爬取3DM游戏排行榜
一、选题背景
当今社会,电子游戏作为大家的一种娱乐消遣的方式,所占的比重也是越来越大。特别是从2020年疫情爆发开始,电子游戏作为一种在家的娱乐方式,越来越受到大家的喜爱。
从经济方面来说,互联网的用户越来越多,大家对于正版的版权意识也愈发提高,愿意对正版游戏进行消费,促进了游戏厂商的积极性,而游戏排行榜可以给厂商明白的消费者的喜好,对厂商的开发起了重要的作用。
同时游戏排行榜,也是消费者的风行指标,让消费者可以更好的进行选择。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取3DM单机游戏排行榜
2.主题式网络爬虫爬取的内容与数据特征分析:利用3DM单机游戏排行榜中的游戏名称,游戏排名,评分以及评论数。通过pandas,matplotlib进行可视化数据分析。
3. 主题式网络爬虫设计方案概述:爬取网页再进行数据采集并清洗,最后对可视化数据进行分析。
三、 主题页面的结构特征分析
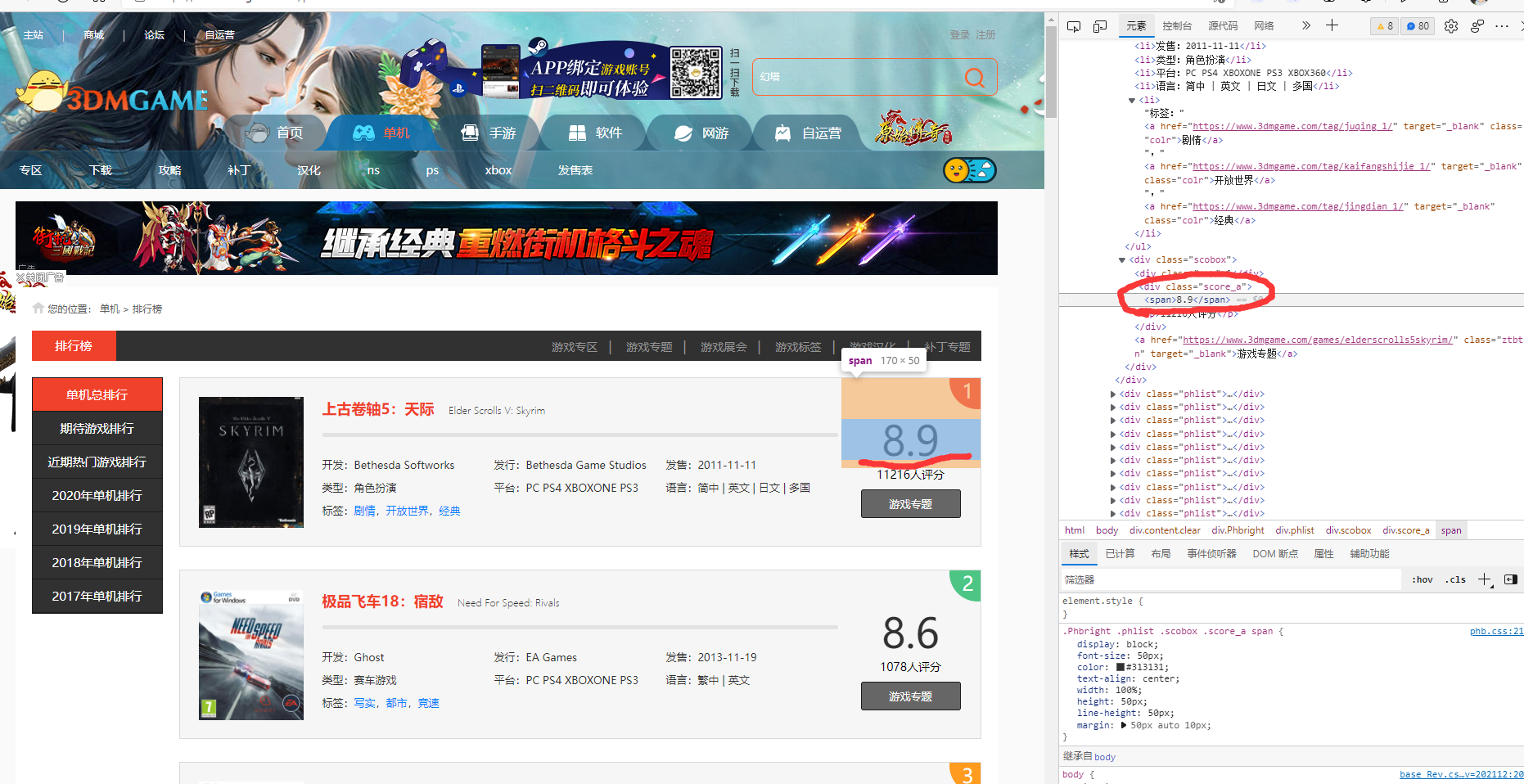
通过浏览器的开发工具,进行元素查找,如图所示,查找到需要的标签。
四、网络爬虫程序设计
1.数据爬取与采集
1 1 #爬取网站 2 2 import requests 3 3 from bs4 import BeautifulSoup 4 4 import pandas as pd 5 5 from matplotlib import pyplot as plt 6 6 from sklearn.linear_model import LinearRegression 7 7 import seaborn as sns 8 8 from scipy.optimize import leastsq 9 9 url='https://www.3dmgame.com/phb.html' 10 10 headers={'user-Agent':url} 11 11 r=requests.get(url,headers=headers) 12 12 r.raise_for_status() 13 13 r.encoding=r.apparent_encoding 14 14 #print(r.text) 15 15 soup=BeautifulSoup(r.content,'html.parser') 16 16 print(soup)
