软工实践寒假作业(2/2)
软工实践寒假作业(2/2)
总览和相关链接
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 1、重读阅读之法提出问题 2、熟悉git的使用 3、编写字符统计程序<br /4、学会单元测试 5、学会性能测试 |
| 其他参考文献 | allure docs pytest docs 计算单元测试代码覆盖率(pytest-cov) 廖雪峰-单元测试 知乎-单元测试是什么 python3-cookbook-给你的程序做性能测试 |
任务一 重新阅读《构建之法》并提问
在这个内卷化日益严重的年代我们是否要跟着一起内卷
当初选择软件工程的原因是因为兴趣,但是为了未来的工作,我现在也需要和别人一起内卷,但是这样我选择软件工程的初衷也没了,可以预见的是这样内卷下去,我的激情会消耗殆尽,而且甚至因为996,007工作的原因而进入不健康的状态。
问题来源:
21世纪以来,中国大陆每年招收六百万大学生,其中的百分之十是在学习各种IT
相关的专业(计算机科学与技术、计算机工程、计算机软件、软件工程、管理信
息系统等)。扣除读研究生(最终大部分也会走上工作岗位)、出国等分流,同
时考虑到培训机构给就业市场贡献的大量劳动力,每年大致有四十万到六十万左
右的“职业软件工程师”进入工作岗位。
如何选择自己的发展方向
正如书中所说绝大部分软件工程师都不是技术天才,那么我们应该如何选择自己的发展方向,或者说如何发现自己在软件工程中的长处
问题来源:
并不是每个软件工程师都有强烈的愿望或机遇去做最先进、最创新、最有风险的
项目。绝大部分软件工程师都不是技术天才,但即使是一般的工程师,做一般的
信息系统,就是业界说的“CRUD”(Cre-ate/Retrieve/Update/Delete,增删改
查)数据库系统,也需要一些核心技术和许多扩展的知识
如何解决课外实践与课内学习的冲突
我们如何划分课内学习的时间和课外实践的实践,有时候课外实践占用的实践太多影响到了课内学习,我们应该如何把握?
如果实践太少的话,毕业出去就被卷没了,如果太多的话,我们的基础知识就不牢靠了,基础知识是我们以后发展的根基也不能轻易忽视。
问题来源:
很少有人能在学校里掌握这么多知识后才毕业找工作,随后把技术运用在实践
中。工程师应该在实际工作中不断学习和不断成长,根据自己的情况选择在哪个
方面追求“专和精”,在哪几个方面达到“知道就好”的水平
现在有那么多种语言,我们如何选择一种语言作为自己的主攻方向
想要做到文章说的大脑自动操作,这无疑是需要大量的时间和实践,而到现在为止我接触到的语言有python,php,java,go,c,c++,c#,js,shell,powershell,bat,vb,ruby,而这些语言我都无法做到大脑自动操作,总是这个学学那个学学,不知道以哪个为重点,有时要求这个,有时要求那个,那么我们如何选择一门语言作为自己的主攻方向。
问题来源:
我要查一查……你发现他把时间都花在“解决(低层次)问题”上了,你想考察
的“算法技能”、“C#程序设计技能”都无暇顾及。注意,这是在他认为非常精通的
编程工具和编程语言中出现这样的问题。你要这样的员工么?那怎么提高技能
呢?答案很简单,通过不断的练习,把那些低层次的问题都解决了,变成不用经
过大脑的自动操作,然后才有时间和脑力来解决较高层次的问题。
我们如何才能进入团队,而不是被当成完成工作就领钱的乌合之众?
我在网上看的一些帖子,很多时候都体现了与公司对立的情绪,很多人都说公司不把程序员当人看,996,007压榨,严重的甚至有一些人选择了轻生或者是猝死了,我们在未来找工作的时候无疑会遇到这样的公司,那么我们如何鉴别出他们呢,如何知道他们团队的工作氛围,公司内部真的是一个团队一起工作学习吗?
