NLP基础知识学习(撰写中)
NLP入门总览
教材推荐:


实用文章


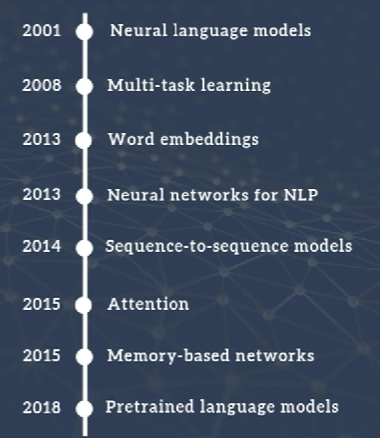
NLP领域的重要模型
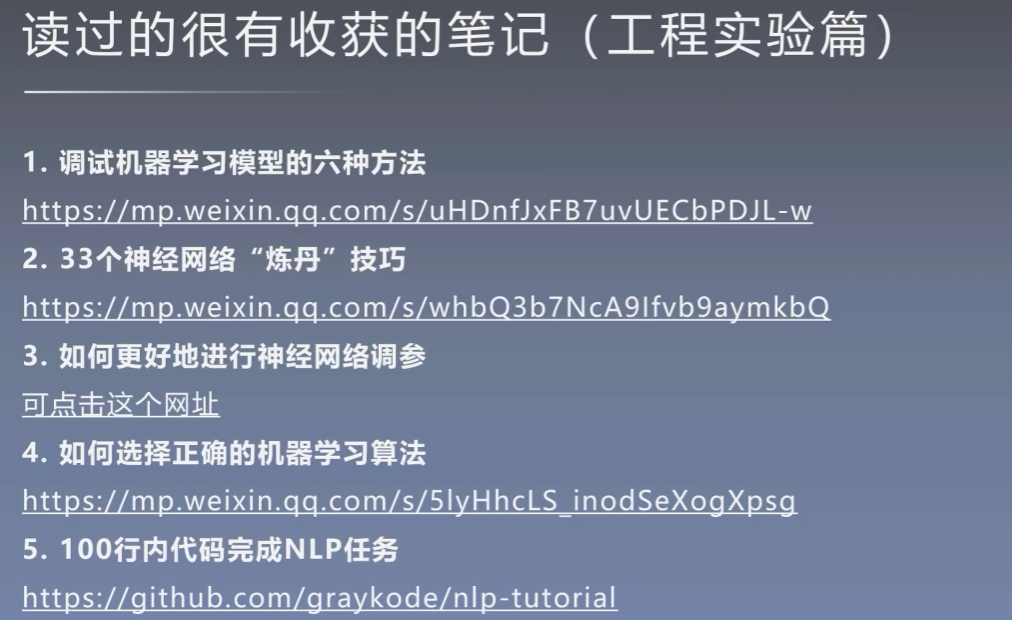
100行代码完成的NLP任务
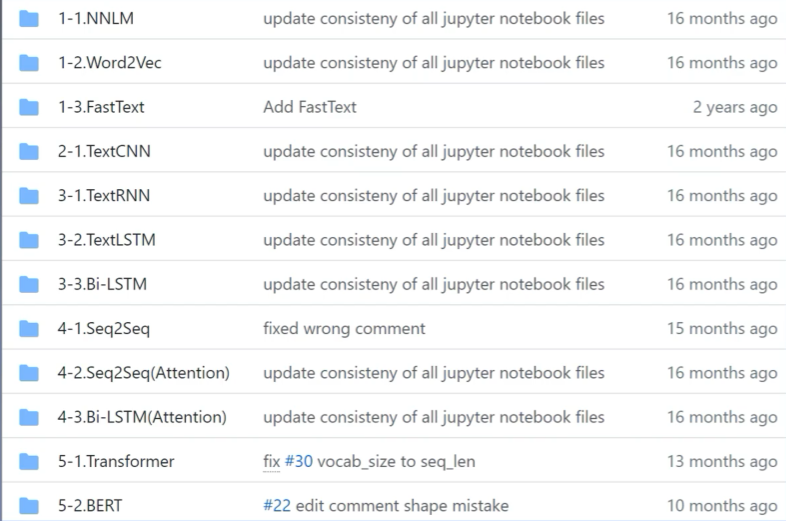
好的课程

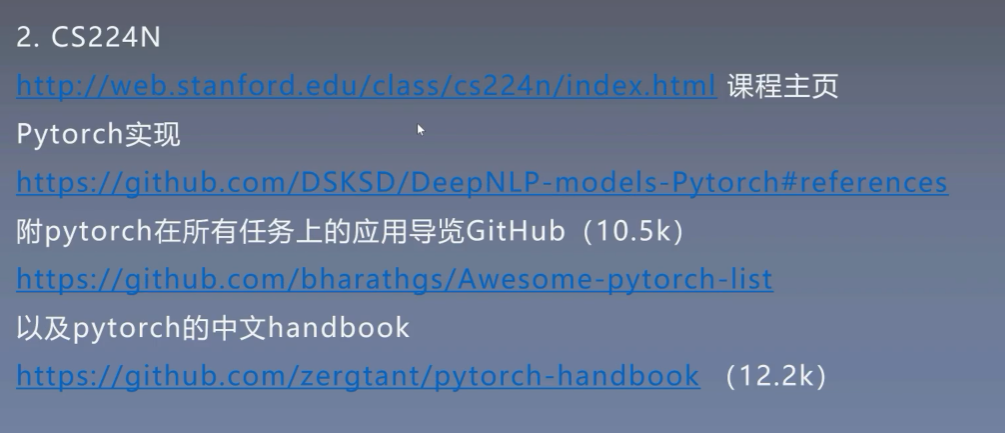
NLP领域的几个研究方向与公共数据集
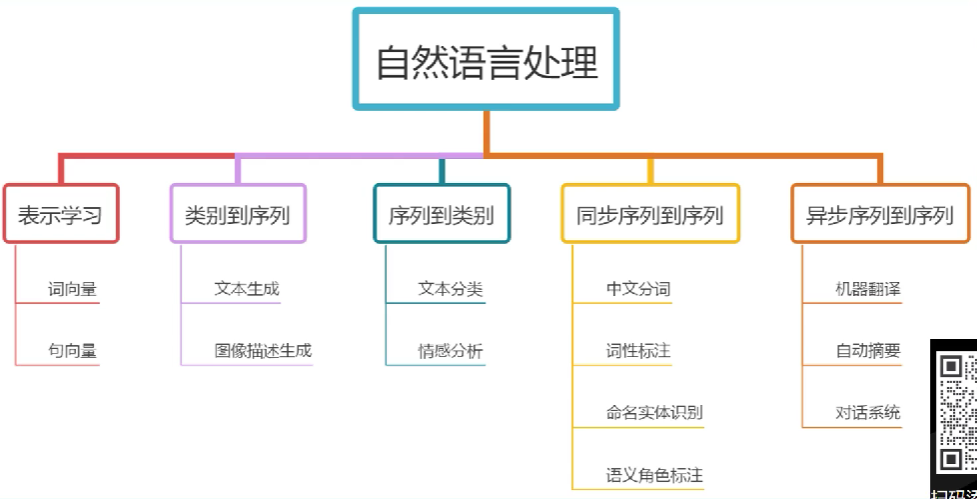
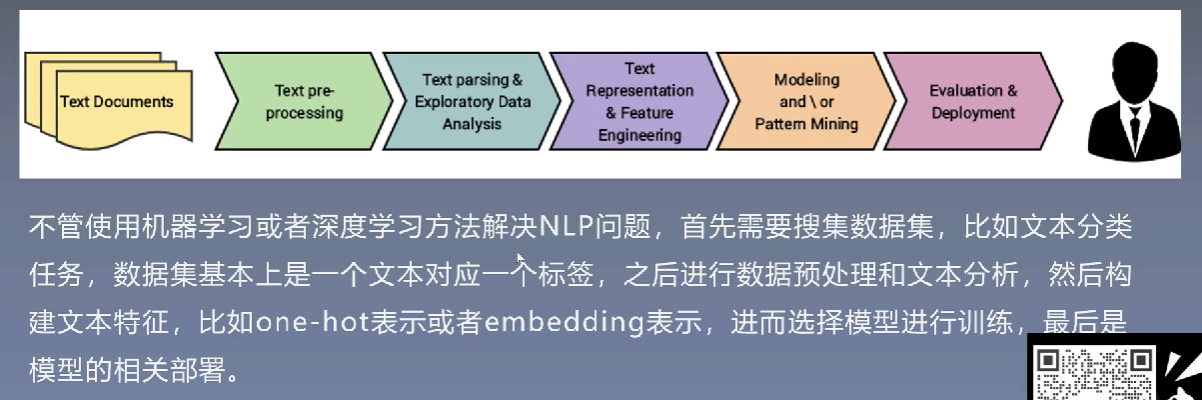
NLP的基本方法和流程
NLP基础知识
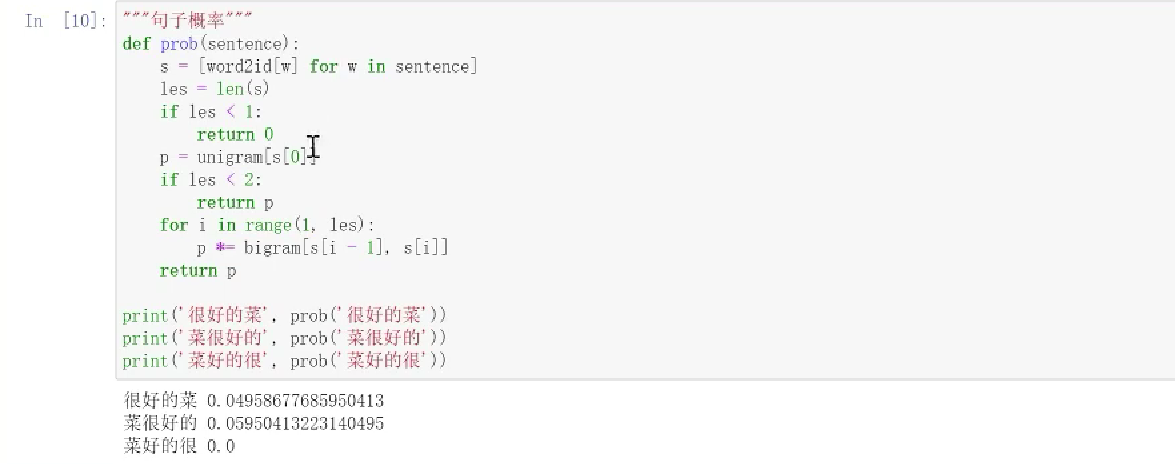
1、文本信息表示方法
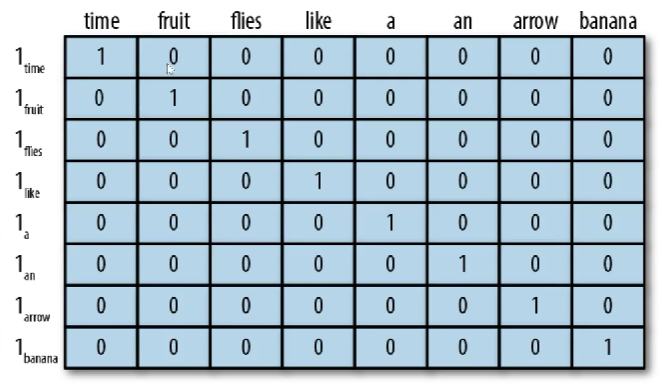
1.1 one-hot表示

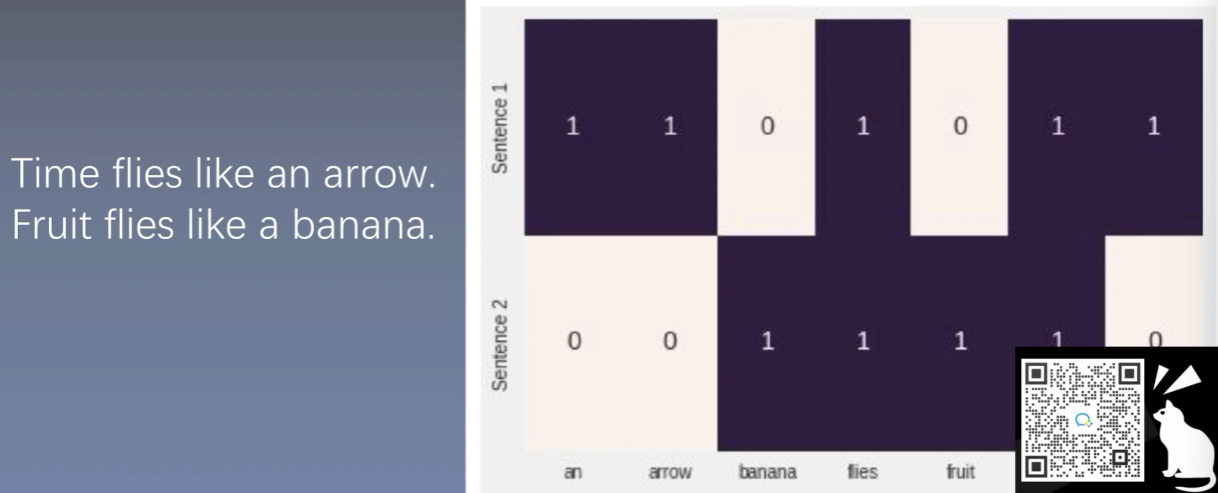
1.2 TF表示
是基于one-hot表示基础上对于每个词的统计,其实也可以理解为one-hot求和的结果

1.3 IDF表示
过于高频的词有时候反而会丢失掉文本真正有意义的词

1.4 TF-IDF表示

1.5 上述表示方法的缺陷

1.6 稠密编码
稠密编码其实就是词向量,后面的特征编码部分会进行详细介绍
2、NLP问题中的特征
2.1 直接可观测特征
-
单独词特征
![]()
-
文本特征
![]()

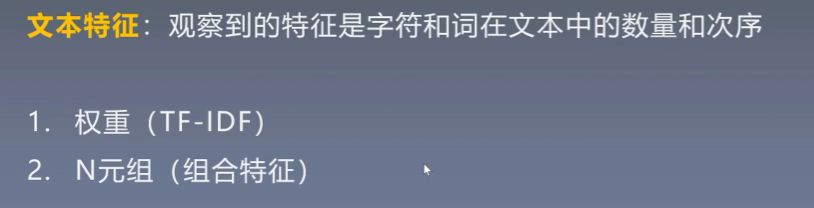
N元组(N-gram):
- 上下文词特征
![]()

2.2 可推断的语言学特征

句子结构
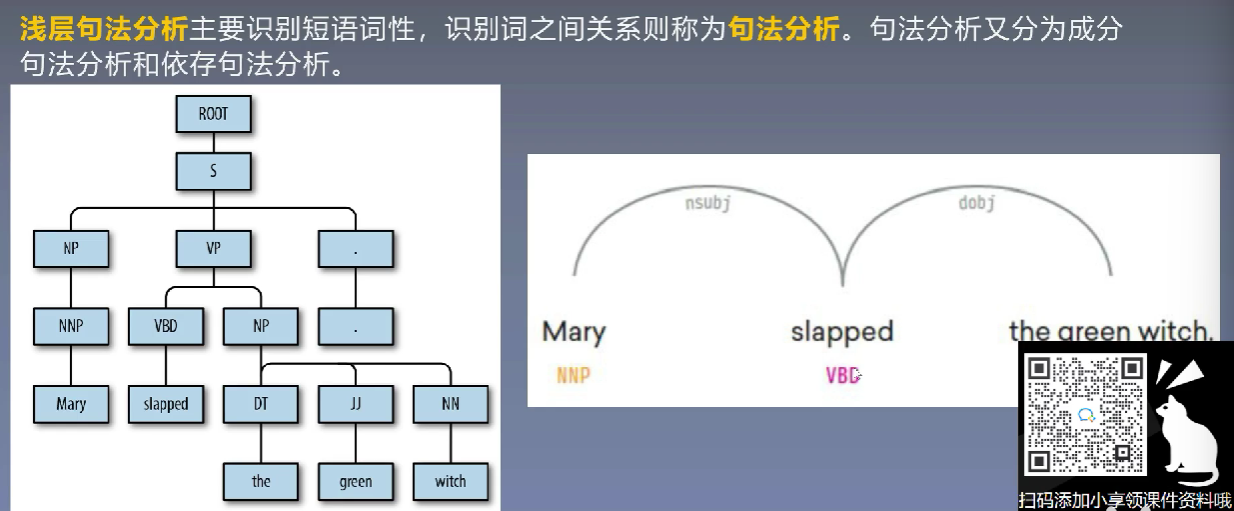
3、特征编码
3.1 onehot编码
词性之间没有太大的关系,采用onehot编码
3.2 稠密编码
将高维的稀疏数据压缩成低维的稠密数据

稠密编码的每个数据都要经过NN学习,将一个词作为输入学成一个词向量的过程就是词嵌入

稠密编码的优势:

3.3 组合稠密向量
-
基于窗口的特征
![]()
-
可变特征数目(CBOW)
不管一句话有多少个词,最后都只会获得一个向量,变成固定大小
![]()
-
其他特征输入
![]()



