PyTorch深度学习快速入门教程【小土堆】
PyTorch深度学习快速入门教程【小土堆】
P4 Python学习中的两大法宝函数
dir():打开,看见
help():说明书

将pytorch视作一个盒子,包含1、2、3、4个分隔区,每个分隔区中有不同的工具,若3号分隔区中有a、b、c三个工具,则:
- dir(pytorch):输出1、2、3、4个分隔区
- dir(pytorch.3):输出a、b、c三个工具
- help(pytorch.3.a):输出a工具的说明
测试:python console中import torch,然后输入dir( torch),可以看到许多分隔区,其中包括有cuda,dir( torch.cuda)同样输出了很多分隔区,其中包括有is_available,help( torch.cuda.is_available )输出is_available( )方法的说明
相对路径:如有A.py处于Project项目下的train文件夹下,B.jpg处于Project项目下的image文件夹下,在A中定义B的相对路径:../image/B.jpg
P5 PyCharm及Jupyter使用及对比

P6-7 PyTorch加载数据初认识
数据从下载到送给后面网络需要的基本步骤:
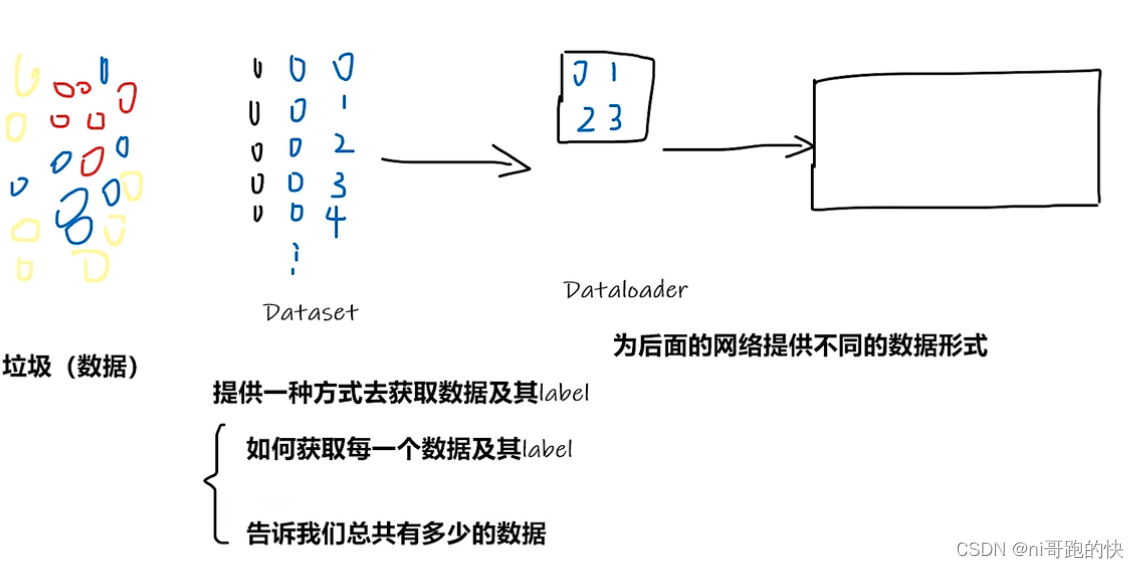
通过Dataset方法将数据进行下载,这个方法包含了两个函数,分别是getitem和111;Dataloader则是将数据进行打包,为后面的网络提供不同的数据形式
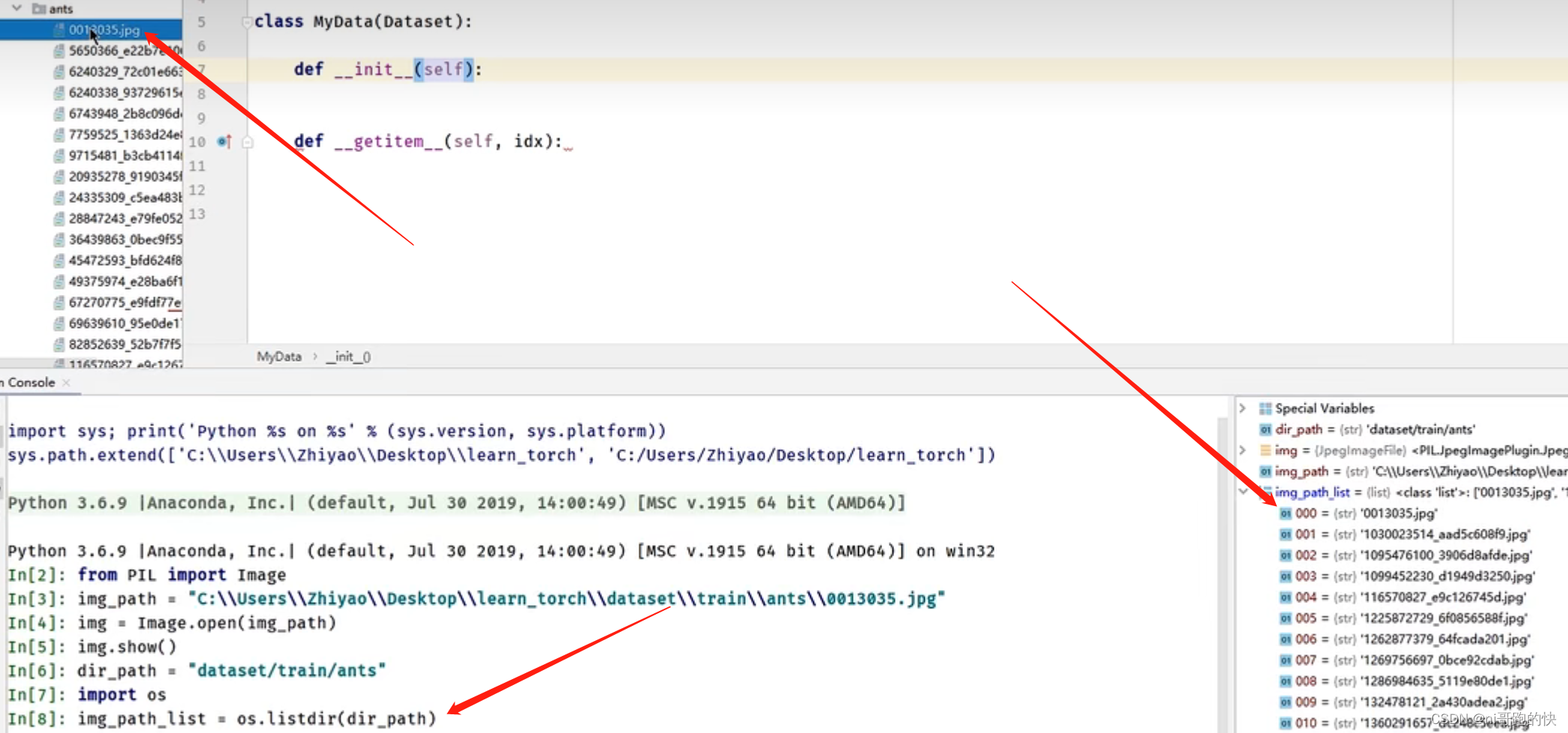
以读取蚂蚁蜜蜂训练集举例:
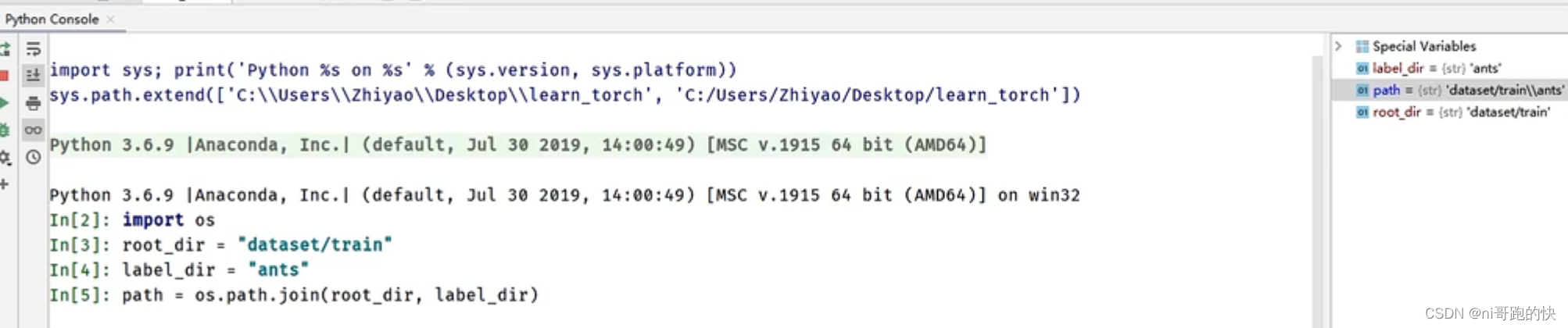
os.listdir方法是将文件夹下面的所有list变成列表
os.path.join方法是将两个路径用斜杠加起来,好处是根据系统自动判断添加斜杠种类,防止出错
from torch.utils.data import Dataset#抽象类
from PIL import Image#读取图片
import os#用于路径拼接
class MyData(Dataset):
def __init__(self,root_dir,label_dir):#初始化类,一般可以用于为class提供一个全局变量
self.root_dir = root_dir #self是在init方法中声明的一个类中的全局变量,在getitem,len中都可以调用
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)#用适当的方式将路径进行拼接
self.img_path = os.listdir(self.path)#将文件夹下面的所有list变成列表
def __getitem__(self, idx):#获得单个图像
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir = "learn_torch/data/train"
ants_label_dir = "ants_image"
ants_label_dir = "bees_image"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,ants_label_dir)
train_dataset = ants_dataset + bees_dataset
[对于self的详细讲解]:
P8-9 Tensorboard的使用
安装
pip install tensorboard
[SummaryWriter]
初始化
from torch.utils.tensorboard import SummaryWriter
- 在PyCharm中按住ctrl键,将鼠标移至SummaryWriter,变为蓝色,点击SummaryWriter
- 或者在终端中SummaryWriter??
进行SummaryWriter的查看
class SummaryWriter(object):
"""Writes entries directly to event files in the log_dir to be
consumed by TensorBoard.
直接向log_dir文件夹写入事件文件,这个事件文件可以被TensorBoard解析。需要输入一个文件夹的名称,不输入的话默认文件夹为runs/**CURRENT_DATETIME_HOSTNAME**。
log_dir:tensorboard文件的存放路径
flush_secs:表示写入tensorboard文件的时间间隔
其他的参数当前并不重要,需要的话可以自己看看。
创建实例
writer = SummaryWriter("logs") #将事件文件存储至logs文件夹中
# writer.add_image()
# y = 2x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
writer.close()
def add_scalar(self, tag, scalar_value, global_step=None, walltime=None):
"""Add scalar data to summary. 添加一个标量数据至summary
Args:
tag (string): Data identifier 图表的标题
scalar_value (float or string/blobname): Value to save Y轴
global_step (int): Global step value to record X轴
打开事件文件
在pycharm的terminal中输入tensorboard --logdir=logs(logdir=事件文件所在文件夹名)
默认打开6006端口,当运行同一个服务器避免冲突时可以指定端口:
tensorboard --logdir=logs --port=6007 #在这个位置port设置终端的端口号
打开6007端口
在writer中写入新事件,还有上个事件
解决方法:删除logs文件夹下的所有事件,重新运行程序,在terminal中按ctrl+c退出,再按上键打开端口
add_image()的使用(常用来观察训练结果)
1、下载数据集,将其放入项目文件夹中
2、处理图片类型
img_tensor参数类型要求为:torch.Tensor、numpy.array或者string类型。global_step为步骤,int类型。
# 先查看numpy.array格式
print(type(img))
用PIL中的Image 打开的img type是“<class 'PIL.JpegImagePlugin.JpegImageFile'>”
利用numpy将img改为numpy形式
import numpy as np
img_array=np.array(img)
print(type(img_array))
#<class 'numpy.ndarray'>
img = PIL.Image.open(img_path) # img类型为PIL类型
cv_img = cv2.imread(img_path) # cv_img为numpy的n维数组类型
3、处理图片格式
img_tensor默认的图片尺寸格式为(3,H,W),但是一般我们的图片格式为(H,W,3),因此需要对图片格式进行调整
通过print(img_array.shape)以查看img是否为C(通道)H(高度)W(宽度)的形式
print(img_array.shape)
#(512, 768, 3)
把add_img语句改成
writer.add_image("test",img_array,1,dataformats='HWC')
4、最终代码
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer=SummaryWriter("logs")#创建实例文件夹“logs”
img_path=r"hymenoptera_data/train/ants_img/5650366_e22b7e1065.jpg"#图片路径
img_PIL=Image.open(img_path)#打开PIL格式的图片
img_np=np.array(img_PIL)#将该图片转换为numpy.array格式
writer.add_image("test",img_np,3,dataformats='HWC')
writer.close()
参数:
tag (string): Data identifier 标题
img_tensor : Image data 在这个位置输入图像且图像的数据类型必须是tensor、numpy等类型的
global_step (int): Global step value to record 训练的步骤
P10-11 Transforms的使用——主要是对图片进行变换
transforms一个torchvision下的一个工具箱,用于格式转化,视觉处理工具,不用于文本。

