【学习笔记】机器学习(西瓜书)- 周志华
第一章 绪论
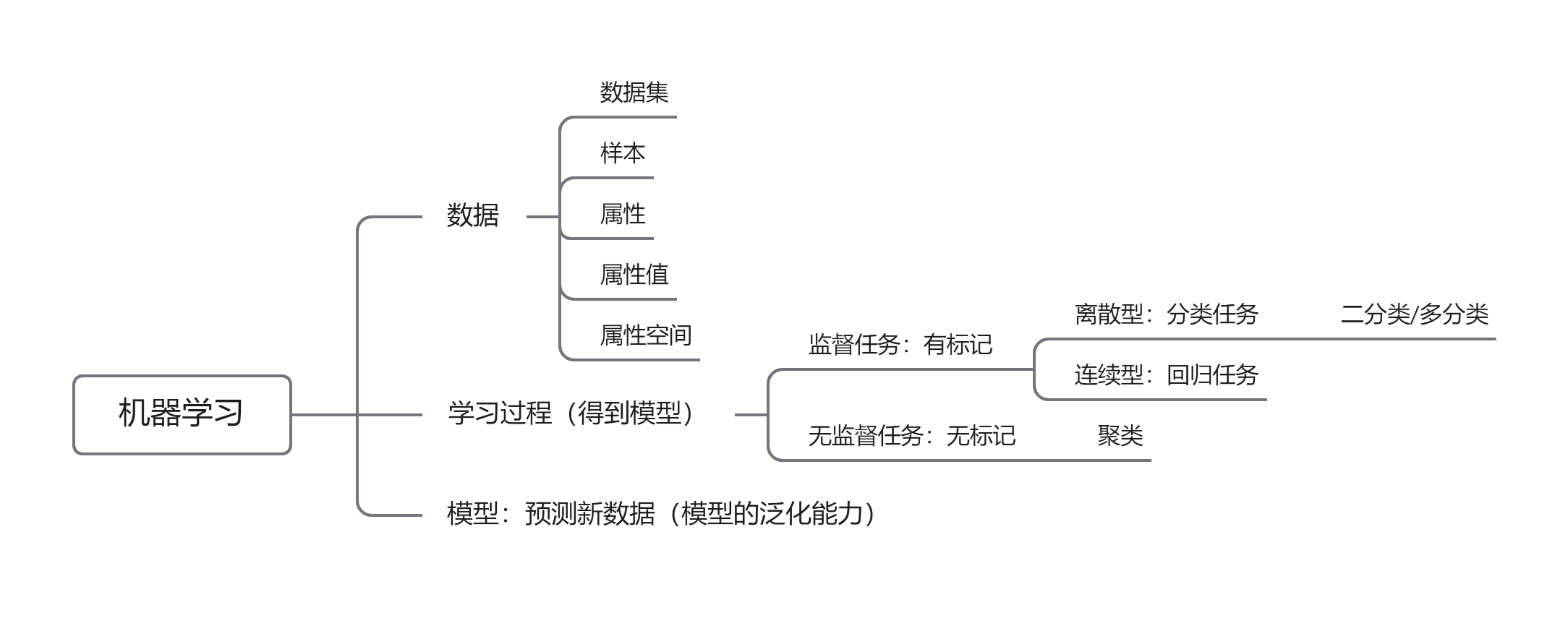
什么是机器学习
-
通过计算的手段,从“数据”产生“模型”的“算法”
-
我们将新“数据”提供给“算法”,能产生关于这些“数据”的“模型”,“模型”能给我们提供相应的判断
-
tips:本书模型指机器学习的结果
基本术语
-
数据集(data set):一组样本(sample)的集合
-
样本(sample):样本是针对实际个体的数据描述
-
属性(attribute):反映样本某方面的特点的事项分类
-
属性值(attribute value):属性的值
-
样本空间(sample space)/属性空间(attribute space):属性张成的空间
例如把
色泽,根蒂,敲声三个属性作为三个坐标轴,可以张成一个用于描述西瓜的三维空间,每个西瓜对应空间里的一个点,点就是坐标向量,所以我们也可以把样本称为“特征向量”(feature vector) -
数据集的公式含义
令\(D=\{x_1,x_2...,x_m\}\)表示包含m个样本的数据集,每个样本有\(d\)个属性,则每个样本\(x_i=\{x_{i1},x-{i2},...,x_{id}\}\)是d维样本空间\(\chi\)的一个向量,\(x_i\in\chi\),\(X_{ij}\)是\(x_i\)在第j个属性上的取值,d是样本\(x_i\)的维数 -
训练与假设(hypothesis)
从数据得到模型这个过程我们称之为学习(leaning)或训练(training),学习使用的数据称为训练数据,每个样本为训练样本,训练样本组成训练集学得的模型对应关于数据的某种规律,被称为假设(hypothesis)。而这种规律本身则被称为真相或真实 -
预测与样例
通过已有的信息,判断一个瓜的好坏就是预测,这里瓜的好或坏就是标记(label),样本和标记组合在一起就是样例
用\((x_{ij},y_i)\)表示第i个样例,其中\(y_i\in \mathcal{Y}\)是样本\(x_i\)的标记,\(\mathcal{Y}\)是所有标记的集合,称为标记空间、输出空间 -
分类与预测
根据数据的类型(离散型or连续型),机器学习可以分为分类任务和回归任务 -
二分类与多分类
只涉及两个类别的分类任务,我们称其中一个为正类,另一个为反类 -
预测和测试
通过已经训练得到的模型,对一组样本的标记进行预测的过程,就是测试(testing) -
聚类
将训练集中的样本分成若干组,每组称为一个簇,这个过程不需要有标记信息
假设空间
- 机器学习是从样例中获取模型的泛化过程,也可以称为归纳学习
- 广义的归纳学习是从样例中学习,狭义的归纳学习则是从训练数据中获取概念
- 假设空间
机器学习过程可以看作一个在“所有假设(hypothesis)组成的空间”中进行搜索的过程,搜索目标是找到匹配(fit)的假设,即能够将训练集中的瓜判断正确的假设 - 版本空间
现实生活中假设空间很大,而训练数据有限,可能存在多个假设与训练集一致,这些假设的集合为版本空间
归纳和偏好
- 学习得到的模型对应着假设空间的假设,不同的假设判断得到不同的结果,
归纳偏好是我们对模型判断结果的标准

 浙公网安备 33010602011771号
浙公网安备 33010602011771号