4、文本的向量化表示(嵌入)
4.1 如何获得词向量(稠密表示)
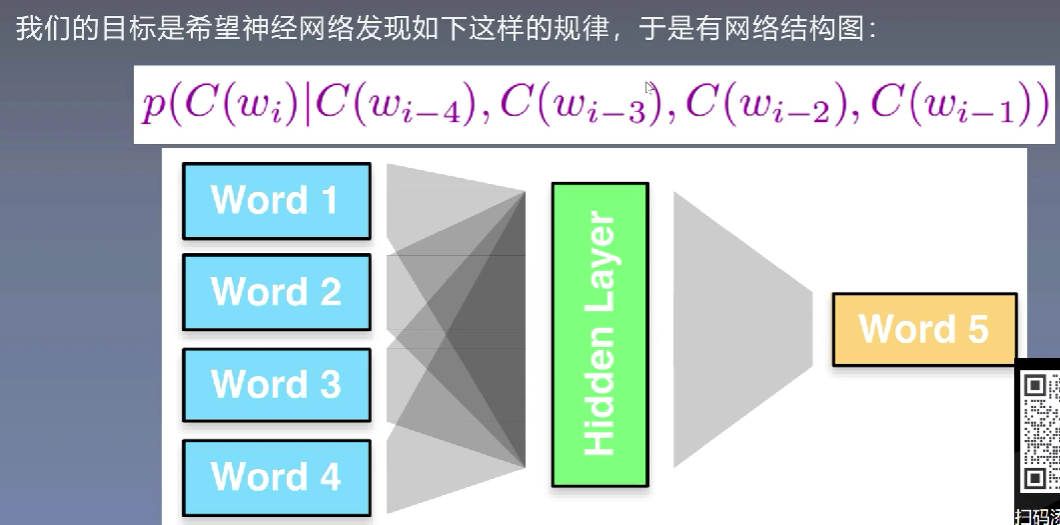
-
先使用one-hot表示每个词
![]()
-
再使用隐层映射为稠密向量
![]()
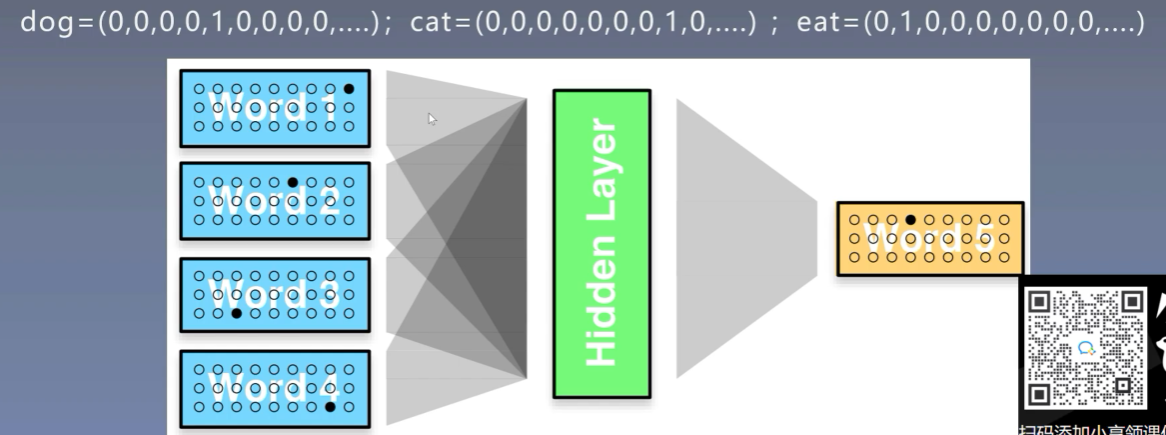
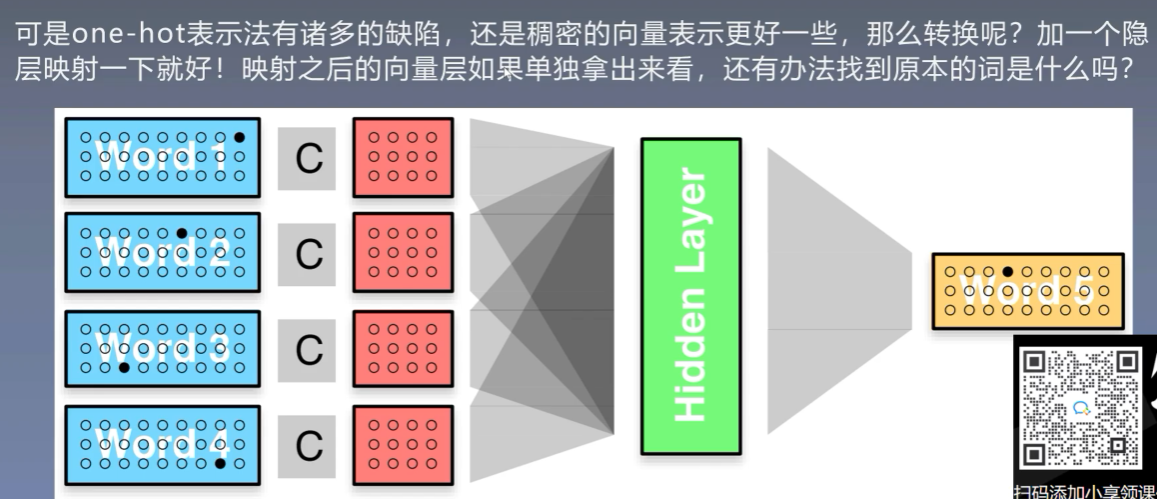
4.2 程序实现

我们可以发现使用one-hot进行映射其实第四个词映射的结果就是隐藏层的第四行。所以其实映射矩阵就是one-hot的查找表
4.3 结果
-
分布情况
![]()
-
向量间的关系
![]()

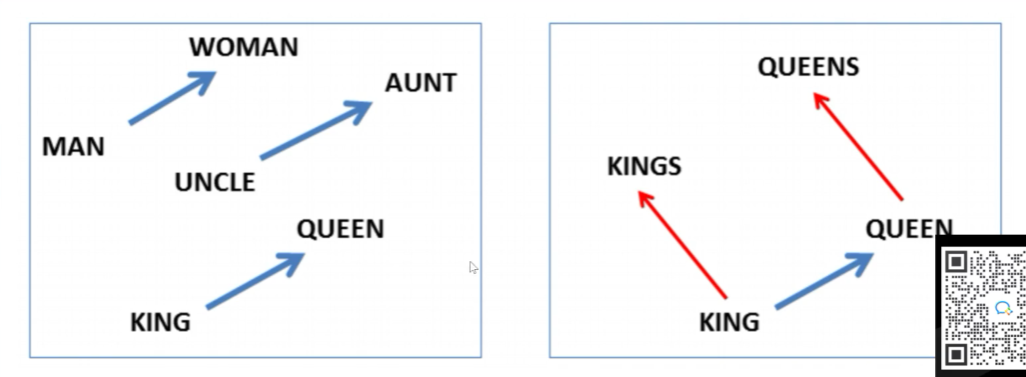
5、词嵌入的具体案例
6、统计语言模型简介
6.1 语言模型任务

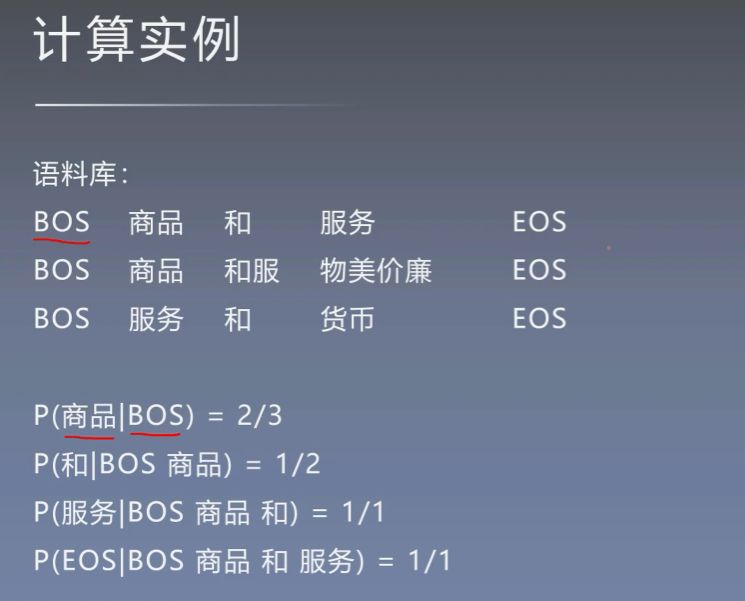
6.2 语言模型实例
构建一个语料库,除此以外的词本概率就为0。但是我们现实中根本无法涵盖所有的文本,而且随着样本的增大,每个句子的概率都会趋近于0,但是词表中的词会是重复的,所以构建单词列表

6.3 语言模型任务

贝叶斯公式



6.4 语言模型的改进方法

7、语言模型的实操
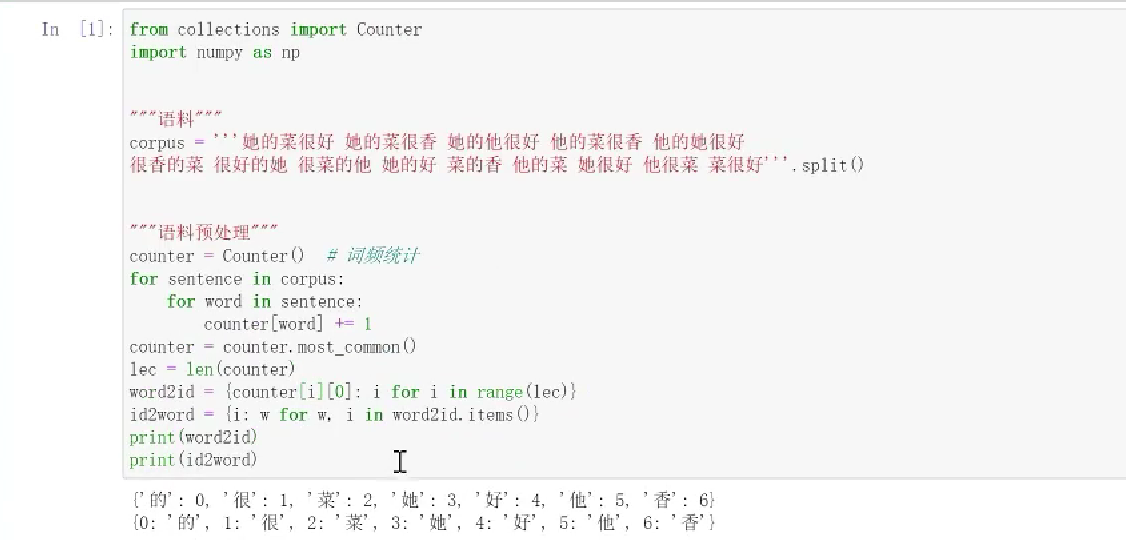
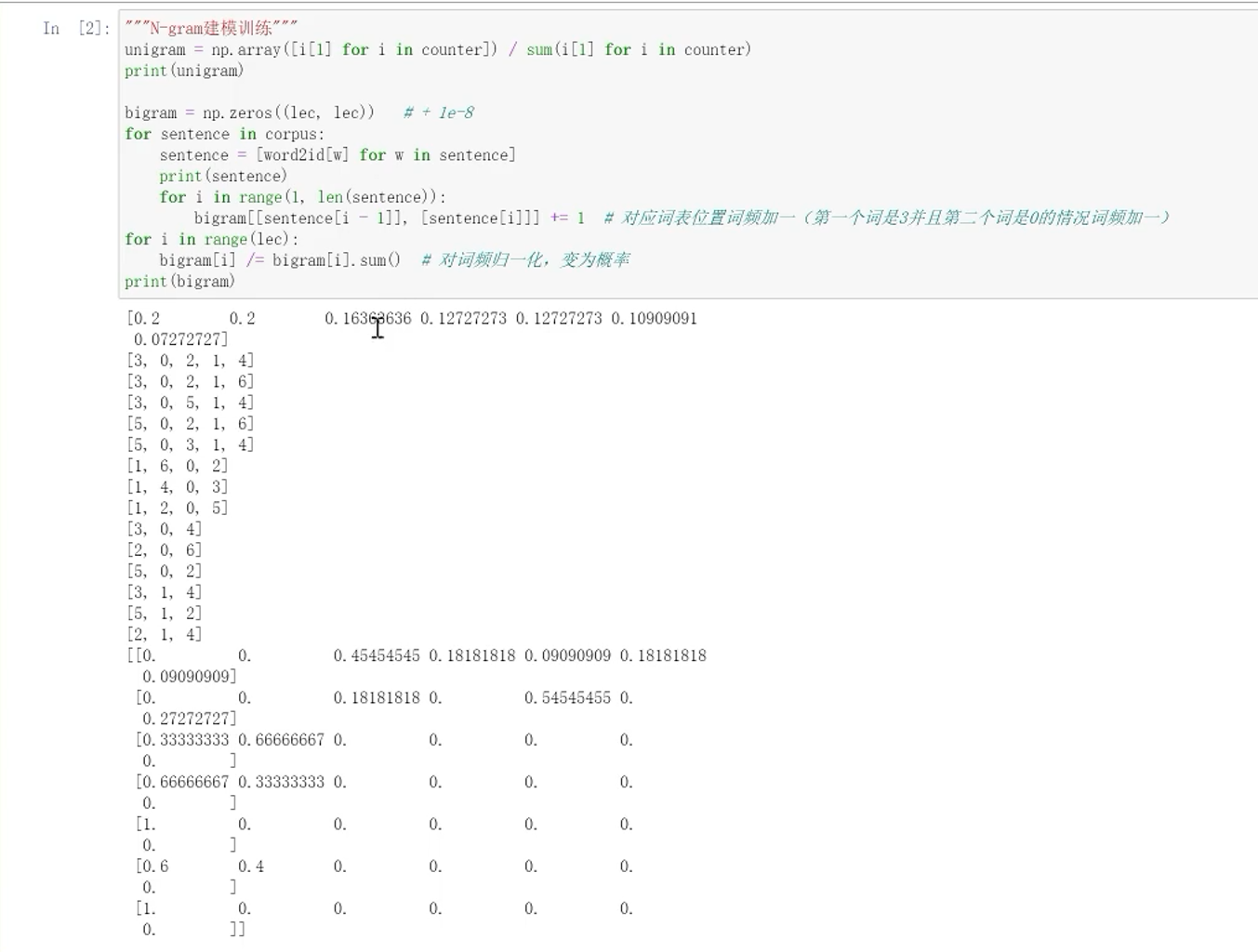
n阶马尔可夫
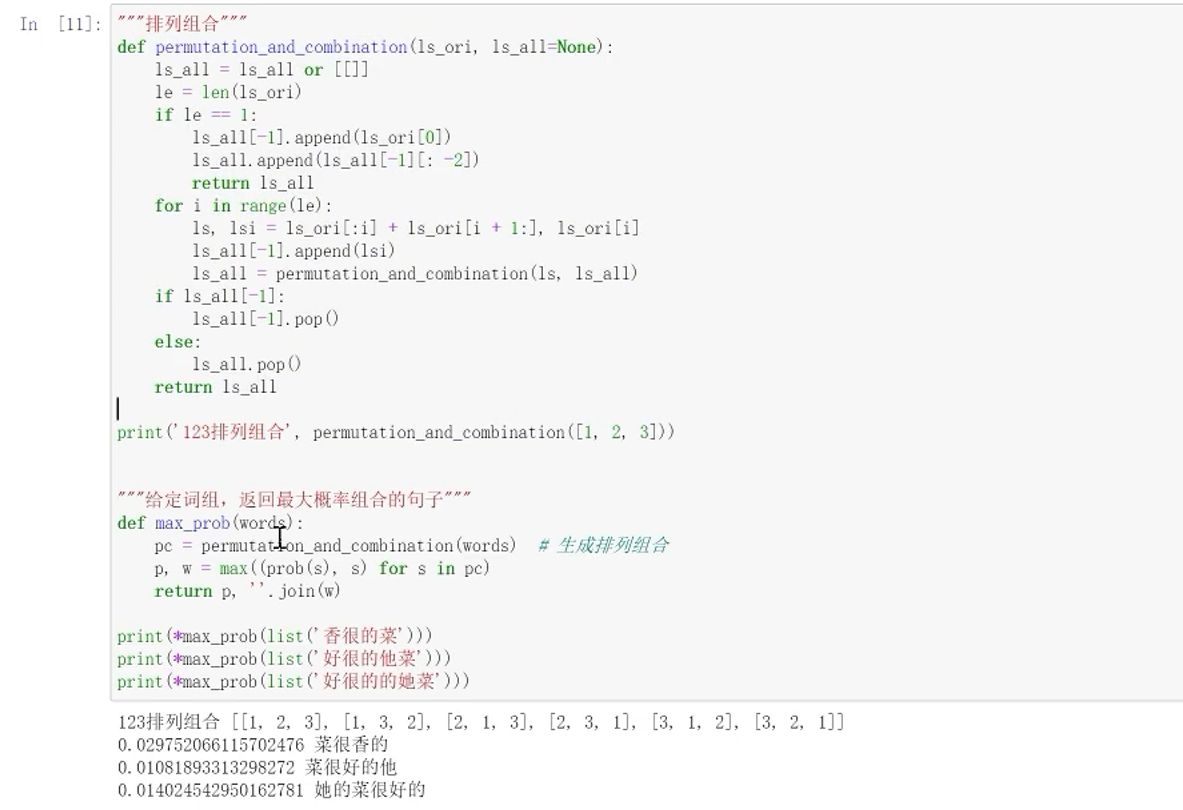
8、语言模型任务评估
8.1 信息熵

