【python爬虫实战】使用Selenium webdriver采集山东招考数据
1、目标
- 目标:按地区、高校 采集2020年拟在山东招生的所有专业信息
- 采集地址:http://xkkm.sdzk.cn/zy-manager-web/gxxx/selectAllDq#
2、Selenium webdriver说明
2.1 为什么使用webdriver
Selenium Webdriver是通过各种浏览器的驱动(web driver)来驱动浏览器的,相遇对于使用requests库直接对网页进行解析,效率较低,本次使用webdriver库主要原因是requests库无法解析该网站
2.2 webdriver支持浏览器
- Google Chrome
- Microsoft Internet Explorer 7,8,9,10,11 for Windows Vista,Windows 7,Windows 8,Windows 8.1.
- Microsoft Edge
- Firefox
- Safari
- Opera
2.3 配置与使用说明
webdriver是通过各浏览器的驱动程序 来操作浏览器的,所以,要有各浏览器的驱动程序,浏览器驱动要与本地浏览器版本对应,常用浏览器驱动下载地址如下:
| 浏览器 | 对应驱动下载地址 |
|---|---|
| chrom(chromedriver.exe) | http://npm.taobao.org/mirrors/chromedriver/ |
| firefox(geckodriver.exe) | https://github.com/mozilla/geckodriver/releases |
| Edge | https://developer.microsoft.com/en-us/micrsosft-edage/tools/webdriver |
| Safari | https://webkit.org/blog/6900/webdriver-support-in-safari-10/ |
本文使用谷歌的chrome浏览器,
chrome + webdriver的具体配置和操作说明见 https://www.cnblogs.com/cbowen/p/13217857.html
3、采集
3.1 分析网站
-
进入网页发现各省份地址相同、各高校地址相同,因此想按规律构造每个省份和每个学校的url,并用requests进行解析就无法实现了。
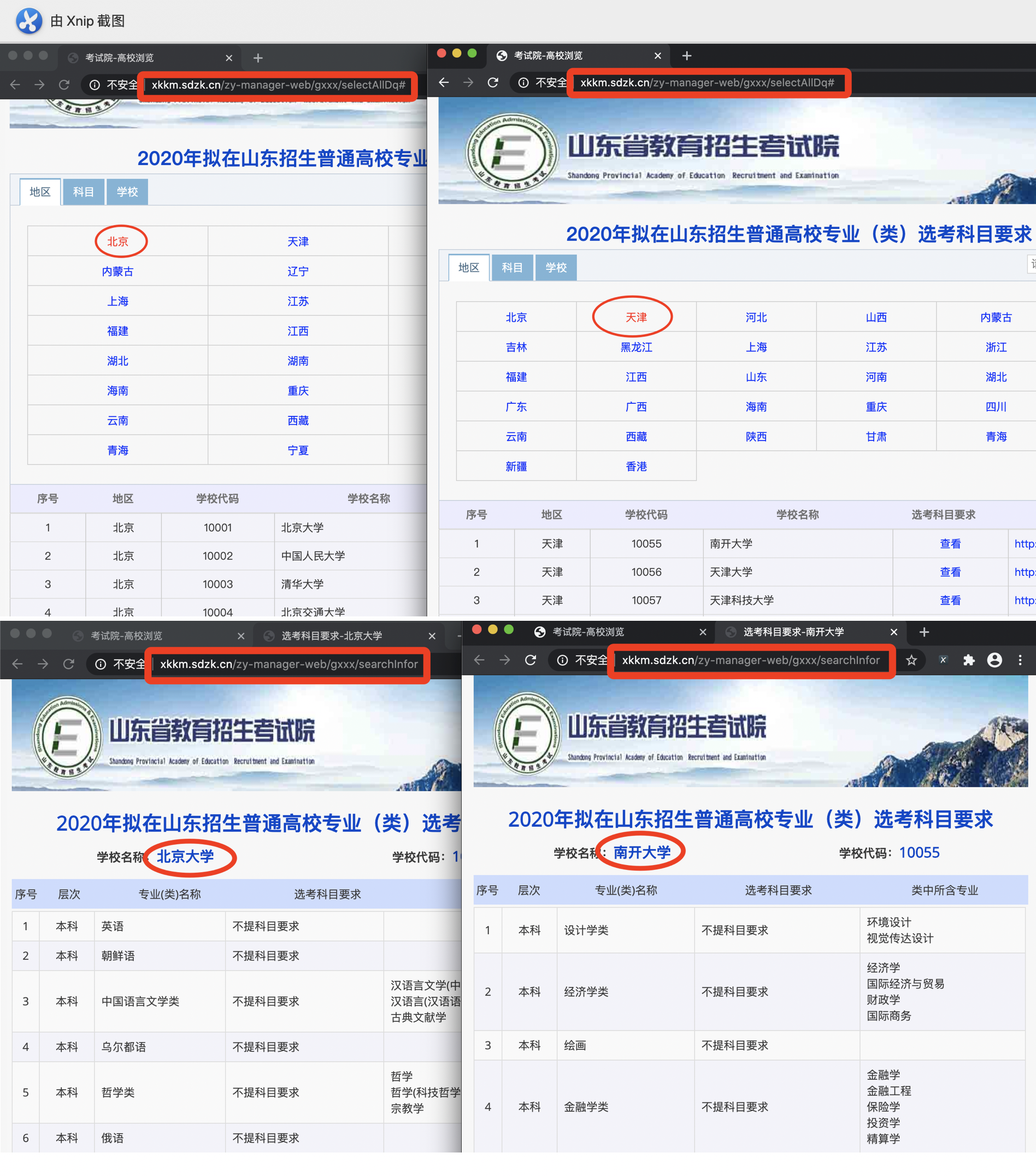
-
于是想到webdriver,来模拟人工操作,获取当前页面,再通过xpath定位到要获取的数据单元。
先用chrome控制台获取目标数据单元的xpath
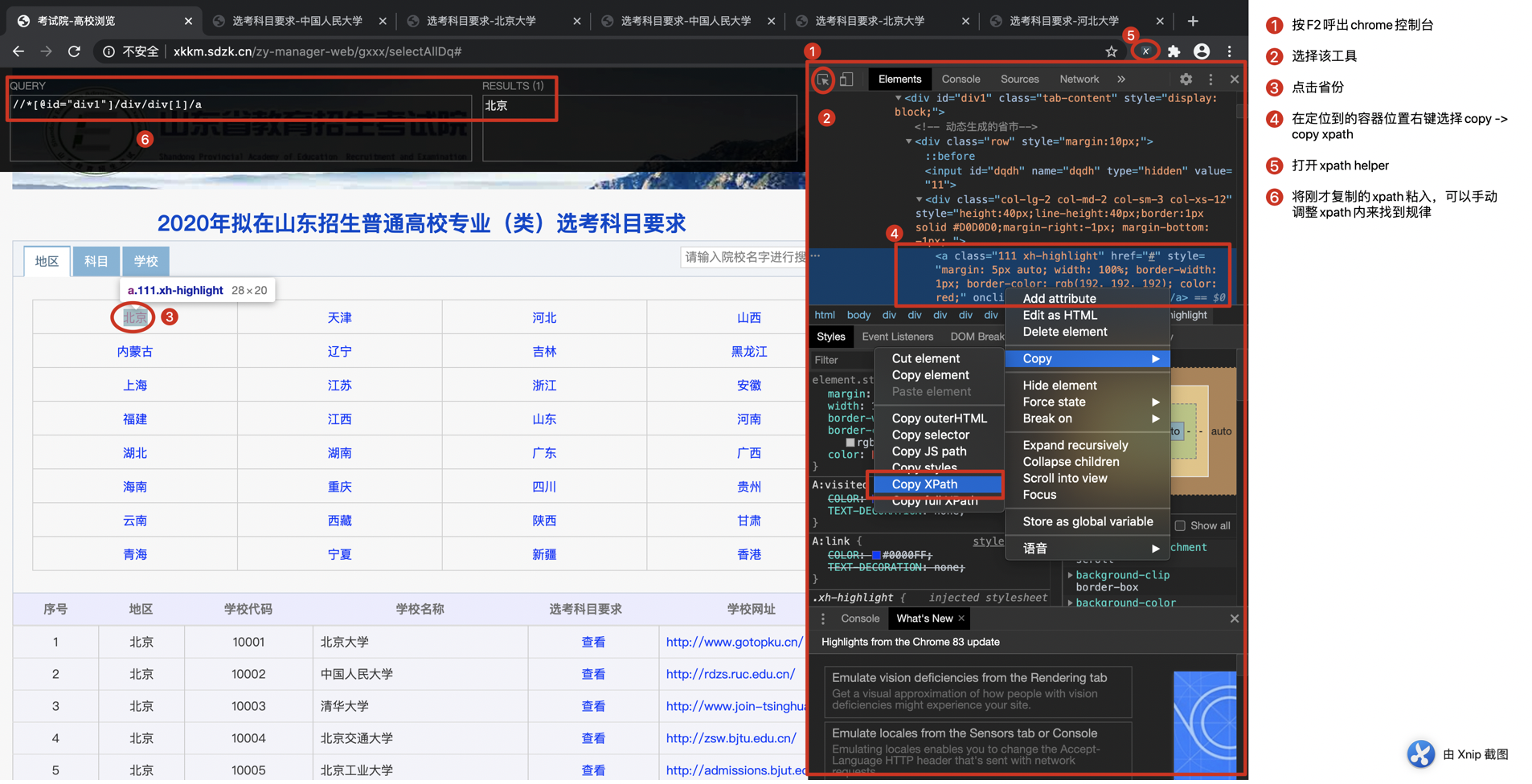
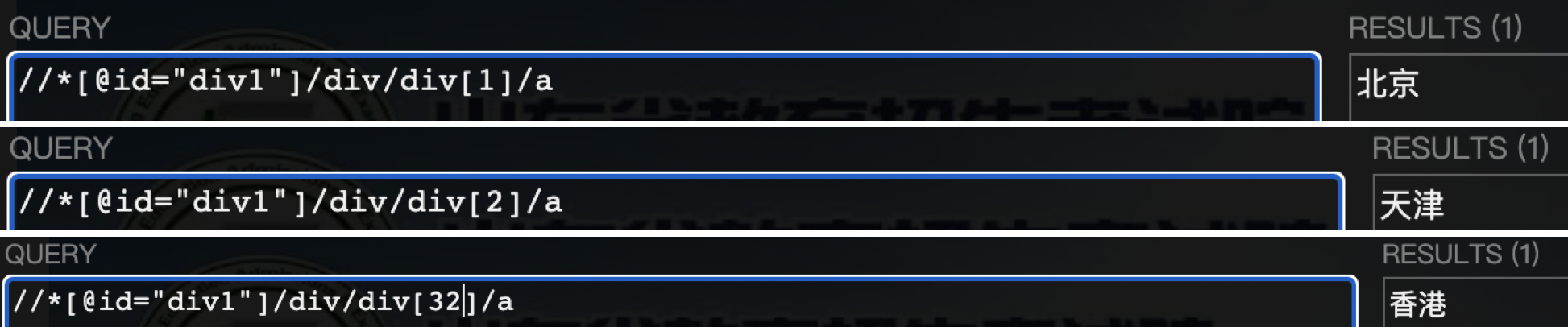
通过手动调整xpath,很容易发现省份xpath的规律为
for province_id in rang(1, 33)
