stacking学习方法
Stacking集成学习算法
原理展示
stacking方法在在blending方法基础上演变而来,总体逻辑依旧是分层集合预测结果,以两层为例

第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的stacking模型。
相对于blending,将HoldOut CV(自定义拆分)替换为K-fold CV(K折检验过程),能更充分的利用数据
具体训练过程:
-
第一层
- 划分训练集为K折,为各个模型的训练打下基础;
- 针对各个模型分别进行K次训练,每次训练保留K分之一的样本用作训练时的检验,训练完成后对testing data进行预测,一个模型会对应5个预测结果,将这5个结果取平均;
- 最后分别得到n个模型运行5次之后的平均值,同时拼接每一系列模型对训练数据集的预测结果带入下一层;
-
第二层:将上一层的n个结果带入新的模型,进行训练再预测。第二层的模型一般为了防止过拟合会采用简单的模型。
代码实现
由于sklearn并没有直接对Stacking的方法,因此我们需要下载mlxtend工具包(pip install mlxtend)
# 1. 简单堆叠3折CV分类
# 导入包
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier
# 导入数据
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
RANDOM_SEED = 42
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
# Starting from v0.16.0, StackingCVRegressor supports
# `random_state` to get deterministic result.
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3], # 第一层分类器
meta_classifier=lr, # 第二层分类器
random_state=RANDOM_SEED)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes','StackingClassifier']):
scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
3-fold cross validation:
Accuracy: 0.91 (+/- 0.01) [KNN]
Accuracy: 0.95 (+/- 0.01) [Random Forest]
Accuracy: 0.91 (+/- 0.02) [Naive Bayes]
Accuracy: 0.93 (+/- 0.02) [StackingClassifier]
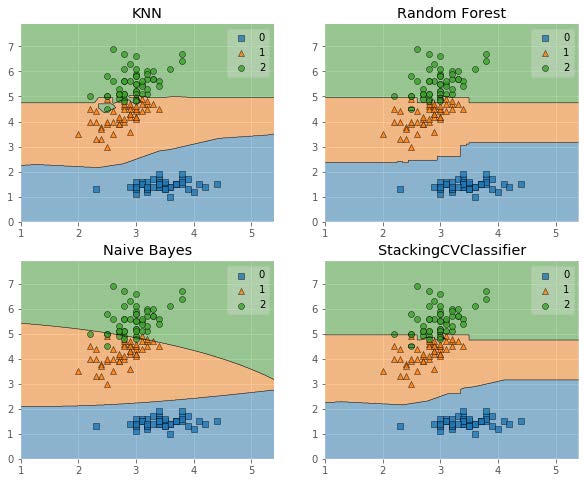
# 画出决策边界
from mlxtend.plotting import plot_decision_regions
import matplotlib.gridspec as gridspec
import itertools
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
for clf, lab, grd in zip([clf1, clf2, clf3, sclf],['KNN','Random Forest','Naive Bayes','StackingCVClassifier'],itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(lab)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号