大模型- 强化学*-*端策略优化PPO--89
参考
https://newfacade.github.io/notes-on-reinforcement-learning/15-ppo.html
https://gemini.google.com/app/247cc5d3d5bad7de
https://arxiv.org/abs/1707.06347
强化学习领域目前最流行、最实用的算法之一:近端策略优化 (Proximal Policy Optimization, PPO)。
理解 PPO 的最佳方式,是把它看作对上一讲 TRPO 思想的继承和简化。它想要实现和 TRPO 一样的目标——防止策略更新步子太大导致崩溃——但用了更简单、更易于实现的方法。
1. 背景:从 TRPO 的复杂性中解脱
先回顾一下 TRPO 的优缺点
优点:通过复杂的二阶优化(共轭梯度法)和 KL 散度约束,实现了非常稳定的策略更新,几乎从理论上杜绝了“策略崩溃”。
缺点:算法极其复杂,计算量大,难以实现和调试。
PPO 的作者们思考:我们能不能找到一种更简单的方法,只用一阶优化(即普通的梯度下降),就能实现类似 TRPO 的“可信区域”效果呢? Trust Regin
PPO 算法的核心就是为了回答这个问题,它提出了一种新颖的目标函数 (Objective Function),通过一个简单的“裁剪 (Clipping)”操作,巧妙地限制了新旧策略的差距。
2. PPO 的核心思想:裁剪代理目标函数 (Clipped Surrogate Objective)
先从普通策略梯度PG的目标函数出发。
目标函数 L_PG(在 PPO 论文中被称为“代理目标函数”)是:

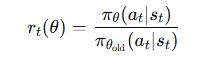
新旧策略的概率比率。
A_t 是在 t 时刻的优势函数(通常用 GAE 计算)
TRPO 通过 KL 散度约束来防止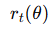 离 1 太远.
离 1 太远.
而 PPO 则直接修改了目标函数本身
PPO-Clip 提出了如下的目标函数 L^{CLIP}
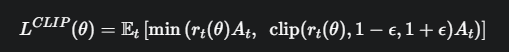
这个公式是 PPO 的灵魂,我们来详细拆解它
- min(...): 取两个值中较小的一个
- clip(r_t(\theta), 1-\epsilon, 1+\epsilon):这是一个裁剪函数。它会把概率比率 r_t(\theta) 强制限制在 [1-ε, 1+ε] 的区间内。ε (epsilon) 是一个很小的超参数,比如 0.2。
为了理解这个公式的精妙之处,我们分两种情况讨论:
情况一: 优势 A_t > 0 (这是一个好动作)
此时,我们希望增大 r_t(\theta) 来提高这个好动作的概率。目标函数变为:
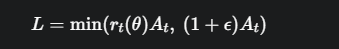
当 r_t(\theta) 比较小(比如在 1.0 到 1.2 之间)时
r_t(\theta) < 1+ε,所以 min 函数会取 r_t(\theta)A_t,目标函数会随着 r_t(\theta) 的增大而增大,策略正常更新。
但是,一旦我们对策略的更新过大,导致 r_t(\theta) 超过了 1+ε,min 函数就会取 (1+ε)A_t。这个值是一个常数,它的梯度为零。
效果: 这相当于给目标函数加了一个“天花板”。我们鼓励好的动作,但当策略更新的步子大到让新策略的概率超过旧策略的 1.2 倍时,我们就“夹住(clip)”它,不再提供更多的梯度。这有效地防止了策略因为某个好动作而过度更新。
情况二:优势 A_t < 0 (这是一个坏动作)
此时,我们希望减小 r_t(\theta) 来降低这个坏动作的概率。目标函数变为:
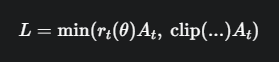
当 r_t(\theta) 在 [1-ε, 1] 之间时,clip 函数不起作用,min 会取 r_t(\theta)A_t。
当我们对策略更新过大,导致 r_t(\theta) 小于 1-ε 时,clip 函数会把 r_t(\theta) 裁剪到 1-ε,此时 (1-ε)A_t 会比 r_t(\theta)A_t 更大,min 函数会选择前者 r_t(\theta)A_t
这似乎和期望的不一样。我们再仔细看一下 min 函数
重新审视 min 函数,因为A_t是负数,r_t(θ)A_t和 clip(...)A_t 都是负数。min会选择绝对值更大的那个。这等价于选择max(r_t(θ)A_t, (1-ε)A_t),因为A_t是负数。
效果: 这相当于给目标函数加了一个“地板”。我们惩罚坏的动作,但当策略更新的步子大到要让新策略的概率低于旧策略的 0.8 倍时,我们就“夹住(clip)”它,不再提供惩罚梯度。这防止了策略因为某个坏动作而过度“害怕”,导致策略过于保守。

上图直观展示了PPO的裁剪目标函数。无论优势是正还是负,目标函数的增长或降低都被限制在一个范围内,从而保证了更新的稳定性
PPO 的完整算法与训练流程
PPO 是一个 Actor-Critic 框架的算法,它的完整损失函数还包括 价值函数损失 (Critic Loss) 和 熵奖励 (Entropy Bonus)。
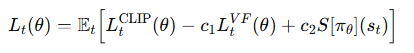
策略损失(Clipped Objective)
核心思想:限制新旧策略偏离太远,防止梯度更新过大。
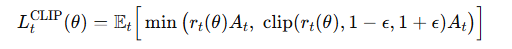
其中: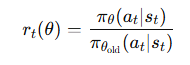
价值函数损失(Value Function Loss)
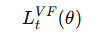
用来约束 Critic 的学习效果,一般是均方误差:
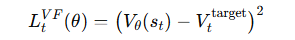
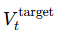 一般是用 GAE (Generalized Advantage Estimation) 计算的回报:
一般是用 GAE (Generalized Advantage Estimation) 计算的回报:

策略熵正则项(Entropy Bonus)
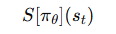
用于鼓励策略的探索性,防止策略收敛得太早:
权重系数
c1,c2:用于平衡这三部分损失的权重。
通常:
c1 比较大(例如 0.5),强调 Critic 学得准确。
c2一般较小(例如 0.01),轻度鼓励探索。

PPO 独特的训练流程
PPO 的训练方式也很有特点。它不像基础 Actor-Critic 那样每一步都更新,而是:
收集数据: 让 Actor(使用旧策略 π_{θ_old})与环境交互固定的 N 步(例如2048步),并把所有 (s_t, a_t, r_t, log_prob_old) 存起来。
计算优势: 在这 N 步数据上,使用 GAE 计算出每一时间步的优势 A_t 和回报 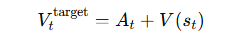
多轮优化 (Multiple Epochs):
循环 K 次(例如10次)。
在每一次循环中,将收集到的 N 步数据分成若干个小批量(mini-batches)
对每一个小批量数据,计算 PPO 的总损失函数 L(θ)。
执行一次梯度下降来更新网络参数 θ
关键点:PPO 用同一批数据,训练好几次!这怎么可以呢?