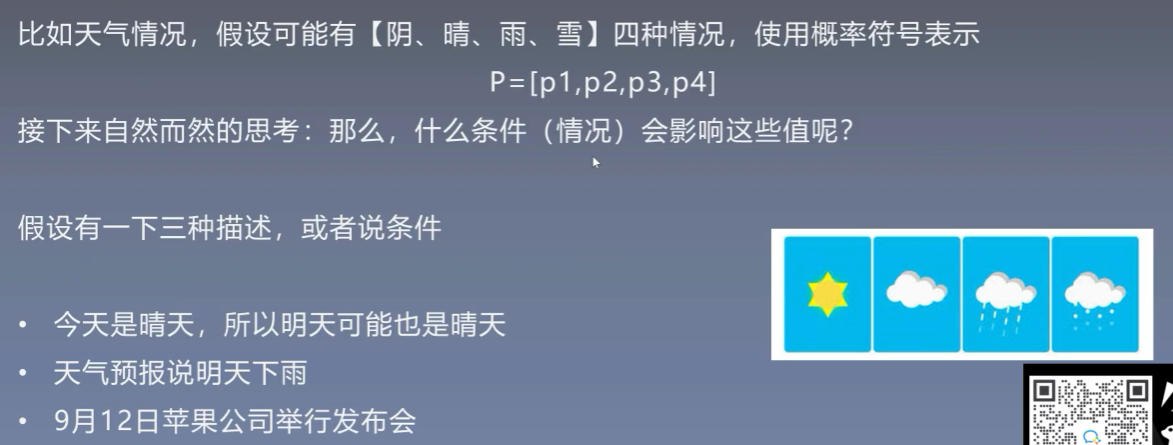
不确定程度从低到高



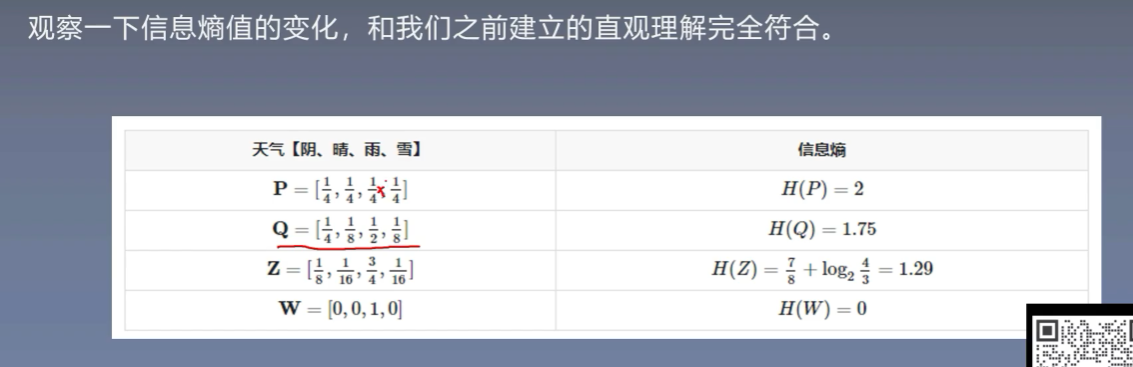
8.2 相对熵

8.3 交叉熵

8.4 困惑度
本质上就是一个交叉熵函数,两种语言模型必须在同一个语料库的背景下,比较困惑度才有意义



9.5 传统语言模型的限制

10、神经语言模型

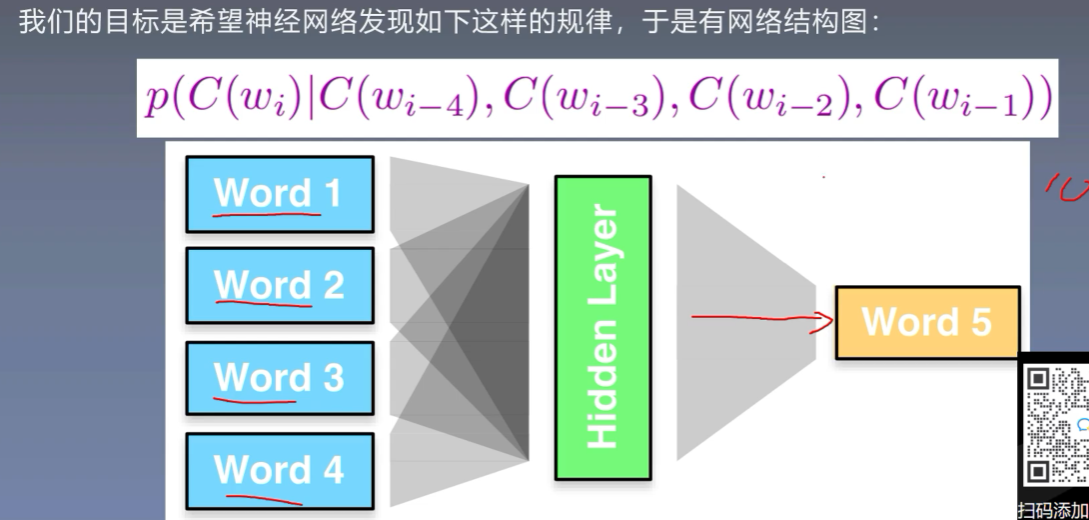
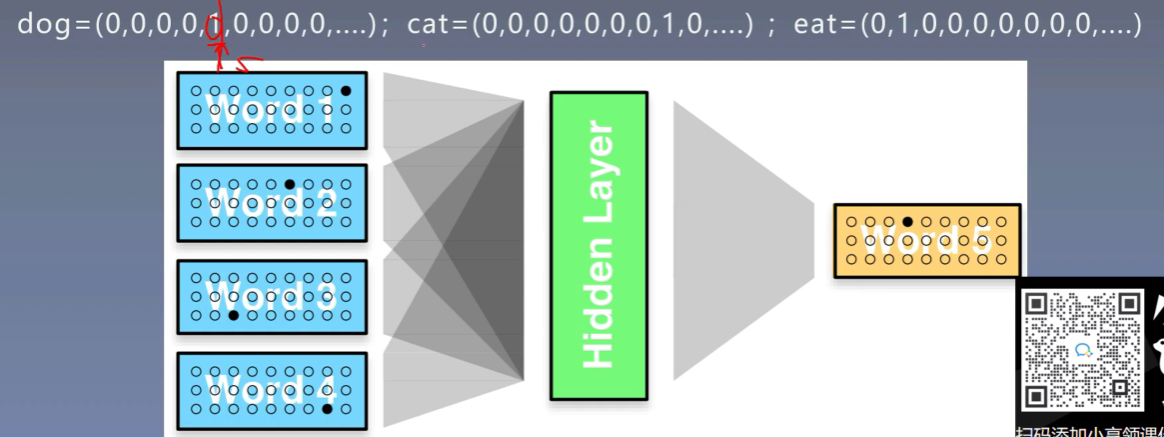
-
首先使用onehot表示每个词
![]()
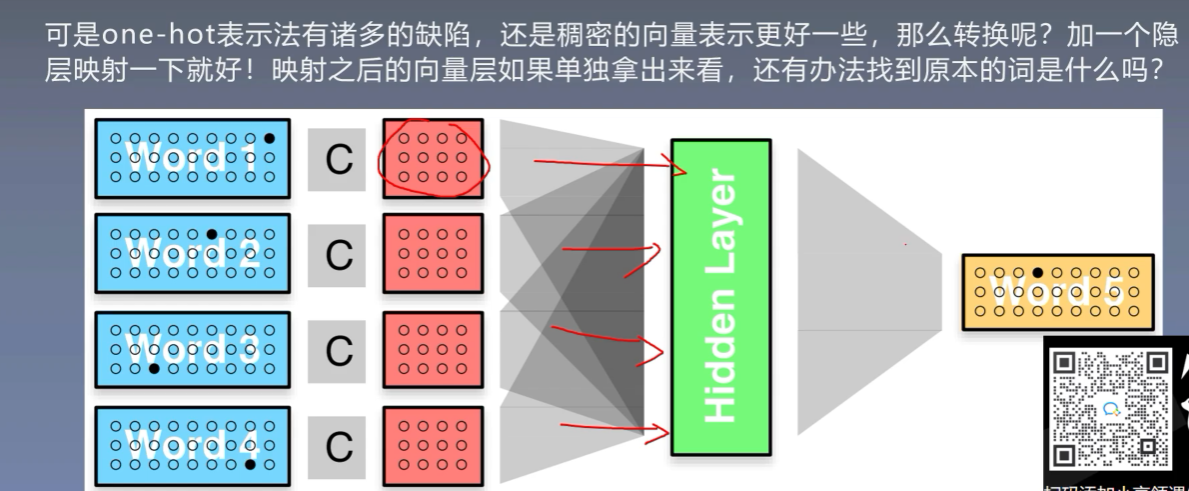
-
隐层转化为稠密向量
![]()
![]()

总结

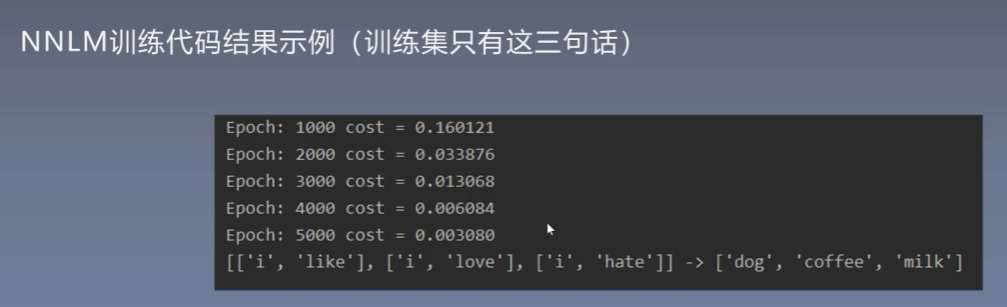
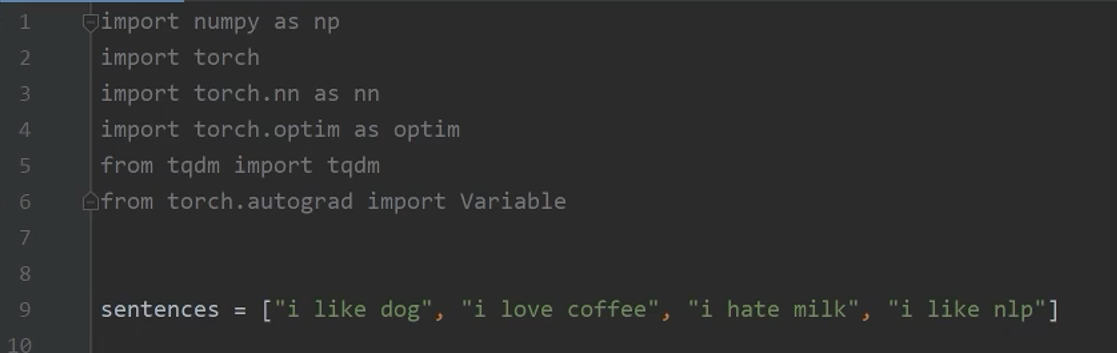
11、NNLM的实现

11.1 导入相关包并建立语料库
11.2 建立词表
-
以" "为分隔符获取所有的词
![]()
![]()
-
去重
![]()
![]()
-
word2id,id2word
![]()
![]()
-
划分类的数量
![]()
-
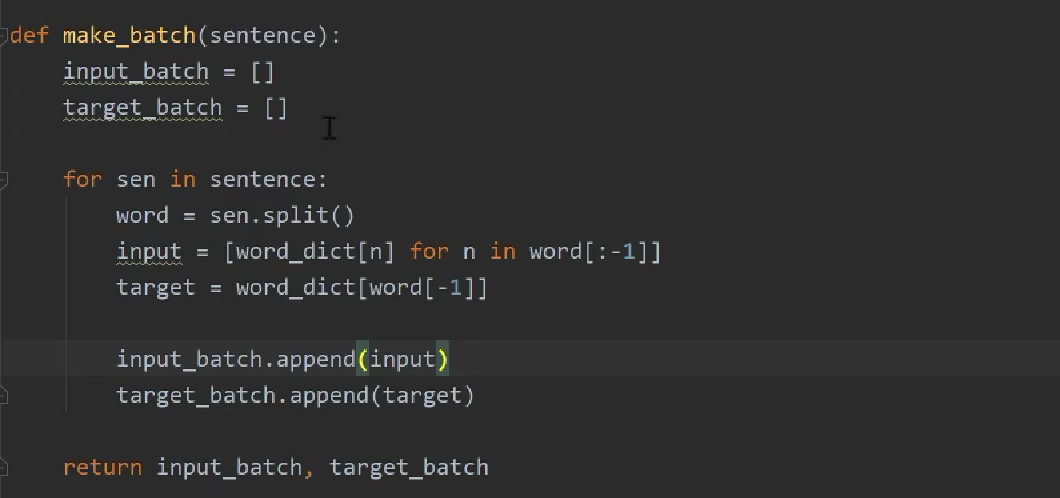
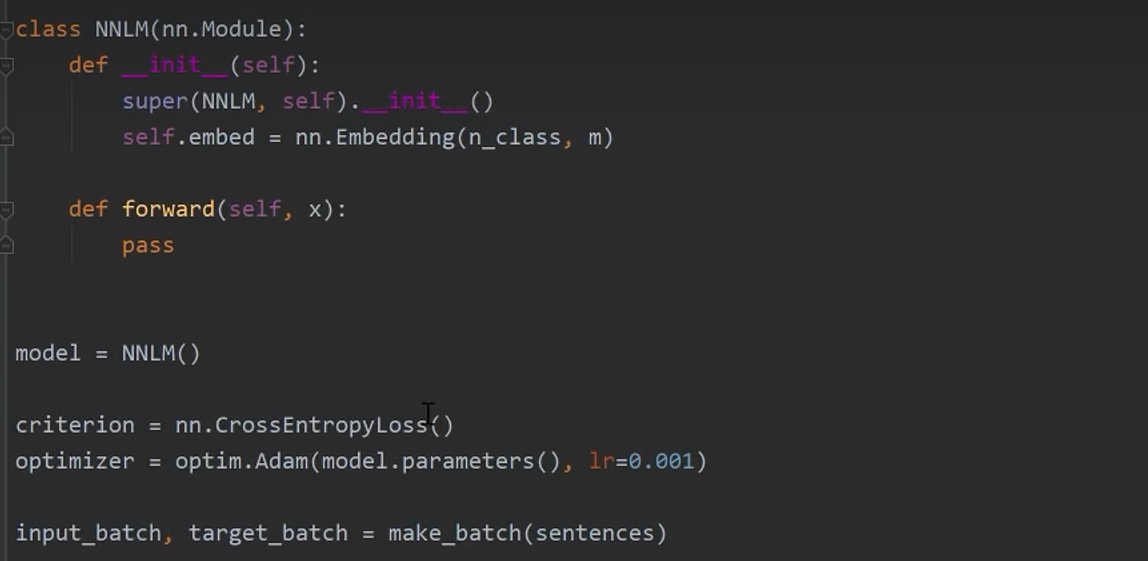
构建模型
![]()







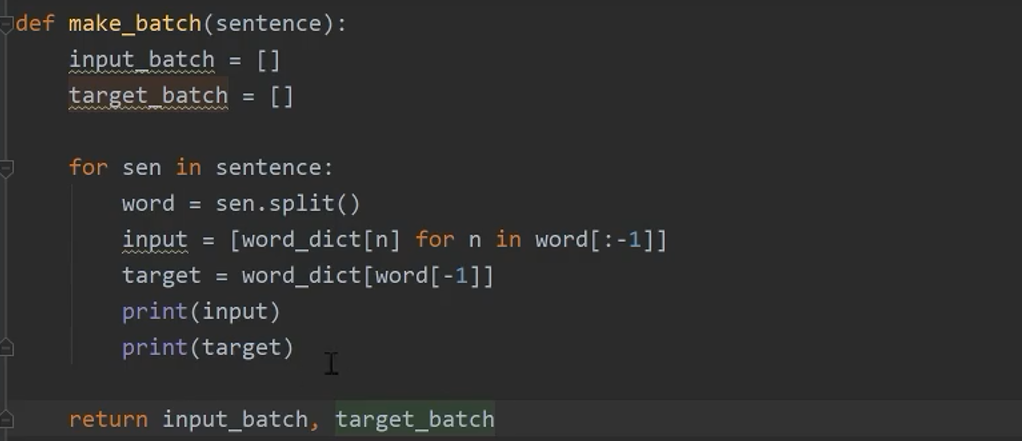
输出正确可以直接导出
-
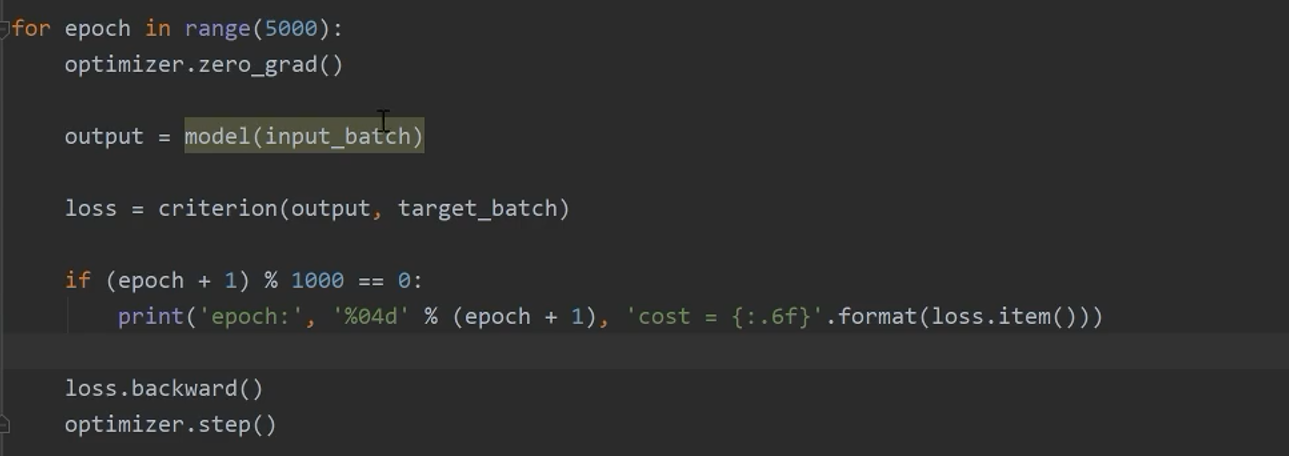
开始训练
![]()
-
预测结果
11.3 局限性

12、预训练好的词向量
12.1 预训练的词表示

12.2 获取方式
13、如何使用词表示

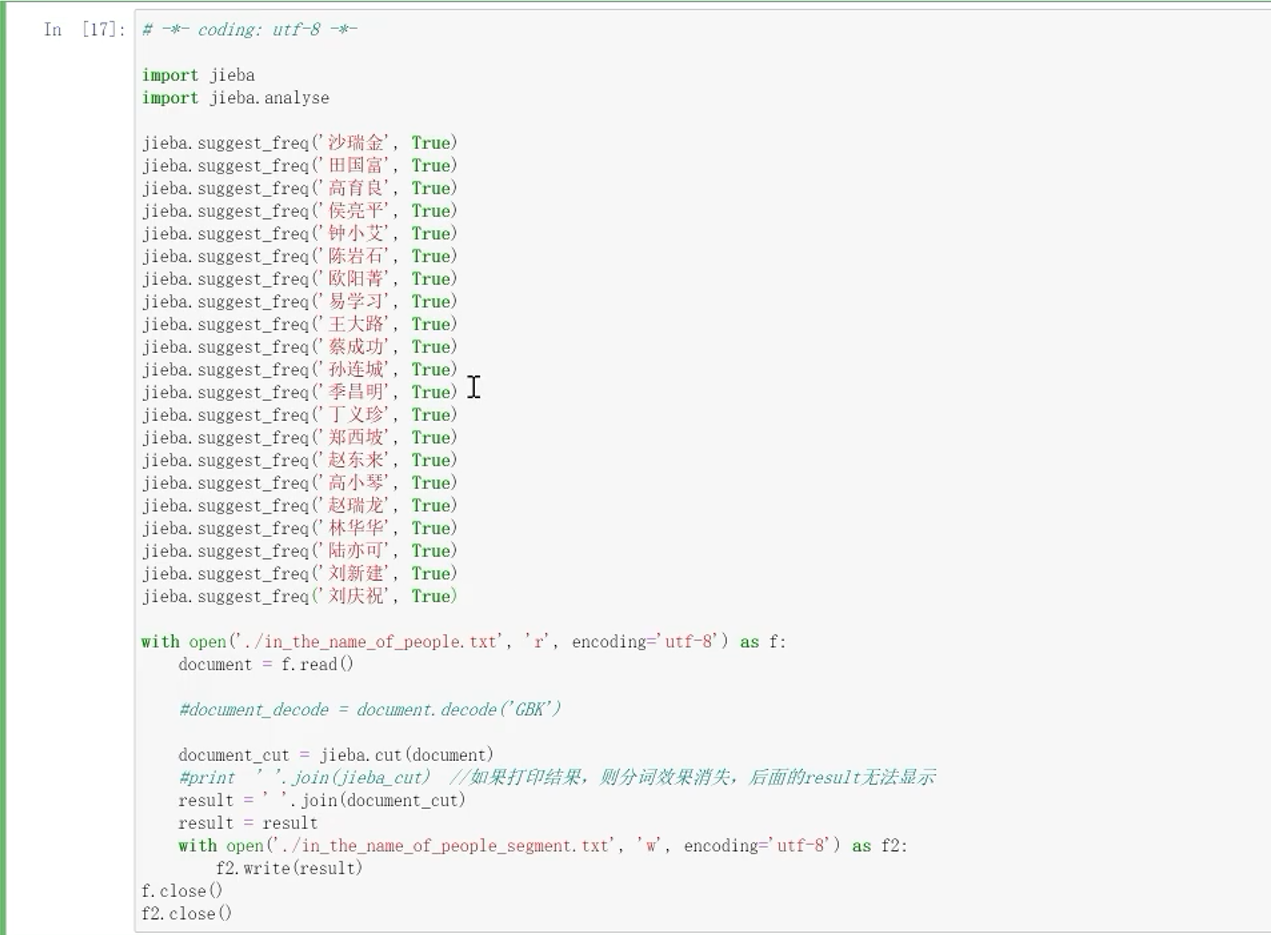
13.1 使用jieba进行分词
在jieba字典中添加人名
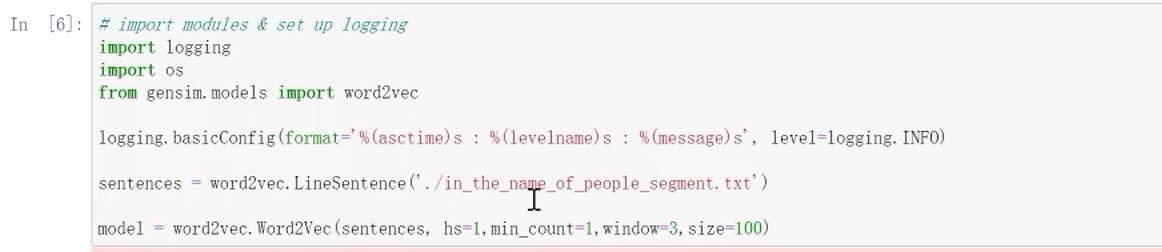
13.2 将其作为语料库开始训练