1 #抓取数据 2 soup=BeautifulSoup(r.content,'html.parser') 3 a1=soup.find_all('div',{'class':'score_a'}) 4 score=[] 5 vote=[] 6 for i in a1: 7 score.append(i.find('span').string) 8 vote.append(i.find('p').string) 9 print(score) 10 print(vote) 11 name=[] 12 a2=soup.find_all('div',{'class':'bt'}) 13 for i in a2: 14 name.append(i.find('span').string) 15 rank=[] 16 for i in range(1,31): 17 rank.append(i) 18 i=float(i) 19 print(rank)


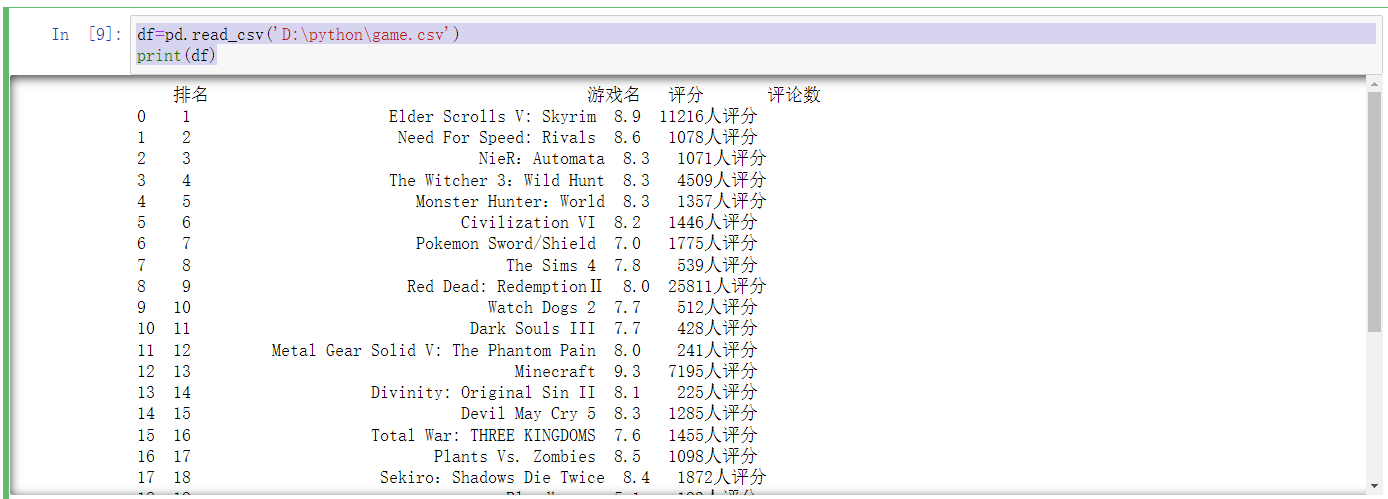
#数据采集 import pandas as pd df=pd.DataFrame({'排名':rank,'游戏名':name,'评分':score,'评论数':vote}) df.to_csv('D:\python\game.csv',index=False) df=pd.read_csv('D:\python\game.csv') print(df)
2.数据清理
1 #数据清洗 2 #查找重复值 3 print(df.duplicated())

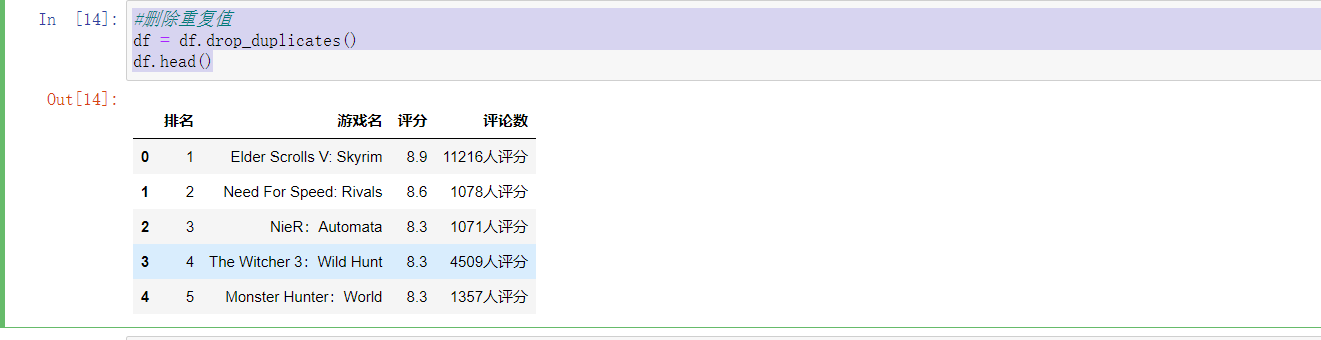
#删除重复值 df = df.drop_duplicates() df.head()
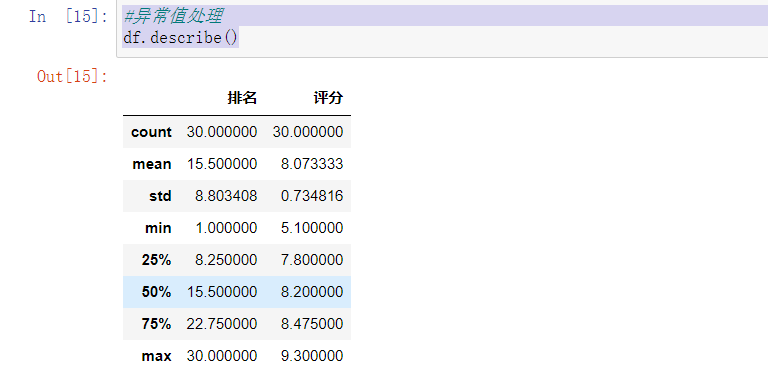
#异常值处理 df.describe()
#检查是否有空值 print(df['游戏名'].isnull().value_counts())

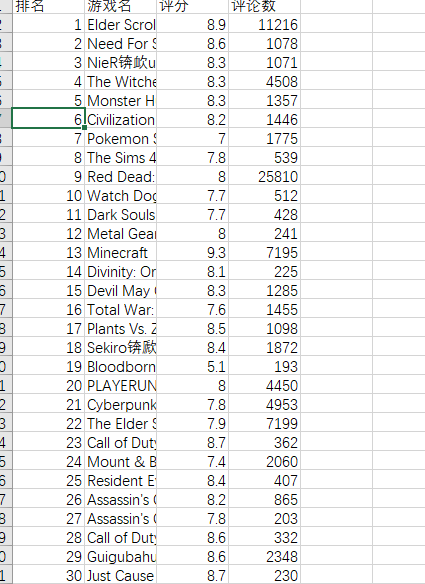
#生产的表格
3.数据分析
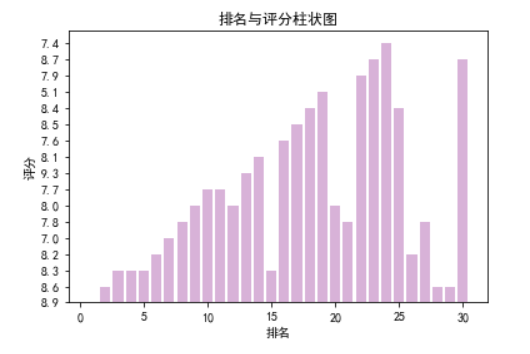
plt.rcParams['font.sans-serif']=['SimHei'] plt.bar(df.排名, df.评分, color='purple',alpha=0.3) plt.xlabel("排名") plt.ylabel("评分") plt.title('排名与评分柱状图') plt.show()