图片经过transforms工具的变换,得到我们想要的一个图像变换结果
解释:根据模具创造工具,使用具体工具根据说明进行输入和输出
按住ctrl,点击transforms
它里面有多个工具类:
Compose类:将几个变换组合在一起。
CoTensor类:顾名思义,讲其他格式文件转换成tensor类的格式。
ToPILImage类:转换成Image类。
Nomalize类:用于正则化。
Resize类:裁剪。
RandomCrop:随机裁剪。
工具类都有__call__()方法,具体作用看python中的 call()
通过transforms.ToTensor解决两个问题:
- transform应该如何使用?
- 为什么需要tensor数据类型?
ToTensor()使用——把 image 或 numpy 转换为 tensor
from PIL import Image
from torchvision import transforms
img_path = "hymenoptera_data/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
# tensor_trans 是一个类
tensor_trans = transforms.ToTensor() # 吧 imgge 或 numpy 转换为 tensor
tensor_img = tensor_trans(img)
print(tensor_img)
为什么需要tensor数据类型?
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = "hymenoptera_data/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
# print(tensor_img)
writer.add_image("lyy", tensor_img)
writer.close()
P12-13 常见的transforms
小记def __call__与普通def的区别
class Person:
def __call__(self, name):
print("__call__"+" Hello "+ name)
def hello(self,name):
print("Hello"+name)
person=Person()#实例化
person.hello("li4")
person("zhang3")#将zhang3赋给__call__,不需要加.hello
#output:
#Helloli4
#zhang3
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# from paddle.vision.transforms import RandomCrop
import cv2#用opencv读取数据
writer = SummaryWriter("P10_logs")
img = Image.open("OIP-C.jpg")
print(img)
#ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor",img_tensor)
#normalize
#计算公式是减均值除以标准差
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])#前面均值,后面标准差,rgb3通道
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
# Resize
#变换图像大小
print(img.size)
trans_resize = transforms.Resize((512,512))
# img PIL -> resize -> img_resize PIL 变换大小
img_resize = trans_resize(img)
# img_resize PIL -> totensor -> img_resize tensor #转成tensor类型
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
print(img_resize.size)
# Compose - (resize-2)
#合并两个transforms
trans_resize_2 = transforms.Resize(512)#正方形裁剪
# PIL -> PIL ->tensor
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])#括号里面是一个列表的形式
img_resize_2 = trans_compose(img)
writer.add_image("Resize",img_resize_2,1)
#RandomCrop
#按照裁切所需要的尺寸在画面中随意裁切
trans_random = transforms.RandomCrop((50,50))
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("randomCrop", img_crop, i)
writer.close()
总结
-
关注输入和输出类型
若输出类型未知,可使用print(),print(type())直接查看,也可以设置断点debug -
多看官方文档
-
关注方法需要什么参数
在init初始化中查看需要设置的参数,在Args查看具体的数据类型 -
如果不知道括号中填入什么参数,在PyCharm中可以使用CTRL+P查看相关提示
P14 torchvision数据集使用——CFAR10数据集举例
CIFAR-10数据集包含60000张32x32彩色图像,分为10个类,每类6000张。有50000张训练图片和10000张测试图片。
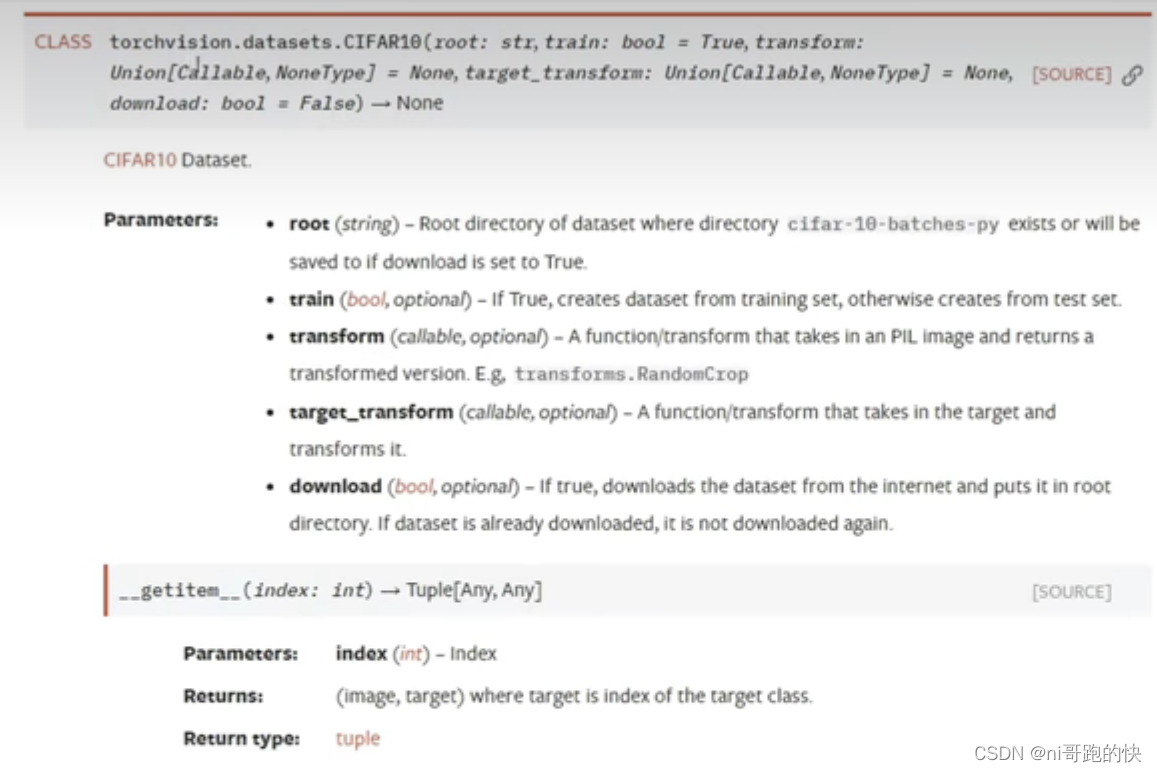
root:数据集的位置
tran:true-训练集;false-测试集
download:true-自动从网上下载数据集
先导入包,然后输入
import torchvision
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True)
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)
#注意所有的True/False首字母要大写,不然识别不出来
#download这个方法比较智能,如果你没有它会自动给你下载到这个地址上,如果你之前在这个地址中下载过,他会直接辨别并验证,不会重复下载,所以可以使用让它为True
使用print打印数据集里的一张图
import torchvision
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)
print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show() # 展示数据集中的图片