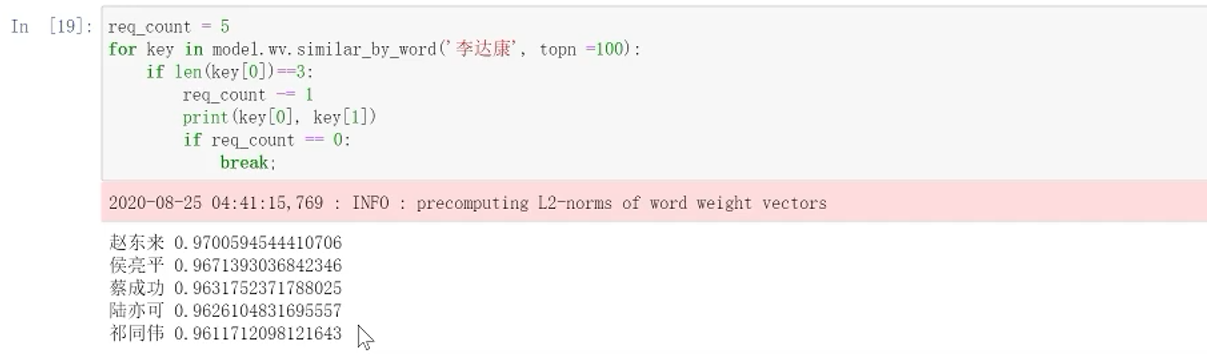
13.3 查看训练效果
查看和李达康最相近的词
查看赵东来
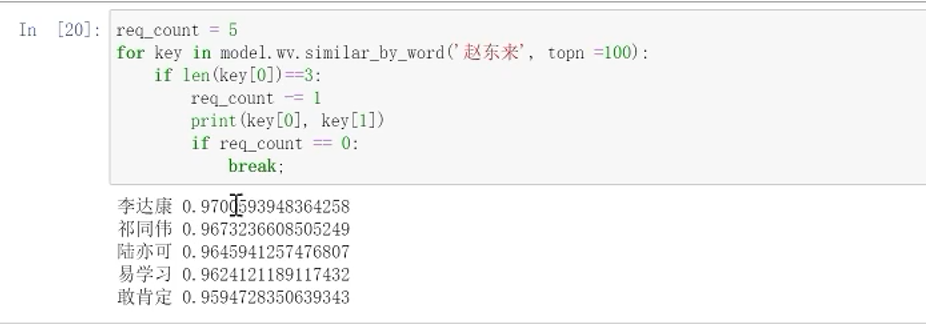
出现了敢学习这种错误的现象
高育良
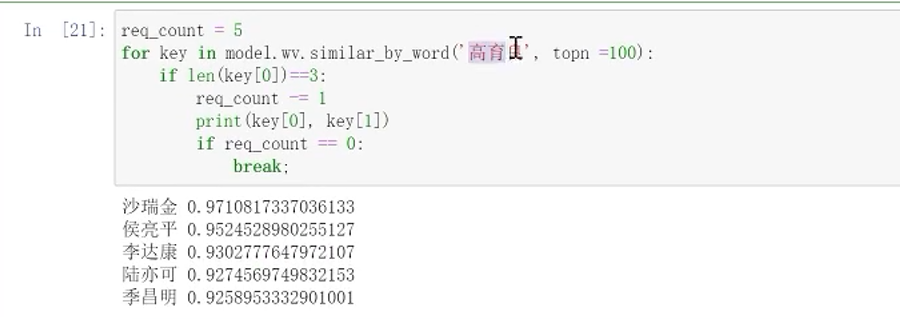
13.4 查看两个词之间的相关性和在一群词中找出不同的词
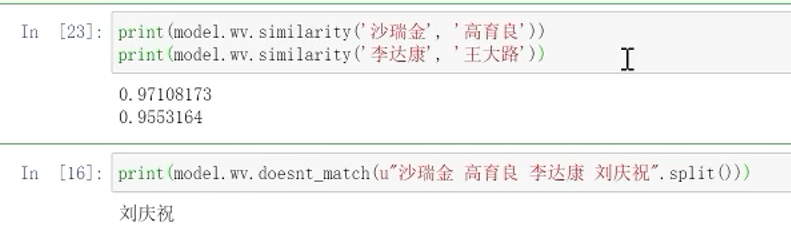
NLP必须掌握的经典模型
1、基本背景回顾

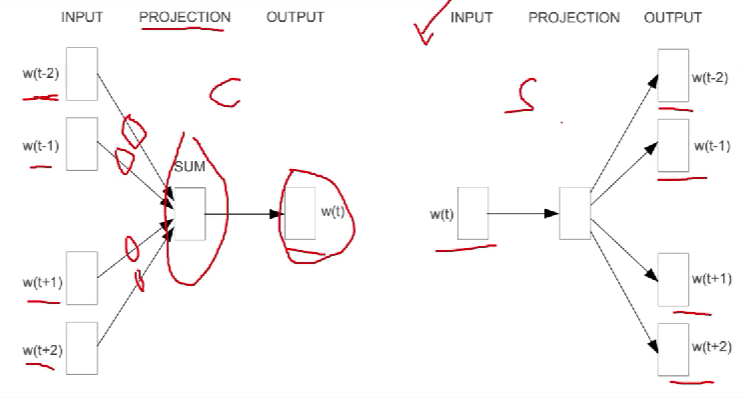
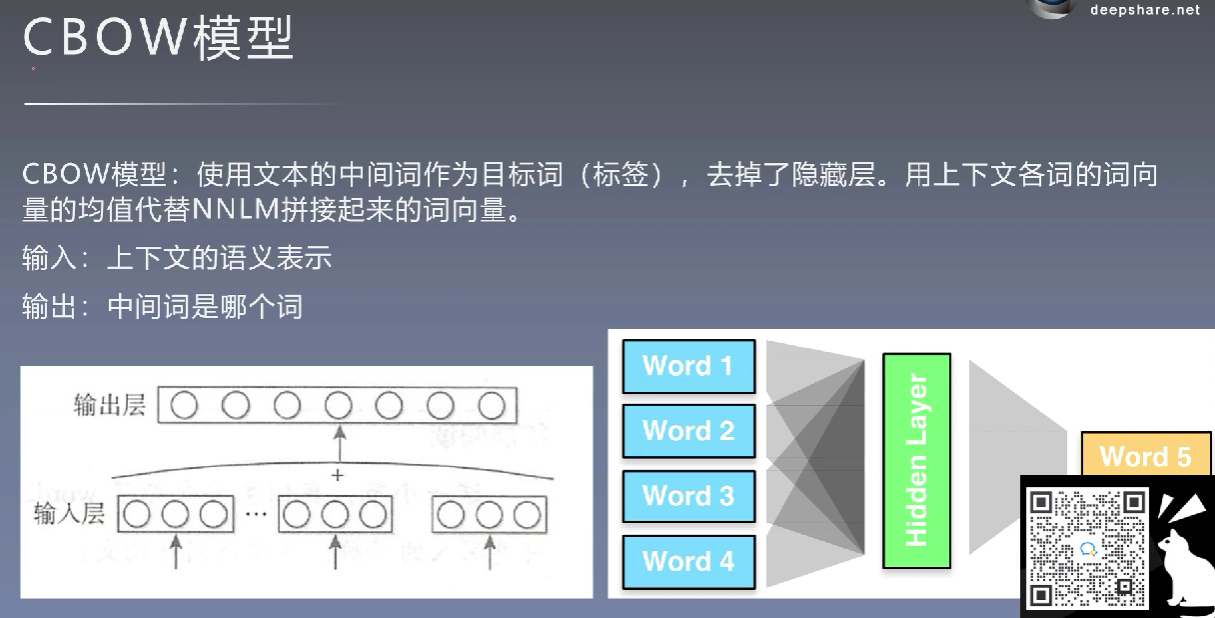
2、CBOW模型

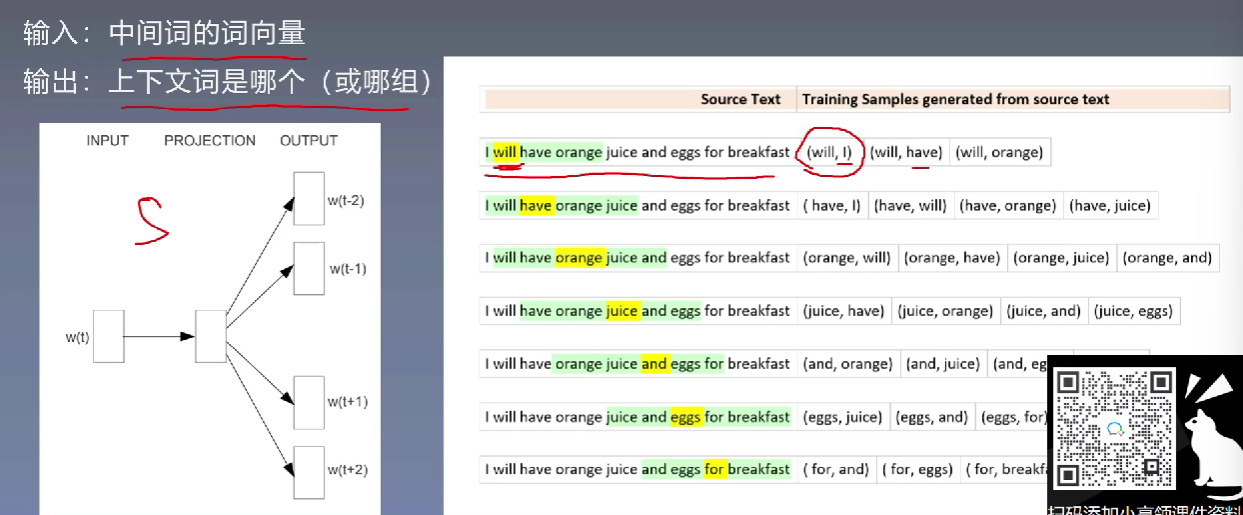
3、Skip-gram模型
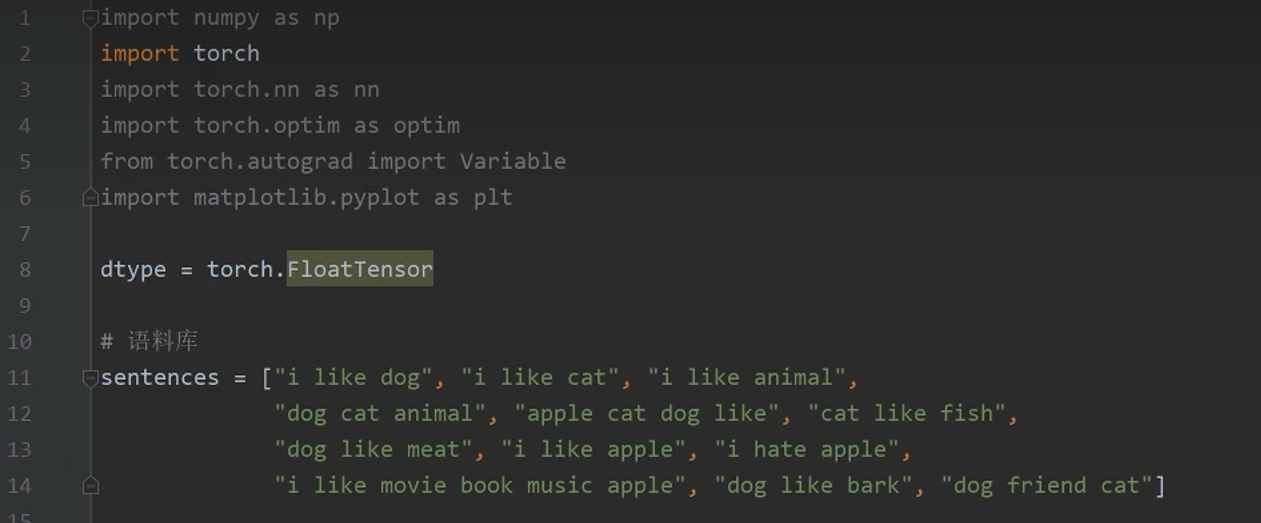
4、Skip-gram模型的复现

4.1 导入包并构建语料库
4.2 语料库的处理,获得词表
首先合并在一起,再使用空格进行分割


4.3 将词表转化为词典
去除重复,获取列表格式的词典


4.4 给每一个词分配一个序号,获取词典


4.5 批量导入
random_input和random_labels的格式都是列表,还要是随机选择的输入。随后获取到了下标
获取到下标之后,根据下标信息回到sentences找到对应的语句,输入到random_input.append,[data[i][0]]的含义是将该句话的第一个词拿出来
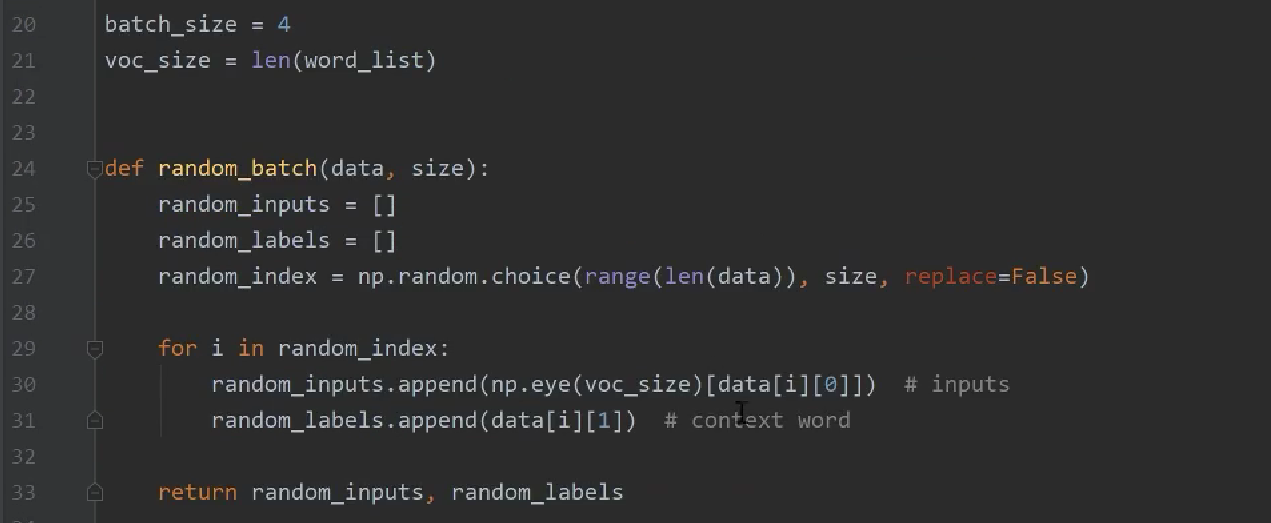
4.6 生成输入和输出的数据,用词典翻译给到计算机相应的数据
构建训练数据
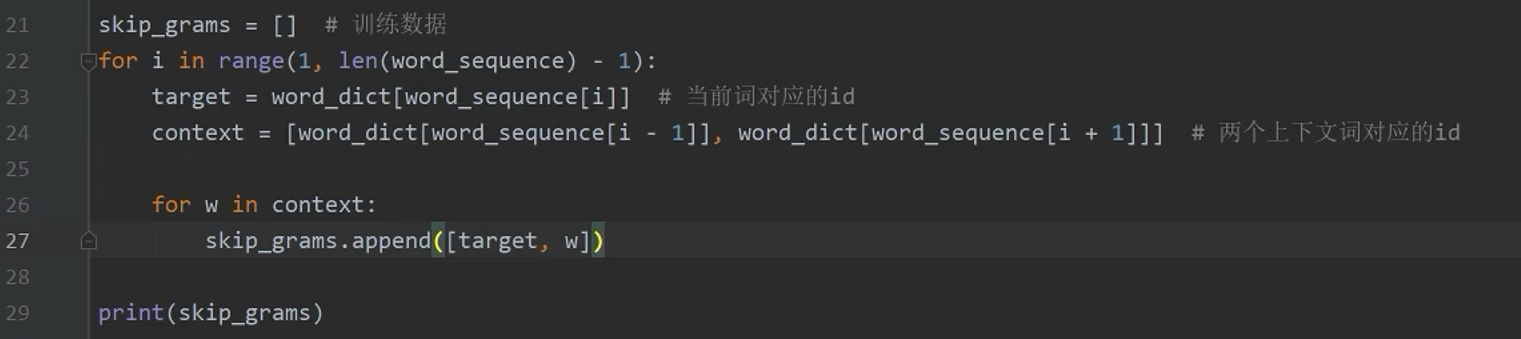