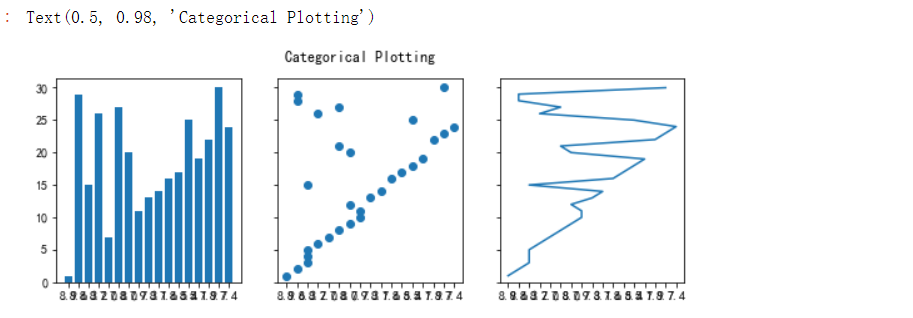
1 ##绘制分布图 2 data = {'a': 10, 'b': 15, 'c': 5, 'd': 20} 3 m = df.评分 4 n = df.排名 5 fig, axs = plt.subplots(1, 3, figsize=(9, 3), sharey=True) 6 axs[0].bar(m, n) 7 axs[1].scatter(m, n) 8 axs[2].plot(m, n) 9 fig.suptitle('Categorical Plotting')
1 #绘制直方图 2 #设置画布大小 3 plt.figure(dpi=100) 4 ab = df.评分 5 cd = df.排名 6 plt.bar(ab,cd,color='purple') 7 plt.title("评分直方图") 8 plt.xlabel("排名") 9 plt.ylabel("评分") 10 plt.show()
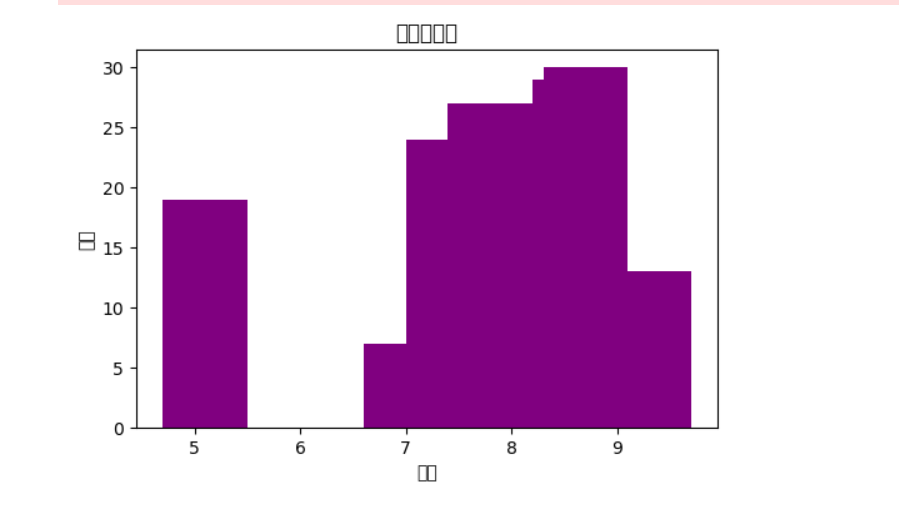
1 #绘制盒图 2 import seaborn as sns 3 def box(): 4 plt.title('评分盒图') 5 sns.boxplot(x='排名',y='评分', data=df) 6 box()
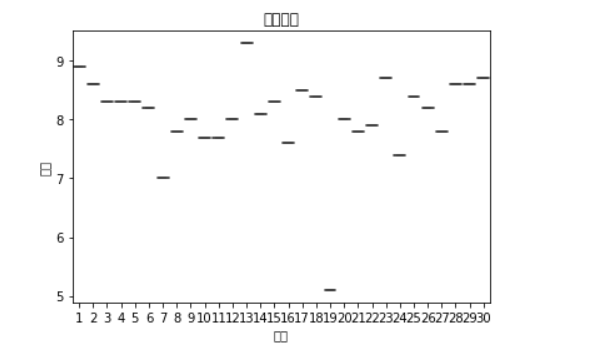
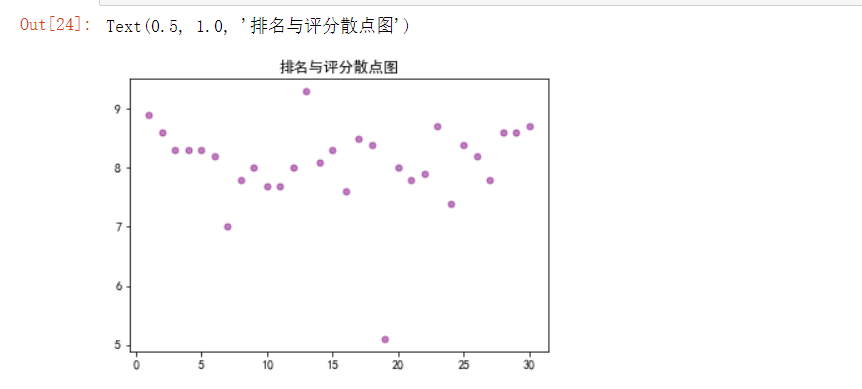
1 #绘制散点图 2 import matplotlib.pyplot as plt 3 plt.rcParams['font.sans-serif']=['SimHei'] 4 #设置散点大小 便于数据观察 5 size =25 6 plt.scatter(df.排名,df.评分,size, color="purple",alpha=0.5, marker='o')#设置透明度 7 plt.title("排名与评分散点图")
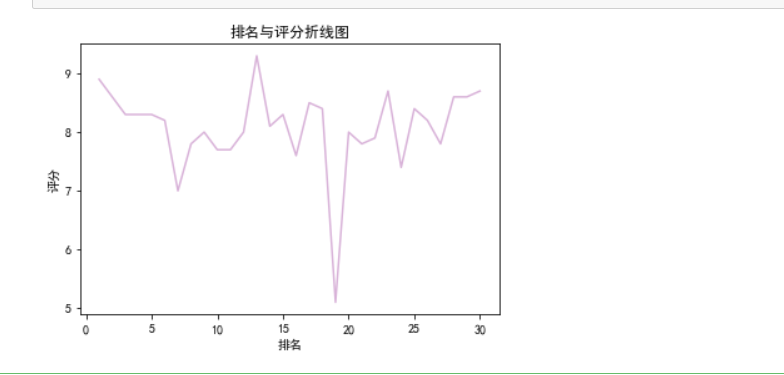
1 #绘制折线图 2 plt.rcParams['font.sans-serif']=['SimHei'] 3 plt.plot(df.排名, df.评分, color='purple',alpha=0.3) 4 plt.xlabel("排名") 5 plt.ylabel("评分") 6 plt.title('排名与评分折线图') 7 plt.show()