最后面的那个6是对应的class,在CIFAR10中我们有10个class,在右边红框里可以看到
(<PIL.Image.Image image mode=RGB size=32x32 at 0x2C0C7D92588>,6)
test的第一张图片是PIL格式,RGB形式,大小32x32,其分类为第六类
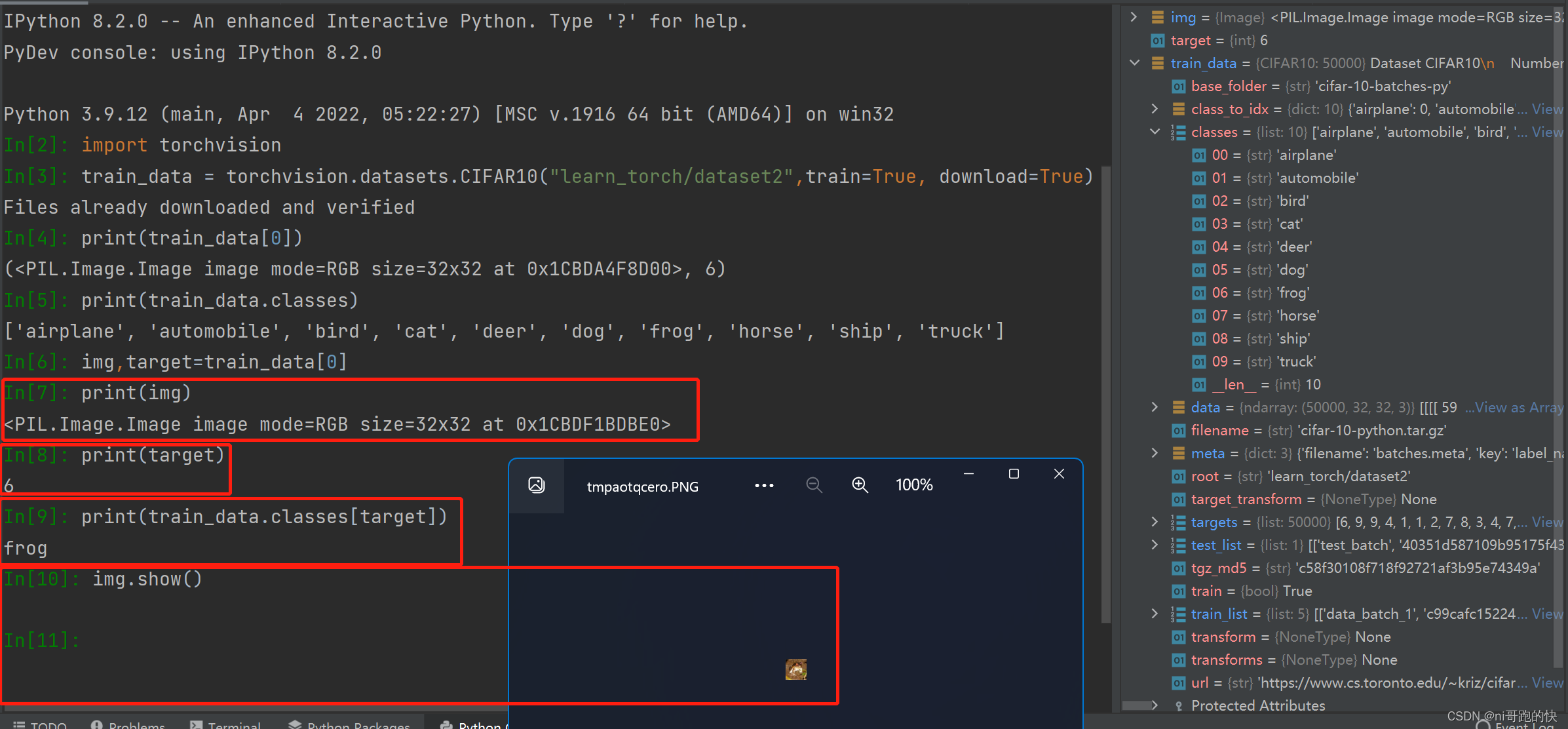
target对应的数据是这个数据集对应的识别出来的图片属性这个target对应的数字为6,则这个数据集对应的第一个是类别里面对应的frog。其实也可以使用label代替。
与SummaryWriter联合使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
pipeline = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=pipeline, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=pipeline, download=True)
print(train_set.classes)
img, label = train_set[0]
print(img)
print(label) # 代表某一类的数字
print(train_set.classes[label]) # 数字代表的类别名
writer = SummaryWriter("logs")
for i in range(10):
img, label = train_set[i]
writer.add_image(tag="test_img", img_tensor=img, global_step=i)
writer.close()
DataLoader 使用
将Dataset视为一摞牌,而DataLoader就是抓几张牌,以什么样的方式抓牌
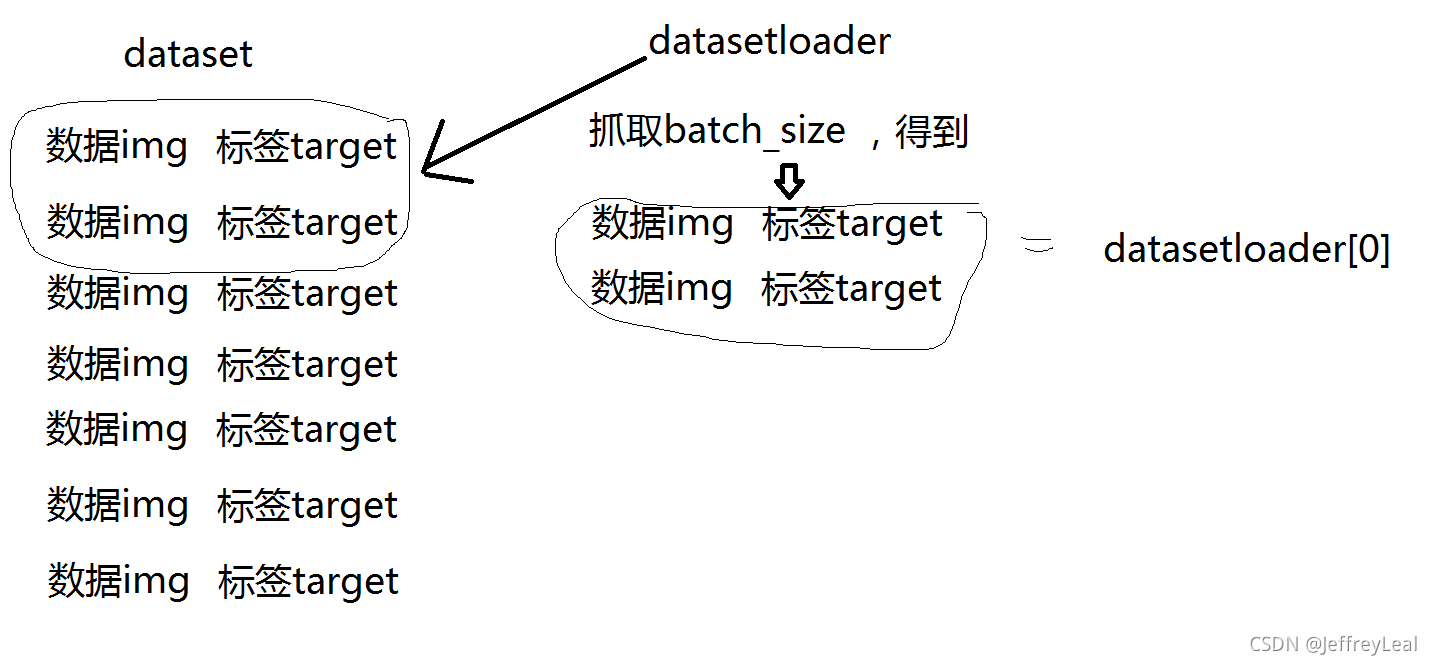
点进dataset源文件查找getitem()可以查看该数据集返回数据类型(如CIFAR,返回img和target)
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False)
参数
- dataset ( Dataset ) – 从中加载数据的数据集。
- batch_size ( int , optional ) – 每批要加载多少样本(默认值:1)。
- shuffle ( bool , optional ) – 设置为True在每个 epoch 重新洗牌数据(默认值:False)。
- num_workers ( int , optional ) – 用于数据加载的子进程数。0表示数据将在主进程中加载。(默认:0)
- drop_last ( bool , optional ) –True如果数据集大小不能被批次大小整除,则设置为丢弃最后一个不完整的批次。如果False数据集的大小不能被批大小整除,那么最后一批将更小。(默认:False)
import torchvision
from torch.utils.data import DataLoader
train_set=torchvision.datasets.CIFAR10(root="./dataset",transform=torchvision.transforms.ToTensor(),train=True,download=True)
train_loader=DataLoader(dataset=train_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
for data in train_loader:
imgs,targets=data
print(imgs.shape)
print(targets)
#output:
#torch.Size([4, 3, 32, 32])#四张图片,每张三通道,32x32
#tensor([4, 9, 3, 9]).....#标签
多张图片写入tensorboard:
对于打包的图片展示,使用的方法是add_images()方法,单张图片展示使用add_image()方法
step=0
writer=SummaryWriter("dataloader")
for data in train_loader:
imgs,targets=data
writer.add_images("test1",imgs,step)
step=step+1
writer.close()
P16-18 神经网络基本骨架以及卷积层
torch.nn.Module介绍
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self): #初始化
super().__init__()
#在使用nn.module构建神经网络时,需要在__init__()方法中对继承的Module类中的属性进行调用,因此在初始化方法中需要添加
self.conv1 = nn.Conv2d(1, 20, 5) #卷积模型1
self.conv2 = nn.Conv2d(20, 20, 5) #卷积模型2
def forward(self, x):
x = F.relu(self.conv1(x)) #输入(x) -> 卷积 -> 非线性
return F.relu(self.conv2(x)) #卷积 -> 非线性 -> 输出
from torch import nn
import torch
class haha(nn.Module):
def __init__(self):
super(haha,self).__init__()#调用父类初始化函数
#自定义
def forward(self,input):#forward一定不能拼错!否则会报错
output=input+1#自定义
return output#自定义
c=haha()#实例化
x=torch.tensor(1.0)
output=c(x)
print(output)
#output
#tensor(2.)
torch.nn.functional.conv2d介绍
首先介绍一下torch.nn和torch.nn.functional的区别
- torch.nn是实例化的使用
- torch.nn.functional是方法的使用
torch.nn是对于torch.nn.functional的封装,二者类似于包含的关系,如果说torch.nn.functional是汽车齿轮的运转,那么torch.nn就是方向盘
在由多个输入平面组成的输入图像上应用 2D 卷积
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
参数
-
input
形状的输入张量(minibatch ,in_channels , iH , iW) -
weight
形状过滤器(out_channels, in_channels/groups , kH , kW) -
bias
形状的可选偏差张量(out_channels). 默认:None -
stride
卷积核的步幅。可以是单个数字或元组(sH, sW)。默认值:1 -
padding
输入两侧的隐式填充。可以是字符串 {‘valid’, ‘same’}、单个数字或元组(padH, padW)。默认值:0 padding='valid'与无填充相同。padding='same'填充输入,使输出具有与输入相同的形状。但是,此模式不支持 1 以外的任何步幅值。
nn.funcational.conv2d实际操作
import torch
import torch.nn.functional as F
#输入:5x5矩阵
input=torch.tensor([1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1])
#卷积核3x3矩阵
kernel=torch.tensor([1,2,1],
