图像生成-GAN--05
第一部分:GAN 的核心理论 - “伪造者”与“鉴赏家”的博弈
想象一个场景:一个新手伪造者(Generator)想画出足以以假乱真的名画,而一位经验丰富的艺术鉴赏家(Discriminator)则负责鉴定画作的真伪。
伪造者 (Generator, G):他的目标是学习如何画出越来越逼真的画,让鉴赏家无法分辨。他从一堆随机的“灵感”(噪声)开始,画出作品。
鉴赏家 (Discriminator, D):他的目标是不断提升自己的眼力,准确地分辨出哪些是真迹,哪些是伪造的赝品。
GAN 的训练过程就是这两者之间的一场“猫鼠游戏”或“对抗性”博弈:
鉴赏家学习:我们给鉴赏家看大量的真迹(真实数据)和伪造者画的赝品(生成数据),并告诉他哪些是真、哪些是假。鉴赏家通过学习,提升自己的鉴别能力。
伪造者学习:伪造者画了一幅画,然后交给鉴赏家评判。鉴赏家会给出一个反馈(“这画看起来有多真?”)。伪造者根据这个反馈,调整自己的绘画技巧,争取下次画出的画能更好地骗过鉴赏家。
这个过程不断重复。最终,如果一切顺利,伪造者的技艺将变得炉火纯青,其作品足以以假乱真,而鉴赏家也很难再分辨真假,此时我们就得到了一个强大的图像生成器。
这场博弈可以用一个目标函数(Value Function)来描述,这是一个最小最大化游戏 (Minimax Game):
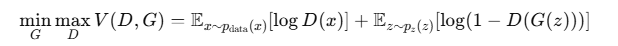
判别器 \(D\) 区分真假样本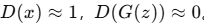
生成器 \(G\) 的目标:以假乱真,希望让判别器判断 \(G(z)\) 也为真,即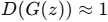
所以 GAN 的目标是一个最小最大问题:


D 的优化目标:最大化这两个期望,即正确分类真假样本。
G 的优化目标:使 D 分不清真伪,最小化第二项(或用变种目标)
第二部分:从 GAN 到 DCGAN - 为图像而生的进化
最初的 GAN 使用的是简单的全连接网络(多层感知机),这对于处理高维的图像数据来说效果不佳。2015年,深度卷积生成对抗网络 (Deep Convolutional GAN, DCGAN) 被提出,它将 GAN 的思想与卷积神经网络 (CNN) 结合起来,成为了图像生成领域的一个里程碑。
DCGAN 的核心架构改进如下:
用卷积层替代全连接层:在判别器中使用带步长(Strided)的卷积层来替代池化层进行下采样;在生成器中使用转置卷积层 (Transposed Convolution) 来进行上采样。
使用批归一化 (Batch Normalization):在生成器和判别器中都使用批归一化,这有助于稳定训练,解决梯度消失/爆炸问题。
激活函数的选择:
生成器(Generator):在输出层使用 Tanh 激活函数(因为图像数据通常被归一化到 \([-1, 1]\) 范围),其余层使用 \(ReLU\)。
判别器(Discriminator):使用 \(LeakyReLU\) 激活函数,这有助于在反向传播时为负值区域也提供梯度,防止梯度稀疏。
第三部分:PyTorch 代码实现 (DCGAN 生成 MNIST 手写数字)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 超参数
LEARNING_RATE = 2e-4 # 学习率
BATCH_SIZE = 128 # 批处理大小
IMAGE_SIZE = 64 # 图像大小 (MNIST是28x28, 我们将其调整到64x64)
CHANNELS_IMG = 1 # 图像通道 (MNIST是灰度图)
Z_DIM = 100 # 潜在向量维度 (噪声维度)
NUM_EPOCHS = 10 # 训练轮次
# 数据预处理
transform = transforms.Compose([
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor(),
transforms.Normalize(
[0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)]
),
])
# 下载并加载数据集
# dataset = datasets.MNIST(root="dataset/", train=True, transform=transform, download=True)
dataset = datasets.FashionMNIST(root=".", train=True, transform=transform, download=True) # 也可以用FashionMNIST
loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
# 生成器接收一个 100 维的噪声向量 z,通过一系列的转置卷积层将其“放大”成一张 64x64 的图像。
class Generator(nn.Module):
def __init__(self, z_dim, channels_img, features_g):
super(Generator, self).__init__()
# 输入: N x z_dim x 1 x 1
self.net = nn.Sequential(
# _block(in_channels, out_channels, kernel_size, stride, padding)
self._block(z_dim, features_g * 16, 4, 1, 0), # N x f_g*16 x 4 x 4
self._block(features_g * 16, features_g * 8, 4, 2, 1), # N x f_g*8 x 8 x 8
self._block(features_g * 8, features_g * 4, 4, 2, 1), # N x f_g*4 x 16 x 16
self._block(features_g * 4, features_g * 2, 4, 2, 1), # N x f_g*2 x 32 x 32
nn.ConvTranspose2d(features_g * 2, channels_img, kernel_size=4, stride=2, padding=1), # N x c_img x 64 x 64
nn.Tanh() # 将输出归一化到 [-1, 1]