这怎么可以呢?因为 \(L^{CLIP}\) 目标函数保证了每次更新都不会让新策略偏离旧策略太远,所以我们可以放心地在同一批数据上进行多次优化,从而极大地提高了数据利用率 (Sample Efficiency)。
代码实现(核心逻辑解读)
# 假设已经收集了一批数据 (states, actions, old_log_probs, advantages, returns)
# K_EPOCHS 是优化的轮数,EPSILON 是裁剪参数 ε
def update():
for _ in range(K_EPOCHS):
# 将数据分成小批量进行遍历
for batch in data_loader(data_batch):
# --- 核心计算 ---
# 1. 用当前网络评估这批数据
# 得到新的对数概率、当前状态的价值和策略的熵
new_log_probs, state_values, entropy = model.evaluate(batch.states, batch.actions)
# 2. 计算概率比率 r_t(θ)
ratio = torch.exp(new_log_probs - batch.old_log_probs)
# 3. 计算 Actor 的裁剪损失 L_CLIP
advantage = batch.advantages
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - EPSILON, 1 + EPSILON) * advantage
# PPO 的目标是最大化 L_CLIP,所以我们最小化它的负值
policy_loss = -torch.min(surr1, surr2).mean()
# 4. 计算 Critic 的价值损失
value_loss = F.mse_loss(state_values, batch.returns)
# 5. 计算总损失 (注意熵损失的符号)
loss = policy_loss + C1 * value_loss - C2 * entropy.mean()
# 6. 梯度下降
optimizer.zero_grad()
loss.backward()
optimizer.step()
目标:PPO 旨在用更简单、更高效的方式实现 TRPO 的稳定性。
核心机制:裁剪代理目标函数 (Clipped Surrogate Objective)。它通过一个简单的 clip 操作,温和地限制了新旧策略的差距,防止了过大的更新。
训练流程:通过在同一批数据上进行多轮优化 (Multiple Epochs),显著提高了数据利用率。
优点:集稳定性高、实现简单、性能强大、效率高等优点于一身。
地位:PPO 是目前强化学习领域的首选算法之一,是你工具箱中必须掌握的强大工具。
from dataclasses import dataclass
@dataclass
class Args:
env_id: str = "CartPole-v1"
"""the id of the environment"""
total_timesteps: int = 200000
"""total timesteps of the experiments"""
learning_rate: float = 2.5e-4
"""the learning rate of the optimizer"""
num_envs: int = 4
"""the number of parallel game environments"""
num_steps: int = 128
"""the number of steps to run in each environment per policy rollout"""
num_minibatches: int = 4
"""the number of mini-batches"""
update_epochs: int = 4
"""the K epochs to update the policy"""
gamma: float = 0.99
"""the discount factor gamma"""
gae_lambda: float = 0.95
"""the lambda for the general advantage estimation"""
clip_coef: float = 0.2
"""the surrogate clipping coefficient"""
vf_coef: float = 0.5
"""coefficient of the value function"""
max_grad_norm: float = 0.5
"""the maximum norm for the gradient clipping"""
# to be filled in runtime
batch_size: int = 0
"""the batch size (computed in runtime)"""
minibatch_size: int = 0
"""the mini-batch size (computed in runtime)"""
num_iterations: int = 0
"""the number of iterations (computed in runtime)"""
args = Args()