[0,1,0],
[2,1,0])
#reshape函数:尺寸变换,要对应conv2d input的要求(minibatch=1,channel=1,h,w)
input=torch.reshape(input,(1,1,5,5))
#如果不进行转换直接输入会出现报错
# RuntimeError: weight should have at least three dimensions
kernel=torch.reshape(kernel,(1,1,3,3))
#stride:每次(在哪个方向)移动几步
output=F.conv2d(input,kernel,stride=1)
print(output)
output1=F.conv2d(input,kernel,stride=2)
print(output1)
output2=F.conv2d(input,kernel,stride=1,padding=1)
print(output2)
#output
# tensor([[10, 12, 12],
# [18, 16, 16],
# [13, 9, 3]])
# tensor([[10, 12],
# [13, 3]])
# tensor([[ 1, 3, 4, 10, 8],
# [ 5, 10, 12, 12, 6],
# [ 7, 18, 16, 16, 8],
# [11, 13, 9, 3, 4],
# [14, 13, 9, 7, 4]])
nn.conv2d实际操作:对神经网络进行了封装,在面对更复杂的卷积网络场景的时候更适合
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
参数
-
in_channels (int) – Number of channels in the input image 输入图像的通道数
-
out_channels (int) – Number of channels produced by the convolution 卷积后输出的通道数,也代表着卷积核的个数
-
kernel_size (int or tuple) – Size of the convolving kernel 卷积核的大小
-
stride (int or tuple, optional) – Stride of the convolution. Default: 1 步径大小
-
padding (int, tuple or str, optional) – Padding added to all four sides of the input. Default: 0 填充
-
padding_mode (string, optional) – 'zeros', 'reflect', 'replicate' or 'circular'. Default: 'zeros' 以什么方式填充
-
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1 卷积核之间的距离,空洞卷积
-
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
-
bias (bool, optional) – If True, adds a learnable bias to the output. Default: True 偏置
使用学习到的方法构建了一个简单的卷积网络,并对输入输出图像进行展示对比
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset=dataset,batch_size=64,shuffle=True,drop_last=False)
class test(nn.Module):
def __init__(self):
super(test, self).__init__()
self.conv1=nn.Conv2d(3,6,3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
writer=SummaryWriter("log1")
test1=test()
step=0
for data in dataloader:
imgs,t=data
output=test1(imgs)
#torch.size([64,3,32,32])
writer.add_images("input",imgs,step)
#由于图片只能以三个通道显示,因此要把6个channel改成3个
#torch.size([64,6,30,30])->[???,3,30,30]
#batch_size不知道写多少的时候就写-1,它会自动计算
output=torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step=step+1
writer.close()
原始图像:
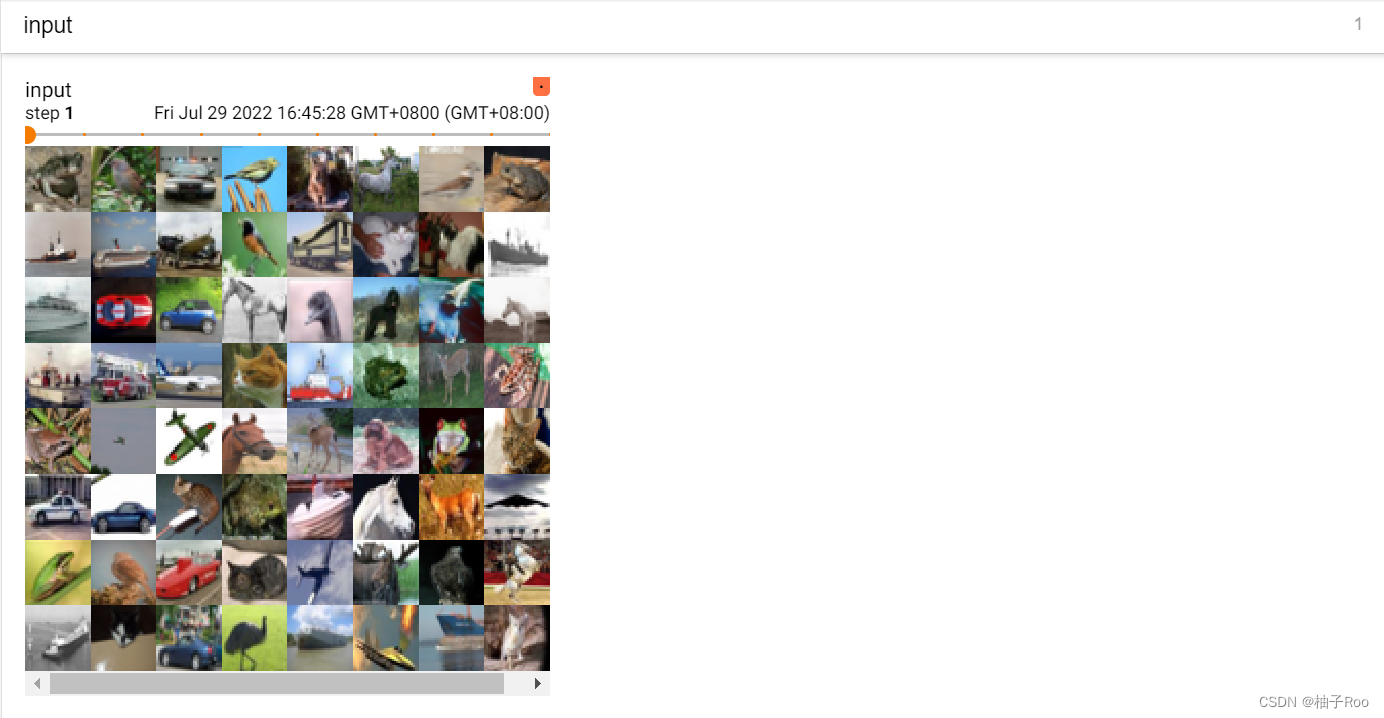
卷积后的图像:
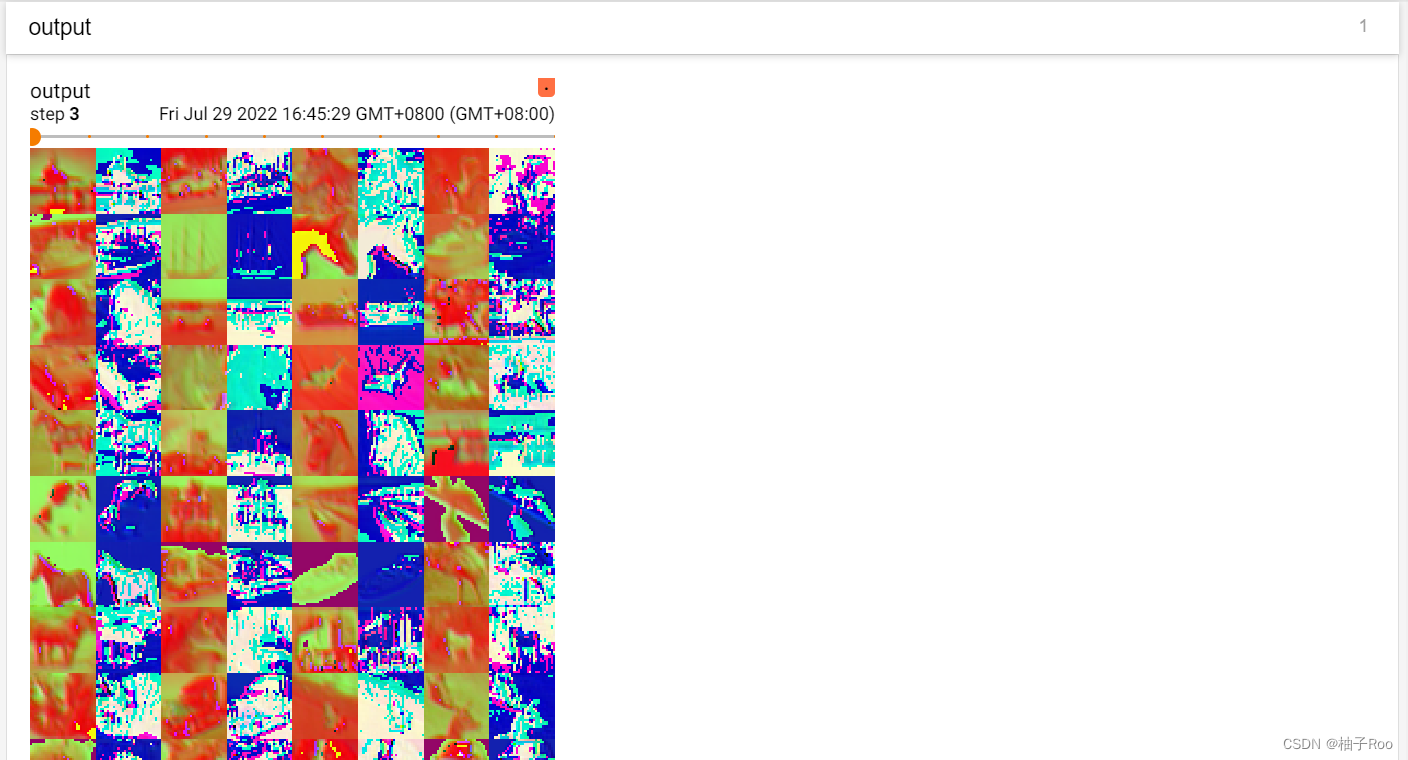
P19 最大池化层——以MaxPool2d为例
在一个范围内(选中的kernel_size中)选择有代表的一个数来代表整个kernel_size,减少数据量。
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
在由多个输入平面组成的输入信号上应用 2D 最大池化
参数
- kernel_size – 最大的窗口大小
- stride——窗口的步幅。默认值为kernel_size
- padding – 要在两边添加隐式零填充
- dilation – 控制窗口中元素步幅的参数
- return_indices - 如果True,将返回最大索引以及输出。torch.nn.MaxUnpool2d以后有用
- ceil_mode – 当为 True 时,将使用ceil而不是floor来计算输出形状。简单点来说,ceil模式就是会把不足square_size的边给保留下来,单独另算,或者也可以理解为在原来的数据上补充了值为-NAN的边。而floor模式则是直接把不足square_size的边给舍弃了。
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset=dataset,batch_size=64,shuffle=True,drop_last=False)
#dtype:将数据类型更改为浮点数
#输入:5x5矩阵
input=torch.tensor([1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1],dtype=torch.float32)
input=torch.reshape(input,(-1,1,5,5))
class test(nn.Module):
def __init__(self):
super(test, self).__init__()
self.maxpool1=MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output=self.maxpool1(input)
return output
test1=test()
#矩阵输出
print(test1(input))
#图像输出
writer=SummaryWriter("log2")
step=0
for data in dataloader:
imgs,t=data
writer.add_images("input", imgs, step)
output=test1(imgs)
#注意,最大池化不会改变channel(input是3通道,output也是三通道)
writer.add_images("output", output, step)
step=step+1
writer.close()
output:
# tensor([[2., 3.],
# [5., 1.]])