province_xpath = '//*[@id="div1"]/div/div[%s]/a' % province_id
再用同样方法获取高校的xpat,这里就不贴截图了,直接上结果
# sch_id为每个省份的高校id
# schid_xpath,province_xpath,schcode_xpath,school_xpath,subpage_xpath,schhome_xpath分别对应字段序号、地区、学校代码、学校名称、选考科目要求、学校主页
schid_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[1]/a' % school_id
province_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[2]/a' % school_id
schcode_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[3]/a' % school_id
school_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[4]/a' % school_id
subpage_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[5]/a' % school_id
schhome_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[6]/a' % school_id
再用同样方法获取专业信息的xpat,直接上结果
# major_id为每个高校专业序号,从1到最后一个专业序号
# i从1到4分别对应字段“序号”、“层次”、“专业名称”、“选考科目要求”
for i in range(1, 5):
major_xpath = '//*[@id="ccc"]/div/table/tbody/tr[%s]/td[%s]' % (major_id, i)
3.2 遍历省份
- 遍历省份很简单,一共32个省份,直接用rang(1,33),省去用try来判断。
- 在函数外启动浏览器,并传入WebDriver类wd,所有省份遍历完成后关闭浏览器
- 后面要将数据写入mysql,所有传入了完成数据库连接的connect对象conn,并在全部数据写入后关闭conn连接。
def traverse_province(wd, conn):
"""
循环进入省份
:return:
"""
for province_id in range(1, 33):
province_xpath = '//*[@id="div1"]/div/div[%s]/a' % province_id
wd.find_element_by_xpath(province_xpath).click() # 点击进入省份
time.sleep(1)
traverse_school(wd, conn) # 遍历省份内的高校
