大模型-强化学习Belman方程-71
第一步:强化学习到底是什么? (The Big Picture)
想象一下你正在训练一只小狗。这个过程和强化学习非常相似:
智能体 (Agent):你的小狗。在RL中,这就是我们试图训练的模型或算法。
环境 (Environment):你所在的房间或公园。在RL中,这是智能体所处的外部世界。
状态 (State):小狗当前所处的情况,比如它正“坐在”你面前。在RL中,这代表了环境的一个具体快照。
动作 (Action):小狗可以做出的行为,比如“打滚”、“握手”或“原地不动”。在RL中,这是智能体可以执行的操作。
奖励 (Reward):你给小狗的零食或口头表扬。在RL中,这是一个数值信号,用来告诉智能体某个动作是好是坏。
强化学习的目标 就是让智能体(小狗)学会在不同的状态下,做出能让它获得的 长期累积奖励 (cumulative reward) 最大化的动作。
请注意“长期”这个词。我们不希望小狗只为了眼前的一块零食而做出短视的决定,我们希望它能学会一整套能持续获得奖励的行为模式。
第二步:引入“价值”的概念 (Value Function)
现在,问题来了:在某个状态下,我们怎么知道哪个动作是“好”的呢?或者更进一步,我们怎么衡量一个“状态”本身是好是坏?
比如,对于小狗来说,“听到‘握手’指令并伸出爪子”这个状态,就比“在沙发上搞破坏”这个状态要好,因为它更有可能在未来获得奖励。
为了量化一个状态的好坏,我们引入了 价值函数 (Value Function) 的概念。价值函数有两种主要形式:
状态价值函数 V(s) (State-Value Function):它衡量的是“处于状态 s 有多好?”。它的值等于从状态 s 开始,遵循某一策略 (Policy) 所能获得的 未来奖励的期望总和。
状态-动作价值函数 Q(s,a) (Action-Value Function):它衡量的是“在状态 s 下,执行动作 a 有多好?”。它的值等于在状态 s 下执行动作 a后,再遵循某一策略所能获得的 未来奖励的期望总和。这个函数通常被称为“Q值”(Q-value),大名鼎鼎的Q-learning算法就是基于它。
简单来说:
V(s):这个位置好不好?
Q(s,a):在这个位置做这个动作好不好?
第三步:贝尔曼方程登场 (The Bellman Equation)
好了,我们知道了价值函数很重要,但怎么计算它呢?贝尔曼方程就是用来计算这些价值函数的。
贝尔曼方程的核心思想非常优美和直观,它基于一个简单的递归逻辑:
“一个状态的价值,等于你离开它时获得的即时奖励,加上你将要进入的下一个状态的价值。”
让我们把这个思想用更精确的语言来描述。
- 状态价值函数 V(s) 的贝尔曼方程
想象一下,你正处于状态 s。你可以选择执行一个动作 a。执行完动作 a 后:
你会立即得到一个奖励 R(s,a)。
你会转移到一个新的状态 s′
。
那么,从状态 s 开始的长期价值 V(s),就可以分解成 即时奖励 和 未来所有后续状态的价值 之和。
考虑到从状态 s 出发可能可以执行多种动作,而且执行某个动作后也可能随机转移到不同的新状态 s′
,我们需要用期望(求平均)来表示这种不确定性。
因此,V(s) 的贝尔曼方程可以写成:
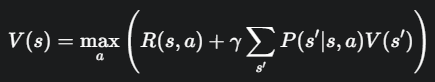

直观理解:为了计算当前状态 s 的价值,我们“向前看一步”,考虑所有可能的动作 a。对于每个动作,我们计算它的价值,这个价值等于即时奖励 R(s,a) 加上未来(被折扣后的)新状态 s′的价值 V(s′)。最后,我们选择那个能让这个总和最大的动作,其对应的总和就是当前状态 s 的最优价值。
Q值函数 Q(s,a) 的贝尔曼方程
Q 函数的贝尔曼方程思路完全一样,但它计算的是“状态-动作对”的价值:
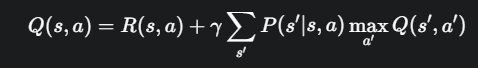

直观理解:在状态 s 执行动作 a 的价值,等于你获得的立即奖励,加上你到达新状态 s′后,从那个新状态出发所能获得的最大未来价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号