P20 非线性激活——ReLU函数
PyTorch官方文档ReLU
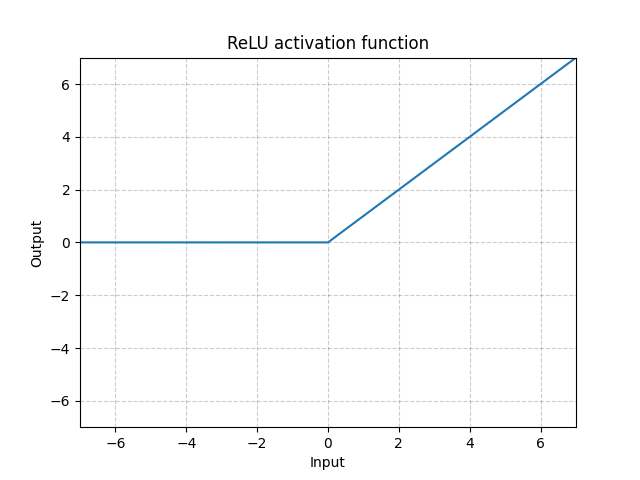
torch.nn.ReLU(inplace=False)
参数:
inplace 可以选择是否用output替换掉input执行操作。默认:False

import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor(([1, -0.5],
[-1, 3]))
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU() # inplace = False, save the original value, put the new value to another variable
def forward(self, input):
output = self.relu1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
加上sigmoid
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor(([1, -0.5],
[-1, 3]))
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10(root="dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU() # inplace = False, save the original value, put the new value to another variable
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("P20")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = tudui(input)
writer.add_images("output", output, step)
step += 1
writer.close()
P21 线性层和其它层
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
参数:
- in_features – 每个输入样本的大小
- out_features – 每个输出样本的大小
- bias——即线性层里面的b(kx+b)。如果设置为False,该层将不会学习附加偏差。默认:True
将图片内容转化为一维,展开后,inputsize为3072
for data in dataloader:
imgs,t=data
print(imgs.shape)
output=torch.reshape(imgs,(64,1,1,-1))
print(output.shape)
output:
#torch.Size([64, 3, 32, 32])
#torch.Size([64, 1, 1, 3072])
实际演练
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#这里不droplast后面会报错,因为linear1的定义是196608,而最后一组图片不够64张,最后的大小也不足196608
dataloader=DataLoader(dataset,batch_size=64,drop_last=True)
class test(nn.Module):
def __init__(self):
super(test, self).__init__()
self.linear1=Linear(3072,10)
def forward(self,input):
output=self.linear1(input)
return output
test1=test()
for data in dataloader:
imgs,t=data
print(imgs.shape)
#将图片线性化
output=torch.reshape(imgs,(64,1,1,-1))
# 也可以用flatten,代码为output=torch.flatten(imgs)
print(output.shape)
output=test1(output)
print(output.shape)
output:
#torch.Size([64, 3, 32, 32])
#torch.Size([64, 1, 1, 3072])
#torch.Size([64, 1, 1, 10])
flatten和reshape展平的功能一样,但是只能够变成一维


P22 Sequential以及搭建网络小实战
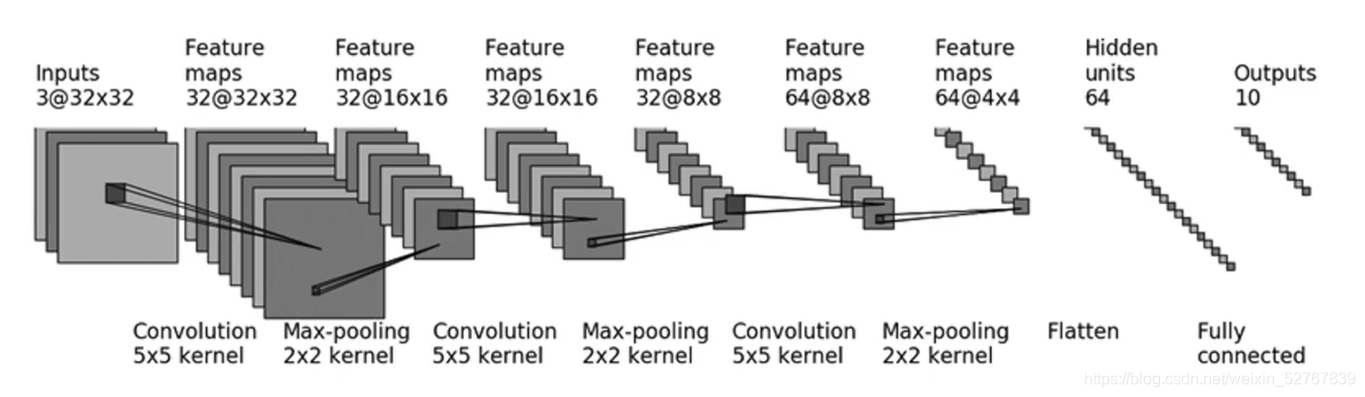
实现的代码:不使用nn.Sequential
计算padding的解题思路,当然也可以口算