wd.quit()
conn.close()
3.3 遍历高校
- 用while True循环来遍历当前页所有的高校,用try-except来判断是否成功捕捉高校信息,失败则终端while True循环。
- 获取高校基本信息放列表school_info中,传入下层函数用于冗余保存高校+专业 完整数据。
- 进入高校的子页面后,需要重新定位当前操作页面,wd.window_handles获取当前浏览器所有子页面句柄,wd.switch_to.window切换至指定页面。
- 最内层函数traverse_major()会获取专业数据,并将本层获取的高校数据和专业数据写入mysql。
- 在一个高校的全部专业数据写入完成后,提交一次。
def traverse_school(wd, conn):
"""
遍历高校信息
:return:
"""
school_id = 1
while True:
school_info = []
try:
# 获取高校信息
for i in [1, 2, 3, 4, 6]:
school_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[%s]' % (school_id, i)
text = wd.find_element_by_xpath(school_xpath).text
school_info.append(text)
# 进入高校子页
wd.find_element_by_xpath('//*[@id="div4"]/table/tbody/tr[%s]/td[5]/a' % school_id).click()
wd.switch_to.window(wd.window_handles[-1]) # 切换到最后一个页面
traverse_major(school_info, wd, conn) # 遍历专业
wd.close() # 关闭当前页
wd.switch_to.window(wd.window_handles[-1]) # 重新定位一次页面
school_id += 1
except:
break
conn.commit() # 每个高校份提交一次
3.4 采集专业数据
- 将专业信息结合上层函数传入的高校信息冗余保存。
- 每个高校启动一次游标。
- 本函数内仅使操作游标进行数据写入,数据库的连接在下面函数中,数据库关闭在最外层函数中。
def traverse_major(school_info, wd, conn):
"""
遍历专业信息,最后结合高校信息一并输出
:param school_info: 上层函数传递进来的高校信息
:return:
"""
major_id = 1
cursor = conn.cursor()
while True:
major_info = []
try:
for i in range(1, 5):
major_xpath = '//*[@id="ccc"]/div/table/tbody/tr[%s]/td[%s]' % (major_id, i)