4.7 模型定义与实例化
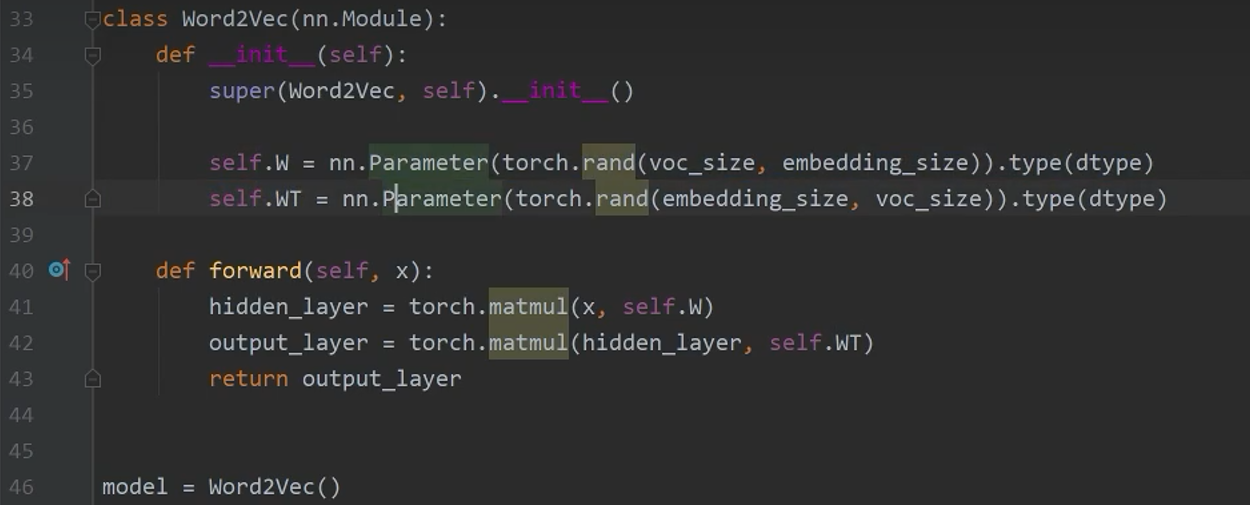
4.8 定义损失函数、优化器、学习率

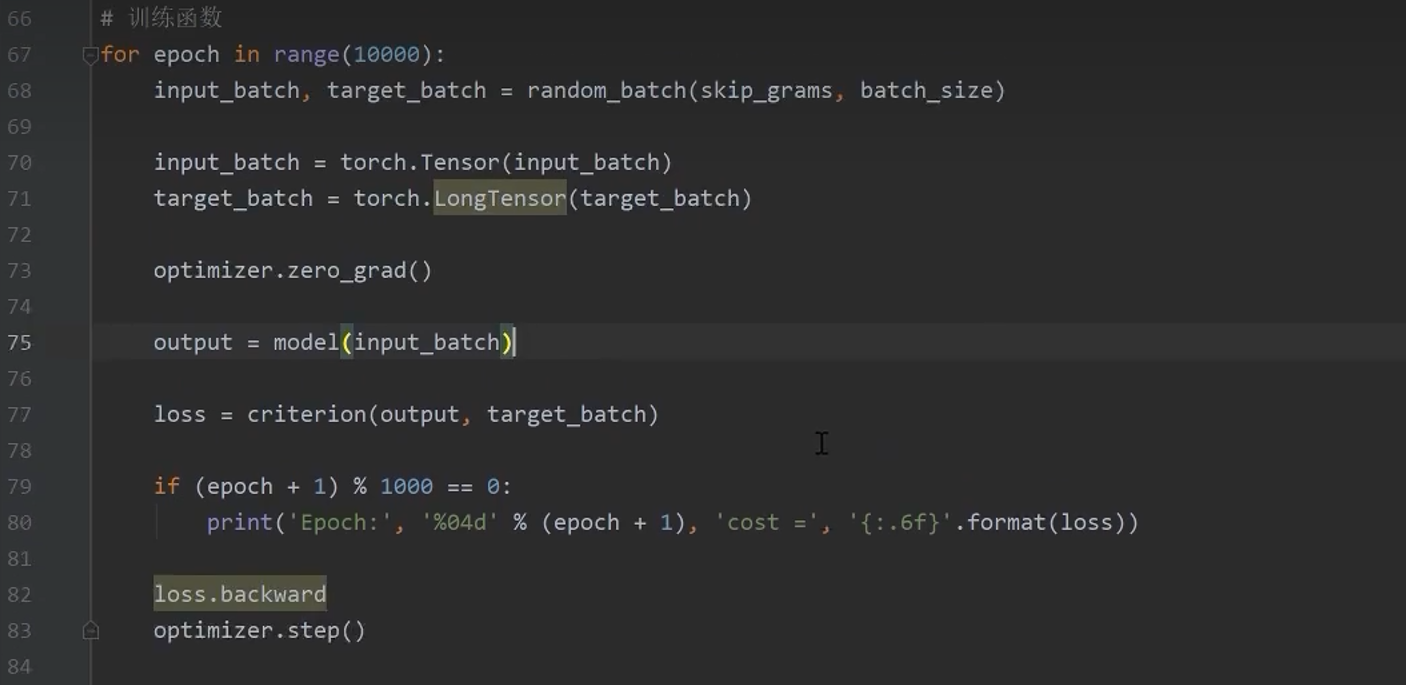
4.9 训练函数
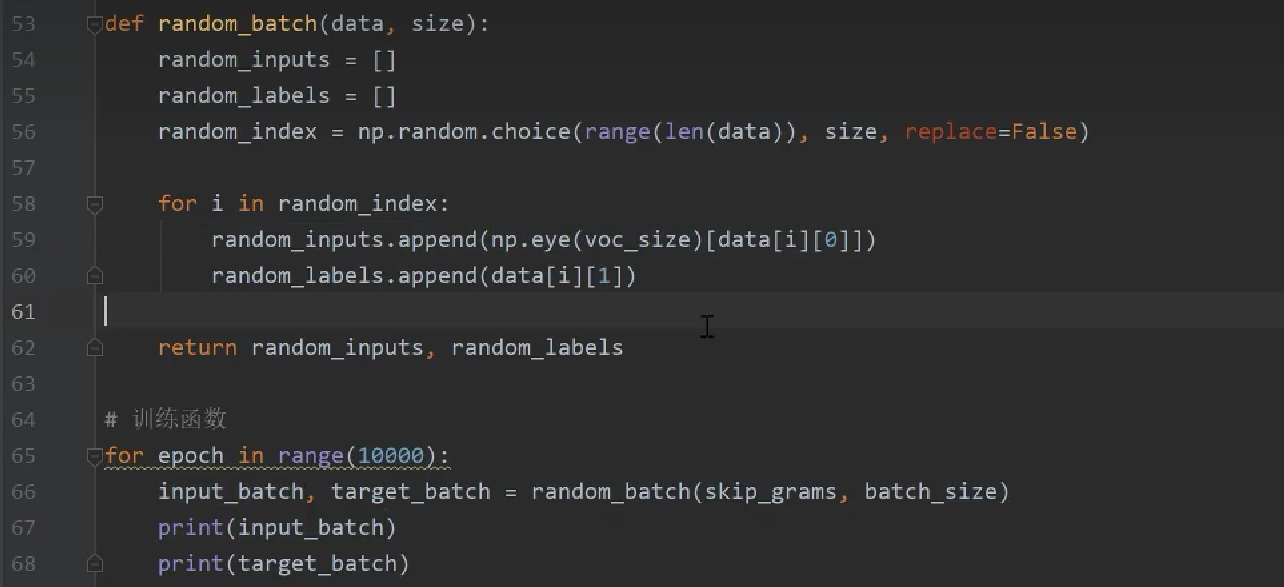
部分结果

只要给到词的ID,就可以自动生成词的one-hot表示。这里为啥有两个array,因为上面指定了batchsize=2
4.10 运行结果可视化

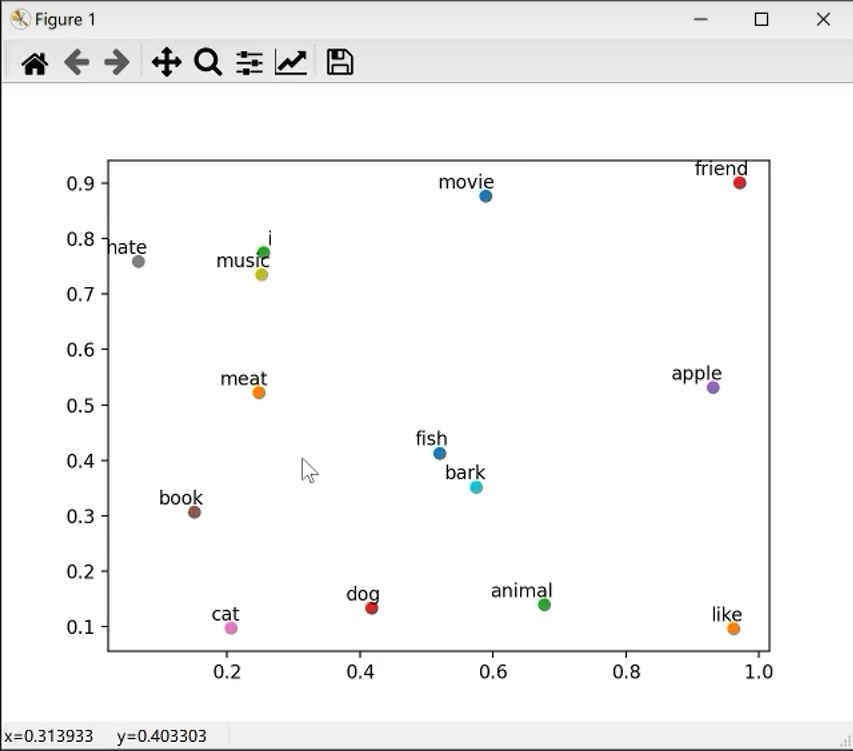
5、CBOW实战Frankenstein数据集

5.1 导入包

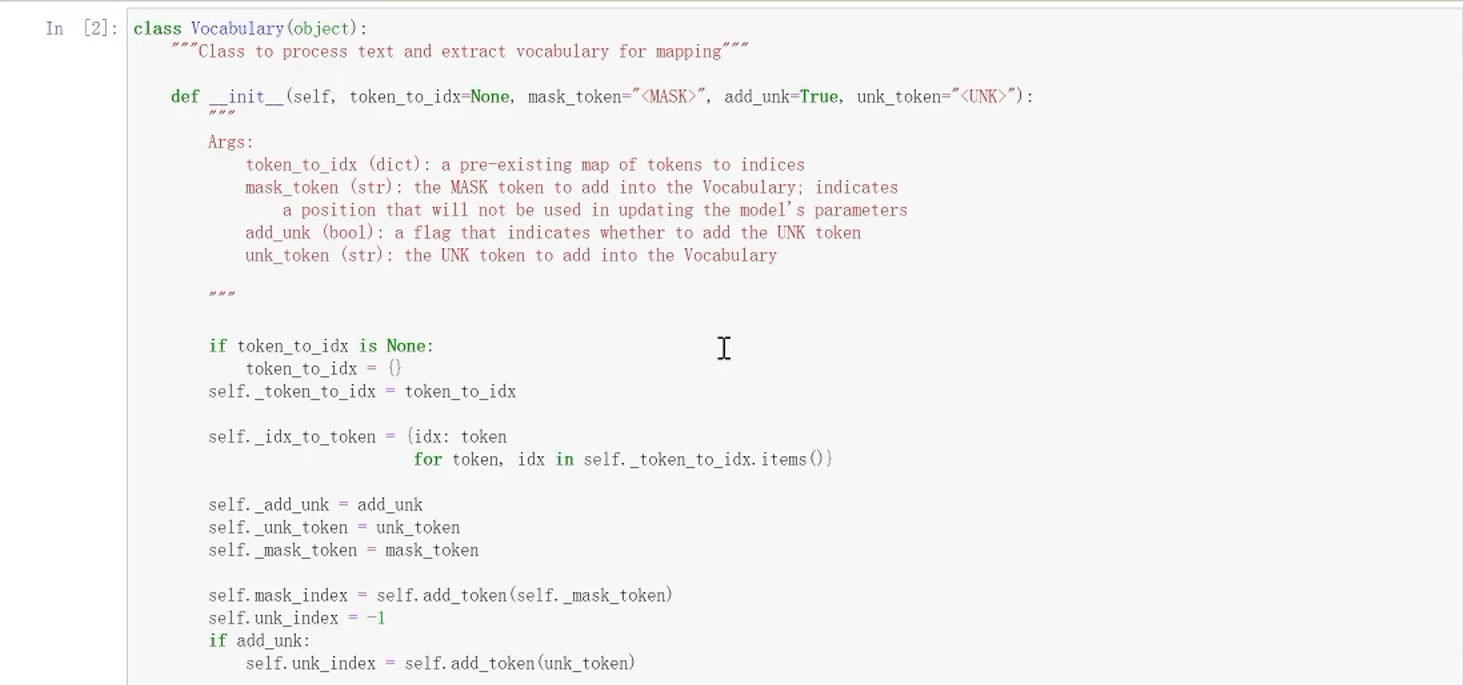
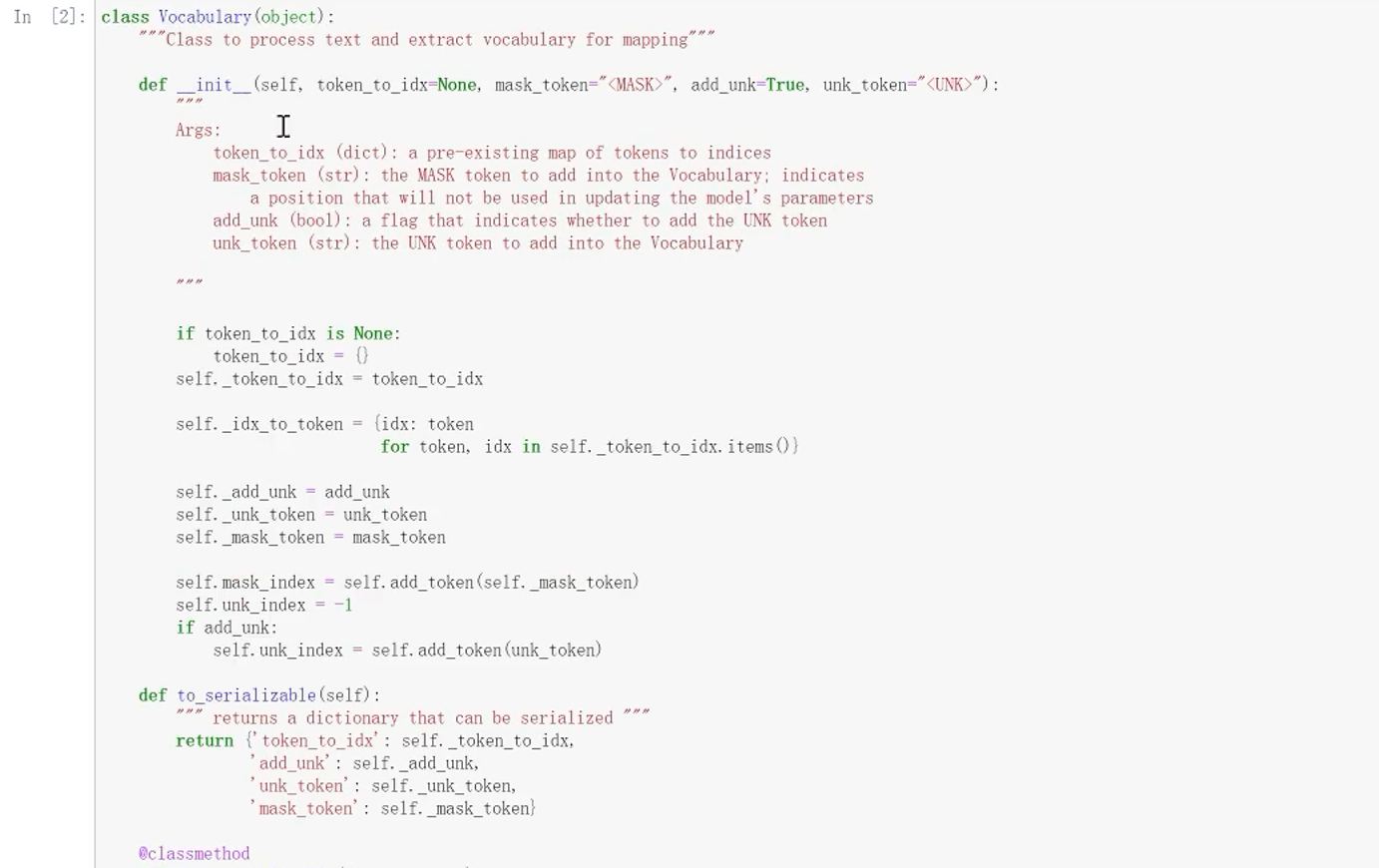
5.2 词典的类


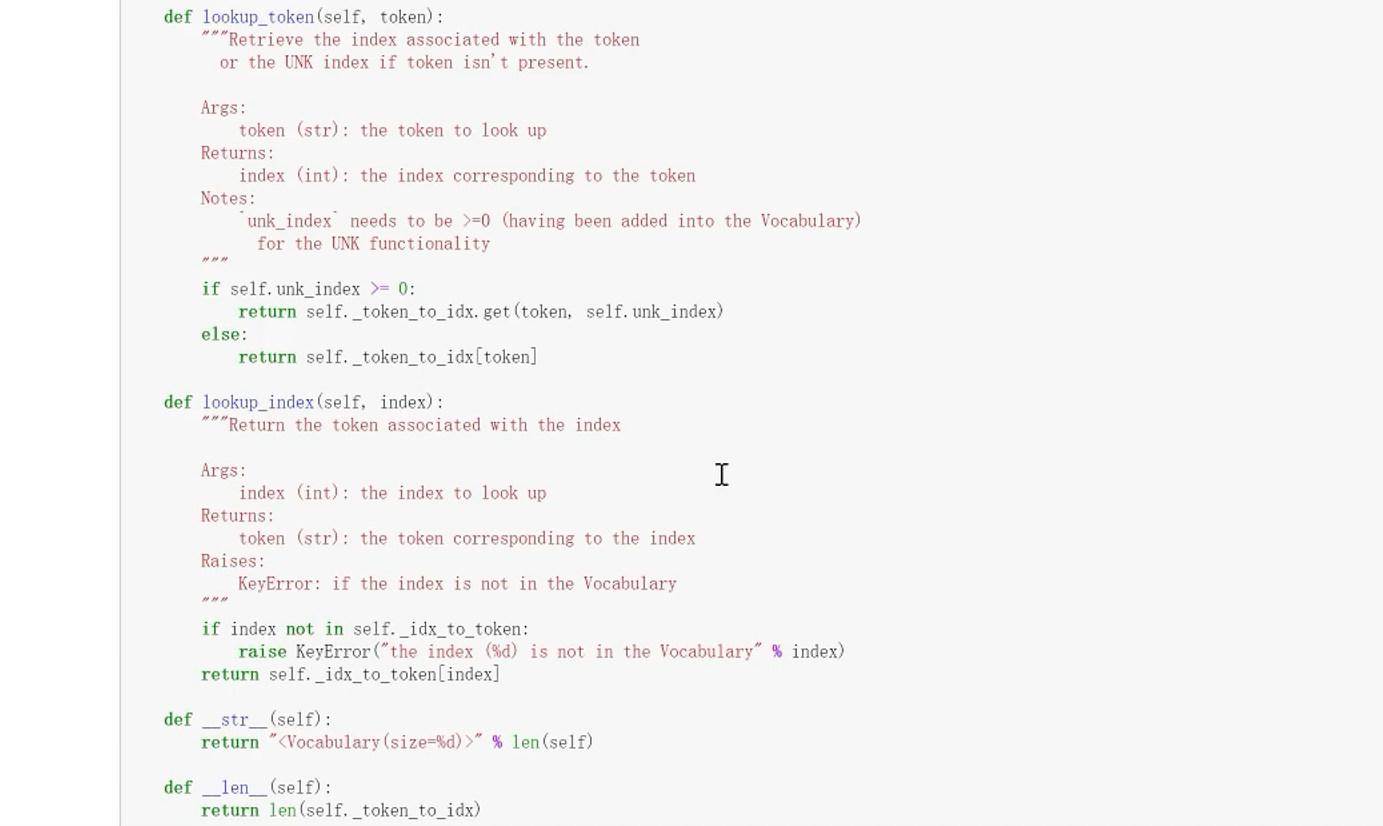
5.3 返回一个表示上下文索引的向量
太多了截图不过来
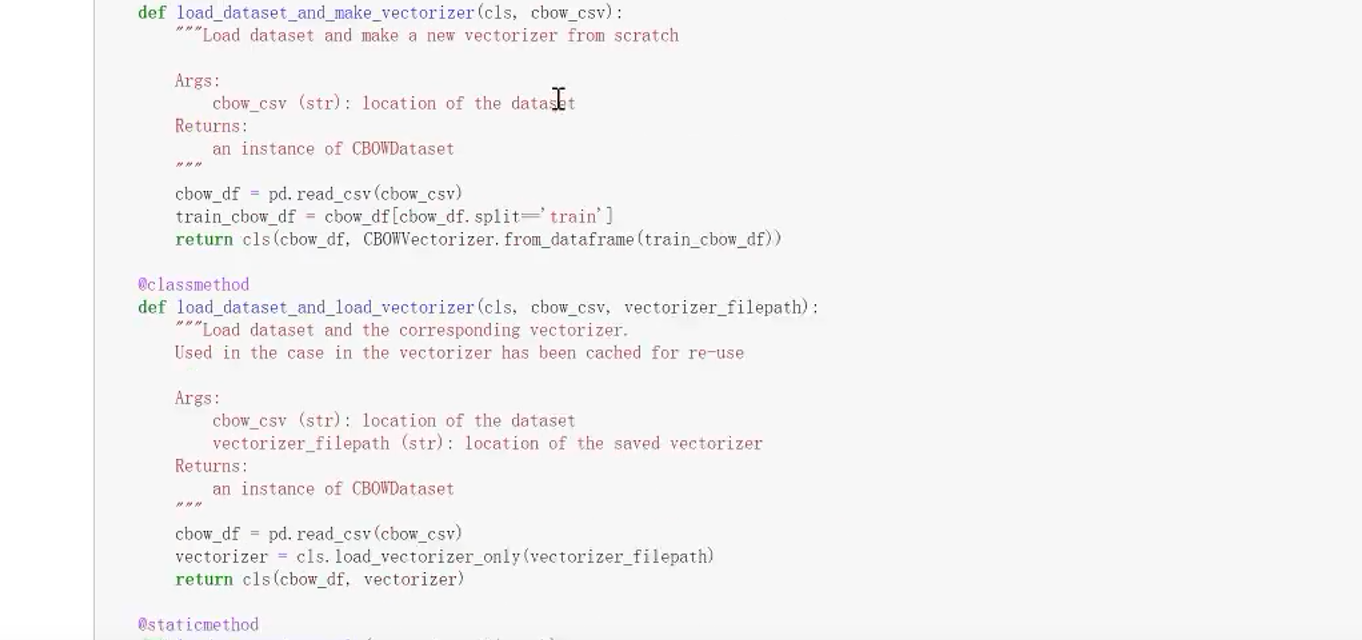
5.4 构建CBOW模型
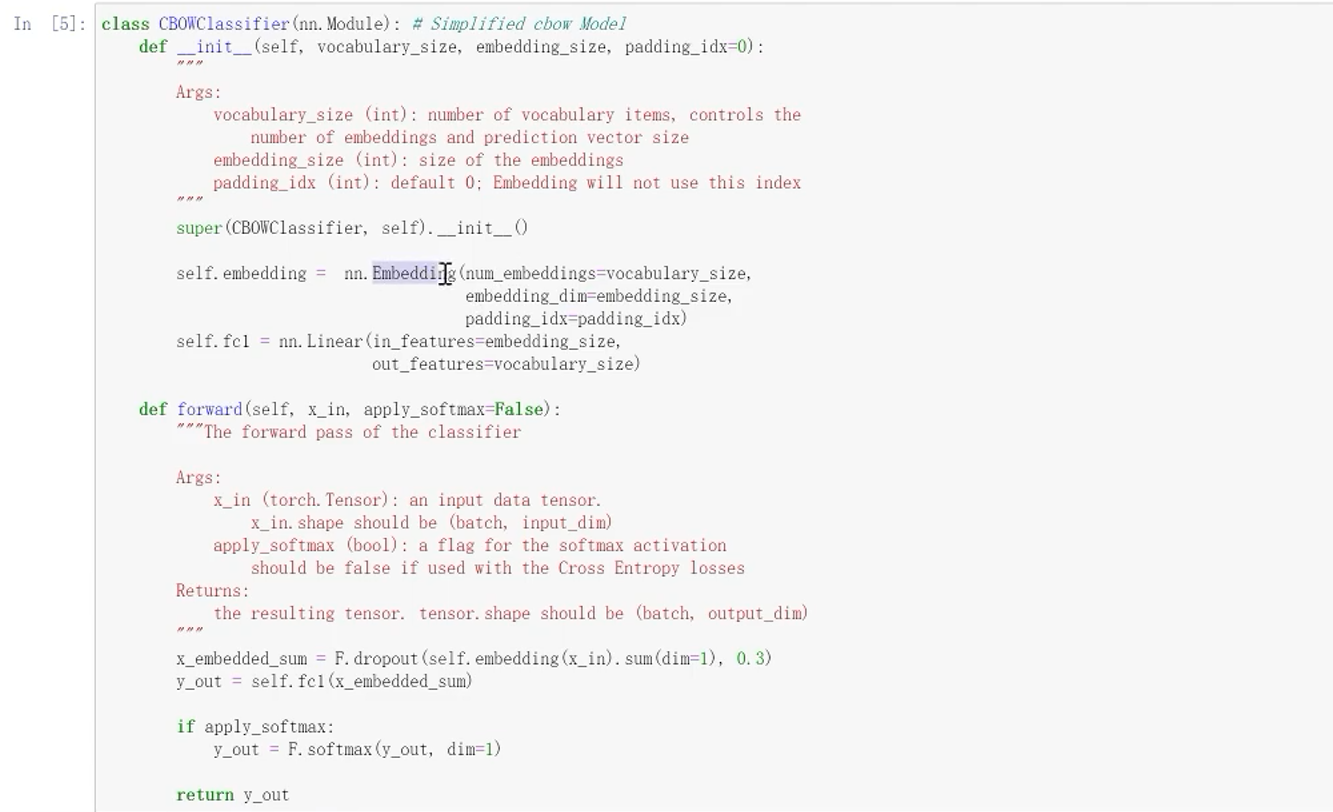
5.5 训练
6、Bert的使用