import torch
from torch import nn
class test(nn.Module):
def __init__(self):
super(test, self).__init__()
#因为size_in和size_out都是32,经过计算得出padding=2,stride=1
self.conv1=nn.Conv2d(3,32,5,padding=2,stride=1)
self.pool1=nn.MaxPool2d(2)
#尺寸不变,和上面一样
self.conv2=nn.Conv2d(32,32,5,stride=1,padding=2)
self.pool2=nn.MaxPool2d(2)
# 尺寸不变,和上面一样
self.conv3=nn.Conv2d(32,64,5,stride=1,padding=2)
self.pool3 = nn.MaxPool2d(2)
self.flatten=nn.Flatten()
#in_feature:64*4*4,out_feature:64
self.linear1=nn.Linear(1024,64)
self.linear2=nn.Linear(64,10)
def forward(self,x):
x=self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.pool3(x)
x=self.flatten(x)
x=self.linear1(x)
x=self.linear2(x)
return x
test1=test()
#对网络结构进行检验
input=torch.ones((64,3,32,32))
output=test1(input)
print(output.shape)
output:
#torch.Size([64, 10])
实现的代码:不使用nn.Sequential,且不确定线性层的输入时
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear
from torch.nn.modules.flatten import Flatten
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2) # input size is as the same as output size, so padding is 2
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
return x
tudui = Tudui()
print(tudui)
# test if the net is correct
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
实现的代码:使用nn.Sequential,直接输出
Sequential的作用就是简化代码块1,把代码块1装进去Sequential容器里,就是代码块2的代码了,然后代码块1就可以删除
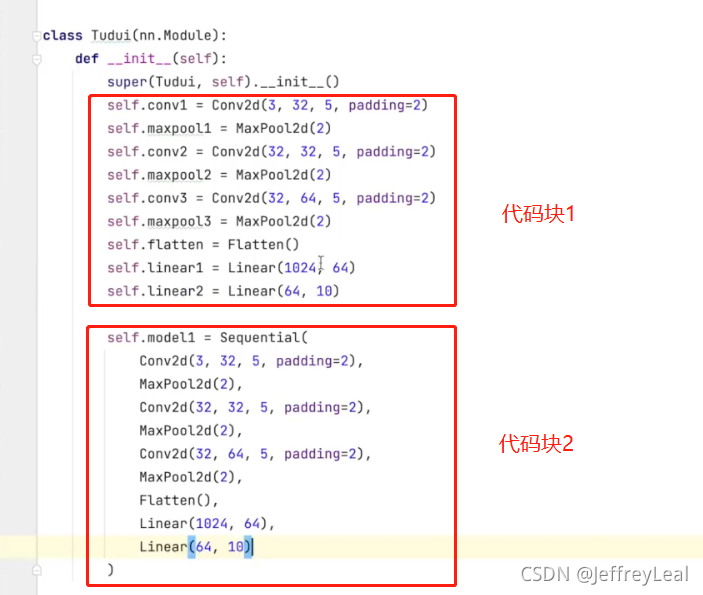
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential
from torch.nn.modules.flatten import Flatten
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
# test if the net is correct
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
实现的代码:使用nn.Sequential,输入SummaryWriter
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential
from torch.nn.modules.flatten import Flatten
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
# test if the net is correct
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
writer = SummaryWriter("P21")
writer.add_graph(tudui, input)
writer.close()
tensorboard中打开可以看到每一层的关系和参数
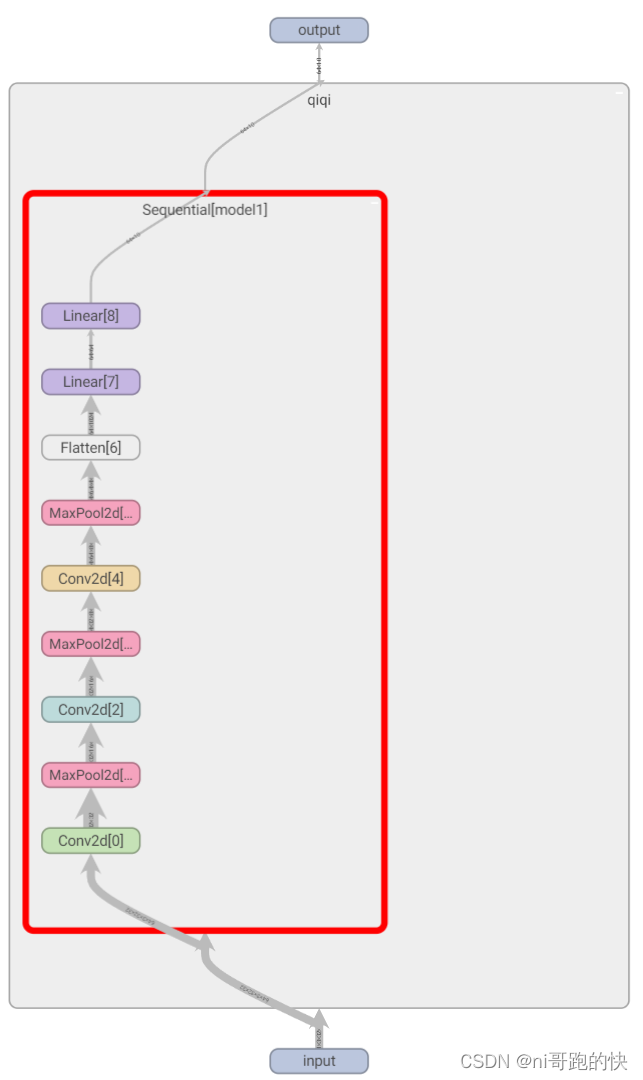
P23 损失函数与反向传播
损失函数
损失函数的作用:
- 计算实际输出与目标输出之间的差距
- 为我们更新数据输出提供一定依据(反向传播),grand
L1Loss
参数设置
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
参数除了最后一个前面的都已经弃用了
当使用的参数为 mean(在pytorch1.7.1中elementwise_mean已经弃用)会对N个样本的loss进行平均之后返回
当使用的参数为 sum会对N个样本的loss求和
reduction = none<表示直接返回n分样本的loss
实际运行
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# L1Loss = (0 + 0 + 2) / 3 = 0.6667
loss = L1Loss()
result = loss(inputs, targets)
print(result)
平方差MSELoss
参数设置
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
实际运行
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# L1Loss = (0 + 0 + 2) / 3 = 0.6667
# reduction = 'sum', L1Loss = 0 + 0 + 2 = 2
loss = L1Loss(reduction='sum')
result = loss(inputs, targets)
# MSELoss = (0 + 0 + 2^2) / 3 = 1.3333
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result)
print(result_mse)
# output
# tensor(2.)
# tensor(1.3333)
交叉熵CrossEntropyLoss
参数设置
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction=‘mean’, label_smoothing=0.0)
