Apache Storm - Core Concepts
@Source
https://www.tutorialspoint.com/apache_storm/apache_storm_core_concepts.htm
Apache Storm 从一端实时读取原始数据流 , 经过一系列小处理单元(bolts), 在另一端输出被加工好的数据。
下图展示了其核心概念:
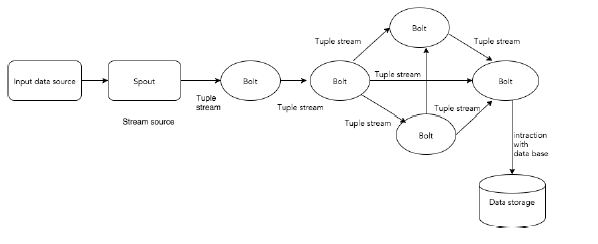
##Tuple
Tuple 是Storm 主要的数据结构, 它是一系列元素的集合。默认的, Tuple 支持所有的数据类型, 一般搞成一组逗号分隔的值传递给storm cluster。
##Stream
Stream 是一组无序的tuples。
##Spouts
是stream 的数据源, 从Twitter Streaming API、 Apache Kafka patition 队列接收原始数据。 你也能够从数据源自己读取数据写入 Spouts, ISpout 是其核心接口, 还有一些专门的接口, 如:IRickSpout 、 BaseRichSpout 、KafkaSpout 等等。
##Bolts
Bolts 是最基本的 处理逻辑单元, Spouts 传递数据到Bolts, Bolts 产生新的输出流, Bolts 可以执行过滤、聚合、连接、数据库交互等操作,并会发送到接下来的一个或多个 bolts。 IBolt 是实现bolts 的核心接口, 一些通用的接口包括IRichBolt、IBasicBolt 等等。
看一个案例:
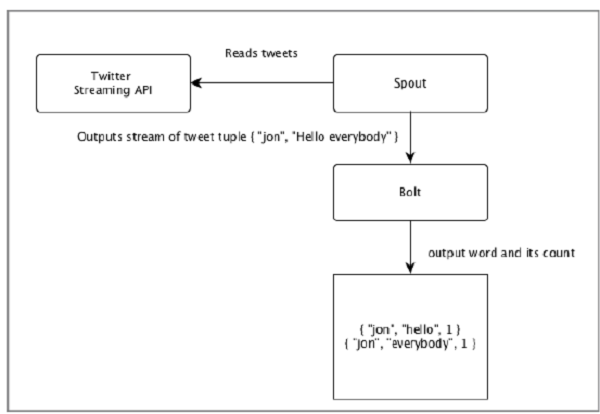
##Topology
dSpouts 和bolts 被连接在一起, 他们组成了一个topology, 实时应用的逻辑定义在topology, 简单来说, 一个topology 就是一个有向图, 顶点表示计算, 边表示数据流。
一个简单的topology 开始于spouts Spout 发射数据到一个或多个bolts, 经过处理后的数据流可以继续发射到其它blots。 Storm 保持topology 总是运行, 知道kill掉topology, Storm 主要任务就是运行topology 并且可以同时运行多个。
##Tasks
现在已经有了spouts 和bolts 的基本概念, 他们是topology 最小的逻辑单元, 一个topology 由一个spout 和bolts 数组组成。他们必须按照特定的顺序执行。无论是bolt 还是spout 的执行都被称作是Tasks , 简单说, 一个task 就是一个spout 或bolt 的执行, spout 和bolt 可以同时跑多个实例。
##Workers
一个topology 以分布式的形式, 运行在多个worker节点上, Storm 均匀的分发task 到多个worker结点。worker 的任务就是监听jobs , 对于新来的job启动和关闭进程。
##Stream Grouping
数据流在spouts 和bolts 或着bolt 和bolt 之间“漂移”, Stream Grouping 控制tuples 如何在topology 中路由, 下面介绍四种内置的grouping 方式。
###Shuffle Grouping
相同数量的tuples 被分别随机分发到所有worker 。
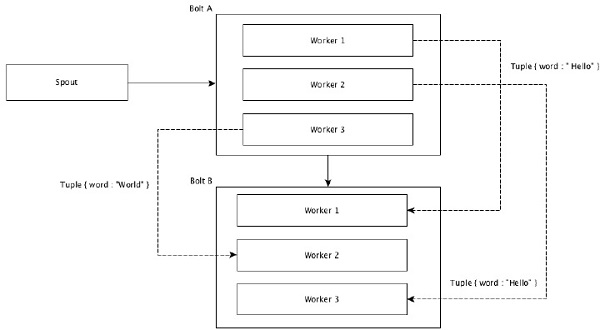
###Field Grouping
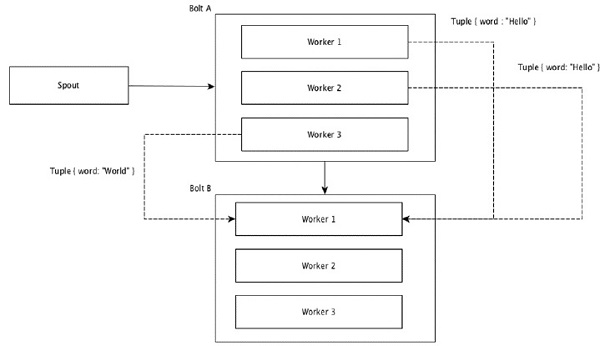
有相同值的tuples 被分组到一起。比如统计单词的时候, 所有worker 上跑出来的单词, 相同的单词必须扔到一个同一个worker
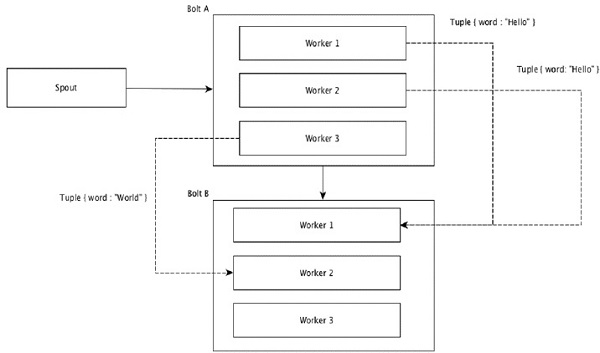
Global Grouping
所有的tuple 都被分到一组, 发射到同一个bolt
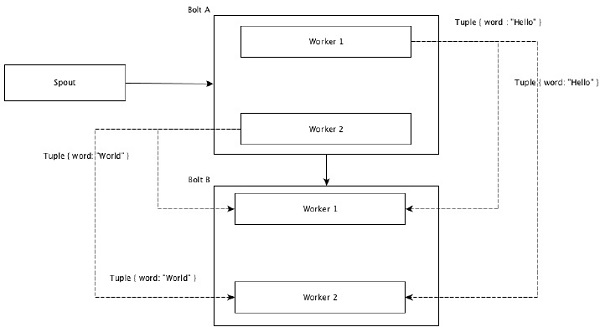
All Grouping
一个tuple 被发射到所有的bolt 实例, 这种分组策略, 被用于向bolts 发送信号, 在join 操作上很有用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号