9.19 小记
长链剖分!
关于长链剖分
我们参考重链剖分的办法,按照最长的链确定长儿子。
额偷一张 Wiki 的图
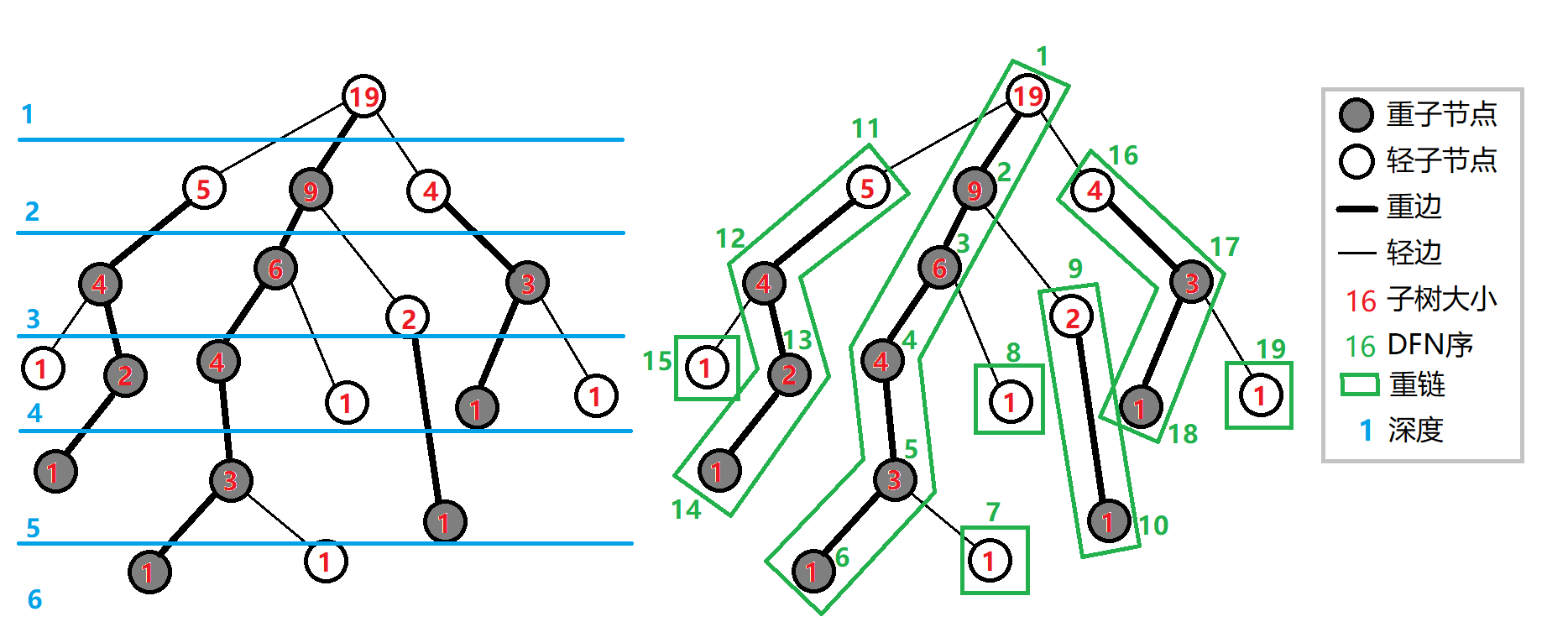
图里面说的重儿子应该就是长儿子吧
这东西有一些好玩的性质
- 跳链头的复杂度是 \(O(\sqrt n)\) 级的
- 重链长度总和为 \(O(n)\) ,也就是说 ,暴力合并轻儿子的总复杂度是 \(O(n)\) 的
然后我们可以用这些性质搞事情啦
树上 k 级祖先
最经典的是 \(O(1)\) 树上 k 级祖先
我们可以先预处理出每个点向上跳 \(2^i\) 次的祖先是谁。
然后我们能对于 \(k\) 找到 \(2^i\leq k <2^{i+1}\) 的 \(i\) ,然后从当前点跳到 \(f[p][i]\) ,剩下离答案的长度显然是 \(<2^{i}<d\) 的 ,\(d\) 是长链的长度。
然后我们跳到所在链的链头,由于长链的长度一定大于剩下的长度,我们可以提前预处理所有链向上 \(d\) 级和向下 \(d\) 级的点分别都是谁,然后在链头如果剩下需要跳的步数为正就在向上的数组里找,否则就在向下的数组里找。
预处理是 \(O(n\log n)\) 的,查询需要提前预处理每个 \(k\) 能找到的 \(i\) ,所以查询是 \(O(1)\) 的。
CF1009F Dominant Indices
这道题不仅可以长链剖分,还可以线段树合并,还可以 dsu on tree
先说说后两种吧,线段树合并就是每个节点维护一棵线段树,自底向上合并,合并的过程中求最大值。dsu on tree 是开一个桶,在记录的过程中寻找最小值。
那么现在是长链剖分。
其实思想和 dsu on tree 的差不多,就是统计一下每种深度对应的节点。
对于重儿子的统计,只需要用父亲的向下错一位就行了。
而对于轻儿子的统计,就需要再单开一段数组来统计。
而轻儿子的合并只需要暴力的合并就行了
这个过程用指针比较好实现,(我这是第一次真正用指针干什么事情)
int *f[maxn],g[maxn];
int *cur=g;
int ans[maxn],pos[maxn];
void dfs(int p)
{
f[p][0]=1;
if(son[p])
{
f[son[p]]=f[p]+1;
dfs(son[p]);
pos[p]=pos[son[p]]+1;
}
for(int i=head[p];i;i=nxt[i])
{
if(to[i]==fa[p]||to[i]==son[p]) continue;
f[to[i]]=cur; cur+=len[to[i]];
dfs(to[i]);
for(int j=1;j<=len[to[i]];j++)
{
f[p][j]+=f[to[i]][j-1];
if(f[p][j]>f[p][pos[p]]||(f[p][j]==f[p][pos[p]]&&j<pos[p]))
pos[p]=j;
