大模型-qwen3 模型结构解读-66
参考:https://zhuanlan.zhihu.com/p/1901014191235633835
Decoder-Only架构
Qwen3 Dense的模型结构与Qwen2大体相同,只是在注意力层的加入了对q和k的归一化。而Qwen3 MoE模型则是把某些MLP层替换为了MoE层。两个模型的结构图如下:
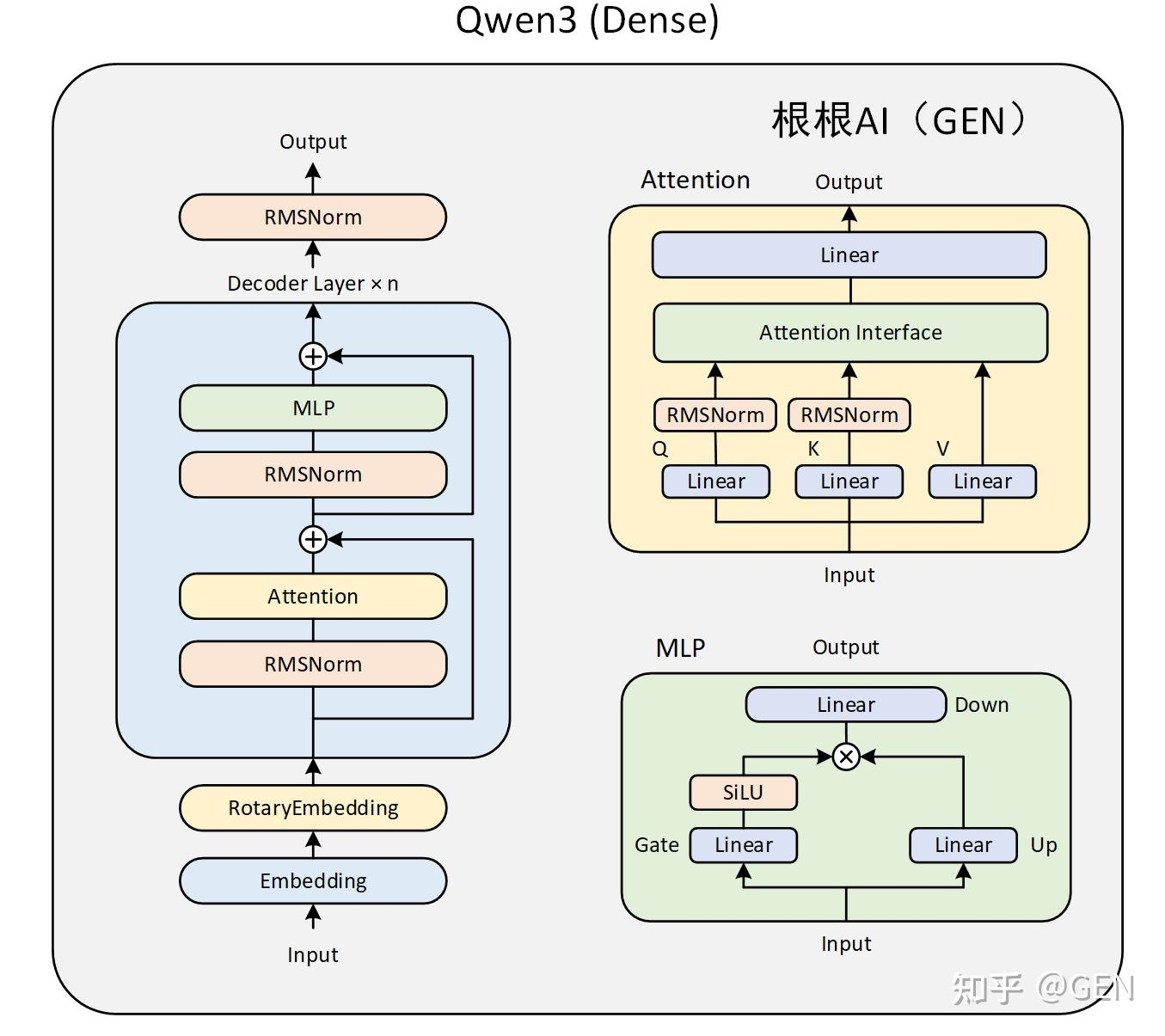
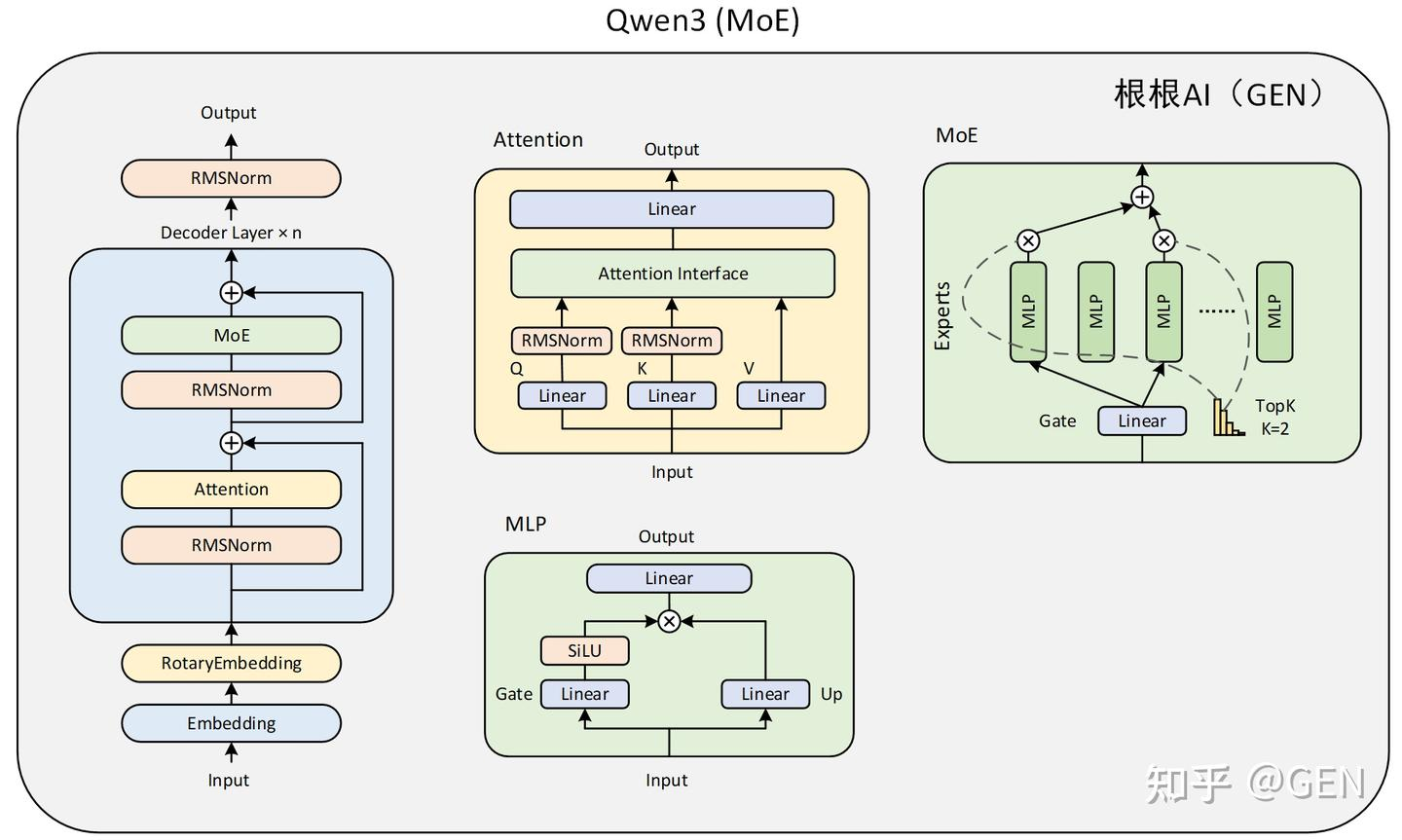
代码解读
Attention 和 MLP 模块开始,逐步向上分析,因为优化的关键细节都在这些底层模块中。
Qwen3Attention - 注意力模块
这是 Qwen3 模型的一个特色模块,它包含了张量并行、算子融合和独特的Q/K归一化。
class Qwen3Attention(nn.Module):
def __init__(...):
# ... 计算每个GPU上的头数 ...
self.num_heads = self.total_num_heads // tp_size # Q头的数量 tp_size gpu卡的数量
self.num_kv_heads = max(1, self.total_num_kv_heads // tp_size) # KV头的数量 (支持GQA)
# 核心优化1: QKV算子融合 + 列并行
# QKVParallelLinear 将 q_proj, k_proj, v_proj 合并成一个大的列并行线性层。
self.qkv_proj = QKVParallelLinear(...)