bert生成的词向量是动态的,在不同的句子里输入到bert会动态变化。而word-embedding是静态的
6.1 Hugging Face
记载了极大部分预训练模型,主要工作就是封装预训练模型
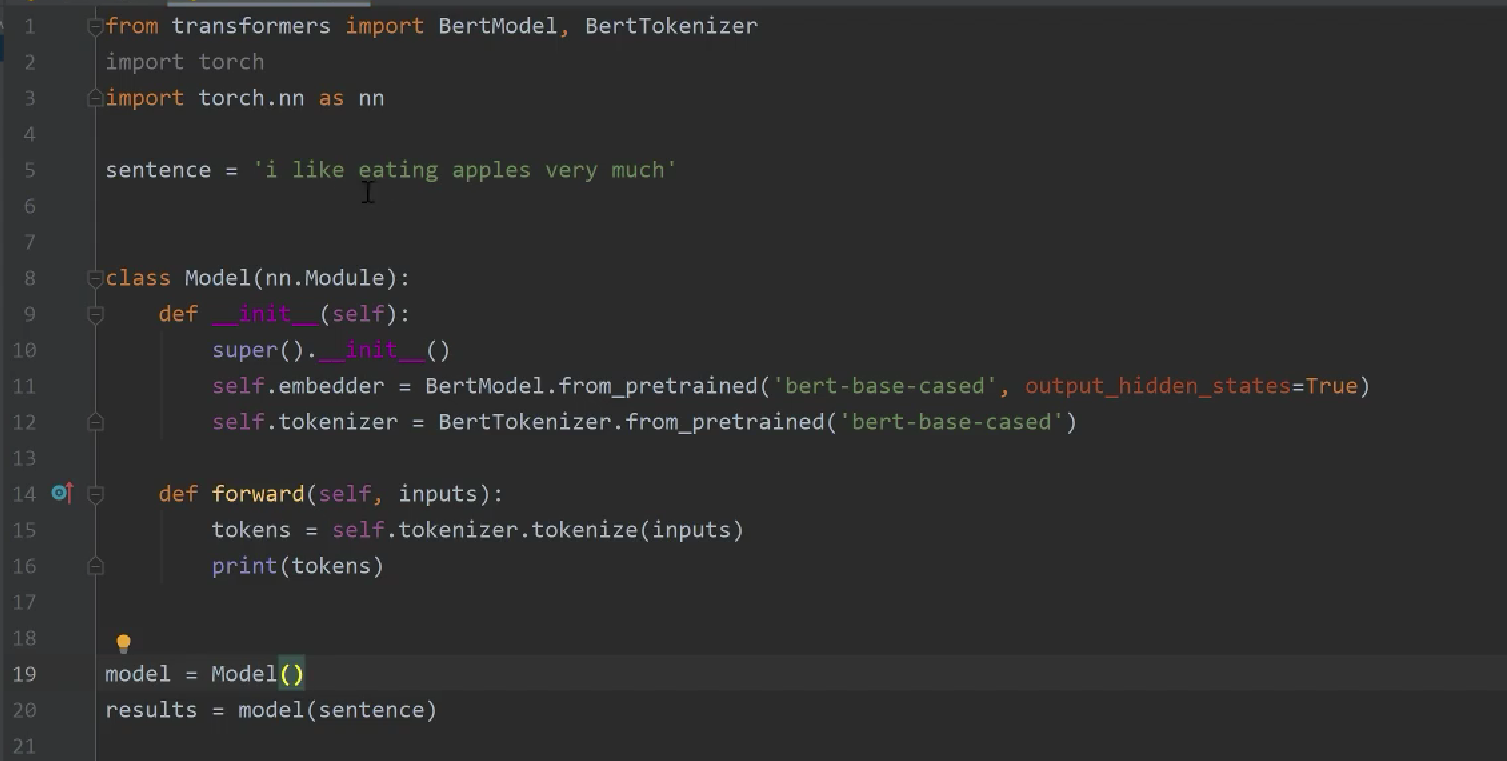
6.2 Bert模型的使用
分词
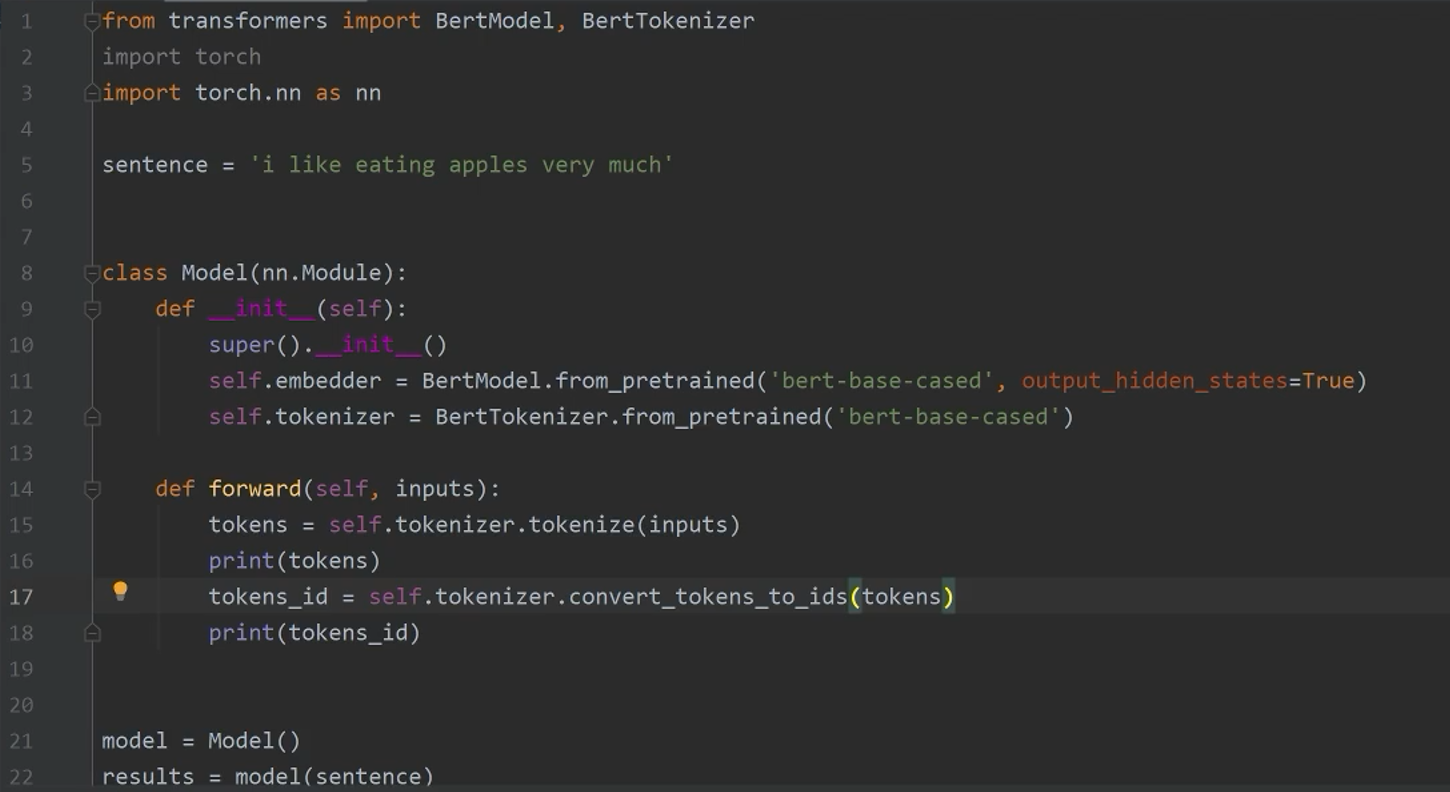
把词转换为ID
把ID转换为词
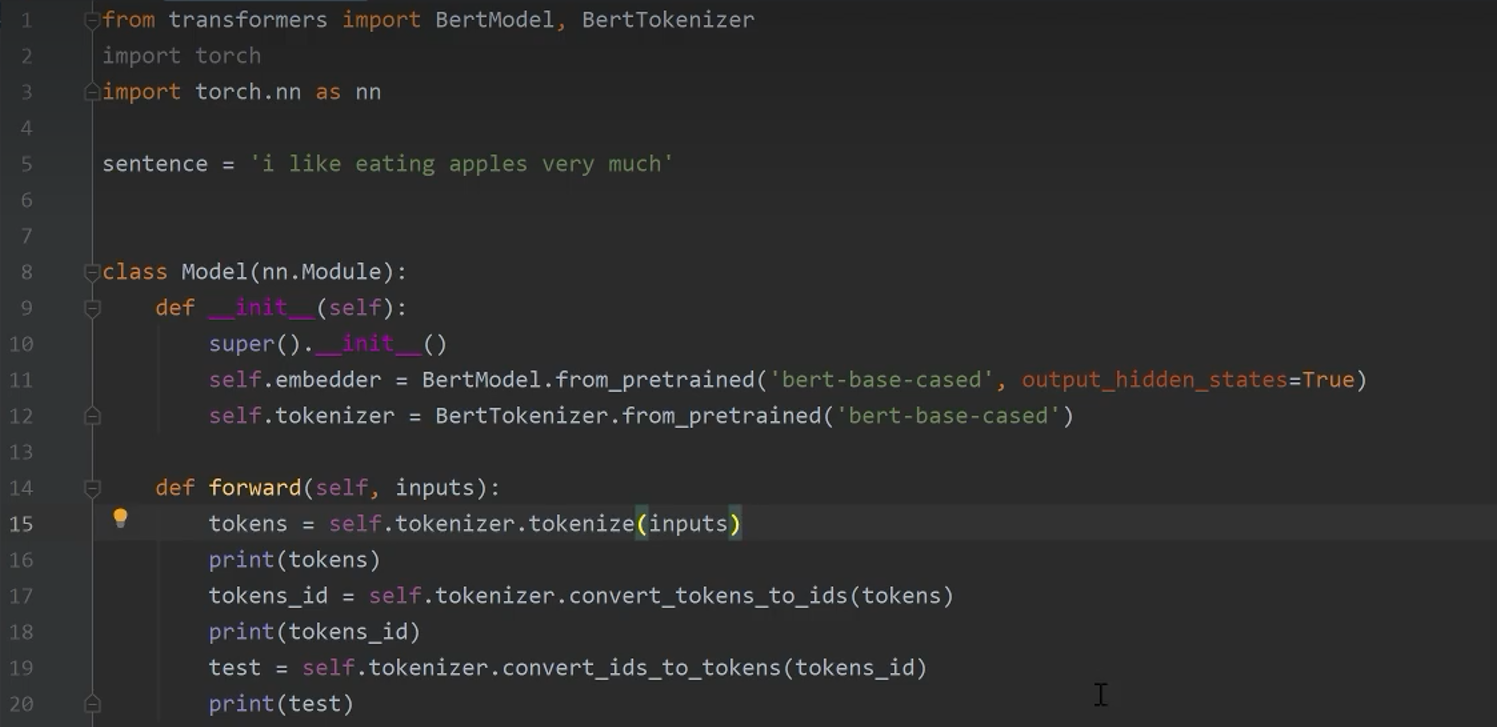
结果一览

