1 #字典排序使用到的函数具体是sorted() 2 #按key排序 3 dict1={"name":"cch","age":"3","sex":"girl","height":"1.65"} 4 data=dict(sorted(dict1.items(),key=lambda item:item[0])) 5 print(data) 6 #按value排序 7 dict1={"name":"cch","age":"3","sex":"girl","height":"1.65"} 8 data1=dict(sorted(dict1.items(),key=lambda item:item[1])) 9 print(data1)
1 #字符串格式化使用的是format关键字,例如: 2 name=(input("what is your name?\n")) 3 sex=bool(input("what is your sex?\n")) 4 age=int(input("how old are you?\n")) 5 salary=float(input("what is your salary?")) 6 print() 7 print("my name is {username},and my sex is {sex},and my age is {age},and my salary is {salary}.").format(username=name,sex=sex,age=age,salar=salary)
1 #append:添加的元素默认在列表的最后一位 2 #insert:可以指定元素添加的位置 3 list1=["Java","Python","Go"] 4 list1.append("Net") 5 print(list1) 6 7 list1.insert(0,"C") 8 print(list1)
查看一个对象的类型关键字是type,查看对象的内存地址关键字是id.
1 #使用关键字enumerate 2 str1='dgknfndhjs' 3 for index,item in enumerate(str1): 4 print(index,item)
data=[x for x in range(10)]
当元组只有一个对象的时候,需要注意加逗号。
1 #字符串转换为列表 2 str1="ggdjh,fgdsh,fhdhgh" 3 str_list=str1.split(',') 4 print(str_list) 5 print(type(str_list)) 6 #列表转换为字符串 7 list_str=','.join(str_list) 8 print(list_str) 9 print(type(list_str))
1 #字符串的替换使用的方法是replace 2 str1="ggdjh,fgdsh,fhdhgh" 3 str2=str1.replace('fgdsh','Python') 4 print(str2)
''' is是对于两个对象的内存地址的比较; in是指一个对象包含在另一个对象里; ==是对两个对象的内容和类型的比较 '''
解答:列表与的区别是列表是列表是可变的,可以增加和删除元素,但是元组是不可变的(元组的结构是不可变的),只能获取和修改元组的值。
1 list1=["C","Java","Python","Go"] 2 list1.append("Net") #在列表最后增加一个为“Net”的元素 3 print(list1) 4 list1.pop() #删除列表最后一个元素 5 print(list1.pop()) #返回列表删除的最后一个元素 6 print(list1) 7 list1.insert(0,"Net") #指定在列表中索引号为0的为止增加“Net”元素 8 print(list1) 9 list1.remove("C") #指定删除列表中为“C”的元素 10 print(list1) 11 12 tuple1=({"C":0,"Java":1,"Python":2},[1,2,3]) 13 print(tuple1[0]["Python"]) #获取元组中第一个元素的"Python"的值 14 tuple1[1][1]="middle" #修改元组中第二个元素的中的“2”的值为“middle” 15 print(tuple1)
以上代码的执行结果为:
![]()
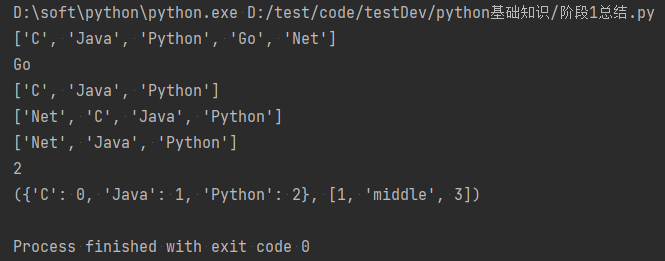
解答:字典的有序
1 from collections import OrderedDict 2 data1=OrderedDict() 3 data1["name"]="cch" 4 data1["age"]=18 5 data1["city"]="宝鸡" 6 print(dict(data1))
以上代码的执行结果为:
![]()

字典的排序
1 dict1={"name":"cch","age":"18","city":"宝鸡"} 2 #按key排序 3 data=dict(sorted(dict1.items(),key=lambda item:item[0])) 4 print(data) 5 #按value排序 6 data=dict(sorted(dict1.items(),key=lambda item:item[1])) 7 print(data)
以上代码的执行结果为:
![]()