text = wd.find_element_by_xpath(major_xpath).text
major_info.append(text)
print(school_info + major_info)
# 写入mysql
insert_sql = '''
insert into sdzk_data
(school_id,province,school_code,school_name,school_home,major_id,cc,major_name,subject_ask)
values('%s','%s','%s','%s','%s','%s','%s','%s','%s')
''' % (school_info[0], school_info[1], school_info[2], school_info[3], school_info[4],
major_info[0], major_info[1], major_info[2], major_info[3])
cursor.execute(insert_sql)
major_id += 1
except:
break
cursor.close() # 每个高校都重新开启一次游标
3.5 写入mysql
- 该函数仅用于创建mysql连接,并创建表。
- 判断表是否存在,存在则先删除再创建。
- 函数返回connect类,用于其他函数使用。
- 关闭连接在最外层函数中,直到所有省份数据采集结束后才关闭连接。
def connect_mysql(config):
"""
连接数据库,并创建表,如果表已存在则先删除
:param config: mysql数据库信息
:return: 返回连接成功的connect对象
"""
create_sql = '''
CREATE table if NOT EXISTS sdzk_data
(school_id int(3),province varchar(20), school_code varchar(5),
school_name varchar(50), school_home varchar(100), major_id int(3),
cc varchar(5), major_name varchar(100), subject_ask varchar(50))
'''
# 判断表是否存在,存在则删除,然后创建
conn = pymysql.connect(**config)
cursor = conn.cursor()
cursor.execute('''show TABLEs like "sdzk_data"''')
if cursor.fetchall():
cursor.execute('''drop table sdzk_data''')
cursor.execute(create_sql)
cursor.close()
return conn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号