import gymnasium as gym
# Vectorized environment that serially runs multiple environments.
envs = gym.vector.SyncVectorEnv([lambda: gym.make(args.env_id) for _ in range(args.num_envs)])
# envs
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions.categorical import Categorical
def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
# Described in `Exact solutions to the nonlinear dynamics of learning in deep linear neural networks`
torch.nn.init.orthogonal_(layer.weight, std)
torch.nn.init.constant_(layer.bias, bias_const)
return layer
class Agent(nn.Module):
def __init__(self, envs):
super().__init__()
self.critic = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 1), std=1.0),
)
self.actor = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
)
def get_value(self, x):
return self.critic(x)
def get_action_and_value(self, x, action=None):
logits = self.actor(x)
probs = Categorical(logits=logits)
if action is None:
action = probs.sample()
return action, probs.log_prob(action), self.critic(x)
agent = Agent(envs=envs)
optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
# ALGO Logic: Storage setup
obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape)
actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape)
logprobs = torch.zeros((args.num_steps, args.num_envs))
rewards = torch.zeros((args.num_steps, args.num_envs))
dones = torch.zeros((args.num_steps, args.num_envs))
values = torch.zeros((args.num_steps, args.num_envs))
# start the game
next_obs, _ = envs.reset(seed=1) # (num_envs, observation_space)
next_obs = torch.Tensor(next_obs)
next_done = torch.zeros(args.num_envs)
args.batch_size = int(args.num_envs * args.num_steps)
args.minibatch_size = int(args.batch_size // args.num_minibatches)
args.num_iterations = args.total_timesteps // args.batch_size
def train():
global next_obs, next_done
for iteration in range(1, args.num_iterations + 1):
# collect data
for step in range(args.num_steps):
obs[step] = next_obs
dones[step] = next_done
# ALGO LOGIC: action logic
with torch.no_grad():
action, logprob, value = agent.get_action_and_value(next_obs)
values[step] = value.flatten() # (num_envs, 1)
actions[step] = action # (num_envs)
logprobs[step] = logprob # (num_envs)
# execute the game
next_obs, reward, terminations, truncations, infos = envs.step(action.numpy())
next_done = np.logical_or(terminations, truncations)
next_obs, next_done = torch.Tensor(next_obs), torch.Tensor(next_done)
rewards[step] = torch.tensor(reward).view(-1)
# compute advantages and rewards-to-go
with torch.no_grad():
next_value = agent.get_value(next_obs).reshape(1, -1)
advantages = torch.zeros_like(rewards)
lastgaelam = 0
for t in reversed(range(args.num_steps)):
if t == args.num_steps - 1:
nextnonterminal = 1.0 - next_done
nextvalues = next_value
else:
nextnonterminal = 1.0 - dones[t + 1]
nextvalues = values[t + 1]
delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
returns = advantages + values
# flatten the batch
b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
b_logprobs = logprobs.reshape(-1)
b_advantages = advantages.reshape(-1)
b_returns = returns.reshape(-1)
b_values = values.reshape(-1)
# Optimizing the policy and value network
b_inds = np.arange(args.batch_size)
for epoch in range(args.update_epochs):
np.random.shuffle(b_inds)
for start in range(0, args.batch_size, args.minibatch_size):
end = start + args.minibatch_size
mb_inds = b_inds[start: end]
_, newlogprob, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])
logratio = newlogprob - b_logprobs[mb_inds]
ratio = logratio.exp()
with torch.no_grad():
# calculate approx_kl http://joschu.net/blog/kl-approx.html
approx_kl = ((ratio - 1) - logratio).mean()
mb_advantages = b_advantages[mb_inds]
mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
# Policy loss
pg_loss1 = -mb_advantages * ratio
pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
pg_loss = torch.max(pg_loss1, pg_loss2).mean()
# Value loss
newvalue = newvalue.view(-1)
v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
v_clipped = b_values[mb_inds] + torch.clamp(
newvalue - b_values[mb_inds],
-args.clip_coef,
args.clip_coef)
v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
v_loss = 0.5 * v_loss_max.mean()
loss = pg_loss + v_loss * args.vf_coef
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
optimizer.step()
if epoch == args.update_epochs - 1 and iteration % 50 == 0:
print(iteration, loss.item())
# Save model after training
torch.save(agent.state_dict(), "ppo_agent.pth")
envs.close()
def eval_model():
agent.load_state_dict(torch.load("ppo_agent.pth"))
agent.eval() # Switch to evaluation mode
env = gym.make(args.env_id, render_mode='human')
for i in range(5): # Run 5 episodes
obs, _ = env.reset()
for t in range(500): # Max steps for CartPole-v1
env.render()
with torch.no_grad():
obs_tensor = torch.from_numpy(obs).float().unsqueeze(0)
action, _, _ = agent.get_action_and_value(obs_tensor)
obs, reward, terminated, truncated, _ = env.step(action.item())
if terminated or truncated:
print(f"Episode {i+1} finished after {t+1} timesteps")
break
env.close()
if __name__ == "__main__":
train()
eval_model()
带有仿真环境的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号