4.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变
量之间的回归方程
1 #建立排名与昨日指数的回归方程进行回归分析 2 #一元一次回归散点图 3 X= df.排名 4 Y = df.评分 5 #生成一元一次方程 6 def func(p,x): 7 k, b = p 8 return k * x + b 9 def error(p,x,y): 10 return func(p,x)-y 11 #定义一个主函数 12 def main(): 13 plt.figure(figsize=(10,6)) 14 p0 = [0,0] 15 Para = leastsq(error,p0,args=(X,Y)) 16 k, b = Para[0] 17 plt.scatter(X,Y,color="blue",linewidth=2) 18 x=np.linspace(0,20,20) 19 y=k * x + b 20 plt.plot(x,y,color="blue",linewidth=2,) 21 plt.title("评分分布") 22 plt.grid() 23 plt.show() 24 print(main())
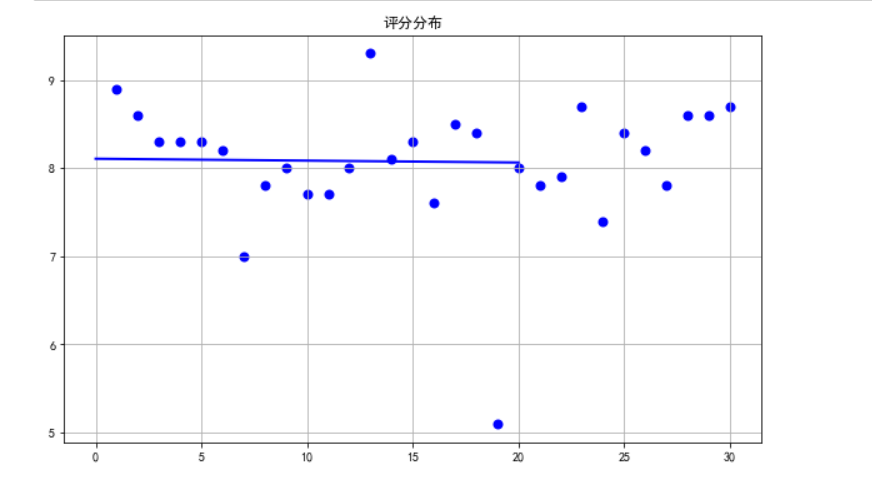
5.代码汇总
1 #爬取网站 2 3 import requests 4 from bs4 import BeautifulSoup 5 import pandas as pd 6 from matplotlib import pyplot as plt 7 from sklearn.linear_model import LinearRegression 8 import seaborn as sns 9 from scipy.optimize import leastsq 10 url='https://www.3dmgame.com/phb.html' 11 headers={'user-Agent':url} 12 r=requests.get(url,headers=headers) 13 r.raise_for_status() 14 r.encoding=r.apparent_encoding 15 #print(r.text) 16 soup=BeautifulSoup(r.content,'html.parser') 17 