# 核心优化2: 与列并行配对的行并行
# o_proj (输出投影) 是一个行并行层,可以直接接收注意力计算后的分片输出,
# 从而避免了在注意力计算后进行 all_gather 通信,这是关键性能优化。
self.o_proj = RowParallelLinear(...)
# ... 初始化旋转位置编码 RoPE ...
# Qwen3 独有特性:在应用RoPE前,对Q和K的每个头进行RMSNorm
self.q_norm = RMSNorm(self.head_dim, eps=rms_norm_eps)
self.k_norm = RMSNorm(self.head_dim, eps=rms_norm_eps)
def forward(...):
# 1. 一次性计算出 Q, K, V
qkv = self.qkv_proj(hidden_states)
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
# 2. 对Q和K进行 per-head 的归一化 (Qwen3 特色)
q_by_head = q.view(-1, self.num_heads, self.head_dim)
q_by_head = self.q_norm(q_by_head)
q = q_by_head.view(q.shape)
# 对K也执行相同操作...
# 3. 应用旋转位置编码
q, k = self.rotary_emb(positions, q, k)
# 4. 执行注意力计算
o = self.attn(q, k, v)
# 5. 输出投影,这是一个行并行操作,其内部隐式包含了 all_reduce
output = self.o_proj(o)
return output
设计解读:
性能: QKVParallelLinear (列并行) 和 o_proj (行并行) 的配对使用,是张量并行中的黄金法则,它消除了昂贵的 all-gather 通信。
Qwen3 特色: 与标准 Llama 模型不同,Qwen3 在 QKV 投影之后,对 Q 和 K 的每个头单独进行了 RMSNorm。这可能是为了改善训练稳定性和模型性能的一种独特设计。
GQA (Grouped-Query Attention): num_heads 和 num_kv_heads 的数量不同,表明它使用了分组查询注意力,让多个查询头共享同一组键/值头,以减少 KV 缓存的显存占用,提升推理速度。
Qwen3MLP - 前馈网络模块
这个模块同样采用了算子融合和张量并行技术
class Qwen3MLP(nn.Module):
def __init__(...):
# 核心优化1: Gate/Up 算子融合 + 列并行
# MergedColumnParallelLinear 将 gate_proj 和 up_proj 两个线性层
# 合并成一个单一的、更高效的列并行层。
self.gate_up_proj = MergedColumnParallelLinear(
hidden_size,
[intermediate_size] * 2, # 输出维度是两倍的 intermediate_size
bias=False,
)
# 核心优化2: 与列并行配对的行并行
# down_proj 是一个行并行层,用于将维度降回 hidden_size。
self.down_proj = RowParallelLinear(...)
# 核心优化3: 融合激活函数
# SiluAndMul 将 SiLU(x) * y 这个操作融合在一个 CUDA kernel 中完成,
# 避免了两次独立的计算和内存读写,提升了效率。
self.act_fn = SiluAndMul()
def forward(self, x):
# 1. 一次性计算出 gate 和 up 的结果
gate_up = self.gate_up_proj(x)
# 2. 高效的融合激活
x = self.act_fn(gate_up)
# 3. 输出投影 (行并行)
x = self.down_proj(x)
return x
设计解读:
这个 MLP 模块是性能优化的典范。它将 FFN(前馈网络)中的两个线性层和一个激活函数相关的操作,通过融合和并行技术,优化为三个高效的步骤。
Qwen3DecoderLayer - 单个解码器层
这个模块将 Attention 和 MLP 组装在一起,并负责处理残差连接和层归一化(LayerNorm)。
class Qwen3DecoderLayer(nn.Module):
def __init__(...):
# ... 初始化 self_attn 和 mlp ...
self.input_layernorm = RMSNorm(...)
self.post_attention_layernorm = RMSNorm(...)
def forward(...):
# 这是一个非常清晰的 Pre-LN 架构实现
# 第一次残差连接
if residual is None:
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
else:
# vLLM/PagedAttention 中的优化:将 add 和 norm 融合
hidden_states, residual = self.input_layernorm(hidden_states, residual)
# 注意力计算
hidden_states = self.self_attn(...)
