python爬虫get得到的数据和浏览器访问的不一致
python爬今日头条数据
访问这个链接获取json数据
浏览器页面:

requests库get得到的数据:
{'count': 0, 'return_count': 0, 'query_id': '6595871395417167108', 'has_more': 0, 'request_id': '201907191724580100160602073089DDE', 'search_id': '201907191724580100160602073089DDE', 'cur_ts': 1563528298, 'offset': 20, 'message': 'success', 'pd': 'synthesis', 'show_tabs': 1, 'keyword': '中国太平保险', 'city': '北京', 'log_pb': {'impr_id': '201907191724580100160602073089DDE'}, 'data': None, 'data_head': [{'challenge_code': 1366, 'cell_type': 71, 'keyword': '中国太平保险', 'url': 'sslocal://search?keyword=%E4%B8%AD%E5%9B%BD%E5%A4%AA%E5%B9%B3%E4%BF%9D%E9%99%A9&from=&source=search_tab'}], 'ab_fields': None, 'latency': 0, 'search_type': 2, 'tab_rank': None}
可以看到get返回的数据不正确
解决办法:
在get请求参数中加上cookie,cookie数据在图示红框位置处中复制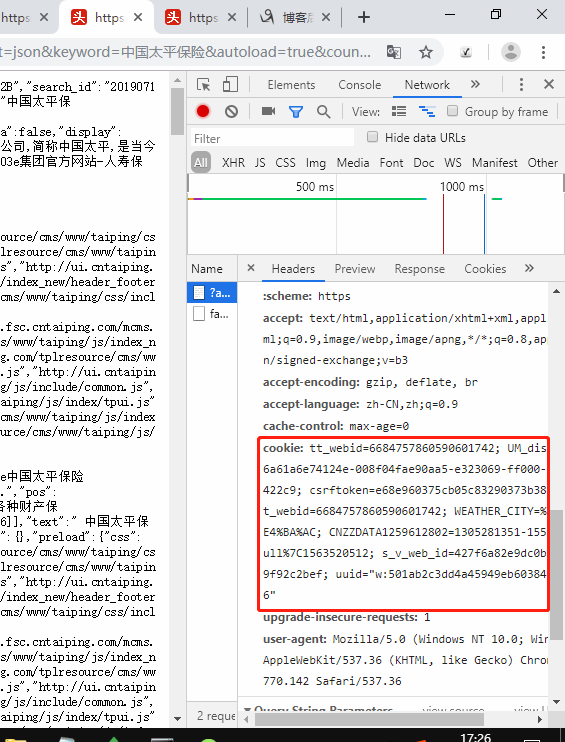
header={'Cookie':'tt_webid=6684757860590601742; UM_distinctid=16a61a6e74124e-008f04fae90aa5-e323069-ff000-16a61a6e7422c9; csrftoken=e68e960375cb05c83290373b38511ae6; tt_webid=6684757860590601742; WEATHER_CITY=%E5%8C%97%E4%BA%AC; CNZZDATA1259612802=1305281351-1556414389-null%7C1563520512; s_v_web_id=427f6a82e9dc0b2c9c4d8a99f92c2bef; uuid="w:501ab2c3dd4a45949eb60384b30f1cd6"'}
data=requests.get(urls,headers=header)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号