT,
stock_name TEXT,
latest_price REAL,
change_percent REAL
)
''')
# 所有市场
markets = [
{"name": "深圳主板", "fs": "m:0 t:6"},
{"name": "创业板", "fs": "m:0 t:80"},
{"name": "上海主板", "fs": "m:1 t:2"},
{"name": "科创板", "fs": "m:1 t:23"},
{"name": "北交所", "fs": "m:0 t:81 s:2048"}
]
url = "http://80.push2.eastmoney.com/api/qt/clist/get"
for market in markets:
params = {
"pn": "1",
"pz": "50",
"po": "1",
"np": "1",
"fltt": "2",
"invt": "2",
"fid": "f3",
"fs": market["fs"],
"fields": "f12,f14,f2,f3",
"_": "1622801330672"
}
try:
print(f"正在获取 {market['name']}...")
response = requests.get(url, params=params, timeout=10)
if response.status_code == 200:
data = response.json()
if data and data.get('data') and data['data'].get('diff'):
stocks = data['data']['diff']
for stock in stocks:
code = stock.get('f12', '')
name = stock.get('f14', '')
price = stock.get('f2', 0)
change = stock.get('f3', 0)
if code and name:
cursor.execute(
"INSERT INTO stocks VALUES (?, ?, ?, ?, ?)",
(market["name"], code, name, price, change)
)
print(f"✓ {market['name']}: {len(stocks)}条数据")
else:
print(f"✗ {market['name']}: 未获取到有效数据")
else:
print(f"✗ {market['name']}: 请求失败")
except Exception as e:
print(f"✗ {market['name']}: 获取失败")
conn.commit()
# 预览数据
print("\n" + "="*50)
print("数据预览:")
print("="*50)
# 显示各市场统计
cursor.execute("SELECT market, COUNT(*) FROM stocks GROUP BY market")
stats = cursor.fetchall()
print("\n各市场数据统计:")
for market, count in stats:
print(f" {market}: {count}条")
# 显示前15条数据
cursor.execute("SELECT * FROM stocks LIMIT 15")
rows = cursor.fetchall()
print(f"\n前15条数据预览:")
print(f"{'市场':<8} {'代码':<10} {'名称':<12} {'价格':<8} {'涨跌幅':<8}")
print("-" * 50)
for row in rows:
market, code, name, price, change = row
print(f"{market:<8} {code:<10} {name:<12} {price:<8.2f} {change:<8.2f}%")
# 显示价格最高的5只股票
cursor.execute('''
SELECT market, stock_code, stock_name, latest_price, change_percent
FROM stocks
ORDER BY latest_price DESC
LIMIT 5
''')
top_stocks = cursor.fetchall()
print(f"\n价格最高的5只股票:")
for stock in top_stocks:
market, code, name, price, change = stock
print(f" {market}-{code}-{name}: {price:.2f}元 ({change:+.2f}%)")
conn.close()
print(f"\n数据抓取完成!总计 {sum([count for _, count in stats])} 条数据")
if __name__ == "__main__":
get_stock_data()

作业心得
通过开发股票数据爬虫,掌握了金融API的调用技巧和数据存储方法,实现了从数据采集、格式化处理到本地存储的完整流程,为量化分析打下了坚实的数据基础。
https://gitee.com/chen-caiyi041130/chen-caiyi/tree/master/作业2
第三题
核心代码和运行结果
点击查看代码
import requests
import sqlite3
import ast
import re
def match_brackets(text, start, left_char, right_char):
"""匹配括号对"""
level = 0
in_string = False
escape = False
left_pos = start
for i in range(start, len(text)):
