
20191108 实验四《Python程序设计》实验报告
20191108 2019-2020-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1911
姓名: 朱家婧
学号:20191108
实验教师:王志强
实验日期:2020年5月21日
必修/选修: 公选课
1.实验内容:
使用Python进行网页内容爬取
3. 实验过程及结果
1.找到需要处理的网页,然后查看这个网页的源代码,观察需要的数据在哪个位置
2.在浏览器中查看当前网页的Html源码,我们找到每个主播的名字和视频的浏览量
比如:

3.编程实现获取Html标签里的数据,并将其重新整理后打印显示
from urllib import request
import re
class Spider():
#需要抓取的网络链接
url = "https://www.panda.tv/cate/kingglory"
reString_div = '<div class="video-info">([\s\S]*?)</div>'
#获取主播名
reString_name = '</i>([\s\S]*?)</span>'
#取视频浏览量
reString_number = '<span class="video-number">([\s\S]*?)</span>'
def __fetch_content(self):
r = request.urlopen(Spider.url)
data = r.read()
htmlString = str(data,encoding="utf-8")
return htmlString
def __alalysis(self,htmlString):
videoInfos = re.findall(Spider.reString_div,htmlString)
anchors = []
#print(videoInfos[0])
for html in videoInfos :
name = re.findall(Spider.reString_name,html)
number = re.findall(Spider.reString_number,html)
anchor = {"name":name,"number":number}
anchors.append(anchor)
#print(anchors[0])
return anchors
def __sort(self,anchors):
#按浏览量从大到小排序
anchors = sorted(anchors,key=self.__sort_seed,reverse = True)
return anchors
def __sort_seed(self,anchor):
list_nums = re.findall('\d*',anchor["number"])
number = float(list_nums[0])
if '万' in anchor["number"]:
number = number * 10000
return number
def __show(self,anchors):
#打印数据
for rank in range(0,len(anchors)):
print("第" + str(rank+1) +"名 " + anchors[rank]["number"] + "\t" + anchors[rank]["name"])
def startRun(self):
#运行程序入口
htmlString = self.__fetch_content()
anchors = self.__alalysis(htmlString)
anchors = self.__refine(anchors)
anchors = self.__sort(anchors)
self.__show(anchors)
#爬取数据
spider = Spider()
spider.startRun()
结果:
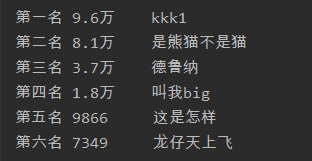
参考资料
附码云链接:
课程感悟:
在整学期Python课程的学习过程中,困扰最多的不是程序代码是设计和实践,而是各种安装和配置的问题,从一开始安装Python和Pycharm,到后来git怎么也成功不了,到最后socket的配置怎么也不成功,一路坎坷,而因为疫情不能当面请教老师又给解决这些问题带来了更大的麻烦。所以,我最深的感悟是,自我学习的能力很重要,很多问题别人是解决不了的,只有靠自己摸索;然后就是不能放弃,有写东西你今天做不成,不妨放一放,但不是放弃,应该明天再拿出来做,只要有空就去做,做成为止。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号