问题来源:
大智冲这些人喊了一嗓子:搬砖的有没有?一百块砖一毛钱!地上蹲着的一些人
抬头看了看,有一两个人慢慢站起来了。大智看了看人数,又喊了一声:中午有
盒饭!这时七八个人都站起来了,拍拍屁股就凑到大智面前。大智就带着他们走
了。这七八个人是团队(Team)么?不是,他们只是一群乌合之众,临时聚集
在一起,各自完成任务就领钱走人
任务二:完成词频统计个人作业
作业描述
在大数据环境下,搜索引擎,电商系统,服务平台,社交软件等,都会根据用户的输入来判断最近搜索最多的词语,从而分析当前热点,优化自己的服务。
首先当然是统计出哪些词语被搜索的频率最高啦,请设计一个程序,能够满足一些词频统计的需求。
1、项目github链接
https://github.com/ccreater222/PersonalProject-Java
2、PSP表格
| 英 | 中 | 预估耗时 | 实际耗时 |
|---|---|---|---|
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
| Planning | 计划 | 15min | 10min |
| • Estimate | • 估计这个任务需要多少时间 | 15min | 10min |
| Development | 开发 | 3h | 5h |
| • Analysis | • 需求分析 (包括学习新技术) | 1h | 1h |
| • Design Spec | • 生成设计文档 | 5min | 5min |
| • Design Review | • 设计复审 | 5min | 5min |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 5min | 5min |
| • Design | • 具体设计 | 15min | 15min |
| • Coding | • 具体编码 | 1h | 3h |
| • Code Review | • 代码复审 | 30min | 30min |
| • Test | • 测试(自我测试,修改代码,提交修改) | 1h | 1h |
| Reporting | 报告 | 2h | 2h |
| • Test Repor | • 测试报告 | 15min | 15min |
| • Size Measurement | • 计算工作量 | 15min | 15min |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 1.5h | 1.5h |
| 合计 | 5h15min | 7h15min |
3、设计思路
需要实现的功能有4个:
- 统计字符数
- 统计单词数
- 统计最多的10个单词及其词频
- 统计行数
还有就是要求API设计
统计字符数的另一个意思就是字符串长度,利用len(string)来解决
统计单词数和统计最多的10个单词及其词频他们的设计是相似的,在完成统计单词数的同时也可以同时完成词频统计以节约算力,使用re.findall来获取合法单词
统计行数有一个难点就是换行符的问题,可以将\r,\r\n都转化为\n方便统计,还有就是空行的问题,我们将空白字符剔除后自然就可以轻易的计算出行数
4、代码规范
缩进:4个空格
变量命名:变量采用下划线命名
每行最多字符数:120
函数最大行数:500
函数、类命名:函数采用驼峰命名,类也采用驼峰命名但第一个字母需要大写
常量:全部大写
空行规则:每个函数和类之间需要空行
注释规则:标注函数和类的参数及作用
操作符前后空格:1个
5、计算模块接口的设计与实现过程
计算模块接口的设计
将所有的功能都封装在了WordCount这个类中
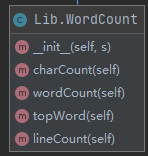
实现细节
charCount
对字符串去长度就可以了:len(s)
lineCount
去除空白字符
spaces = "\f\t\v\b"
for space in spaces:
s = s.replace(space, "")
换行符统一化
s = s.replace("\r", "\n")
while True:
tmp = s.replace("\n\n", "\n")
if tmp == s:
break
s = tmp
函数统计:
s.count("\n") + 1
wordCount
在wordCount中使用正则获取了所有合法的单词
s = s.lower()
self.words = re.findall("([a-z]{4,}[a-z0-9]*)", s)
调用len(self.words)就可以得到单词数
topWord
在topWord中使用了wordCount中得到的words,如果为空则会去调用wordCount
调用count函数来统计单词数的多少
for key in keys:
count.append([key, self.words.count(key)])
调用sort函数来实现排序:count.sort(key=lambda a: a[1], reverse=True)
但是我们在面对频率相同的单词要如何处理呢
这里我选择了在排序前创建一个统计列表的副本,根据排序后的结果,去统计列表找查找频率相同的单词,这样就可以实现在频率相同时根据先后顺序来排序