print(soup) 18 19 20 #数据抓取 28 url='https://www.3dmgame.com/phb.html' 29 headers={'user-Agent':url} 30 r=requests.get(url,headers=headers) 31 r.raise_for_status() 32 r.encoding=r.apparent_encoding 33 34 soup=BeautifulSoup(r.content,'html.parser') 35 a1=soup.find_all('div',{'class':'score_a'}) 36 score=[] 37 vote=[] 38 39 40 for i in a1: 41 score.append(i.find('span').string) 42 vote.append(i.find('p').string) 43 print(score) 44 print(vote) 45 name=[] 46 a2=soup.find_all('div',{'class':'bt'}) 47 48 49 for i in a2: 50 name.append(i.find('span').string) 51 rank=[] 52 53 54 for i in range(1,31): 55 rank.append(i) 56 i=float(i) 57 print(rank) 58 for i in score: 59 i=float(i) 61 for i in vote: 62 i=i.replace('人评分','') 63 64 i=float(i) 65 print(i) 66 #数据采集 68 df=pd.DataFrame({'排名':rank,'游戏名':name,'评分':score,'评论数':vote}) 69 df.to_csv('D:\python\game.csv',index=False) 70 71 df=pd.read_csv('D:\python\game.csv') 72 print(df) 73 74 #数据清洗 75 #查找重复值 76 print(df.duplicated()) 77 78 79 #数据清洗 80 81 #查找重复值 82 print(df.duplicated()) 83 84 #异常值处理 85 df.describe() 86 87 #检查是否有空值 88 print(df['游戏名'].isnull().value_counts()) 89 90 #绘制柱状图 91 plt.rcParams['font.sans-serif']=['SimHei'] 92 93 94 plt.bar(df.