
KMP算法
1 void Solution::KMPSearch(string pat, string txt) 2 { 3 int M = pat.length(); 4 int N = txt.length(); 5 int lps[M]; // 记录最长的相同的前缀后缀的长度 6 computeLPSArray(pat, lps); 7 8 int i = 0; 9 int j = 0; 10 while(i < N) 11 { 12 if(pat[j] == txt[i]) 13 { 14 i++; 15 j++; 16 } 17 if(j == M) 18 { 19 cout << "Found pattern at index " << i-j << endl; 20 j = lps[j-1]; 21 } else if(i < N && pat[j] != txt[i]) 22 { 23 if(j != 0) 24 j = lps[j-1]; 25 else 26 i++; 27 } 28 } 29 30 } 31 32 33 void Solution::computeLPSArray(string pat, int* lps) 34 { 35 int M = pat.length(); 36 int i = 1; 37 int len = 0; 38 lps[0] = 0; 39 40 while(i < M) 41 { 42 if(pat[i] == pat[len]) 43 { 44 len++; 45 lps[i] = len; 46 i++; 47 } 48 else 49 { 50 if(len != 0) 51 { 52 len = lps[len-1]; 53 } 54 else 55 { 56 lps[i] = 0; 57 i++; 58 } 59 } 60 } 61 }
假设你对KMP算法有了解但感到困惑,本文不解释KMP算法的定义。
之前查找资料的时候看到长篇大论的,所以看都不想看,结果自己想表达出来时。。。也变得长篇大论了
详细说一下KMP算法,刚看到的时候一头雾水,想不明白lps[]这个数组的作用,以及实现。
在说明lps[]之前先说明一下最长的相同的前缀后缀的意思
比如字符串:"ababab"
前缀:"ababa", "abab", "aba" ,"ab", "a", "",
后缀:"babab", "abab", "bab", "ab", "b", "",
可以观察到最长的相同的前缀后缀在这里为"abab",长度为4
lps[]的作用就是记录字符串的最长的相同的前缀后缀的长度,这里长度为4,所以lps[5] = 4,
数组下标为5是因为字符串"ababab"的最后一个字符"b"的下标为5.(这里先不考虑lps[]是怎么实现的,明白它代表的意思就行了,后面会说明怎么实现的)
当我们知道最长的相同的前缀和后缀的长度,我们能用它来干什么呢?
“abab" 的最长的相同的前缀后缀为"ab",长度为2
所以"abab"的前2位 和 后2位相同
前缀: (ab) ab
后缀:ab (ab)
假如当我们匹配两个字符串
pat = "abab" , txt = "ababac"
当第一次完全匹配时
a b a b a c
a b a b
此时i = 4, j = 4,根据算法此时打印找到的第一个下标,然后让j = lps[j-1] >> j = lps[3]
lps[3]保存的是"abab"的最长的相同的前缀后缀的长度,这里为”ab",所以长度为2,所以 j = 2;
因为在txt”ababab"找到的第一个字符串"abab"包含了要找的字符串"abab"的后两位“ab”,
而我们要找的字符串“abab”的前两位是"ab",所以我们可以直接跳过前两位,而从第三位字符"a"开始对比
因为"ab"长度为2,所以它的下一位的下标j应该为2,所以下一次循环为 if(pat[j] == txt[i]) >> if(pat[2] == txt[4]);
txt:a b (a b) a c
pat: (a b) a b
pat index 0 1 2 3
KMP算法的核心是从已知的信息取出对我们有用的信息,比如上面我们已知匹配到txt的前四位"abab",而其中的后两位"ab"则是对我们下一次匹配的有用信息
我们利用这个有用信息从而可以跳过下一次对pat的前两位"ab"的匹配,因为它已经与txt“abab”的后两位相配对。
lps[]的实现也利用了这种思想
lps[M]是记录字符串第i位(0 <= i < M)的最长的相同的前缀后缀的长度
lps[0] = 0; // 因为一个字符串的第0位记录的前缀后缀为“”的长度
这里我们通过例子来说明lps[]的实现
为什么当if(pat[i] == pat[len]) 不为真,且len != 0 时,让 len = lps[len-1]呢?
我们明白这一点之后就会明白lps[]怎么实现了
假如 pat = "aaacaaaa"
lps[8] = {0, 1, 2, 0, 1, 2, 3, 3}
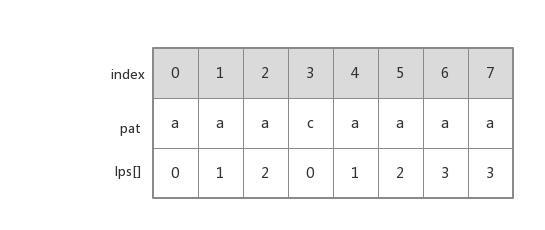
当我们求lps[7]的时候,我们要用到已知的"aaacaaa"的len = lps[6] = 3,
我们让最后一位"a"与第四位(下标为len, 3)的"c"对比,此时我们发现并不相等,所以我们让 len = lps[len-1] ==> len = lps[2] ==> len = 2
为什么要len-1呢?因为我们要取得前缀长度为3的lps[]的值,可以发现前缀是由前往后增长的,所以当len为3的时候,它表示的是前三个字符是前缀,这里是"aaa",我们获取第三个字符的下标len-1
所以令len = lps[len-1] ==> len = 2,由上面已知 pat[0-2] = pat[4-6], pat[0-1] = pat[1-2],所以我们得出pat[0-1] = pat[5-6], 所以此时如果 if(pat[i] == pat[len]) ==> if(pat[7] == pat[2]) 为真的话,就说明了pat[0-2] = pat[5-7],所以lps[7] = 3
假设这里不为真就继续让len = lps[len-1] ,直至0,道理都是一样的。
这里是比较让人感到困惑的一点
明白了这个,你就会明白为什么
if(j != 0)
j = lps[j-1];

 浙公网安备 33010602011771号
浙公网安备 33010602011771号