}
}
if(1==f[p][pos[p]])
pos[p]=0;
}
[湖南集训]更为厉害
对于一个点 \(a\),如果 \(b\) 在 \(a\) 上面,答案就是 \(\min\{K,dep[a]\}\times(siz[a]-1)\) ,很简单的
对于一个点 \(b\) 如果在 \(a\) 下面,就需要转换了。设 \(f_{p,j}\) 表示在第 \(p\) 个节点,点 \(b\) 的距离为 \(j\) 的方案数
\(f_{p,j}=\sum f_{v,j-1}+siz[v]-1\) 我们不可能枚举 \(j\) ,所以我们用一个 \(tag\) 来代表后面的 \(siz[v]-1\) 。
但是还有个事情就是 \(f_{p,0}\) 最后要减掉 \(tag[p]\) ,因为 \(tag[fa[p]]\) 以及祖先里已经包涵 \(f_{p,0}\) 的贡献了
#include <bits/stdc++.h>
using namespace std;
int n;
const int maxn=600005;
const int maxm=1200002;
typedef long long ll;
int to[maxm],nxt[maxm],head[maxn],num;
void add(int x,int y){num++;to[num]=y;nxt[num]=head[x];head[x]=num;}
vector<int> q[maxn];ll dep[maxn],len[maxn],son[maxn],K[maxn],siz[maxn];ll ans[maxn];
void dfs(int p,int fa)
{
siz[p]=1;dep[p]=dep[fa]+1;
for(int i=head[p];i;i=nxt[i])
{
if(to[i]==fa) continue;
dfs(to[i],p);int v=to[i];
siz[p]+=siz[v];
if(len[to[i]]>len[son[p]]) son[p]=to[i];
}
len[p]=len[son[p]]+1;
for(auto i:q[p])
ans[i]+=min(K[i],dep[p])*(siz[p]-1);
}
ll G[maxn],*f[maxn];
ll *cur=G;ll tag[maxn];
void dfs1(int p,int fa)
{
if(son[p])
{
f[son[p]]=f[p]+1;
dfs1(son[p],p);
tag[p]=tag[son[p]]+siz[son[p]]-1;
}
for(int i=head[p];i;i=nxt[i])
{
if(to[i]==fa||to[i]==son[p]) continue;
int v=to[i];f[v]=cur;cur+=len[to[i]];
dfs1(to[i],p);
tag[p]+=tag[v]+siz[v]-1;