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
# 判别器接收一张 64x64 的图像,通过一系列卷积层将其“压缩”成一个概率值,表示该图像为真的可能性。
class Discriminator(nn.Module):
def __init__(self, channels_img, features_d):
super(Discriminator, self).__init__()
# 输入: N x channels_img x 64 x 64
self.net = nn.Sequential(
nn.Conv2d(channels_img, features_d, kernel_size=4, stride=2, padding=1), # 32x32
nn.LeakyReLU(0.2),
# _block(in_channels, out_channels, kernel_size, stride, padding)
self._block(features_d, features_d * 2, 4, 2, 1), # 16x16
self._block(features_d * 2, features_d * 4, 4, 2, 1), # 8x8
self._block(features_d * 4, features_d * 8, 4, 2, 1), # 4x4
nn.Conv2d(features_d * 8, 1, kernel_size=4, stride=2, padding=0), # 1x1
nn.Sigmoid(), # 输出一个概率值
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.2),
)
def forward(self, x):
return self.net(x)
# 初始化网络、优化器和损失函数
def initialize_weights(model):
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight.data, 0.0, 0.02)
gen = Generator(Z_DIM, CHANNELS_IMG, 64).to(device)
disc = Discriminator(CHANNELS_IMG, 64).to(device)
initialize_weights(gen)
initialize_weights(disc)
# 优化器
opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
opt_disc = optim.Adam(disc.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
# 损失函数
criterion = nn.BCELoss()
# 创建固定的噪声,用于可视化生成效果
fixed_noise = torch.randn(64, Z_DIM, 1, 1).to(device)
# 这是 GAN 的核心部分,我们将交替训练判别器和生成器。
gen.train()
disc.train()
# 用于记录损失
G_losses = []
D_losses = []
img_list = []
step = 0
print("Starting Training Loop...")
for epoch in range(NUM_EPOCHS):
for batch_idx, (real, _) in enumerate(loader):
real = real.to(device)
noise = torch.randn(BATCH_SIZE, Z_DIM, 1, 1).to(device)
fake = gen(noise)
# 训练判别器: max log(D(x)) + log(1 - D(G(z)))
# 1. 使用真实图片进行训练
disc_real = disc(real).reshape(-1)
loss_disc_real = criterion(disc_real, torch.ones_like(disc_real)) # 标签为1
# 2. 使用伪造图片进行训练
disc_fake = disc(fake.detach()).reshape(-1) # detach()防止梯度传回生成器
loss_disc_fake = criterion(disc_fake, torch.zeros_like(disc_fake)) # 标签为0
# 3. 组合损失并更新
loss_disc = (loss_disc_real + loss_disc_fake) / 2
disc.zero_grad()
loss_disc.backward()
opt_disc.step()
# 训练生成器: min log(1 - D(G(z))) <-> max log(D(G(z)))
# 为了更好的梯度流,我们最大化log(D(G(z)))
output = disc(fake).reshape(-1)
loss_gen = criterion(output, torch.ones_like(output)) # 让生成器生成的图片标签为1
gen.zero_grad()
loss_gen.backward()
opt_gen.step()
# 打印训练状态并记录损失
if batch_idx % 100 == 0:
print(
f"Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_idx}/{len(loader)} \
Loss D: {loss_disc:.4f}, loss G: {loss_gen:.4f}"
)
D_losses.append(loss_disc.item())
G_losses.append(loss_gen.item())
# 每个epoch结束后,保存一张由fixed_noise生成的图片
with torch.no_grad():
fake = gen(fixed_noise).detach().cpu()
img_grid = torchvision.utils.make_grid(fake, padding=2, normalize=True)
img_list.append(img_grid)
print("Training Finished!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号