# 第二次残差连接
hidden_states, residual = self.post_attention_layernorm(hidden_states, residual)
# MLP 计算
hidden_states = self.mlp(hidden_states)
return hidden_states, residual
设计解读:
Pre-LN 架构: 先对输入进行归一化(input_layernorm),然后再送入自注意力模块。这种结构被认为比 Post-LN 架构训练起来更稳定。
高效的残差流: 代码通过显式地传递 residual 张量,清晰地管理了残差连接的数据流。其中 layernorm(x, residual) 的形式暗示了它可能调用一个融合了 add 和 norm 操作的 CUDA kernel,进一步提升效率。
Qwen3Model & Qwen3ForCausalLM - 顶层封装
这两个类负责将所有模块组装起来,并提供最终的模型接口。
class Qwen3Model(nn.Module):
def __init__(...):
# 并行化的词嵌入层
self.embed_tokens = VocabParallelEmbedding(...)
self.layers = nn.ModuleList([Qwen3DecoderLayer(config) for _ in range(config.num_hidden_layers)])
self.norm = RMSNorm(...) # 最终输出前的归一化
def forward(...):
hidden_states = self.embed_tokens(input_ids)
residual = None
for layer in self.layers:
hidden_states, residual = layer(...) # 逐层计算
hidden_states, _ = self.norm(hidden_states, residual)
return hidden_states
class Qwen3ForCausalLM(nn.Module):
# 这个 mapping 是“灵魂”所在,它告诉权重加载器如何将标准模型的权重
# (如 q_proj, k_proj) 映射到我们融合后的并行模块 (qkv_proj) 中。
packed_modules_mapping = {
"q_proj": ("qkv_proj", "q"),
"k_proj": ("qkv_proj", "k"),
"v_proj": ("qkv_proj", "v"),
"gate_proj": ("gate_up_proj", 0),
"up_proj": ("gate_up_proj", 1),
}
def __init__(...):
self.model = Qwen3Model(config)
# 并行化的语言模型头
self.lm_head = ParallelLMHead(...)
# 权重绑定 (Tie a.k.a Weight Tying)
if config.tie_word_embeddings:
self.lm_head.weight.data = self.model.embed_tokens.weight.data
# ...
设计解读:
端到端的并行化: 从词嵌入层 VocabParallelEmbedding 到每一层的并行计算,再到最终的 ParallelLMHead,整个模型完全构建在张量并行之上。
无缝加载: packed_modules_mapping 是一个非常优雅的设计。它使得这个高度优化的模型可以直接加载标准的、未经修改的 Hugging Face 模型权重,极大地提升了易用性。
权重绑定: tie_word_embeddings 是一种常见的技术,让词嵌入矩阵和最终的输出 lm_head 矩阵共享权重。这可以显著减少模型的参数量,并可能带来轻微的性能提升。
总结
这份代码是一个为实现极致推理性能而设计的 Qwen3 版本。它的每一处都体现了深度优化的思想:
最大化并行: 通过张量并行将模型切分到多个 GPU 上,解决了单卡显存瓶颈。
最小化通信: 通过列并行和行并行的精妙配对,消除了不必要的 GPU 间通信。
最大化融合: 通过算子融合(QKV融合、Gate/Up融合)和激活函数融合,减少了计算核心的启动开销和内存读写次数。
架构忠实度: 在进行大量优化的同时,精准复现了 Qwen3 独特的 per-head Q/K norm 等核心架构特性。
高易用性: 通过 packed_modules_mapping 机制,兼容标准模型权重,无需用户进行繁琐的权重转换。
这不仅仅是一份模型实现,更是一份关于如何在真实世界中部署和优化大语言模型的工程杰作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号