result = []
for c in count:
for c2 in count2:
if c[1] == c2[1] and c2 not in result:
result.append(c2)
count2.remove(c2)
break
if len(result) == 10:
break
6、性能改进
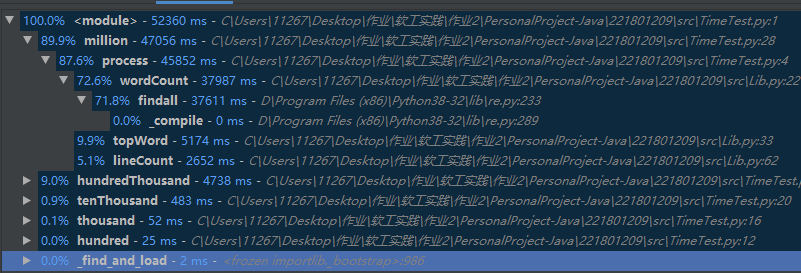
通过性能测试结果我们很容易得知re.find_all是主要的耗时操作,于是我去除了wordCount中可能出现重复调用re.find_all的可能性
如果self.words存在就不会去调用re.find_all,避免了先调用topWord再调用wordCount导致的重复re.find_all调用
7、单元测试
单元测试使用pytest,结果展示使用allure
构造测试数据的思路:首先明确一个函数的功能,接着我是先对所有功能使用一组正常数据测试,再对着每个功能挑刺
7.1、测试获取字符数测试
@allure.story('字符数统计')
def testCharCount(self):
s = string.ascii_letters + string.digits + string.whitespace
wc = WordCount(s)
self.assertEqual(wc.charCount(), len(s))
测试了所有可打印字符
7.2、测试行数测试
@allure.story('行数统计')
def testLineCount(self):
cases = [
["a\ra", 2], # \r换行
["a\r\na", 2], # \r\n换行
["a\na", 2], # \n换行
["a\n\na", 2], # 一个空行
["a\n\b\na", 2], # 一个带有空白字符的空行
["a\f\n\r\t\v\b\na", 2], # 一个带有所有空白字符的空行
]
for case in cases:
wc = WordCount(case[0])
self.assertEqual(wc.lineCount(), case[1],
msg="\ncase index:" + str(cases.index(case)) + " \ntext:\n" + case[0] + "\nresult:" + str(
case[1]))
7.3、获取单词总数和获取频率最高十个词测试
@allure.story('单词数统计')
def testWordCount(self):
cases = []
with open("test.json", "r", encoding="utf-8") as f:
cases = json.loads(f.read())
for case in cases:
wc = WordCount(case["str"])
self.assertEqual(wc.wordCount(), case["word"],msg=" \ntext:\n" + case["str"] + "\nresult:" + str(
case["word"]))
获取频率最高十个词测试的测试函数也是类似的
测试数据及描述
[
{
"str": "a abc123 abcd abcd123 1234",
"desc": "至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割"
},
{
"str": "ABCD AbCd abcd",
"desc": "不区分大小写"
},
{
"str": "a-abc123=abcd*abcd123/1234",
"desc": "单词以分隔符分割,测试特殊字符"
},
{
"str": "abcd1 abcd1 abcd2",
"desc": "只输出频率最高的10个"
},
{
"str": "abcd1 abcd3 abcd2 ABcd4",
"desc": "频率相同的单词,优先输出字典序靠前的单词"
},
{
"str": "ABCD",
"desc": "输出的单词统一为小写格式"
},
{
"str": "abcd1 abcd2 abcd3 abcd4 abcd5 abcd6 abcd7 abcd8 abcd9 abcd10 abcd11",
"desc": "只输出频率最高的10个"
}
]
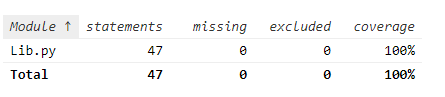
7.4、覆盖率截图
8、异常处理说明
当字符统计对象不为字符串是的错误处理
if not type(s) == str:
raise TypeError("请传入一个字符串")
当输入文件不存在时的错误处理
try:
with open(sys.argv[1], "r", encoding="utf-8") as f:
s = f.read()
except FileNotFoundError:
print("File not found:" + sys.argv[1])
exit()
9、心路历程与收获
学会了单元测试和性能测试
通过性能测试我们可以轻松的定位到耗时函数,通过优化耗时函数,从而提高效率
开始打算养成良好的代码规范习惯

 浙公网安备 33010602011771号
浙公网安备 33010602011771号