解答:
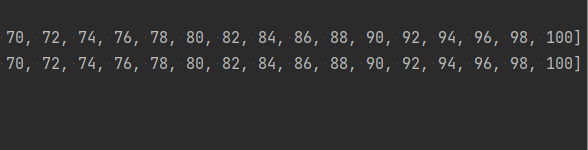
1 data=[x for x in range(101) if x %2==0] #方法一 2 print(data) 3 data=[x for x in range(0,101,2)] #方法二 4 print(data)
以上代码的运行结果为:
![]()

A、学生最大,最小,平均成绩
B、过滤出成绩大于等于60的学生成绩
C、过滤出成绩小于60分的
dict1={'status':0,'msg':'msg','data':[
{'name':"lisi","score":"90"},
{'name':"wangwu","score":"60"},
{'name':"lisi1","score":"88"},
{'name':"lisi2","score":"59"},
{'name':"lisi3","score":"24"},
{'name': "lisi4", "score": "66"},
{'name': "lisi5", "score": "70"},
{'name': "lisi6", "score": "45"},
{'name': "lisi7", "score": "39"}
]}
解答:
1 dict1={'status':0,'msg':'msg','data':[ 2 {'name':"lisi","score":"90"}, 3 {'name':"wangwu","score":"60"}, 4 {'name':"lisi1","score":"88"}, 5 {'name':"lisi2","score":"59"}, 6 {'name':"lisi3","score":"24"}, 7 {'name': "lisi4", "score": "66"}, 8 {'name': "lisi5", "score": "70"}, 9 {'name': "lisi6", "score": "45"}, 10 {'name': "lisi7", "score": "39"} 11 ]} 12 13 score=[] 14 for item in dict1["data"]: 15 score.append(int(item["score"])) 16 print(score) 17 maxScore=print("最高分:",max(score)) 18 minScore=print("最低分:",min(score)) 19 averageScore=print("平均分:",sum(score)/len(score)) 20 data=list(filter(lambda a:a>=60,[x for x in score])) 21 print("成绩大于等于60的:",data) 22 data=list(filter(lambda a:a<60,[x for x in score])) 23 print("成绩小于60的:",data)
以上代码的运行结果为:
![]()

解答:
1 def func(): 2 return "好好学习python" 3 print(func())
以上代码的运行结果为:

解答:序列化就是把python中的对象(列表,元组,字典)转化为字符串的过程,反序列化就是把字符串转化为python中的对象。
1 #字典序列化与反序列化 2 import json 3 dict1={"name":"cch","age":18,"city":"宝鸡"} 4 dict_str=json.dumps(dict1,indent=True,ensure_ascii=False) 5 print(dict_str) 6 print(type(dict_str)) 7 str_dict=json.loads(dict_str,encoding="utf-8") 8 print(dict_str) 9 print(type(str_dict)) 10 #文件序列化与反序列化 11 import json 12 dict1={"name":"cch","age":18,"city":"宝鸡"} 13 json.dump(dict1,open(file="json.txt",mode="w",encoding="utf-8"),ensure_ascii=False) #进行文件写入操作时,ensure_ascii=False可防止中文乱码 14 data=json.load(open(file="json.txt",mode="r",encoding="utf-8")) 15 print(data) 16 print(type(data))
以上代码的运行结果为:
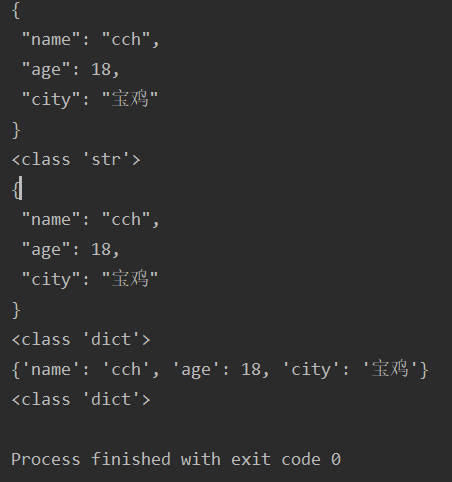
解答:
1 import datetime 2 print("获取当前时间为:",datetime.datetime.now())
以上代码的运行结果为:

解答:
1 def readFile(): 2 with open(file="log.txt",mode="r",encoding="utf-8") as f: 3 print(f.read()) 4 readFile() 5 6 def writeFile(): 7 with open(file="log.txt",mode="w",encoding="utf-8") as f: 8 print(f.write("好好加油")) 9 writeFile()
以上代码的运行结果为:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号