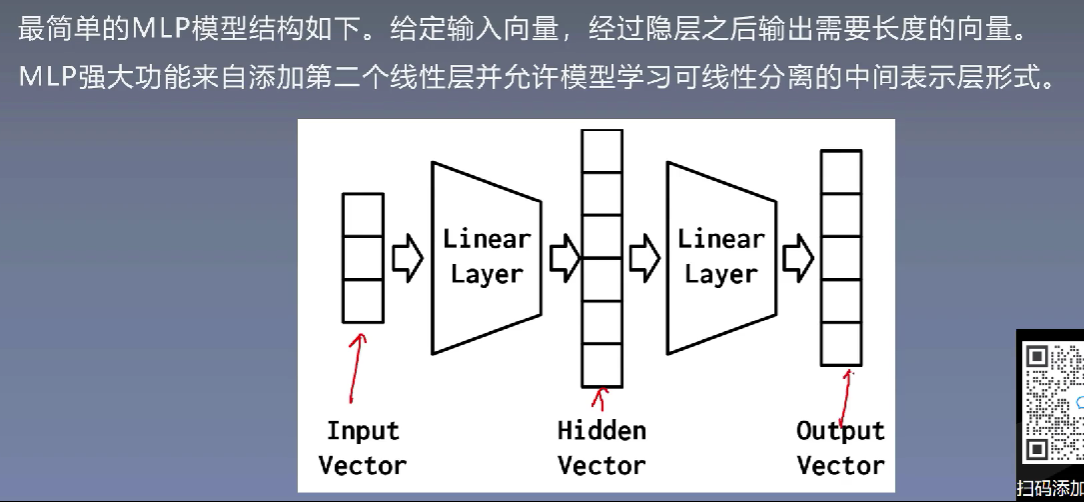
7、MLP模型与实战
7.1 感知器模型

7.2 NLP中的MLP

使用超平面进行二分类
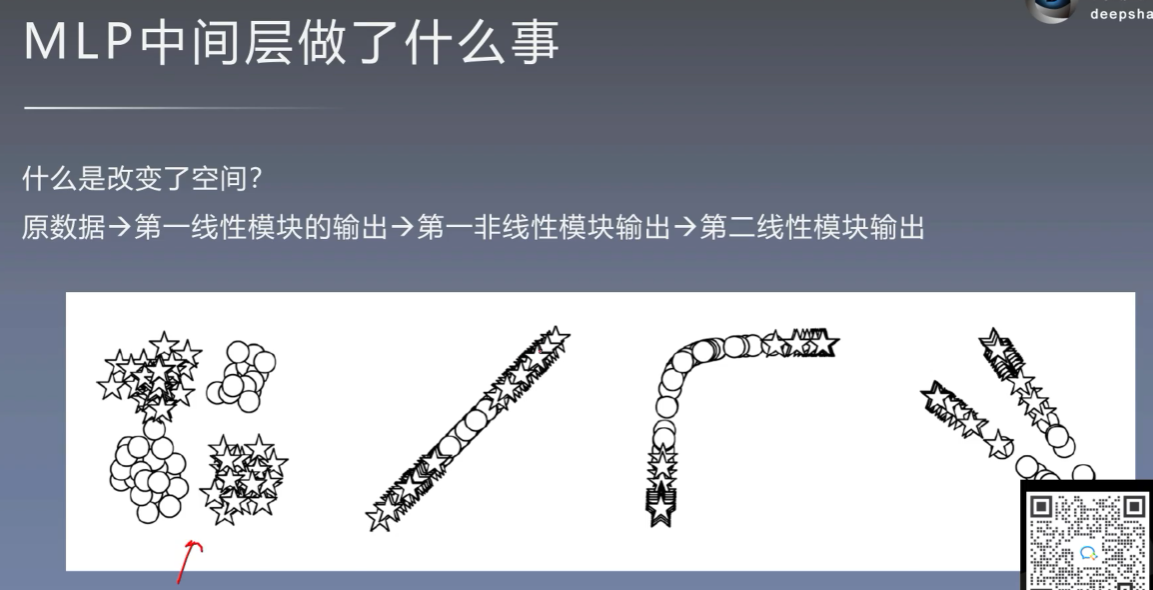
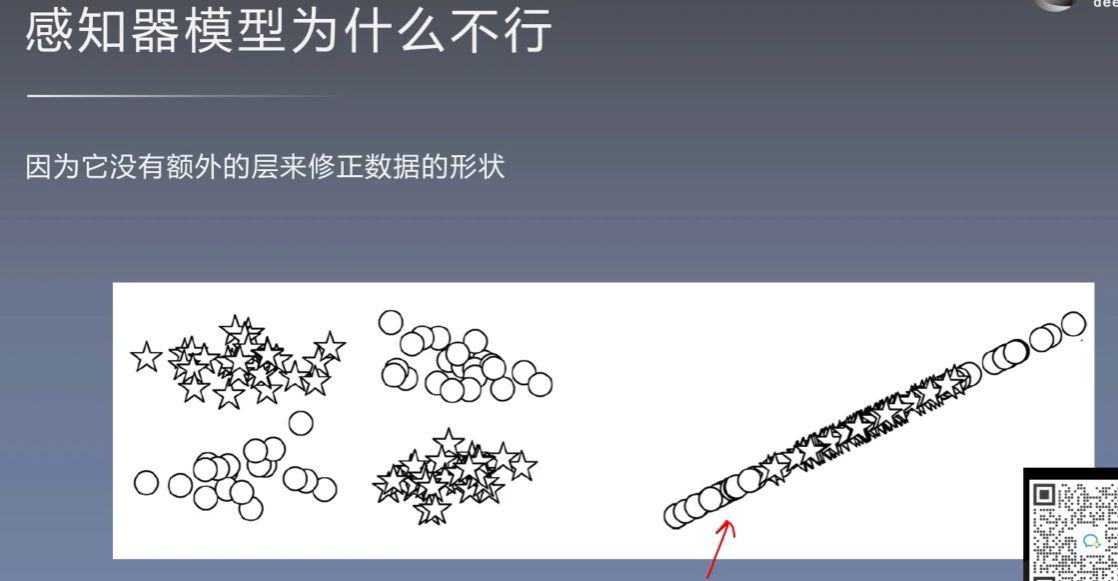
7.3 MLP的pytorch实现
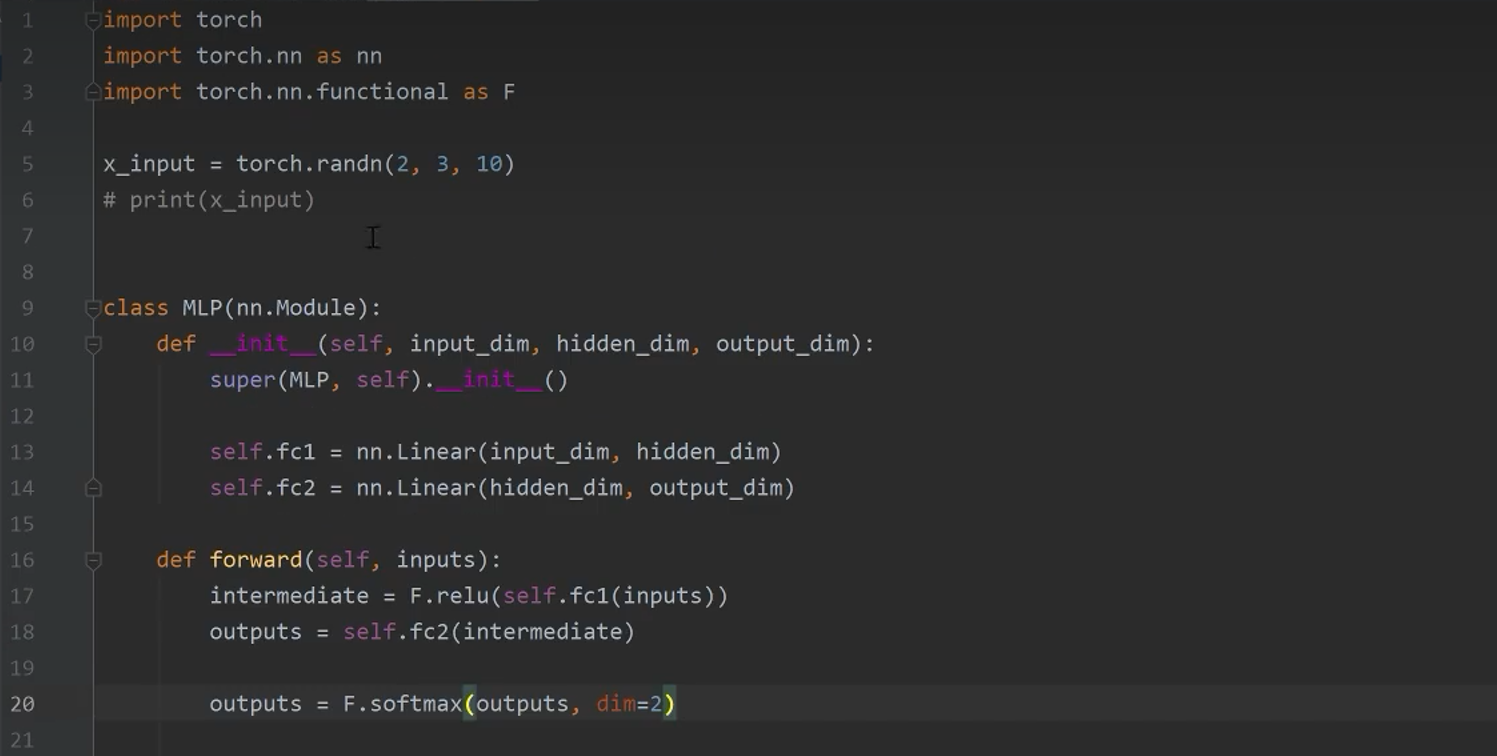

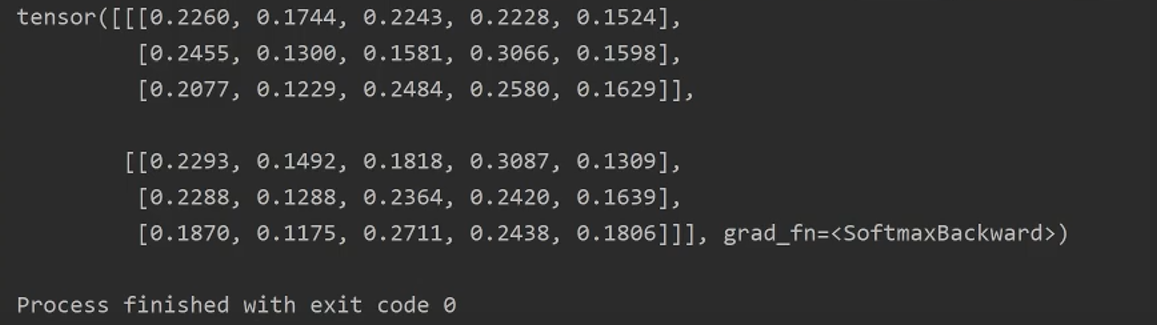
7.4 用MLP进行姓氏分类

数据预处理部分和Frankenstein数据集的处理一致
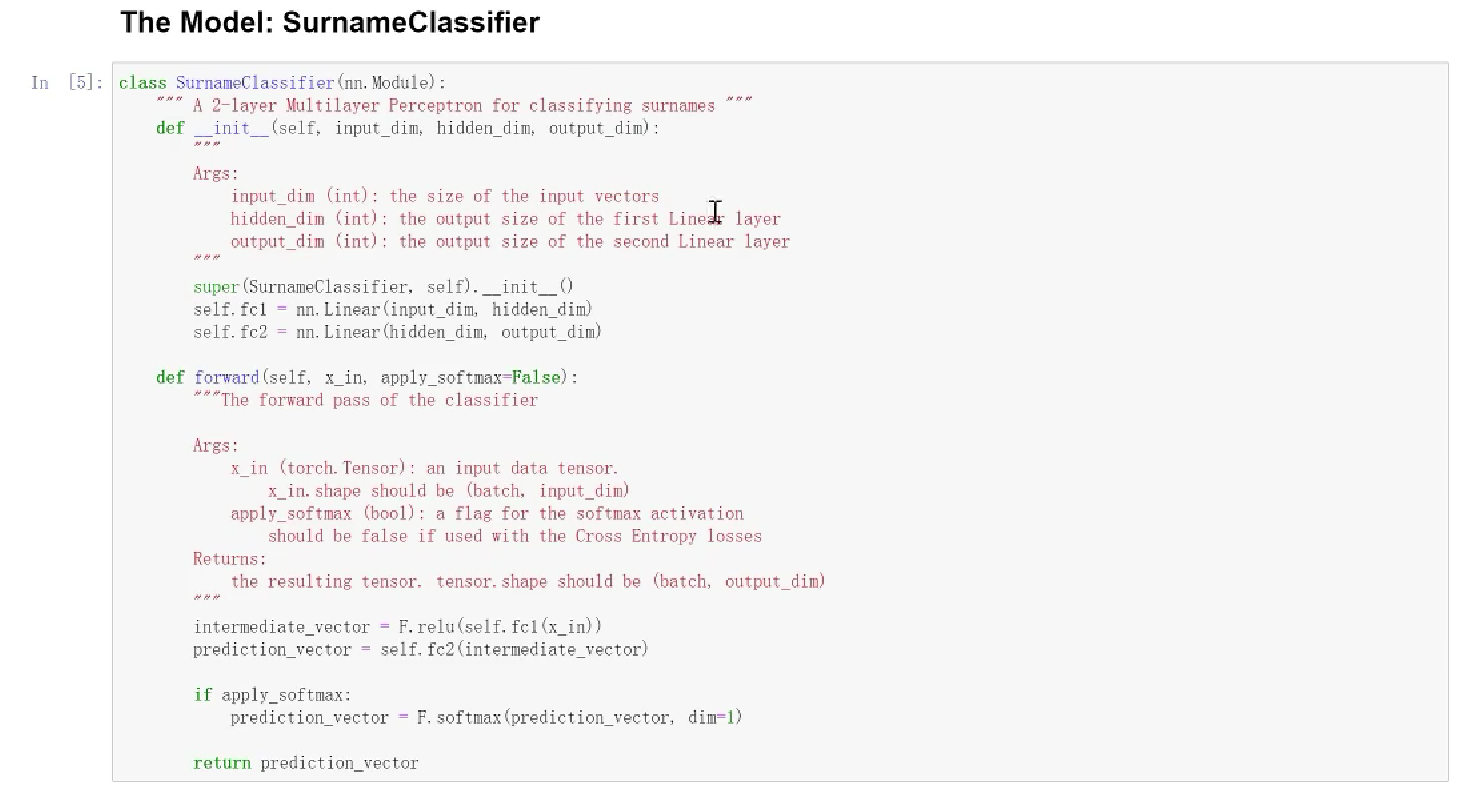
8、RNN
8.1 背景

8.2 RNN介绍

8.3 RNN模型结构
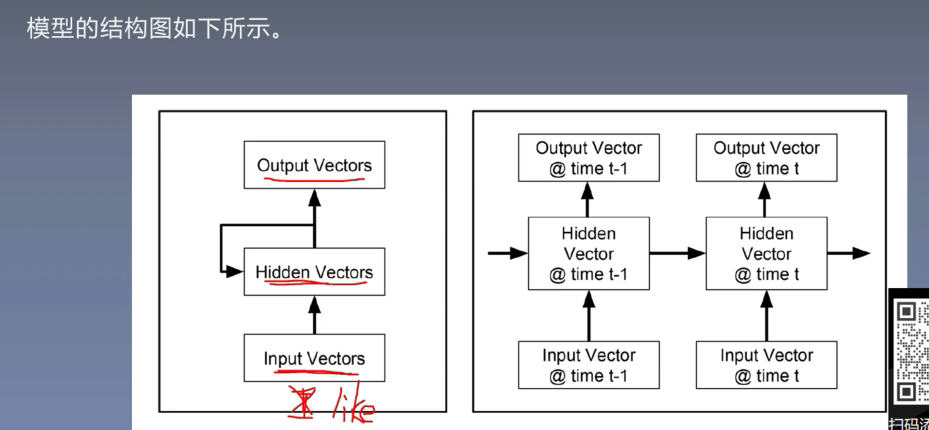
8.4 RNN的代码实现


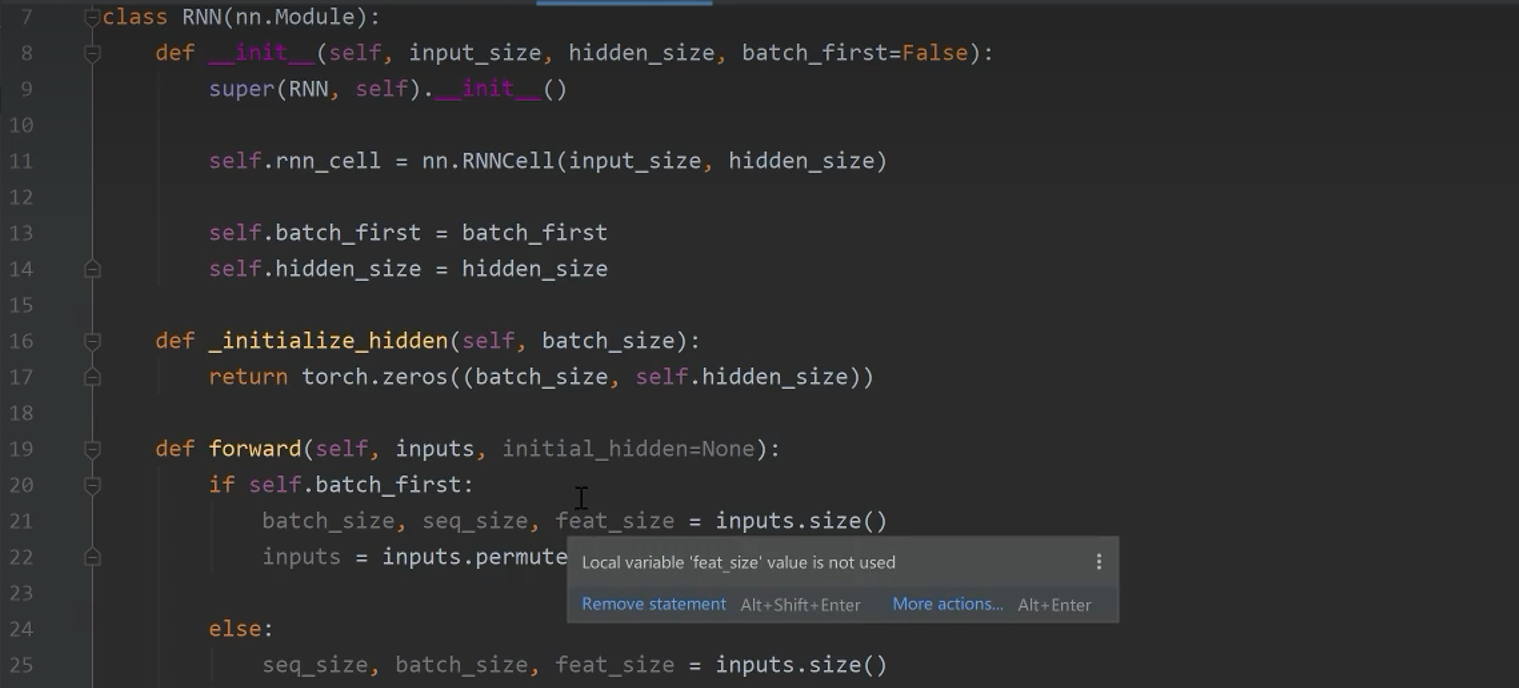
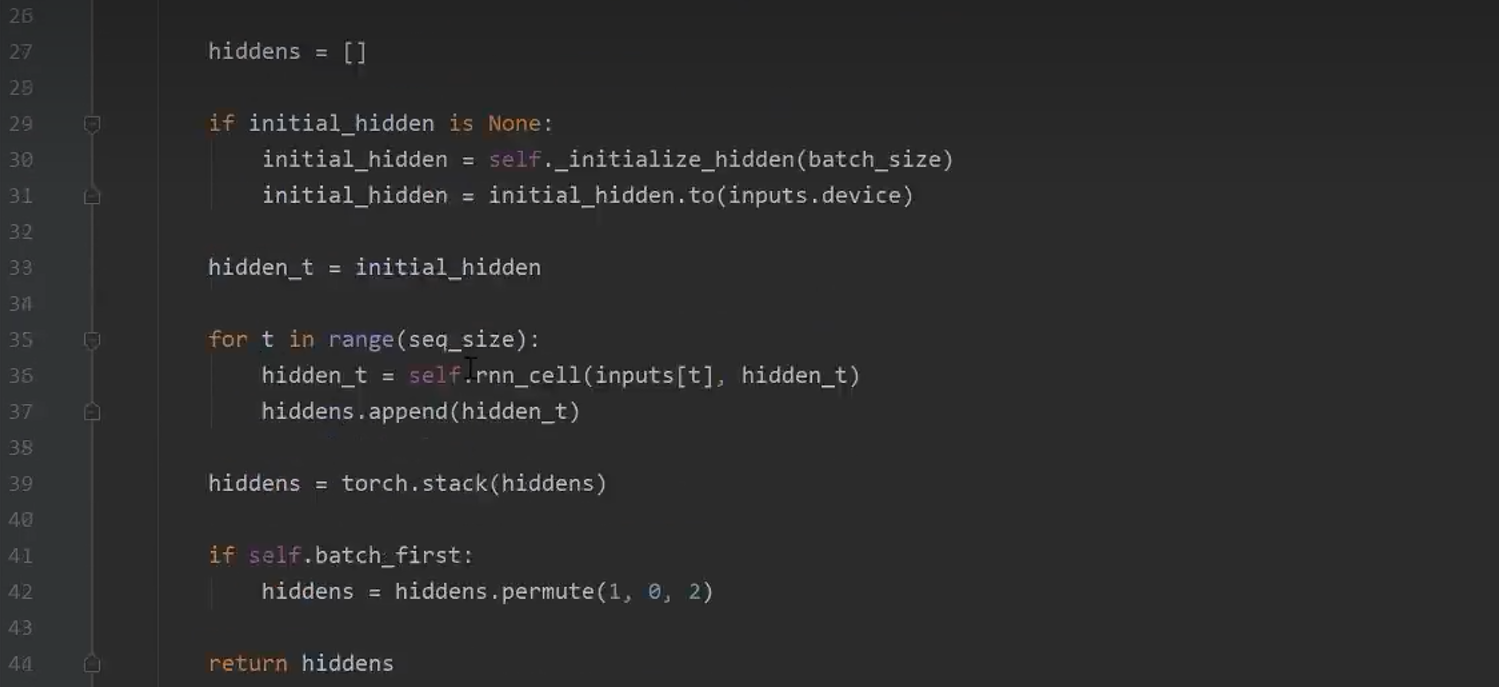

8.5 RNN姓氏分类

8.6 门控RNN模型
乘上特定的权重就达到了控制效果
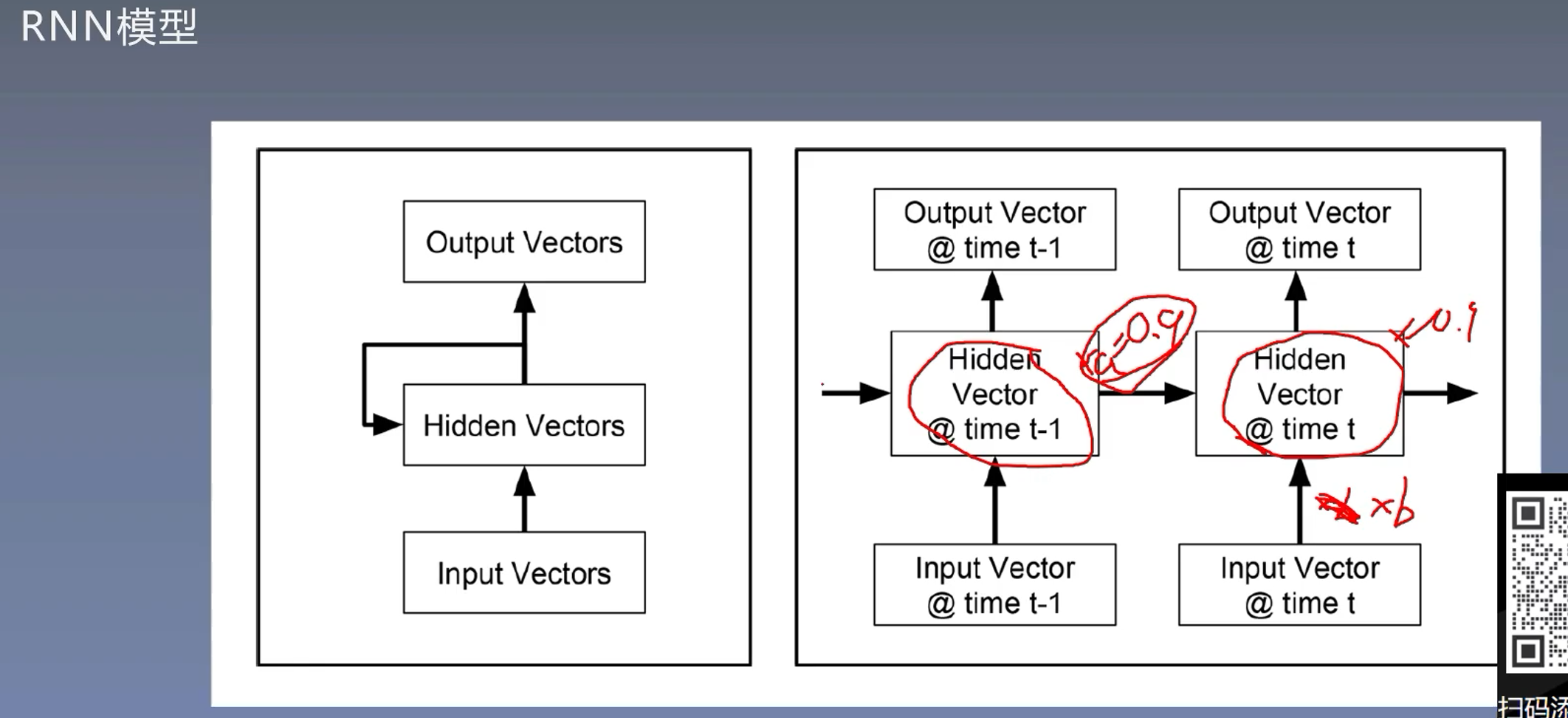
8.7 门控RNN姓氏分类

