[转]Wiki: MurmurHash
原文:http://en.wikipedia.org/wiki/MurmurHash
MurmurHash is a non-cryptographic hash function suitable for general hash-based lookup.[1][2][3] It was created by Austin Appleby in 2008,[4][5] and exists in a number of variants,[6] all of which have been released into the public domain. When compared to other popular hash functions, MurmurHash performed well in a random distribution of regular keys.[7]
Contents
[hide]
Variants[edit]
The current version is MurmurHash3,[8][9] which yields a 32-bit or 128-bit hash value.
The older MurmurHash2[10] yields a 32-bit or 64-bit value. Slower versions of MurmurHash2 are available for big-endian and aligned-only machines. The MurmurHash2A variant adds the Merkle–Damgård construction so that it can be called incrementally. There are two variants which generate 64-bit values; MurmurHash64A, which is optimized for 64-bit processors, and MurmurHash64B, for 32-bit ones. MurmurHash2-160 generates the 160-bit hash, and MurmurHash1 is obsolete.
Implementations[edit]
The canonical implementation is in C++, but there are efficient ports for a variety of popular languages, including Python,[11] C,[12] C#,[9][13] Perl,[14] Ruby,[15] PHP,[16] Haskell,[17] Scala,[18] Java,[19][20] Erlang,[21] andJavaScript.[22][23]
It has been adopted into a number of open-source projects, most notably libstdc++ (ver 4.6), Perl,[24] nginx (ver 1.0.1),[25] Rubinius,[26] libmemcached (the C driver for Memcached),[27] maatkit,[28] Hadoop,[1] Kyoto Cabinet,[29] RaptorDB,[30]OlegDB,[31] Cassandra[32] and Clojure [33]
Algorithm[edit]
Murmur3_32(key, len, seed)
// Note: In this version, all integer arithmetic is performed with unsigned 32 bit integers.
// In the case of overflow, the result is constrained by the application of modulo

arithmetic.
c1
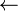
0xcc9e2d51
c2
0x1b873593
r1
15
r2
13
m
5
n
0xe6546b64
hash
seed
for each fourByteChunk of key
k
fourByteChunk
k
k * c1
k
(k << r1) OR (k >> (32-r1))
k
k * c2
hash
hash XOR k
hash
(hash << r2) OR (hash >> (32-r2))
hash
hash * m + n
with any remainingBytesInKey
remainingBytes
SwapEndianOrderOf(remainingBytesInKey)
// Note: Endian swapping is only necessary on big-endian machines.
// The purpose is to place the meaningful digits towards the low end of the value,
// so that these digits have the greatest potential to affect the low range digits
// in the subsequent multiplication. Consider that locating the meaningful digits
// in the high range would produce a greater effect upon the high digits of the
// multiplication, and notably, that such high digits are likely to be discarded
// by the modulo arithmetic under overflow. We don't want that.
remainingBytes
remainingBytes * c1
remainingBytes
(remainingBytes << r1) OR (remainingBytes >> (32 - r1))
remainingBytes
remainingBytes * c2
hash
hash XOR remainingBytes
hash
hash XOR len
hash
hash XOR (hash >> 16)
hash
hash * 0x85ebca6b
hash
hash XOR (hash >> 13)
hash
hash * 0xc2b2ae35
hash
hash XOR (hash >> 16)
A sample C implementation follows:
uint32_t murmur3_32(const char *key, uint32_t len, uint32_t seed) { static const uint32_t c1 = 0xcc9e2d51; static const uint32_t c2 = 0x1b873593; static const uint32_t r1 = 15; static const uint32_t r2 = 13; static const uint32_t m = 5; static const uint32_t n = 0xe6546b64; uint32_t hash = seed; const int nblocks = len / 4; const uint32_t *blocks = (const uint32_t *) key; int i; for (i = 0; i < nblocks; i++) { uint32_t k = blocks[i]; k *= c1; k = (k << r1) | (k >> (32 - r1)); k *= c2; hash ^= k; hash = ((hash << r2) | (hash >> (32 - r2))) * m + n; } const uint8_t *tail = (const uint8_t *) (key + nblocks * 4); uint32_t k1 = 0; switch (len & 3) { case 3: k1 ^= tail[2] << 16; case 2: k1 ^= tail[1] << 8; case 1: k1 ^= tail[0]; k1 *= c1; k1 = (k1 << r1) | (k1 >> (32 - r1)); k1 *= c2; hash ^= k1; } hash ^= len; hash ^= (hash >> 16); hash *= 0x85ebca6b; hash ^= (hash >> 13); hash *= 0xc2b2ae35; hash ^= (hash >> 16); return hash; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号