char = text[i]
if in_string:
if escape:
escape = False
elif char == "\\":
escape = True
elif char == '"':
in_string = False
else:
if char == '"':
in_string = True
elif char == left_char:
level += 1
if level == 1:
left_pos = i
elif char == right_char:
level -= 1
if level == 0:
return left_pos, i
raise ValueError("括号不匹配")
def get_param_mapping(js_code):
"""获取参数映射关系"""
func_start = js_code.find("(function(")
param_end = js_code.find(")", func_start + 10)
param_names = [p.strip() for p in js_code[func_start + 10:param_end].split(",") if p.strip()]
body_start = js_code.find("{", param_end)
body_start, body_end = match_brackets(js_code, body_start, "{", "}")
arg_pos = body_end + 1
while arg_pos < len(js_code) and js_code[arg_pos].isspace():
arg_pos += 1
arg_start, arg_end = match_brackets(js_code, arg_pos, "(", ")")
arg_text = js_code[arg_start + 1:arg_end]
processed_args = (arg_text.replace("true", "True")
.replace("false", "False")
.replace("null", "None")
.replace("void 0", "None"))
arg_values = ast.literal_eval("[" + processed_args + "]")
mapping_size = min(len(param_names), len(arg_values))
return {param_names[i]: arg_values[i] for i in range(mapping_size)}
def get_object_at_position(text, position):
"""获取指定位置的完整对象"""
i = position
while i > 0 and text[i] != '{':
i -= 1
start, end = match_brackets(text, i, "{", "}")
return text[start:end + 1]
def get_value_by_key(obj_text, key_name):
"""根据键名获取值"""
key_pos = obj_text.find(key_name)
if key_pos < 0:
return None
colon_pos = obj_text.find(":", key_pos)
value_start = colon_pos + 1
while value_start < len(obj_text) and obj_text[value_start].isspace():
value_start += 1
if value_start >= len(obj_text):
return None
if obj_text[value_start] in "\"'":
quote_char = obj_text[value_start]
value_end = value_start + 1
escaped = False
while value_end < len(obj_text):
current_char = obj_text[value_end]
if escaped:
escaped = False
elif current_char == "\\":
escaped = True
elif current_char == quote_char:
return obj_text[value_start + 1:value_end]
value_end += 1
return None
value_end = value_start
while value_end < len(obj_text) and obj_text[value_end] not in ",}\r\n\t ":
value_end += 1
return obj_text[value_start:value_end]
def map_variable(var_name, var_map):
"""映射变量名到实际值"""
if var_name is None:
return ""
return str(var_map.get(var_name, var_name))
def check_numeric(value):
"""检查是否为数字"""
try:
float(value)
return True
except:
return False
def get_school_info():
"""获取学校信息"""
data_url = "https://www.shanghairanking.cn/_nuxt/static/1760667299/rankings/bcur/202011/payload.js"
response = requests.get(data_url)
js_data = response.text
print("解析数据中...")