HMM在NLP中的应用
1、序列标注问题简介
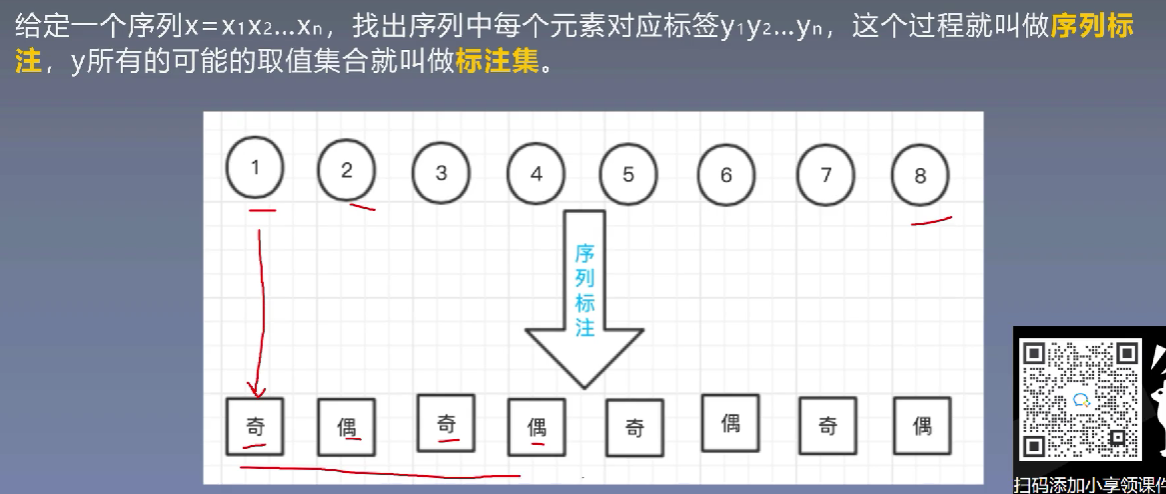
那么对于NLP中的序列标注问题
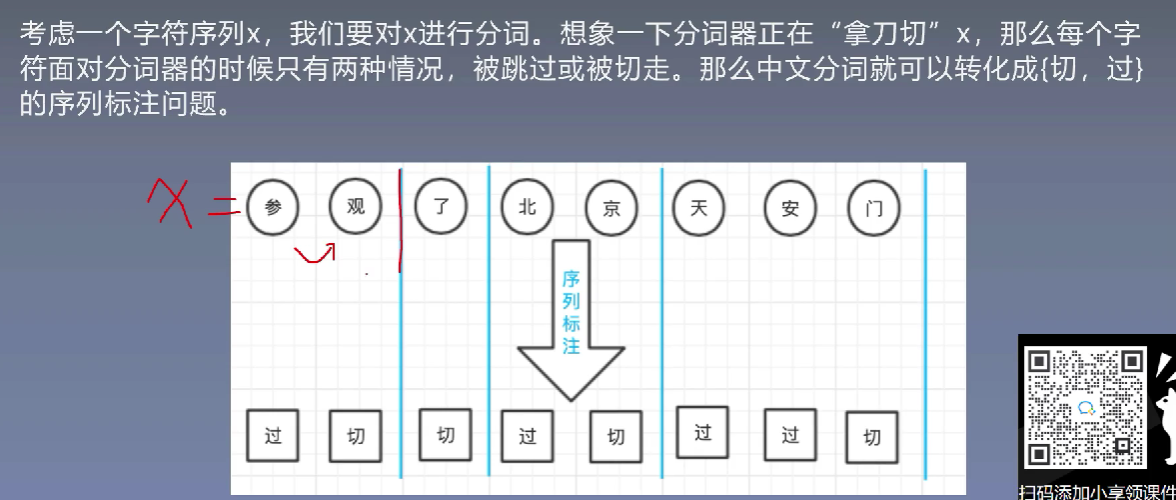
2、标注划分
2.1 BMES标注集
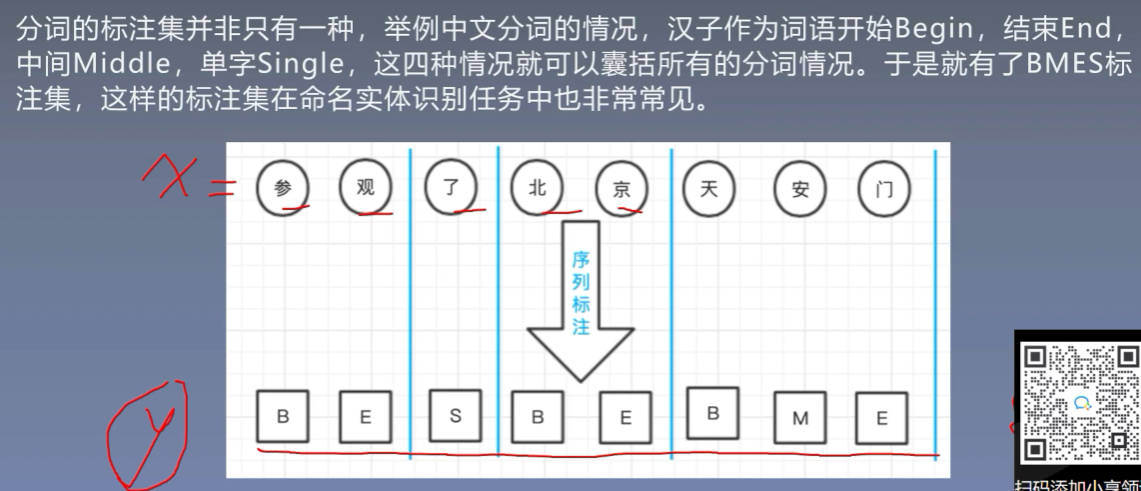
2.2 词性标注
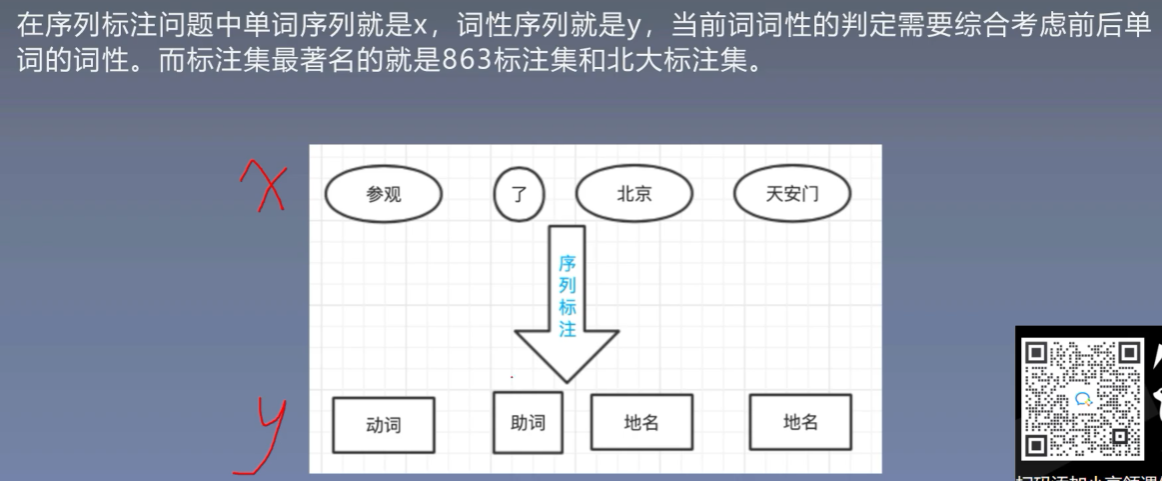
3、隐马尔可夫模型

为什么叫做隐马尔可夫模型:

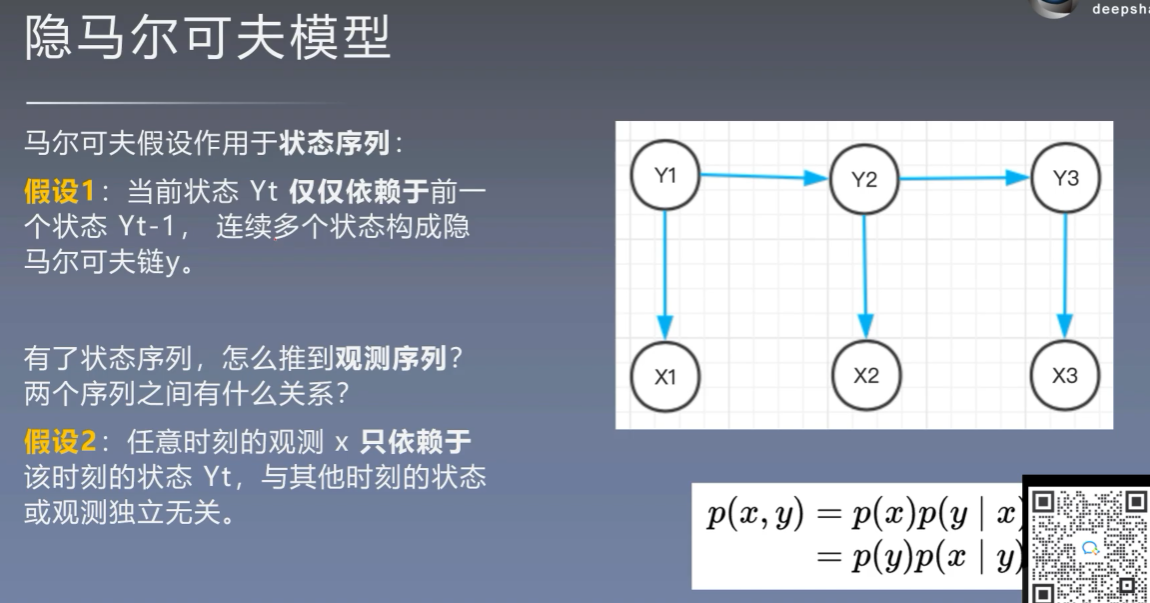
3.1 初始状态概率向量
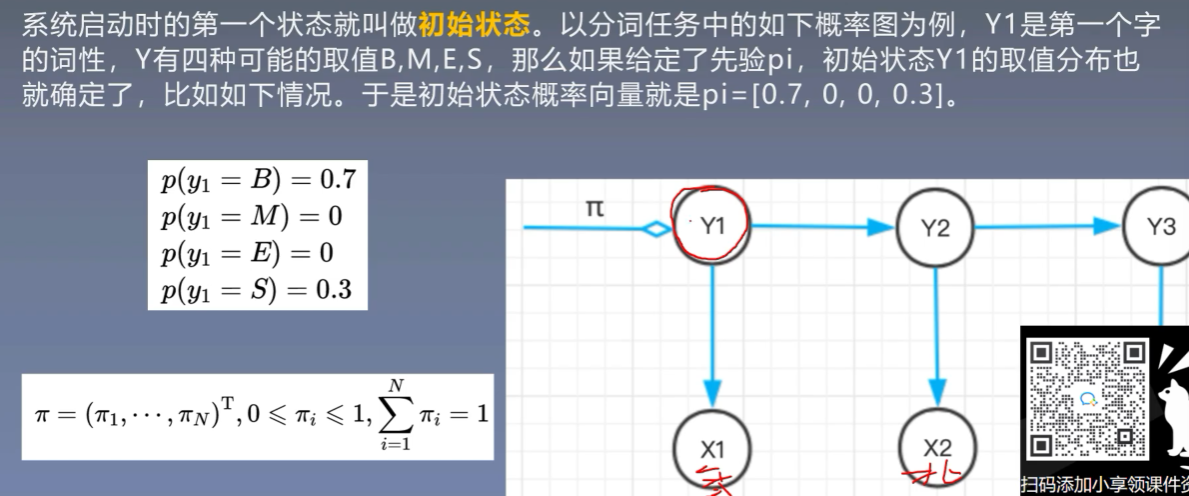
3.2 状态转移概率矩阵
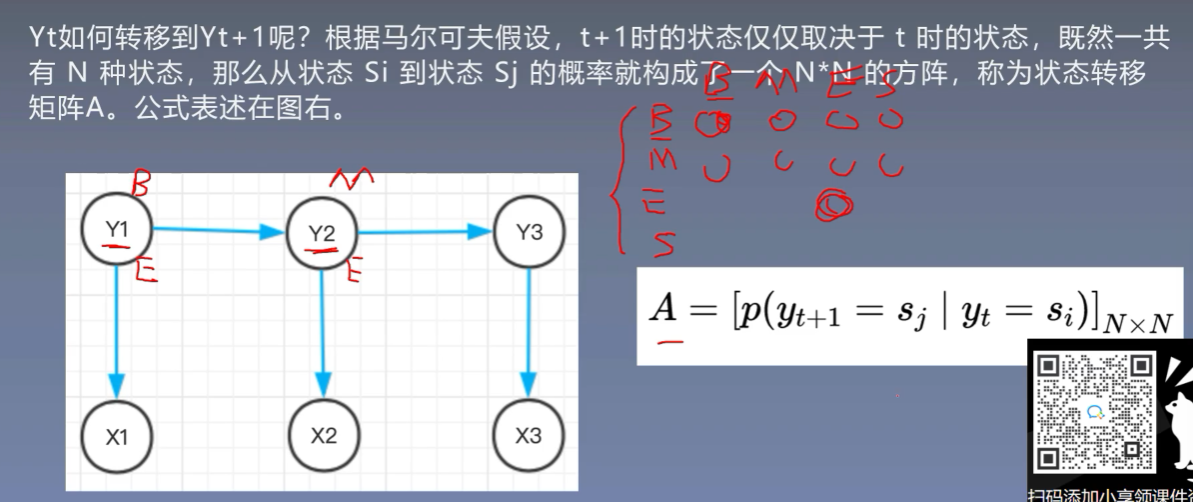
3.3 发射(观察)概率矩阵
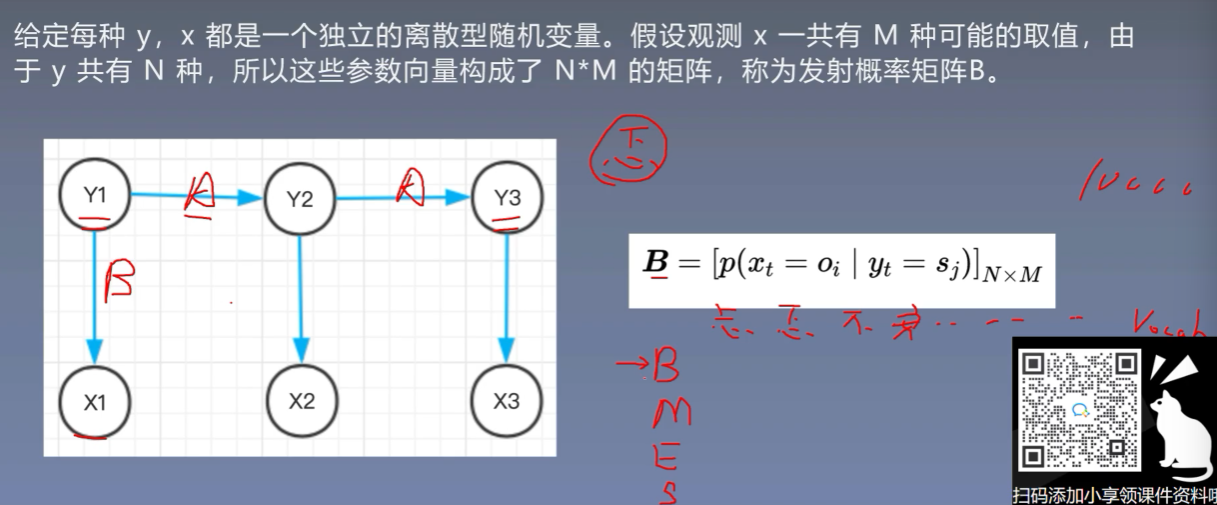
4、隐马尔可夫模型解决的三个问题

5、HMM应用于医疗诊断
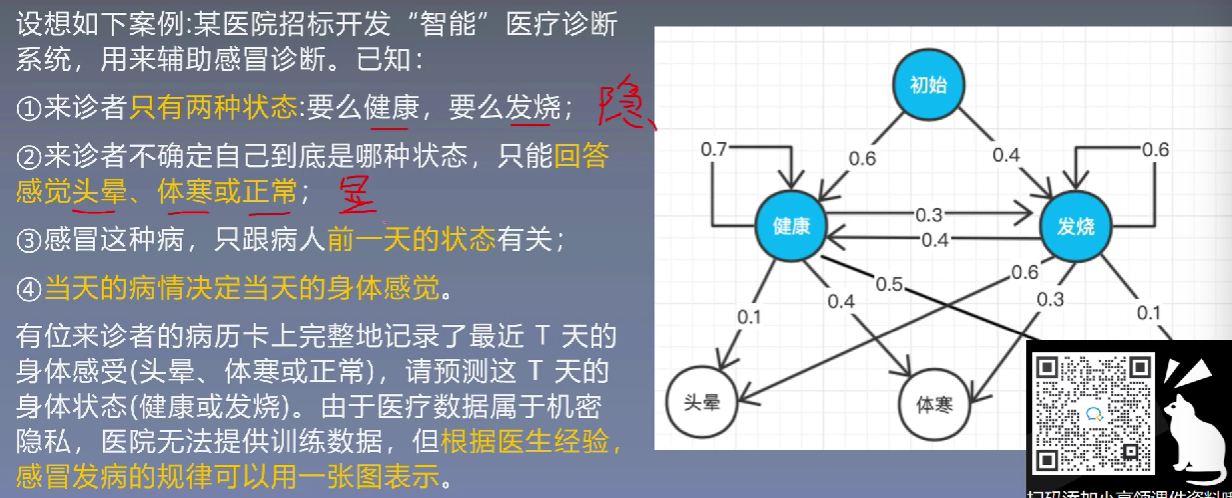

 浙公网安备 33010602011771号
浙公网安备 33010602011771号