排名, df.评分, color='purple',alpha=0.3) 95 96 plt.xlabel("排名") 97 plt.ylabel("评分") 98 plt.title('排名与评分柱状图') 99 plt.show() 100 101 ##绘制分布图 102 data = {'a': 10, 'b': 15, 'c': 5, 'd': 20} 103 a = df.评分 104 b = df.排名 105 fig, axs = plt.subplots(1, 3, figsize=(9, 3), sharey=True) 106 axs[0].bar(a, b) 107 axs[1].scatter(a, b) 108 axs[2].plot(a, b) 109 110 fig.suptitle('Categorical Plotting') 111 112 #绘制直方图 113 #设置画布大小 114 plt.figure(dpi=100) 115 ab = df.评分 116 cd = df.排名 117 plt.bar(ab,cd,color='purple') 118 plt.title("评分直方图") 119 120 plt.xlabel("排名") 121 plt.ylabel("评分") 122 plt.show() 123 124 #绘制盒图 125 import seaborn as sns 126 def box(): 127 plt.title('评分盒图') 128 sns.boxplot(x='排名',y='评分', data=df) 129 box() 130 131 #绘制散点图 132 import matplotlib.pyplot as plt 133 plt.rcParams['font.sans-serif']=['SimHei'] 134 135 #设置散点大小 便于数据观察 136 size =25 137 plt.scatter(df.排名,df.评分,size, color="purple",alpha=0.5, marker='o')#设置透明度 138 plt.title("排名与评分散点图") 139 140 #绘制折线图 141 plt.rcParams['font.sans-serif']=['SimHei'] 142 plt.plot(df.