var_mapping = get_param_mapping(js_data)
print(f"建立 {len(var_mapping)} 个变量映射")
school_list = []
search_pos = 0
while True:
search_pos = js_data.find('univNameCn', search_pos)
if search_pos == -1:
break
obj_content = get_object_at_position(js_data, search_pos)
name = get_value_by_key(obj_content, 'univNameCn')
rank = get_value_by_key(obj_content, 'ranking')
area = get_value_by_key(obj_content, 'province')
school_type = get_value_by_key(obj_content, 'univCategory')
points = get_value_by_key(obj_content, 'score')
school_name = map_variable(name, var_mapping)
rank_num = map_variable(rank, var_mapping)
area_name = map_variable(area, var_mapping)
type_name = map_variable(school_type, var_mapping)
score_num = map_variable(points, var_mapping)
if school_name and rank_num.isdigit() and check_numeric(score_num):
school_list.append({
'position': int(rank_num),
'name': school_name,
'region': area_name,
'category': type_name,
'total_score': float(score_num)
})
search_pos += 1
print(f"找到 {len(school_list)} 所学校")
return school_list
def store_school_data(schools):
"""存储学校数据"""
db_conn = sqlite3.connect('school_data.db')
db_cursor = db_conn.cursor()
db_cursor.execute('''
CREATE TABLE IF NOT EXISTS school_info (
position INTEGER,
name TEXT,
region TEXT,
category TEXT,
total_score REAL
)
''')
db_cursor.execute("DELETE FROM school_info")
for school in schools:
db_cursor.execute(
"INSERT INTO school_info VALUES (?, ?, ?, ?, ?)",
(school['position'], school['name'], school['region'],
school['category'], school['total_score'])
)
db_conn.commit()
db_conn.close()
print(f"存储 {len(schools)} 条记录")
def show_results(schools, show_count=20):
"""显示结果"""
print(f"\n{'位次':<6} {'名称':<20} {'地区':<10} {'类别':<8} {'得分':<8}")
print("-" * 60)
for school in sorted(schools, key=lambda x: x['position'])[:show_count]:
print(f"{school['position']:<6} {school['name']:<20} "
f"{school['region']:<10} {school['category']:<8} "
f"{school['total_score']:<8.1f}")
if __name__ == "__main__":
try:
school_data = get_school_info()
if school_data:
store_school_data(school_data)
show_results(school_data)
print(f"\n完成!共处理 {len(school_data)} 所学校")
else:
print("没有获取到数据")
except Exception as error:
print(f"出错: {error}")
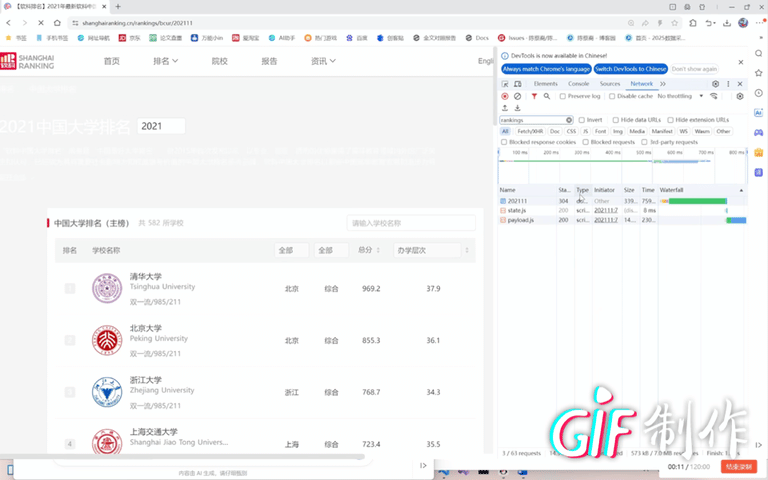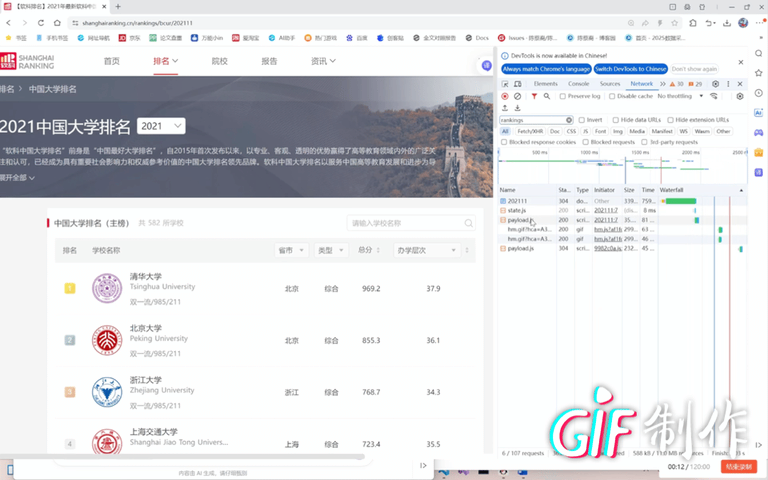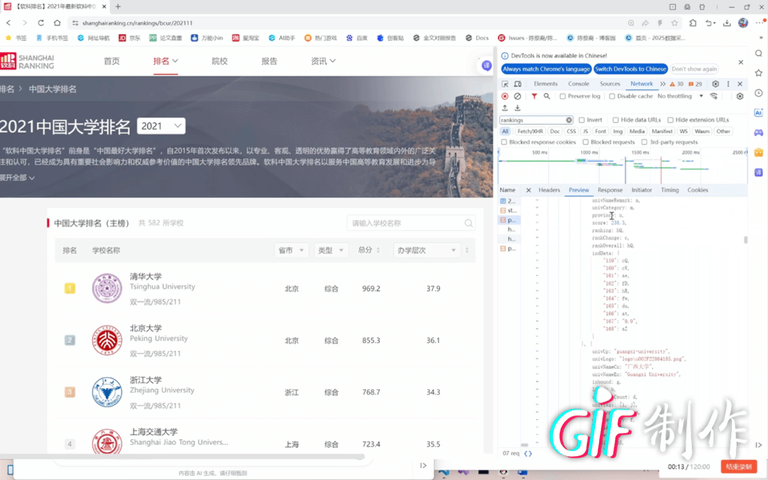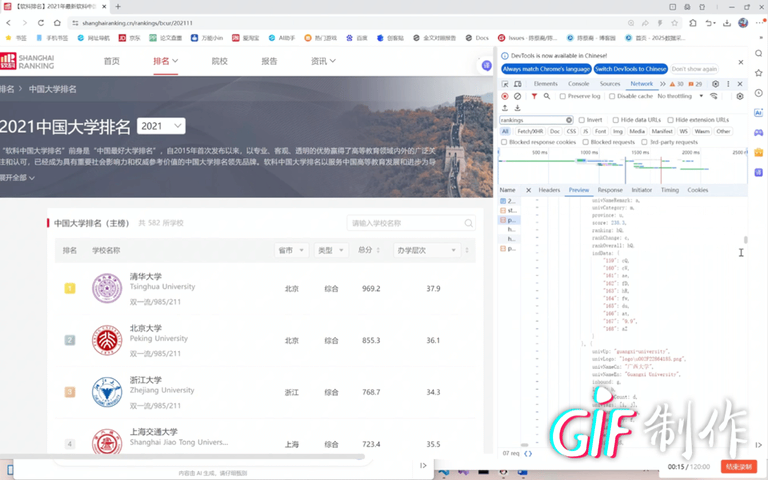

作业心得
通过这次爬虫实践,深刻体会到处理复杂数据结构时需要跳出常规思维。面对Nuxt的JSONP格式,直接解析会陷入变量代号的迷宫。关键在于先建立形参-实参的映射关系,将抽象代号转换为具体值,再逐个提取对象数据。这种"先解码再解析"的思路,比单纯依赖正则表达式更加稳健有效。
https://gitee.com/chen-caiyi041130/chen-caiyi/tree/master/作业2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号