for(int j=0;j<len[v];j++)
f[p][j+1]+=f[v][j];
}
f[p][0]=-tag[p];
for(auto i:q[p])
ans[i]+=f[p][min(K[i],len[p]-1)]+tag[p];
}
int main()
{
// freopen("p.in","r",stdin);
// freopen("t.out","w",stdout);
scanf("%d",&n);
int Q;scanf("%d",&Q);
for(int i=1;i<n;i++)
{
int x,y;scanf("%d%d",&x,&y);
add(x,y);add(y,x);
}
for(int i=1;i<=Q;i++)
{
int x;
scanf("%d%d",&x,&K[i]);
q[x].push_back(i);
}
dep[0]=-1;dfs(1,0);
f[1]=cur;cur+=len[1];dfs1(1,0);
for(int i=1;i<=Q;i++)
printf("%lld\n",ans[i]);
return 0;
}
[POI2014]HOT-Hotels
妙妙树形 DP。
发现有两种可能
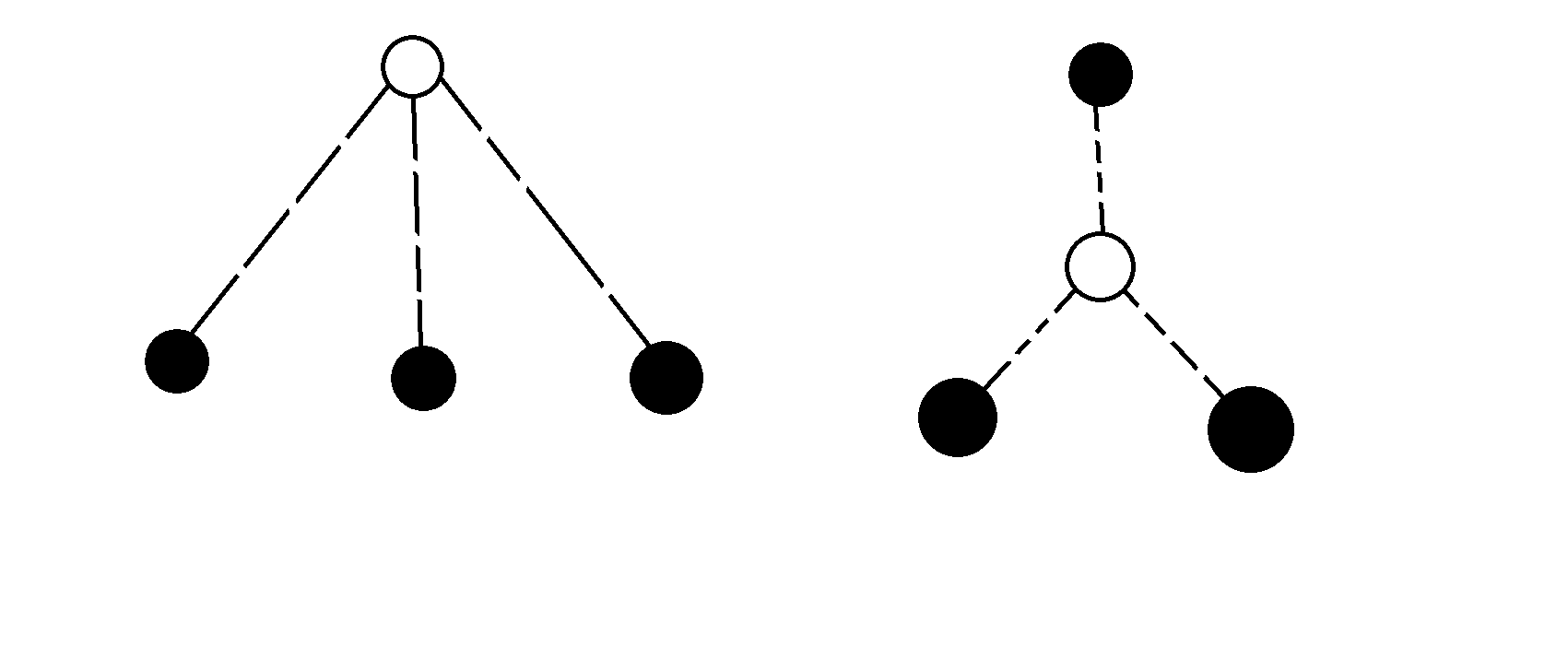
首先我们设 \(f_{i,j}\) 表示第 \(i\) 个节点,子树中到 \(i\) 的距离为 \(j\) 的点数。
\(g_{i,j}\) 表示第 \(i\) 个节点,子树中二元组 \((x,y)\) 满足 \(dis(lca(x,y),i)+j=dis(x,lca(x,y))=dis(y,lca(x,y))\) 的个数
那么答案就是 \(ans+=g_{p,0}+\sum f_{p,j-1}\times g_{v,j+1}\)
然后考虑 \(f\) 和 \(g\) 怎样转移
\(f\) 比较简单,就是 \(f_{p,j}=\sum f_{v,j-1}\)
\(g\) 有两种情况:

第一种情况就是 \(g_{p,j}+=\sum g_{v,j+1}\)
第二种情况就是 \(g_{p,j}+=\sum f_{p,j}\times f_{v,j-1}\)
然后有关深度的转移都可以长链剖分做,所以就完事了
同理,这题也可以用dsu on tree 和线段树合并做,一样的。
BZ3252 攻略
每次贪心地选择所有重链中最长的链,选 k 个就是了。
为什么呢?
因为每次都会选出一条最大的链,再选一条次大的链时如果经过原来被删掉的路径也没关系了,反正也贡献不到。
总结
如果要求与深度相关的信息的话,长链剖分是一个很好的选择。
尤其是 DP 方程中有与深度相关的状态,就很容易用长链剖分优化掉。
在一些情况下,dsu ,线段树合并,长链剖分其实有很多相近之处,某些情况下可以互换的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号