排名, df.评分, color='purple',alpha=0.3) 143 plt.xlabel("排名") 144 plt.ylabel("评分") 145 plt.title('排名与评分折线图') 146 plt.show() 147 148 149 #建立排名与昨日指数的回归方程进行回归分析 150 151 #一元一次回归散点图 152 X= df.排名 153 Y = df.评分#生成一元一次方程 154 def func(p,x): 155 k, b = p 156 return k * x + b 157 def error(p,x,y): 158 return func(p,x)-y 159 160 #定义一个主函数 161 def main(): 162 plt.figure(figsize=(10,6)) 163 p0 = [0,0] 164 Para = leastsq(error,p0,args=(X,Y)) 165 k, b = Para[0] 166 plt.scatter(X,Y,color="blue",linewidth=2) 167 x=np.linspace(0,20,20) 168 y=k * x + b 169 plt.plot(x,y,color="blue",linewidth=2,) 170 plt.title("评分分布") 171 plt.grid() 172 plt.show() 173 print(main())
五、总结:
1.通过数据的可视化分析评分和排名的各种可视化图,可以看出,评分与排名关系并不大,但是通过柱状图和分布图还是可以看出排名前10的游戏评分大部分都在8以上。由此可以看出评分并不是决定游戏排名的决定影响,可能与热度,玩法等其它关系也有一定影响。
2.通过此次程序设计,我意识到自身对于python这门语言的学习有很多不足,在程序设计过程中对于爬虫语言不能熟练的运用,得通过翻书、网络查阅和请教同学。在提取excel表格时出现了中文乱码的情况,通过查阅资料后,通过转为txt文件,在进行更改编码,再装为csv文件才解决了编码问题,再进行数据分析时,因为之前未将采集到的数据转为浮点数的格式,都是字符串。所以无法进行散点图的绘制,给整个程序设计带来 了很大的麻烦。由此可以看出自身没有清晰的掌握整体程序设计的走向,为整个设计带来巨大的麻烦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号