运行代码
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Linear
from torch.nn.modules.flatten import Flatten
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
print(result_loss)
梯度下降
以交叉熵损失函数为例,backward()方法为反向传播算法
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Linear
from torch.nn.modules.flatten import Flatten
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
result_loss.backward()
print(result_loss)
P24 优化器torch.optim——使用随机梯度下降法(SGD)作为优化器的优化依据
优化器的作用:将模型的中的参数根据要求进行实时调整更新,使得模型变得更加优良。
构建与使用
# 优化器通常设置模型的参数,学习率等
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
for input, target in dataset:
#把上一次计算的梯度清零
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
# 损失反向传播,计算梯度
loss.backward()
# 使用梯度进行学习,即参数的优化
optimizer.step()
在degug内查看gard
test1=test()
#lossFunction模型
loss=nn.CrossEntropyLoss()
#优化器模型
optim=torch.optim.SGD(test1.parameters(),0.01)
#只对每张图片进行一轮学习
for data in dataloader:
imgs,t=data
output=test1(imgs)
result_loss=loss(output,t)
#将每个梯度清为0(初始化)
optim.zero_grad()
#反向传播,得到每个可调节参数对应的梯度(grad不再是none)
result_loss.backward()
#对每个参数进行改变,weight-data被改变
optim.step()
print(result_loss)
-
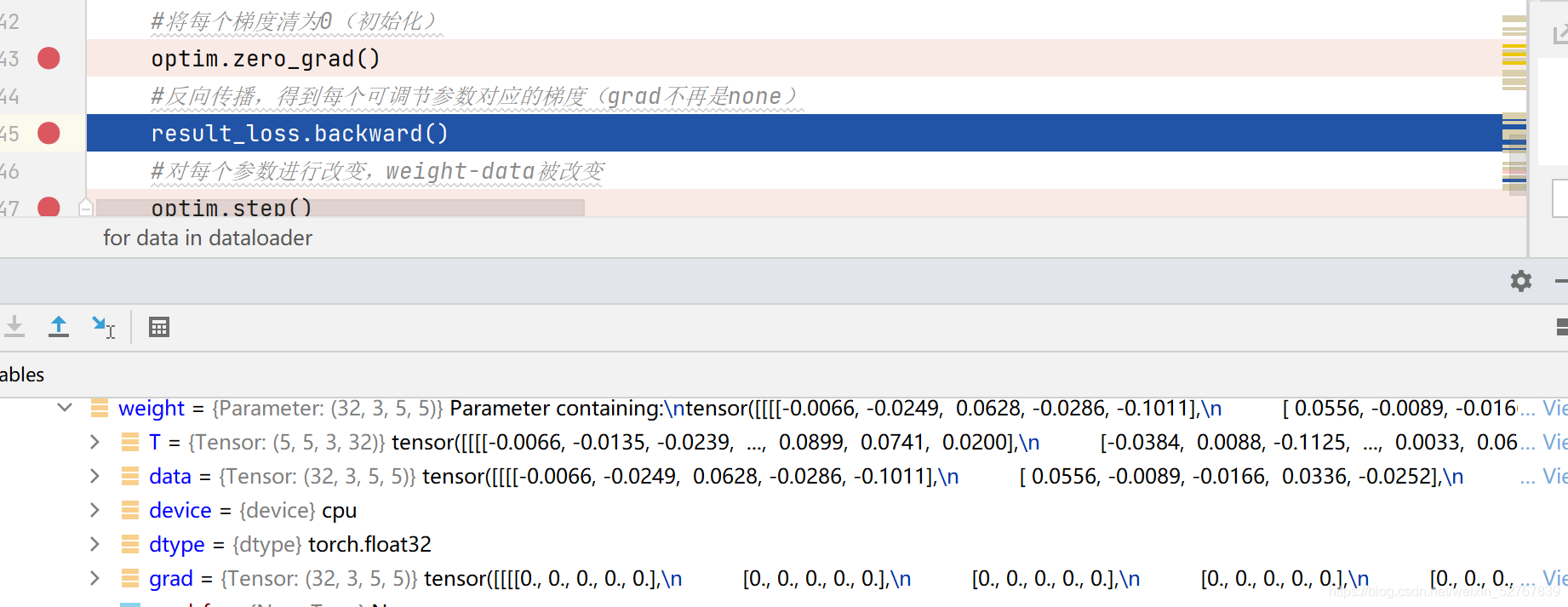
43行之前的weight,grad不为none(非首次循环)
![]()
-
43行运行完毕,gard清零,data不变
![]()
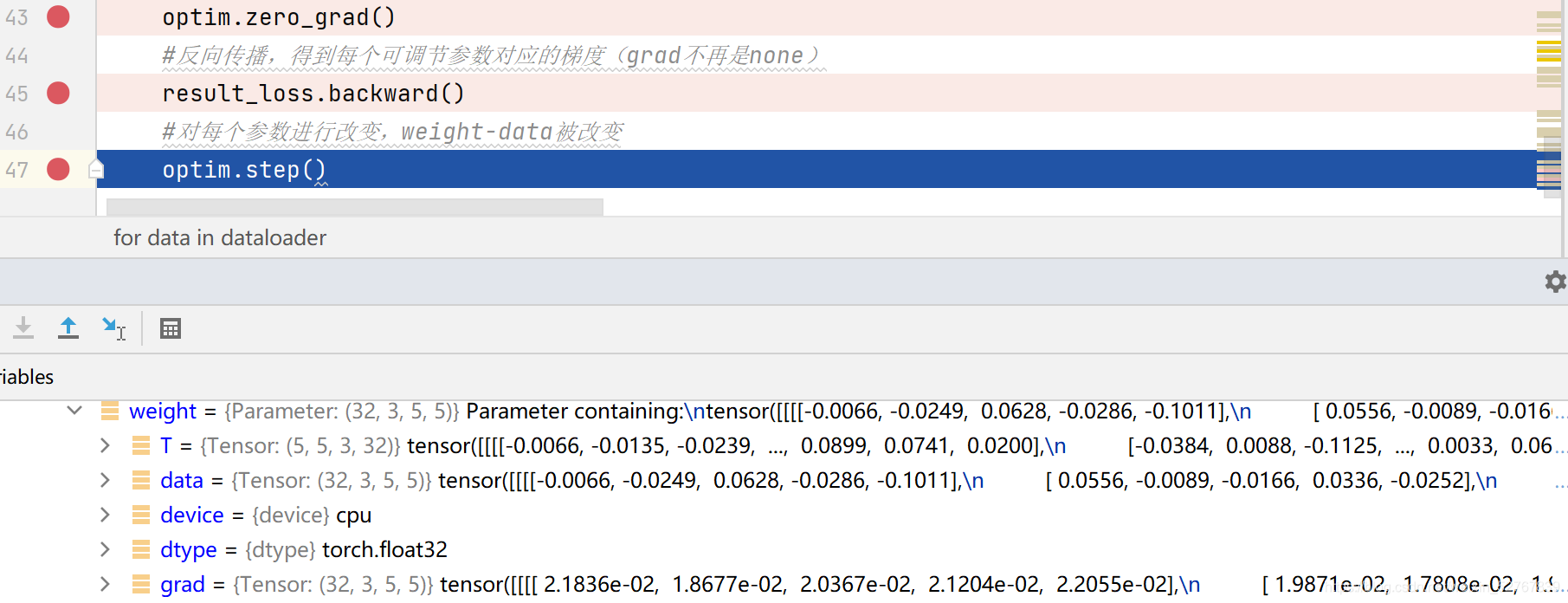
-
45行运行完毕,grad被重新计算,data不变
![]()
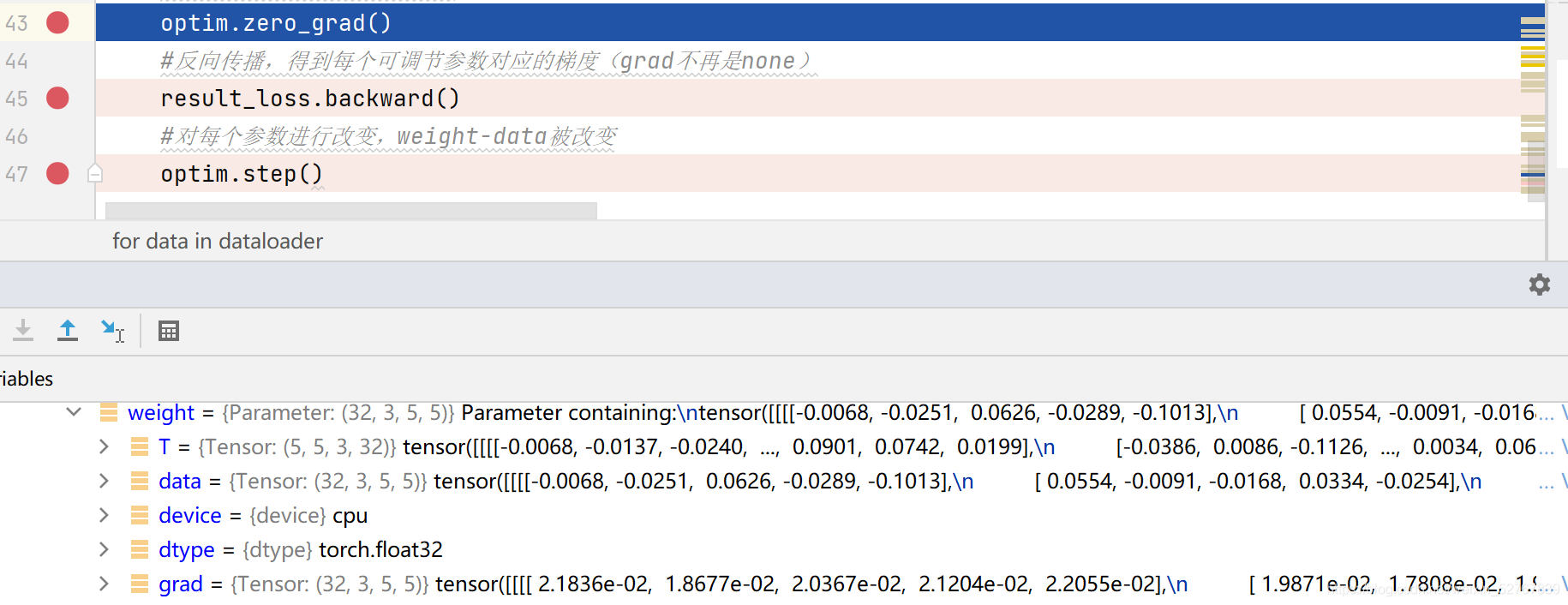
-
47行运行完毕,grad不变,data更新(data就是模型中的参数)
![]()
使用优化器进行优化
import torch
import torchvision
from torch import nn
from torch import optim
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
from torch.utils.data import DataLoader
#导入数据
dataset2 = torchvision.datasets.CIFAR10("dataset2",transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset2,batch_size=1)
#搭建模型
class qiqi(nn.Module):
def __init__(self):
super(qiqi, self).__init__()
self.model1=Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
#引入交叉熵损失函数
loss=nn.CrossEntropyLoss()
#引入优化器
optim=torch.optim.SGD(test1.parameters(),0.01)
qq=qiqi()
for epoch in range(20): #最外面这一层是学习的次数
running_loss=0.0
for data in dataloader: #针对dataloader里面一batch_size的数据学习一次
imgs,targets=data #如果dataloader里面只有一个数据,则针对这个数据计算参数
outputs=qq(imgs)
result_loss=loss(outputs,targets) #计算输出和目标之间的差,计入result_loss
optim.zero_grad() #优化器中每一个梯度的参数清零
result_loss.backward() #反向传播,求出每一个节点的梯度
optim.step() #对每一个参数进行调优
running_loss=running_loss+result_loss #记录叠加的损失值
print(running_loss)
output:
#总loss在逐渐变小
# tensor(18712.0938, grad_fn= < AddBackward0 >)
# tensor(16126.7949, grad_fn= < AddBackward0 >)
# tensor(15382.0703, grad_fn= < AddBackward0 >)
P25 现有网络模型的使用及修改——以vgg16模型为例
简单查看一下vgg16模型
torchvision.models.vgg16(pretrained: bool = False, progress: bool = True, **kwargs: Any) → torchvision.models.vgg.VGG
参数
- pretrained (bool) – If True, returns a model pre-trained on ImageNet
- progress (bool) – If True, displays a progress bar of the download to stderr显示下载进度条
深入了解
vgg16_t=torchvision.models.vgg16(pretrained=True)
vgg16_f=torchvision.models.vgg16(pretrained=False)
vgg16_t的weight:

vgg16_f的weight:

vgg16_t的网络结构:

vgg16_f的网络结构:

可以看到vgg16最后输出1000个类,想要将这1000个类改成10个类。对现有网络模型的修改可分为两种方式,一种为添加,另一种为修改。
import torch
from torch import nn
import torchvision
vgg_true = torchvision.models.vgg16(pretrained=True)
vgg_false = torchvision.models.vgg16(pretrained=False)
vgg_true.add_module("add_model", nn.Linear(in_features=1000, out_features=10))
print(vgg_true)
vgg_false.classifier[6] = nn.Linear(in_features=4096, out_features=10)
print(vgg_false)
P26 网络模型的保存与读取
保存
import torchvision
import torch
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1:既保存模型结构,也保存了参数,.pth不是必须的
torch.save(vgg16, "vgg16_model1.pth")
# 保存方式2 : 把参数保存成字典,不保存结构 (官方推荐)
torch.save(vgg16.state_dict(), "vgg16_model2.pth")
print("end")
读取
import torch
import torchvision
# 加载方式1 - 保存方式1
model = torch.load("vgg16_model1.pth")
print(model)
# 加载方式2
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_model2.pth"))
print(vgg16)
以方式一形式读取自定义模型时要先将该模型复制或引用到读取文件中,否则会报错
import torch
import torchvision
from torch import nn
# trap with saving method 1
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
torch.save(tudui, "tudui_method1.pth")
from data_save import * #将具体的文件名进行导入,来保证模型可以调用。可以不用再次实例化模型,即 qq=qiqi()
model = torch.load("tudui_method1.pth") # must visit the definition of the model
print(model)
P27-29 完整的训练套路
数据集进行下载读取,并进行分组
# 读取数据集
trainset = torchvision.datasets.CIFAR10("dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
testset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 数据分组
train_loader = DataLoader(trainset, 64)
test_loader = DataLoader(testset, 64)
搭建神经网络:
文件model专门用于存放模型,使用时进行调用更符合实际应用场景。
import torch
from torch import nn
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, input):
output = self.model(input)
return output
# to test if the neural network is right
if __name__ == '__main__':
input = torch.ones((64, 3, 32, 32))
test = Test()
output = test(input)
print(output.shape)
train.py文件
# 创建网络模型
test = Test()
# 定义损失函数
loss_fn = torch.nn.CrossEntropyLoss()
# 定义优化器
learning_rate = 0.001
optimizer = torch.optim.SGD(params=test.parameters(), lr=learning_rate)
# 记录训练次数
train_step = 0
# 记录测试次数
test_step = 0
writer = SummaryWriter("logs")
对模型进行训练
# 训练
epoch = 20
for i in range(epoch):
# 训练步骤
print("-------第 {} 轮训练-------".format(i+1))
test.train()
for train_data in train_loader:
imgs, target = train_data
output = test(imgs)
loss = loss_fn(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_step += 1
if train_step % 100 == 0:
print("第 {} 次训练完成 训练损失:{}".format(train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), train_step)
在测试集上进行测试
# 测试步骤
test.eval()
test_loss_sum = 0.0
total_accuracy = 0
with torch.no_grad():
for test_data in test_loader:
imgs, target = test_data
output = test(imgs)
loss = loss_fn(output, target)
accuracy = (output.argmax(1) == target).sum()
test_loss_sum += loss.item()
total_accuracy += accuracy
writer.add_scalar("test_loss", test_loss_sum, test_step)
print("在测试集上的Loss:{}, 正确率:{}".format(test_loss_sum, total_accuracy/len(testset)))
test_step += 1
全流程源代码
import torch
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from MyModel import *
# 准备数据集
train_set = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_set = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 查看数据集大小
print(len(train_set))
print(len(test_set))
# 打包数据集
train_loader = DataLoader(train_set, batch_size=64, shuffle=True, drop_last=True)
test_loader = DataLoader(test_set, batch_size=64, shuffle=True, drop_last=True)
# 模型
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MyNN().to(DEVICE)
# 损失、优化器以及一些超参数
criteria = nn.CrossEntropyLoss().to(DEVICE)
LR = 0.01
EPOCHS = 20
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
writer = SummaryWriter("train-logs") # tensorboard可视化
batch_num = 0 # 无论处于哪个epoch,当前处在第几批
# 训练
for epoch in range(EPOCHS):
print("-----开始第{}轮epoch训练-----".format(epoch + 1))
current_epoch_batch_num = 0 # 当前epoch中的第几批
model.train() # 训练模式,和eval一样,目的在于是否激活dropout等。
for data in train_loader:
imgs, labels = data
imgs, labels = imgs.to(DEVICE), labels.to(DEVICE)
output = model(imgs)
optimizer.zero_grad()
loss = criteria(output, labels)
loss.backward()
optimizer.step()
current_epoch_batch_num += 1 # 累计当前epoch中的批数
batch_num += 1 # 累计总批数
# 在当前epoch中,每扫过100批才打印出那批的损失
if current_epoch_batch_num % 100 == 0:
print("第{}个epoch中第{}批的损失为:{}".format(epoch + 1, current_epoch_batch_num, loss.item()))
writer.add_scalar("train-loss", scalar_value=loss.item(), global_step=batch_num) # tensorboard可视化
# 测试:固定梯度(准确说是验证,用来确定超参数)
test_loss = 0
test_acc = 0
model.eval() # 测试模式
with torch.no_grad():
for data in test_loader:
imgs, labels = data
imgs, labels = imgs.to(DEVICE), labels.to(DEVICE)
output = model(imgs)
loss = criteria(output, labels)
test_loss += loss.item()
pred = output.argmax(1) # 按轴取得每个样本预测的最大值的索引(索引对应label编号!)
pred_right_sum = (pred == labels).sum() # 比对每个样本预测和真实标记,结果为true/false组成的数组,求和时会自动转换为数字
test_acc += pred_right_sum # 将当前批预测正确的数量累加进总计数器
print("第{}个epoch上的测试集损失为:{}".format(epoch + 1, test_loss))
print("第{}个epoch上整体测试集上的准确率:{}".format(epoch + 1, test_acc / len(test_set)))
writer.add_scalar("test-loss", scalar_value=test_loss, global_step=epoch + 1) # tensorboard可视化
writer.add_scalar("test-acc", scalar_value=test_acc / len(test_set), global_step=epoch + 1)
# 保存每个epoch训练出的模型
torch.save(model, "NO.{}_model.pth".format(epoch + 1)) # 保存模型结构和参数
print("当前epoch的模型已保存")
# torch.save(model.state_dict(), "NO.{}_model_param_dic.pth".format(epoch + 1)) # 仅保存参数字典
writer.flush()
writer.close()
P30-31 利用GPU训练:两种方法
方法一:数据(输入、标注) 损失函数 模型 .cuda()
# 创建网络模型
test = Test()
test = test.cuda()
# 定义损失函数
loss_fn = torch.nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()
imgs, target = train_data
imgs = imgs.cuda()
target = target.cuda()
imgs, target = test_data
imgs = imgs.cuda()
target = target.cuda()
output = test(imgs)
方法二:.to(device)
Device = torch.device("cpu") 或 torch.device("cuda")
torch.device("cuda:0") 指定第一张显卡
# 定义训练的设备
device = torch.device("cuda:0")
# 创建网络模型
test = Test()
test = test.to(device)
# 定义损失函数
loss_fn = torch.nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
for train_data in train_loader:
imgs, target = train_data
imgs = imgs.to(device)
target = target.to(device)
for test_data in test_loader:
imgs, target = test_data
imgs = imgs.to(device)
target = target.to(device)
第二种方法的完整代码
import torch
import torchvision
from torch import nn
from torch import optim
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
#定义训练的设备
device = torch.device("cuda")
#准备数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset2", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root = "./dataset2",train=False, transform=torchvision.transforms.ToTensor(),
download=True)
#length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#准备训练模型
class qiqi(nn.Module):
def __init__(self):
super(qiqi, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2), #注意有逗号
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
#创建网络模型
qq=qiqi()
qq = qq.to(device)
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
#优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(qq.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10
#记录时间
start_time = time.time()
writer = SummaryWriter("train_gpu2")
for i in range(epoch):
print("--------第 {} 轮训练开始--------".format(i+1))
#训练步骤开始
qq.train() #对现在的网络层没影响,在含有bn层和dropout层的模型中有影响,因为这两个层在训练和测试是不一样的
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = qq(imgs)
loss = loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step+1
if total_train_step % 100 == 0:
end_time = time.time()
print("本轮用时:{}".format(end_time-start_time) )
print("训练次数:{}, loss: {}".format(total_train_step,loss.item())) #这里item也可以不用
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
qq.eval() #对现在的网络层没影响,在含有bn层和dropout层的模型中有影响,因为这两个层在训练和测试是不一样的
total_test_loss = 0
total_accurancy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = qq(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accurancy = (outputs.argmax(1) == targets).sum()
total_accurancy = total_accurancy + accurancy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accurancy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accurancy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(qq,"qq_{}.pth".format(i))
print("模型已保存")
writer.close()
P33:完整的模型验证套路
import torch
import torchvision
from torch import nn
from torch import optim
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
#定义训练的设备
device = torch.device("cuda")
#准备数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset2", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root = "./dataset2",train=False, transform=torchvision.transforms.ToTensor(),
download=True)
#length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#准备训练模型
class qiqi(nn.Module):
def __init__(self):
super(qiqi, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2), #注意有逗号
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
#创建网络模型
qq=qiqi()
qq = qq.to(device)
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
#优化器
learning_rate = 5e-3
optimizer = torch.optim.SGD(qq.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 70
#记录时间
start_time = time.time()
writer = SummaryWriter("train_gpu2")
for i in range(epoch):
print("--------第 {} 轮训练开始--------".format(i+1))
#训练步骤开始
qq.train() #对现在的网络层没影响,在含有bn层和dropout层的模型中有影响,因为这两个层在训练和测试是不一样的
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = qq(imgs)
loss = loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step+1
if total_train_step % 100 == 0:
end_time = time.time()
print("本轮用时:{}".format(end_time-start_time) )
print("训练次数:{}, loss: {}".format(total_train_step,loss.item())) #这里item也可以不用
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
qq.eval() #对现在的网络层没影响,在含有bn层和dropout层的模型中有影响,因为这两个层在训练和测试是不一样的
total_test_loss = 0
total_accurancy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = qq(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accurancy = (outputs.argmax(1) == targets).sum()
total_accurancy = total_accurancy + accurancy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accurancy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accurancy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(qq,"qq_model/qq_{}.pth".format(i))
print("模型已保存")
writer.close()


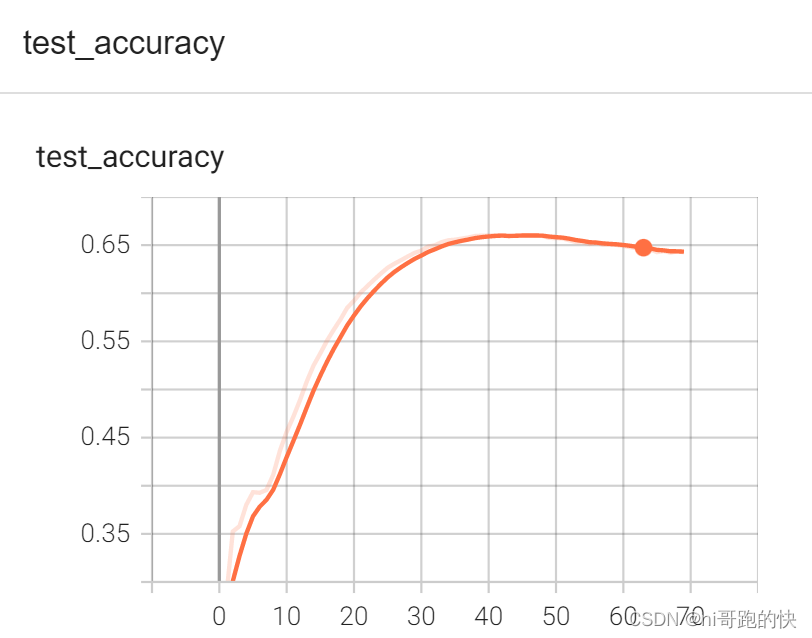
验证代码如下:
拿小狗图像作为输入

import torch
import torchvision.transforms
from PIL import Image
# 网上下载一张狗的图片
img = Image.open("../images/dog.png")
image = image.convert('RGB')
#因为png格式是四个通道,除了RGB三通道之外,还有一个透明通道,所以,我们调用此行保留颜色通道
#加上这句话之后可以进一步适应不用格式,不同截图软件的图片
pipeline = torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()
])
img = pipeline(img)
print(img.shape)
img = torch.reshape(img, (1, 3, 32, 32)) # reshape一下,增加维度,满足输入格式
print(img.shape)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load("NO.20_model.pth") # 加载模型
model.eval()
with torch.no_grad():
img = img.cuda() # 等价写法:img = img.to(DEVICE),因为模型是在cuda上训练保存的,现在要保持输入数据一致
output = model(img)
print(output.argmax(1)) # tensor([5], device='cuda:0') # 预测为第五类:表示狗,正确


 浙公网安备 33010602011771号
浙公网安备 33010602011771号